- シェア
-

【てくさぽBLOG】IBM watsonx.aiを使ってみた(Part2)
こんにちは。
てくさぽBLOGメンバーの高村です。
Part1はご覧いただけましたでしょうか。
watsonx.ai にご興味をもっていただければ幸いです。
Part2(本記事)は応用編ということで、watsonx.ai を利用した Retrieval-Augmented Generation(以下 RAG)検証をやってみた感想をご紹介します。
RAGとは?
生成AIの分野で「RAG」が話題となっていることはご存じでしょうか。
RAG とは、言語モデルが学習していない社内情報や最新情報などのデータ(以下 外部データ)から情報を補完し、言語モデルが生成する回答の品質を向上するフレームワークです。
例えば言語モデルのみを利用した QA の場合、図1の様にユーザが質問をすると、生成AI は質問に対して的確に答えることもあれば、学習データに含まれたいい加減な情報を吐き出すこともあります。
言語モデルのチューニングにより回答精度を調整することも可能ですが、都度アップデートされる情報をモデルに学習させることは労力が必要です。
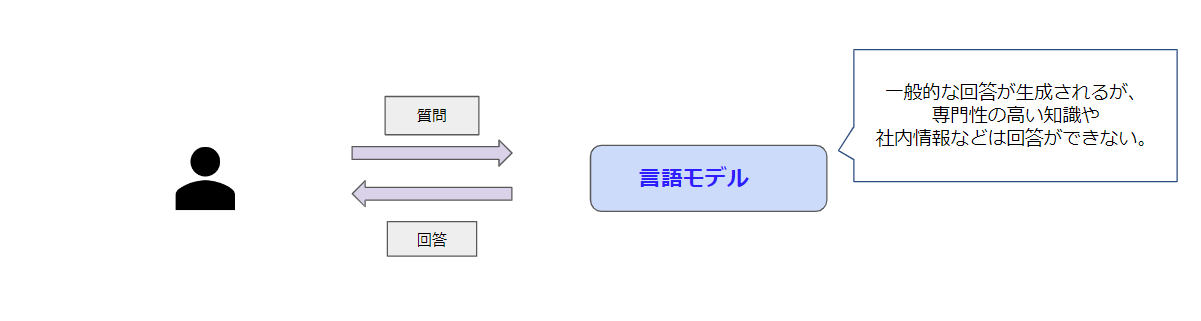
図1. 言語モデルのみを利用した場合の情報検索
そこで考えられたのが、RAG というフレームワークです。
図2のように、外部データをデータベースに保存しその検索結果に基づいて言語モデルに回答を生成させることで、より正確な情報を得ることが可能です。
