
IBM の岡田です。
「最新のデータライフサイクル管理とは?(前編)」では “データの価値” や “IBM Spectrum Scale” についてのお話をしました。
後編は “IBM Cloud Object Storage” とは何か、といったことから、続きのお話をしていきましょう。
IBM Cloud Object Storageとは
先にデータの価値の話をしました。今度は昨今のデータの在り方のお話から入ります。
ここ10年ほどの間に、データの中心はトランザクション系の構造化データからビデオコンテンツや写真や IoT のセンサーデータなどの非構造化データにシフトしています。
近年その伸びも2年ごとに90%レベルの伸びを示しており、現在世の中のデータはすでに数十ゼタバイト程とも言われています。
つまり、これからのストレージはその容量の拡大についていく必要があり、そのような大容量下でデータ保全していかなければならないということです。
このような膨大な非構造化データの保管に向いているのが、オブジェクトストレージと言われるものです。(ブロック・ファイル・オブジェクトの違いはGoogle検索してみると色々解説がありますので、そちらをご参照ください)
オブジェクトストレージには以下の特徴があります。
- 階層を持たない
- API による I/O
- 複数ノードによる分散保管
IBM Cloud Object Storage(以降 ICOS と呼ぶ)はこの複数ノードによる分散保管を地域レベルまで広げ、複数サイトでデータを持ち合う(ただしミラーではない)ことで地域災害などサイトレベルでのダウンにも対応できる保全性を実現します。
これにはイレージャーコーディングという RAID とは別のデータ保全の仕組みが使われてます。
RAID の問題点は、扱う容量が大きくなればなるほど障害後の再構成の時間がかかるようになるということ。この再構成時に新たな障害が発生するとデータロストに繋がります。
ICOS で使われる Information Dispersal Algorithm(以降 IDA と呼ぶ)というイレージャーコーディングをベースにした技術は、複数ディスク、複数ノードの障害を許容する、さらに言えば、ハードウェアは壊れることが当然、という思想の元に出てきたデータ保全方法のため、ある閾値に達するまではハードウェアの障害に影響されず、データの読み書き、運用が正常に行われます。
閾値で許容される障害ノード台数がサイトのノード数以上であればサイト障害にも耐えうる、ということです。
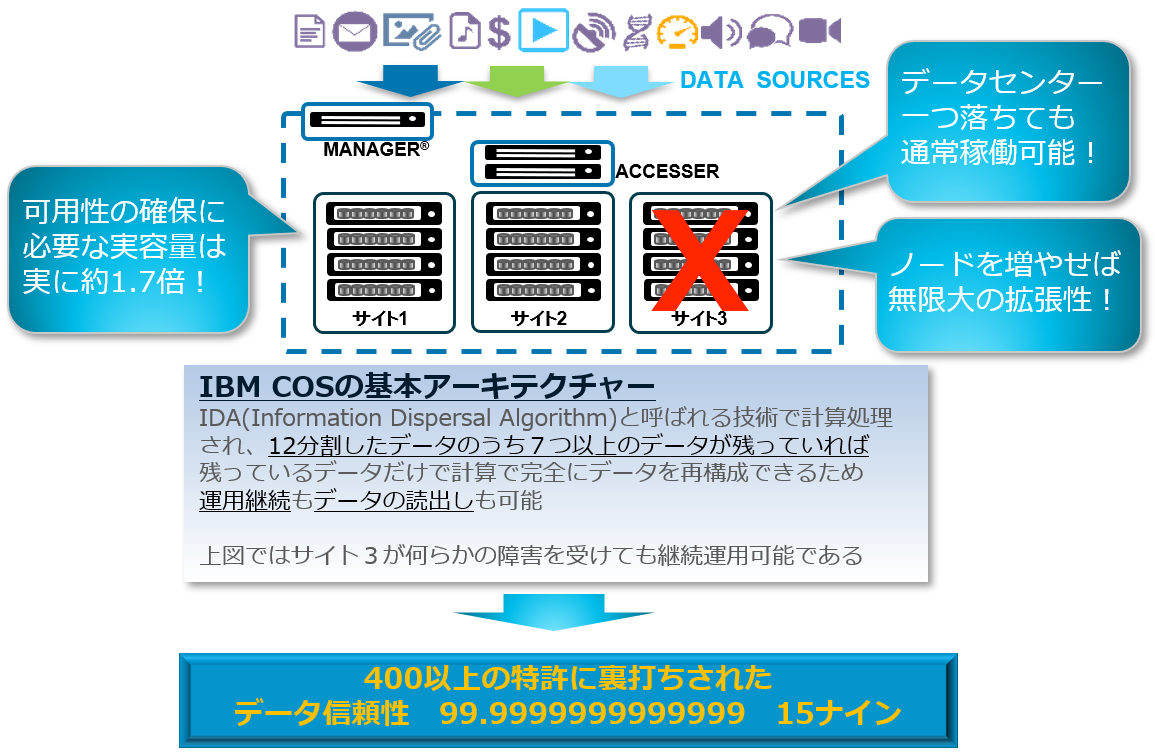
図6. IBM Cloud Object Storageの基本的なアーキテクチャー
IBM Cloud 上でもこの ICOS を使った月額課金のオブジェクトストレージを提供していますが、アジア圏の場合、東京・ソウル・香港の3箇所に分散して ICOS を運用しております。
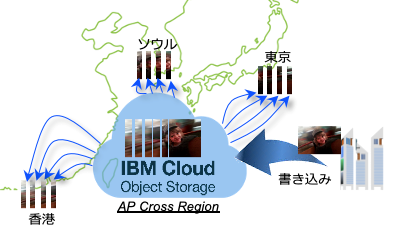
図7. IBM Cloud のオブジェクトストレージ(ICOS)
このような3箇所ないしそれ以上の拠点に暗号化したデータを分散しておくことで、セキュアで信頼性の高いデータ保管が可能となり、現実に ICOS に保管されたデータの信頼性は最大 15ナイン(99.9999999999999%)とも言われています。
安い容量単価でデータの最後の砦としての信頼性を確保できるストレージとして、ICOS はテープと違った面で適していると言えます。
また ICOS は API でやりとりするという点でも、昨今の Cloud Native なアプリケーションとも相性が良く、AI や Analytics系でのデータ提供にも非常に適しています。
よって、非構造化データのような保管がメインで利活用の可能性が高いデータに最適な選択と言えるのが、IBM Cloud Object Storage です。
ICOS にはデータのライフサイクルを管理する上で重要な機能があります。
WORM という言葉をご存知でしょうか?
