
こんにちは、IBM でストレージ・ソリューション・セールスのパートナー様向け技術支援を担当している岡田です。
今回は IBM の最新情報を交えつつ、IBM のストレージ製品の概要をご紹介させていただき、次回以降でその詳細に触れていきたいと思います。
はじめに
皆さんはどのくらい IBM のストレージ製品にご興味がおありでしょうか?
興味のあるなしに関わらず、多くの方は知らず知らずのうちに IBM や他のメーカー のストレージ上に様々なデータを書き込んでいることでしょう。ストレージの使用は、あえてデータを保管しようとせずとも無意識に行なっているものです。
例えば…
例えば、コンサートやイベントのチケットなどのケース。
発売当日は予想を超えるアクセス数がありますね。昔ならサーバーを増強してサーバーがパンクしないように対策し、それでもなおかつ処理能力を超えてしまいダウンしてしまったなどという話を聞いたことがあると思います。
しかし今では、クラウド上で一時的に仮想サーバーを増やして難なく対応するというように、時代とともにやり方は変化してきています。
でもその時データを貯めるストレージはどう扱うのでしょう?
オンプレミスでもクラウドでも連携してハイブリッド・クラウド環境でデータをきちんと管理できるのが IBM のストレージです。
また、景品やポイント目当てで今日もスマホからアンケートに答えている方も多いことでしょう。
そのデータは、しばらくは価値のあるデータとして集計やいろんな解析に回されたりするかもしれません。少し時間が経過してもアンケートのコメント欄に書かれた内容を閲覧する人もまだちらほらといるかもしれません。
でもいずれは旬を過ぎたデータとしてどこかに保存だけされ、そのうち不要なデータとして削除しなければならなくなる。
これが、まさにデータのライフサイクルです。
しかし、実際はこのようなデータを正しく管理するのは非常に手間がかかります。場合によってはどこかでミスを起こし、まさかのデータ流出なんてことになりかねません。
データの「揺り籠から墓場まで」を実際にきちんと自動管理できるのが IBM のストレージです。
そして、さらに考えてみてください。そのデータはどうやって守られているのかを。
「守られている」というのには幾通りかの解釈があります。盗まれない・改ざんされないように守るセキュリティ、無くならないように守る信頼性、壊れないように守るインテグリティ、セキュアな移動に耐えうるポータビリティなど、これら「守る」をきちんと管理できる機能があるのも IBM のストレージです。
では、それらを実現する IBM のストレージの概要をみていきましょう。
IBMストレージ製品の紹介
IBM は現在、あらゆるお客様の規模・業種あるいはユースケースなどに対応するためにストレージ製品群を以下の4つのカテゴリーに分けて考えております。
図1. IBMストレージ製品カテゴリー
これらのカテゴリーにはハードウェア製品のみならず、IBM Spectrum Storage ファミリーというソフトウェア・デファインド・ストレージ製品もマッピングされています。
IBM はいち早くソフトウェア・デファインド・ストレージに取り組み、今やストレージのみならず、バックアップ、マネージメントと幅広いカバレージで展開しております。
それでは一つ一つ見ていきましょう。
Hybrid Multi Cloud Storage
ハイブリッド・マルチクラウド・ストレージに属するものとして、FlashSystem という FlashCore Module(以下 FCM)や SSD などの半導体メモリー系記憶デバイスを活用したストレージ製品群があります。
いわゆるオープン系と呼ばれていた分野は仮想化という過程を経てクラウド時代へ突入しており、コンテナ時代も本格化の兆しを呈しております。この分野で扱うのに適しているストレージ群という位置付けです。

IBM FlashSystem 9200
このラインアップはエントリークラスからハイエンド製品まで、お客様の規模等に合わせた製品を選択でき、なおかつ統一された操作性を実現する製品です。
またこれら FlashSystem の制御機能を外出しした IBM Spectrum Virtualize のパブリック・クラウド版と連携することで、オンプレミスや他のクラウド環境との容易なデータ連携を実現します。