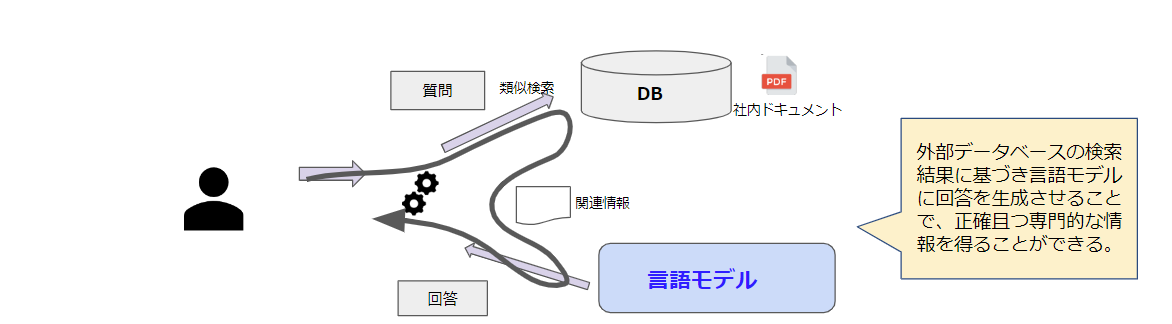
図2. RAGを利用した情報検索
RAGのメリット
RAG は、検索と生成AI を統合することでより正確な関連性の高い回答を提供します。
以下は、RAG を利用することで得られるメリットです。
- より正確な情報を得られる:
初めに外部の知識ベースで検索を実行するため、生成AI だけを使った回答よりもより専門的で正確な回答を提供します。
- 質問の文脈を踏まえた回答を得られる:
検索と生成AI を組み合わせることで多くの情報源から情報を収集し、人間のような新しい回答を生成することができます。
- モデル学習に必要なデータ準備と作業労力を削減:
言語モデルの訓練には大量のデータが必要ですが、RAG は外部データを利用するためモデルへ学習データを取り込むた必要がなく、チューニングにかかる労力も削減できます。
RAGの活用シーン
RAG は様々な業種での活用が考えられます。以下に具体例を挙げます。
- 顧客サポート:
コールセンターや保守業務において、顧客の問い合わせに対して専門的かつ正確な回答を提供します。
RAG を利用することにより迅速な回答提供や効率的な運用が可能となり、顧客満足度を向上します。
- バックオフィス業務サポート:
社内情報の検索において、自己調査が容易になり対応時間を短縮することが可能です。
- オペレーション業務サポート:
例えば現場作業員の機器操作手順など、RAG を利用することにより効率的に解決することが可能です。