元々は US で決められた法律に準拠したデータ保管のメディア方式の一つです。Write Once Read Many の略で、要は上書きが出来ず、改竄不能なメディアとして出来たものです。
ICOS にもこの WORM の機能があります。
WORM として設定されたエリア(一般的にはバケットにあたる。IBM では Vault と呼んでいる)にひとたびデータを書き込むと、そのデータは消去もできなければ改竄もできなくなります。データ保管の期間を設定することができるので、データライフが終わった時にタイムリーにデータを削除することも可能となります。
例えば、法律や規定等で保管年数を決められている契約書などの書類や、証拠物件として扱われる写真や帳簿類など、普段はアクセスすることもないが無くしてはいけない重要なデータのライフ管理には有効な手段となります。
また、最近はランサムウェアなどのデータ改竄(暗号化)に耐えうるバックアップデータエリアとしても注目されています。
IBM Spectrum Discover
ここまでに示した通り、データはますます伸び率が高くなってきています。日ごとに増えるデータを扱う上でネックになるのが、データの特定等、保管データを後から扱うときの仕組みです。
最近のトレンドとしては、ファイルに関連づけられたメタデータや、ユーザーが自由に付加できるタグを活用しデータをカテゴライズしたり検索したり、といった作業が多くなっています。
IBM Spectrum Discover は、こういったメタデータ、タグデータをマネージするためのソフトウェアです。
明確には SDS というわけではなく、むしろデータマネージメントの意味合いが強いソフトウェアです。Discover の強みは、API を介して AI などにデータを食わせることができる、という点にあります。
例えば、画像データであれば画像解析の機能を持った AI(IBM では Watson Visual Recognition がこれに当たる)で画像に付随する情報を抽出し、これをタグデータとして付加する、といった作業を半自動的に行えることです。これにより、膨大なデータのカタログ化や一部のデータの抽出、あるいは不要であったりおかしなデータが紛れ込んでいないかなど、ガバナンスに対応することが可能です。
こうしたデータの利活用の方法も、大きな意味でデータのライフサイクルを支える新しい手法と考えられ、データマネージメントに寄与することができるわけです。
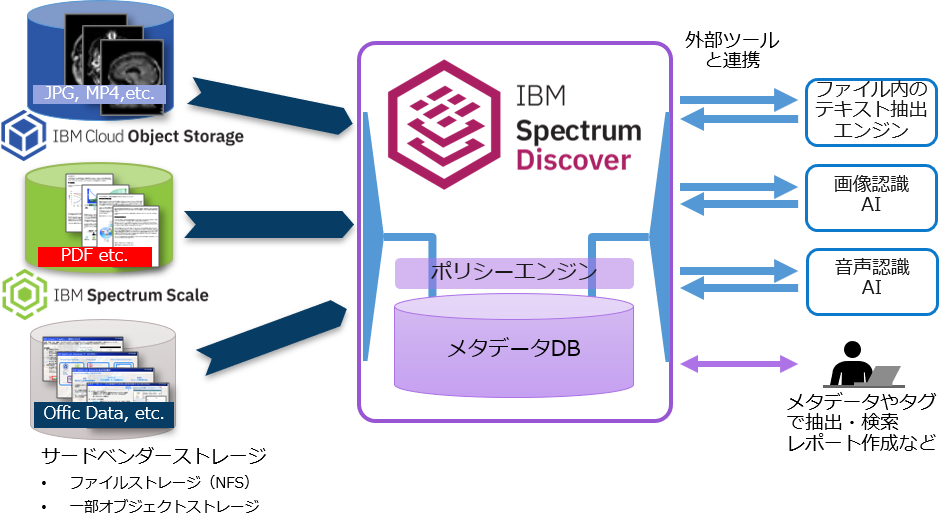
図8. IBM Spectrum Discover のデータマネージメントのイメージ
次回はデータを守ることについてお届けします。最後までお読みいただきありがとうございました。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
参考情報
- IBMストレージ製品 (製品情報)
- 全包囲網。。。最新 IBMストレージ 概要 (ブログ)
- OpenShiftに代表されるコンテナ環境へのIBMストレージの対応 (ブログ)
- ハイブリッド/マルチクラウド時代だからこそIBMのストレージ (ブログ)
- AI導入はどこまで現実的? 5大ハードルとその解決策を解説 (ホワイトペーパー)
- 普及が進む、機械学習による異常検知。
導入の課題はここまで解決している (コラム) - データ・ファーストのハイブリッドクラウド基盤を実現するIBMストレージ (IBMサイト)
- ハイブリッドクラウドにおけるデータ連携の鍵を握るもの (IBMサイト)