(※詳細は第三回のブログで明らかにします。)
同じカテゴリーに位置する IBM Storage Insights は SaaS として提供される統合ストレージ管理サービスです。
複数の IBM ストレージを一括管理できるだけでなく、他のメーカー様のストレージも管理対象としています。世界中で培われた数多くの知見と AI により提供されるアドバイザリー機能は、ストレージの障害発生率の劇的削減につながります。
AI & Big Data
Web Scale という言葉で代表される分野です。
特徴としては IoT のデータのように無限に増えていくデータに対応しうる拡張性、分散保管系、そして広いエリアでファイルやオブジェクトを一意的に扱えるグローバル・ネーム・スペースといったところが挙げられます。
製品で言うと IBM Cloud Object Storage や Elastic Storage System(ひとつ前のモデルまでは Elastic Storage Server と呼んでいました)がこれにあたります。
IBM Cloud Object Storage はオブジェクト・ストレージ機能に特化しており、ペタバイト級のデータを、高信頼性・高可用性・高安全性を保ちつつ扱うことができる分散保管型のストレージで、拡張性にも優れた製品です。業界ではデファクトとなっているオブジェクト・ストレージの AWS(Amazon Web Services)の S3 に準拠した API により、多くのサードパーティーのゲートウェイ・ソフト製品にも対応しております。
IBM Cloud Object Storage はアプラアンス製品としてハードとともに提供しておりますが、評価済みの汎用サーバーをお持ちであればソフトウェアのみでの提供も可能です。また IBM Cloud 上では IaaS としての IBM Cloud Object Storage が月額で使用可能です。
Elastic Storage System は IBM Spectrum Storage 製品のうち IBM Spectrum Scale という分散型ファイル・システムのアプライアンス製品です。GPFS(General Parallel File System)という Power 製品の分野で培った高度なファイル・システムをベースとしており、自動階層化機能、マルチプロトコル対応、拡張性といった特徴のみならず、分散ノードの並列度を上げることで高パフォーマンスな用途にも対応できます。
今日時点最新である2019年11月18日発表のスーパーコンピュータ性能ランキング「TOP 500」で、1位2位を独占する Summit という IBM のスーパーコンピュータにも搭載されている優れものです。
(※次回以降、階層化機能を中心に明らかにします。)
また AI や BigData を扱うエリアでは、膨大なデータにおけるカテゴライズや検索といったことが重要になってきます。
通常はシステムにより自動付加される情報に頼ることが多いですが、メタデータ、タグ情報といったもので効率的にデータを扱える仕組みがあります。このメタデータやタグ情報を管理できるのが IBM Spectrum Discover で、上記2つの製品群と一緒に使われることでデータにより一層の価値を持たせることが可能となります。
Modern Data Protection
一番わかりやすいのがモダン・データ・プロテクションのエリア。災害や障害に耐えうるバックアップやディザスター・リカバリーに特化した製品群です。
いかに短い時間で効率的にバックアップを取得するかということは当然のことながら、いかにロス無く早くシステムを復旧できるかということが重要になってきます。
また、以前より障害やヒューマンエラー、災害対策、争乱と対象が発展し、今やサイバー攻撃にも対応する必要が出てきました。
さらに守るべき対象もオンプレミスだけではなく有機的にクラウドと結びついている場合もあり、これらに対応していくということが、まさにモダン・データ・プロテクションたる所以であります。
ここでの中心となるのはテープ製品群です。