watsonx.aiを使ってRAGを検証してみた
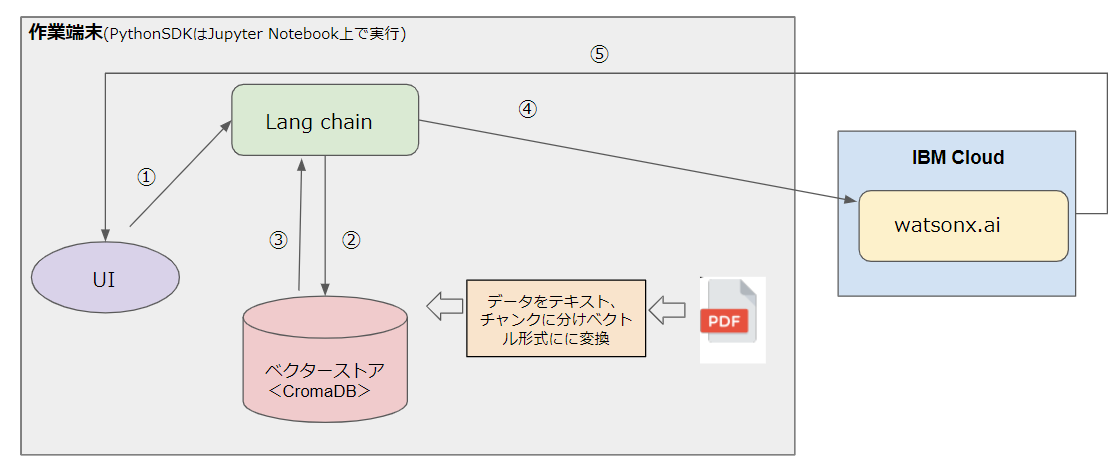
watsonx.ai の言語モデルを利用し、自分の端末から PDF の内容を QA をする RAG を作ります。
利用するコンポーネントは以下の4つです。
- watsonx.ai:
回答を生成する生成AI。言語モデルは llama-2-70b-chat を利用します。
- ベクターストア:
今回はオープンソースのベクターストアである ChromaDB を利用します。
ベクターストアとはデータを文字列ではなくベクトル形式で保管するデータベースです。PDF の内容を質問するため、LangChain により PDFデータをテキストとチャンクに分け、変換し、ベクターストアに取り込みます。
- LangChain:
言語モデルを活用したサービス開発する際に利用するオープンソースライブラリです。
PDF をベクターストアに保存する際にチャンクデータとして分割したり、ベクターストア内を検索し結果を watsonx.ai へ渡します。
- PythonSDKの実行環境 –Jupyter Notebook–:
LangChain は Python と JavaScript の2つの言語プログラミング言語に対応していますが、今回は Python の LangChain を利用します。
PythonSDK の実行環境として作業端末に Anaconda をインストールし、Jupyter Notebook からスクリプトを実行します。
QA処理の流れは以下の通りです。
- LangCain経由で質問
- LangChainからベクターストアへ情報検索
- 検索結果をLangChainへ渡す
- 検索結果をwatsonx.aiの言語モデルへ渡す
- watsonx.aiが回答を生成し、回答
それではさっそく RAG を作って検証してみましょう。
watsonx.aiプロビジョニング、プロジェクト作成
事前に watsonx.aiプロビジョニング、プロジェクト作成が必要です。
※作成方法は part1 をご参照ください
APIキー、プロジェクトIDの取得
watsonx.ai の言語モデルに接続するためには、APIキーとプロジェクトID の取得が必要です。
- APIキーの取得は IBM Cloud画面「管理」⇒「アクセス(IAM)」をクリックし、「APIキー」をクリックします。
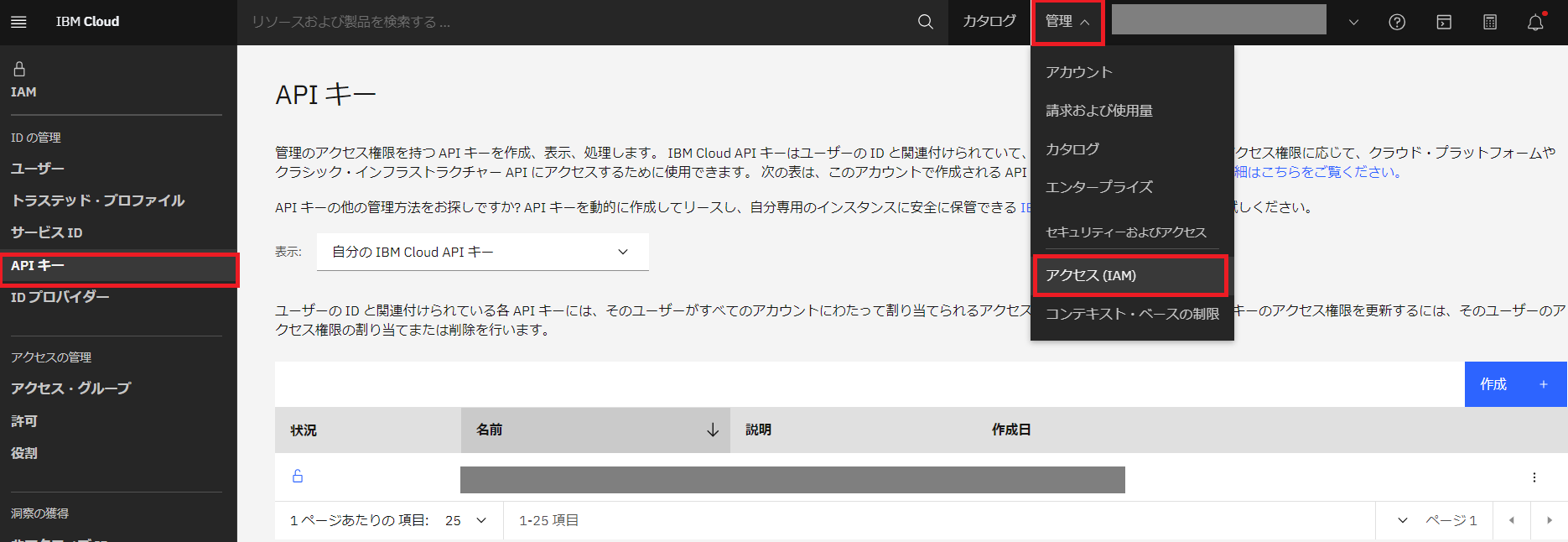
- 「作成+」をクリックし、任意の名前と説明を入力しキーを作成します。
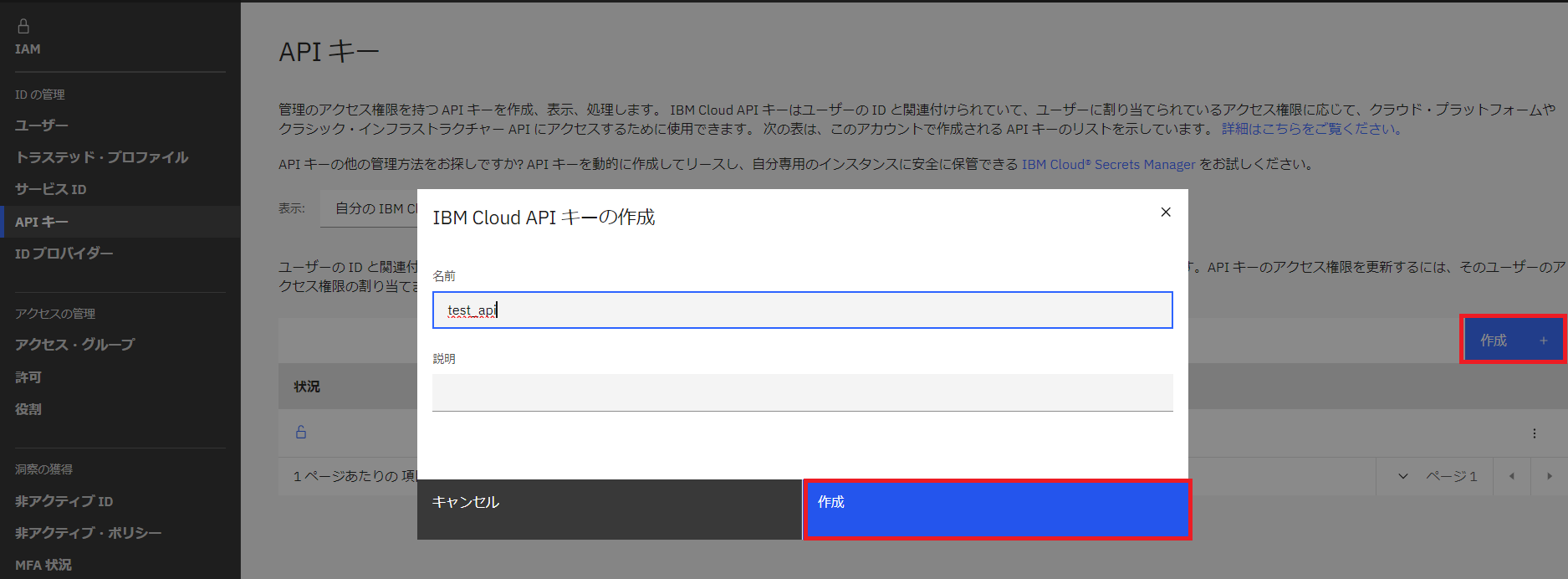
- APIキーが作成されたので、コピーして手元にメモしておきます。
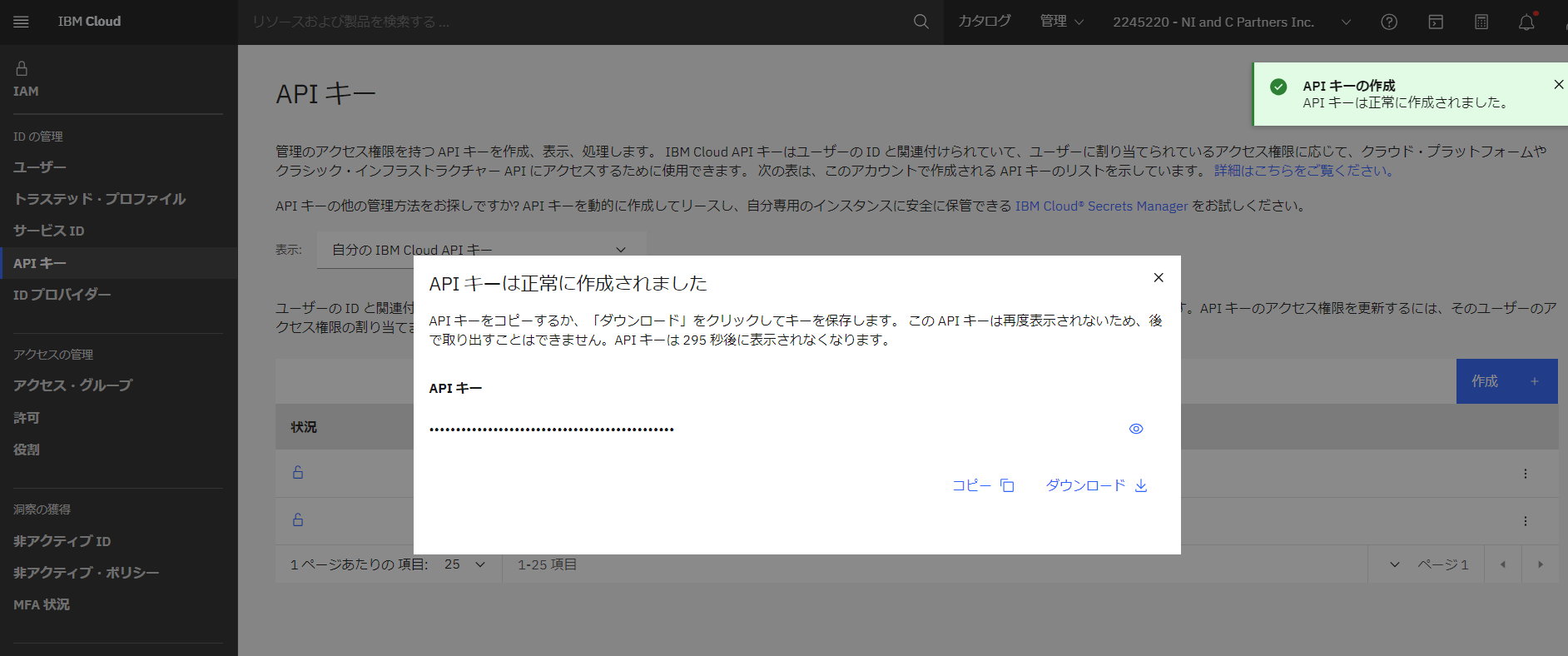
次に、watsonx.ai のプロジェクトIDを取得します。
- watsonx.ai のプロジェクトをクリックします。
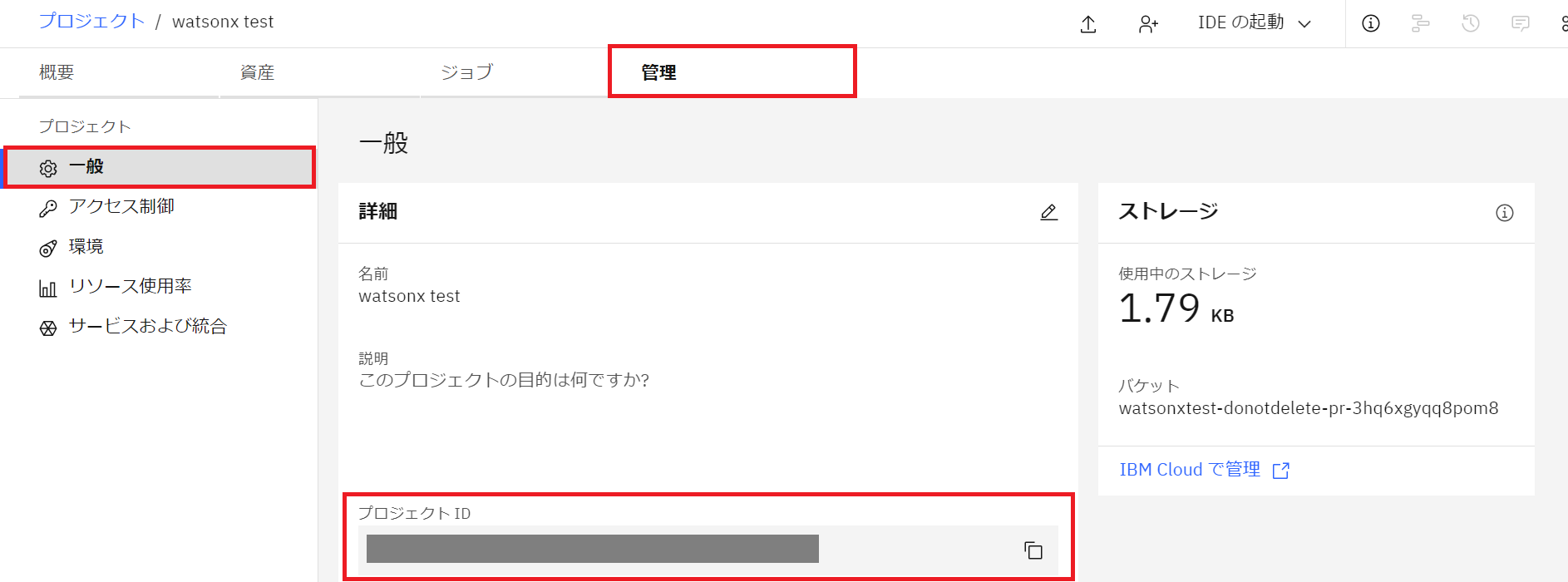