現在の企業向けテープ規格のスタンダードと言えば LTO(Leaner Tape-Open)を思い浮かべる方が多いと思いますが、IBM は規格立案時代より中心的に関わっており、LTO および企業向けに発展させた 3592エンタープライズ向けテープ(IBM 独自フォーマット)の2本立てのテープカートリッジ規格に対応した製品群を扱っております。

IBM TS4500 Tape Library
同じカテゴリーの IBM Spectrum Storage ファミリー製品としては、IBM Spectrum Protect というバックアップ・ソリューション・ソフトウェアがあります。
これは Tivoli Storage Manger というバックアップ・ソフトを Spectrum ファミリーに統合したもので、長い歴史と実績を持っています。完全なる永久増分バックアップ機能と各種データ圧縮機能を用いることでバックアップ容量およびバックアップ時間を格段に削減することが可能です。
仮想サーバー環境に特化した IBM Spectrum Protect Plus という製品もあり、すでにいくつかのパブリック・クラウド上での月額使用も可能となっております。
昨今、テープ装置は物理的にシステムから切り離すことができるストレージとして、「エアー・ギャップ」という言葉のもと、サイバー攻撃にも耐えうるソリューションとして見直されつつあります。
(※詳細は第五回のブログで明らかにします。)
Storage for Z
IBM のフラグシップとも言えるメインフレーム製品にも対応するハイエンド・ストレージ機器群となります。
技術の結晶とも言われるこの分野の製品は信頼性・可用性共に高いレベルにあり、過去から現在に至るまで世界中の経済を支えてきたと言っても過言ではありません。
DS8000 シリーズはホスト製品のみならず、オープン系の分野も含め 2000年代初頭から現在までの長い間、高可用性・高性能の分野で一役を担ってきました。
遠隔のストレージ同士をミラーリングするという考えは、もともとホスト系ストレージ・システムで行なっていた PPRC、XRC と呼ばれるミラーリングに始まり、現在の Metro Mirror、Global Mirror といった同期・非同期のミラーリングに受け継がれているもので、今ではエントリー製品にもあたりまえのように使われる技術となっています。

IBM DS8900F
DS8000 シリーズは今でも進化しており、最新ラインアップ DS8900F シリーズではオール・フラッシュ製品に変化を遂げ、超低遅延・高可用性の他、クラウドとの連携やマルウェア・ランサムウェア対策など最新の技術を投入され、今後のIT環境にも活用いただけるフラグシップ製品です。
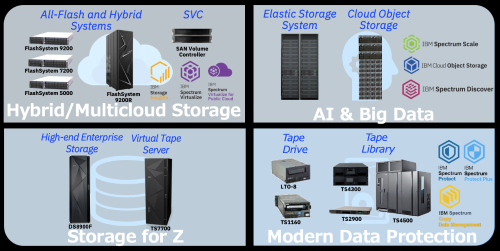
図2. IBMストレージ製品ポートフォリオ
まだまだ説明したい製品がありますが、別の機会にご説明させていただきたいと思います。
おわりに
今後も、以下のようなテーマでブログを掲載させていただく予定ですのでお楽しみに!
(もしかしたら突発的な話題や多少の変更はあるかもしれませんがご了承ください。)
第二弾:「OpenShiftに代表されるコンテナ環境へのIBMストレージの対応」
第三弾:「ハイブリッド/マルチクラウド時代だからこそIBMのストレージ」
第四弾:「最新のデータライフサイクル管理とは?(前編)」「最新のデータライフサイクル管理とは?(後編)」
第五弾:「データを守ることについて」
このブログで少しでも IBM のストレージ製品にご興味を抱いていただけると幸いです。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBMストレージ製品 (製品情報)
- 全包囲網。。。最新 IBMストレージ 概要 (ブログ)
- 最新のデータライフサイクル管理とは?(前編)(ブログ)
- 最新のデータライフサイクル管理とは?(後編)(ブログ)
- ハイブリッド/マルチクラウド時代だからこそIBMのストレージ (ブログ)
- AI導入はどこまで現実的? 5大ハードルとその解決策を解説 (ホワイトペーパー)
- 普及が進む、機械学習による異常検知。導入の課題はここまで解決している (コラム)