- 「管理」タブから「一般」をクリックするとプロジェクトID が表示されるので、コピーして手元にメモします。
PythonSDKの実行環境準備
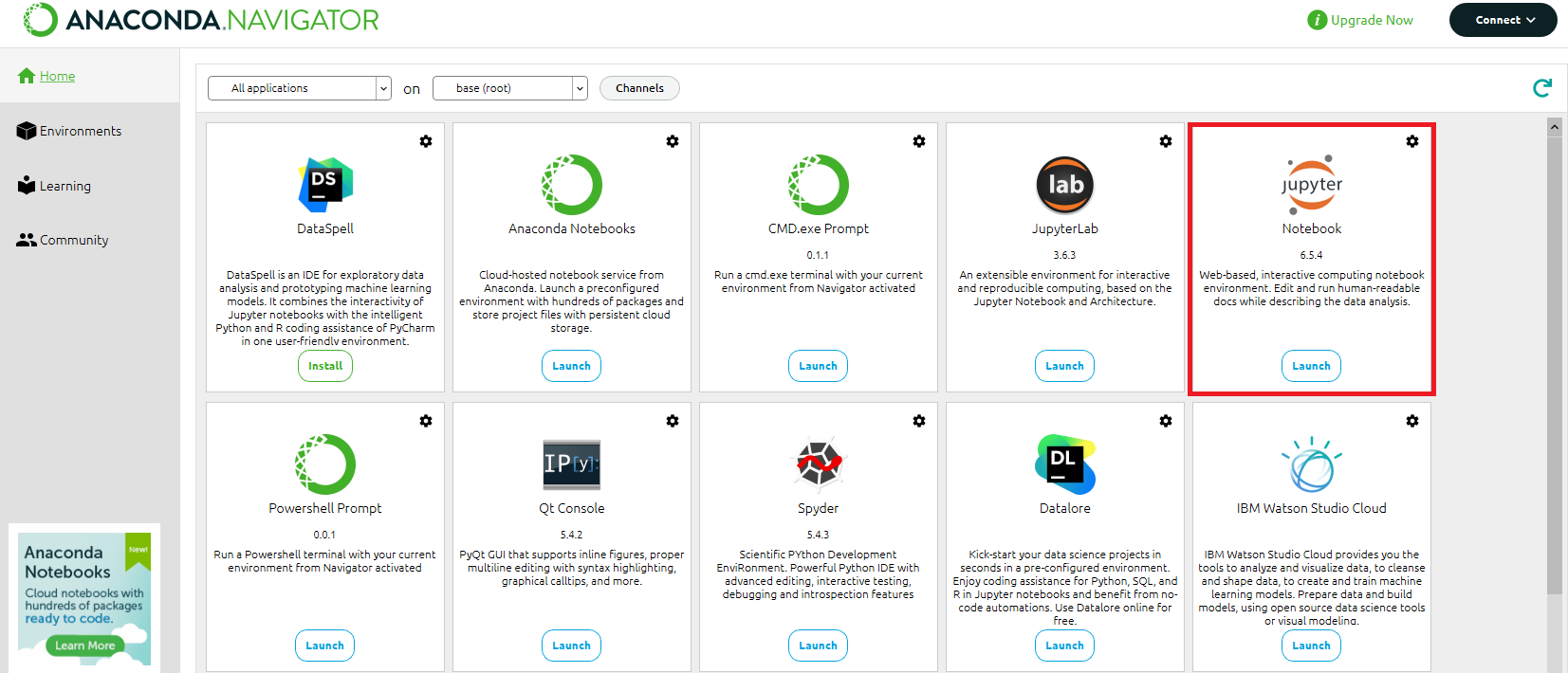
- 以下の URL から Anaconda のイメージをダウンロードし、作業端末にインストールし、インストールが完了したら Jupyter Notebook を起動します。
「https://www.anaconda.com/download」
- 事前に作成したスクリプトをクリックして開きます。

認証設定、モジュールのインポート
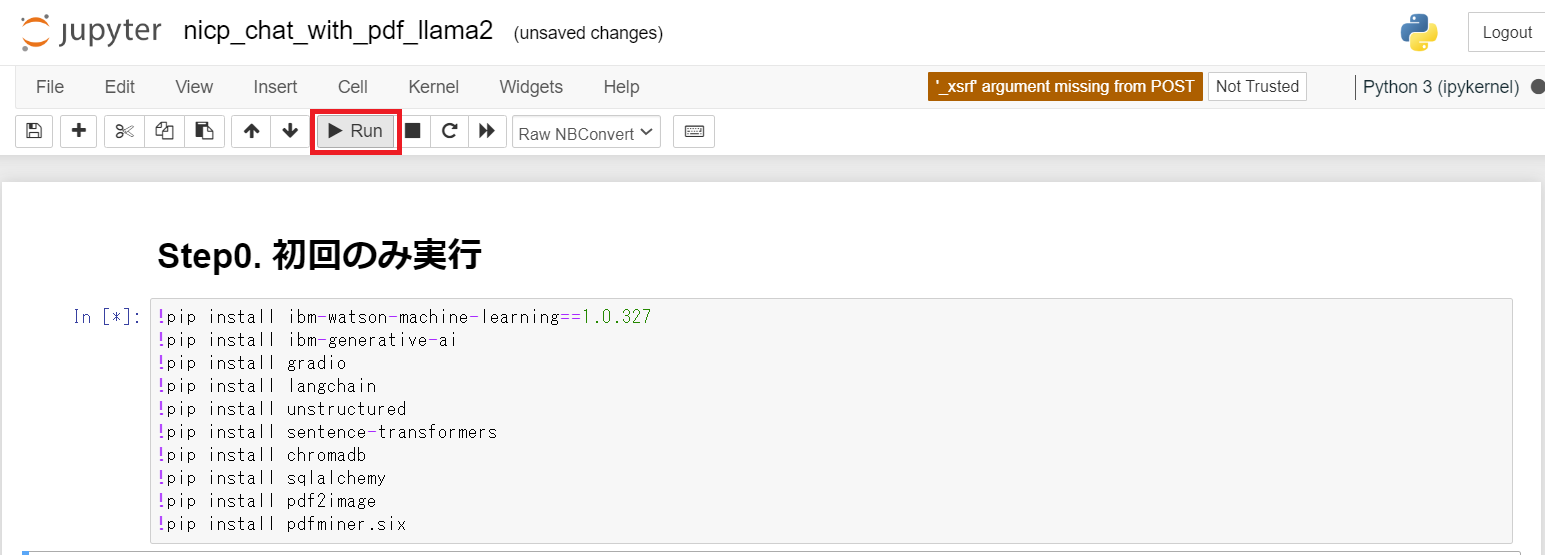
はじめに、必要な Pythonライブラリをインストールします。
- 「Run」ボタンをクリックすると、セル内のプログラムが実行されます。
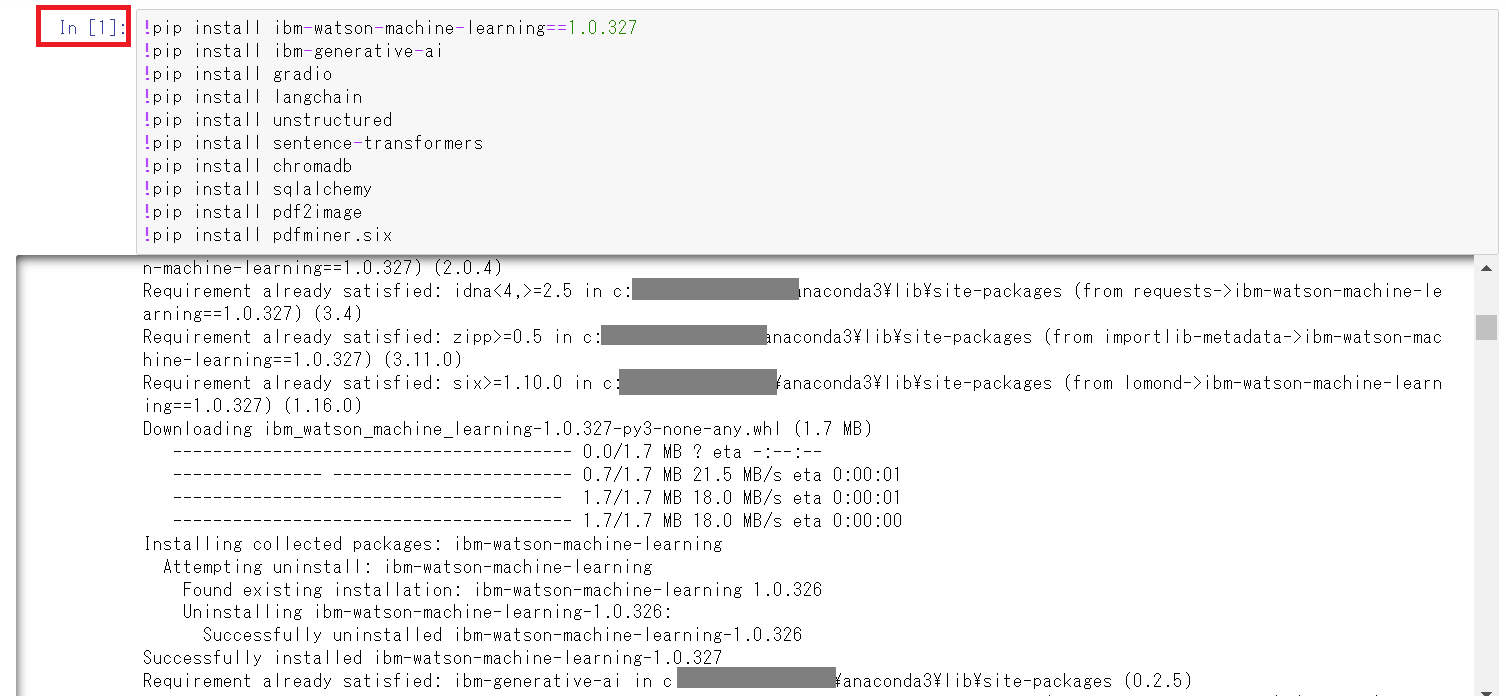
- セルの左箇所が [*] から [1] になると完了です。
特にエラーが出力されていないことを確認します。
認証情報をセットします。
- 先ほど取得した APIキーとプロジェクトID、エンドポイントの URL を指定します。
今回はダラスの Watson Machine learning を使用しているので、ダラスのエンドポイントを指定します。
※エンドポイントの URL は「IBM Cloud API Docs」から確認できます

- LangChain で使う Watson Machine learning のモジュールを複数インポートします。

一旦 LangChain 無しで watsonx.ai の言語モデルに質問をしてみたいと思います。
- まず、使用する言語モデルのパラメータを設定します。
以下に各パラメータの説明を記載します。
| パラメータ名 | 値の範囲例 | 内容 |
|---|---|---|
| MAX_NEW_TOKENS | 1~1000の整数値 | 一度に生成されるトークンの最大数を制御する。 |
| TEMPERATURE | 0.00~2.00 | 生成されるテキストの創造性を制御する。値が低いと予測可能なテキスト、値が高いと創造的なテキストを生成する。 |
| TOP_K | 1~100の整数値 | 各ステップで考慮されるトークンの数を制御する。 モデルは、トークンの確率分布から上位K個のトークンのみを考慮し、残りは無視する。 |
| TOP_P | 0.01~1.00 | 累積確率の閾値を設定する。モデルは累積確率がこの閾値を超えるまでのトークンのみを考慮しま |

- 質問する言語モデルをセットします。

- 質問をしてみたところ、正常に回答が返ってきました。

LangChainの作成
それでは、LangChain を作成していきます。
- LangChain に必要なモジュールをインポートします。

- pdfsフォルダにある PDF を読み込み、ベクターストアへ取り込みます。
ベクターストアへ取り込むみする際は LangChain で提供される intfloat/multilingual-e5-largeモデルを使用します。

- 言語モデルは Llama2 を使用します。
先程と同様にモデルの設定とパラメータを定義します。
Llama2 は回答指示を渡すことが推奨されているため以下の様に指示文を追加します。
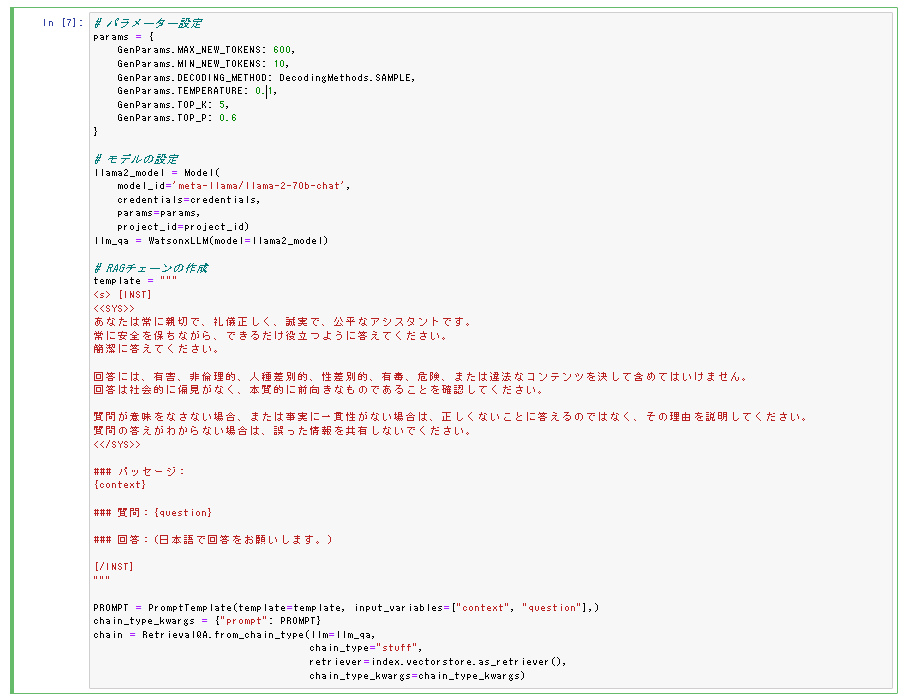
RAGを使って質問する
- PDF の内容を質問したところ、PDF から該当箇所を検索し回答が生成されました。
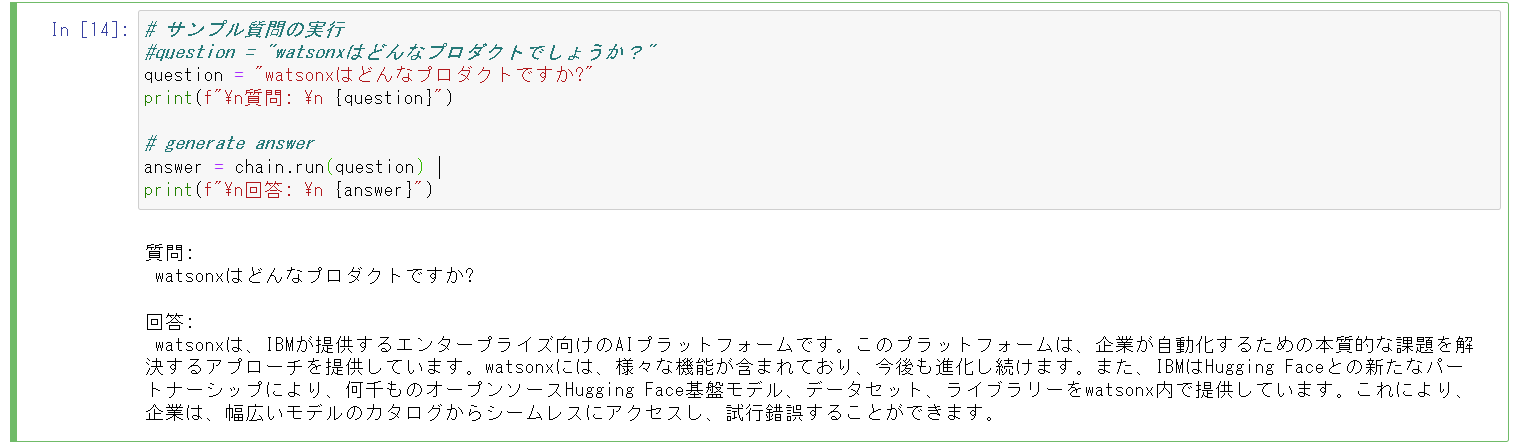
- ChatUI を起動して質問します。
また、PDF のどの箇所を参考にしたか出力するよう指示します。
(補足:ChatUIはPythonライブラリのGradioを使用)
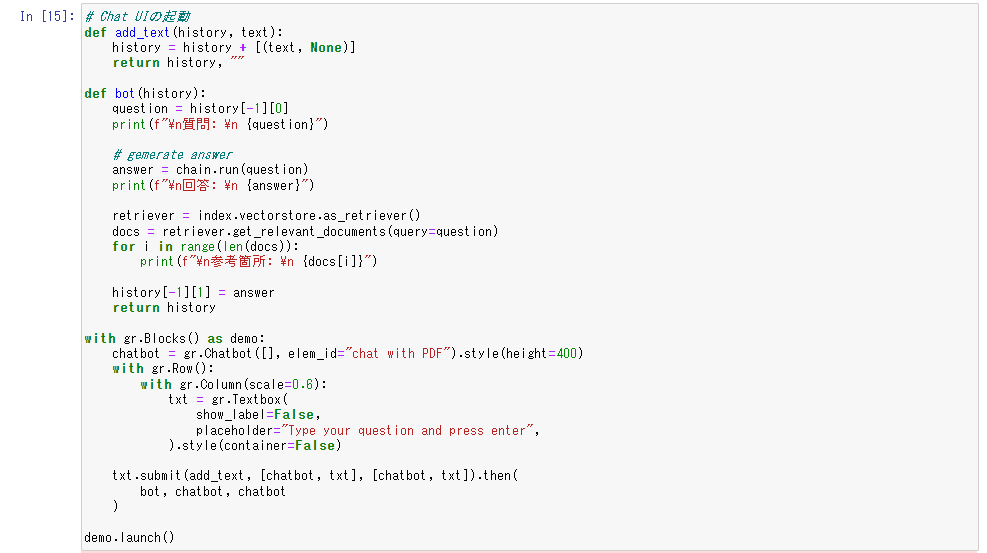
- ChatUI で質問してみました。
実用化したときのイメージが湧きますね。
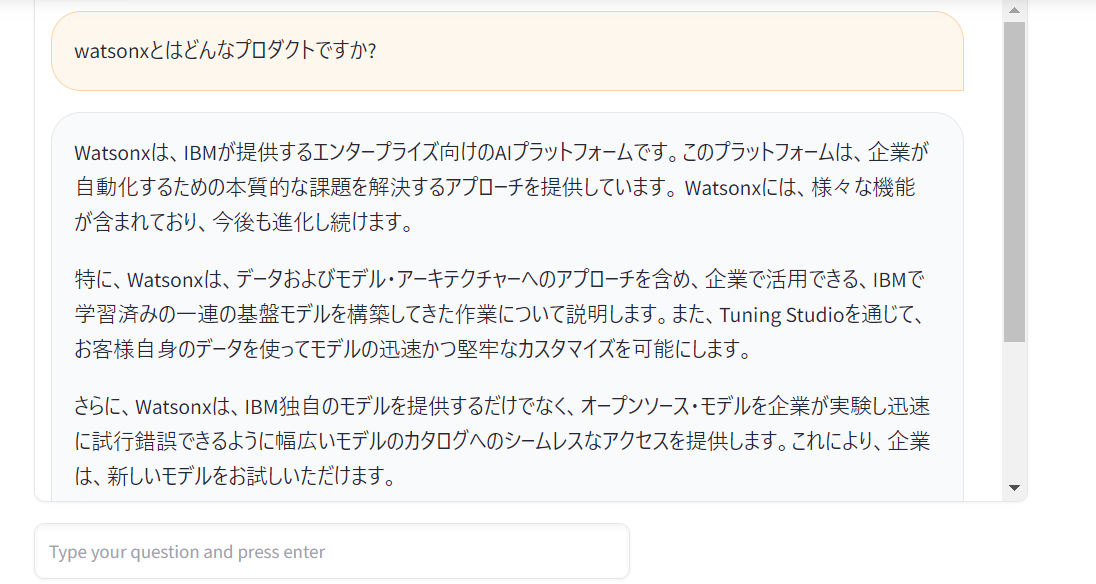
- PDF のどの箇所を検索したのか、参考箇所も出力されています。

以上が、watsonx.ai の言語モデルを利用した RAG検証です。
今回は1つの PDF で検証しましたが、回答まで30秒ほどかかりました。
複数の PDF を検索する場合はもう少し時間がかかりそうなので、実用するには調整が必要かもしれません。
さいごに
いかがでしょうか。
言語モデルに更新情報や専門的な情報をチューニングするのは手間がかかりますが、RAG を使えば、情報をベクターストアに格納して簡単に検索できます。
今回は PDF の内容を検索するものでしたが、テキストの内容や URL の情報も検索可能です。
また Google Colab を使えば、Googleドライブ上のフォルダ内の情報も検索できることが確認できています。
今回の検証で費用が発生した製品は watsonx.ai のみで、LangChain やベクターストアはオープンソースを利用しています。
それほどコストをかけずに実装できるため、社内の検索システムとして導入するなど取り掛かり易い点が魅力的だと思います。
本ブログを読んでいる方々の社内共有プラットフォームにも、RAG を用いた検索システムを導入できるかもしれません。ぜひ試してみてください。
“音声から情報を検索して回答を生成する” など、より高機能なシステムを検討している場合は、watsonx Assistant や Watson Discovery と連携することで実現可能です。
ソリューションの詳細は個別にご説明いたしますので、お問い合わせください。
2024年2月頃、日本語で訓練された言語モデル「Granite」の提供が予定されています。
Llama2 などの言語モデルも日本語の回答は可能ですが、日本語の精度は保証されていません。そのため、新たな「Granite」モデルの提供により、日本国内で watsonx.ai の実用化が進むことを期待しています。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp