- シェア
-

【てくさぽBLOG】IBM watsonx.aiを使ってみた(Part1)
こんにちは。
てくさぽBLOGメンバーの高村です。
IBM の定例イベント「Think 2023」で発表された IBM watsonx はご存じでしょうか?
AI開発の最前線を走り続けている IBM Watson は、2023年7月に企業向けAI及びデータ・プラットフォーム IBM watsonx(以下 watsonx)のサービス提供を開始しました。
なお、watsonx の概要は製品紹介ページで紹介していますので、是非ご覧ください。
今回は watsonx製品の一つ、生成AI開発プラットフォームを担う「IBM watsonx.ai」(以下 watsonx.ai)を使用し、その感想を二部構成でご紹介したいと思います。
Part1(本記事)では、watsonx.ai のご紹介とサービスのプロビジョニング、UI画面にてプロンプトを使ってみた感想を、Part2では、watsonx.ai を利用した Retrieval-Augmented Generation(RAG)検証をご紹介します。
乞うご期待ください。
ビジネスにおける生成AIの活用
2022年の ChatGPT公開を機に生成AI は脅威的なスピードで生活に普及されています。
企業も生成AI をビジネスに取り入れる動きが加速しており、例えば、OpenAI社は企業向けに ChatGPT Enterprise、Microsoft社は Azure上で Azure OpenAI Service を提供しています。
このように企業向け生成AIサービスも次々発表されている状況で、企業はビジネスの目的に合ったサービスを選ぶことが重要になってきています。
それでは、生成AI を採用する際にどのような考慮点があるでしょうか。
以下にいくつかご紹介します。
生成AI採用時の考慮点
- 回答精度の問題:
生成AI は状況や文脈を完全に理解しておらず、適切な回答を生成することが困難となる場合があります。
そのため、モデルのチューニングや精度の高い回答を出せるように指示を設計する仕組みが必要です。
- 他社との差別化:
今後多くの企業が生成AI を活用したビジネスを展開していくと、他社との差別化がますます重要となります。
ベンダー独自の大規模言語モデルを利用することは勿論ですが、AI開発の先駆者であるサード・パーティーが提供するモデルを利用できることなど、複数のモデルから選択できる点もポイントになります。
- セキュリティ対策:
ビジネスで生成AI を活用する上では機密情報の取り扱いを注意しなければいけません。
個人情報を含んだ情報が他のユーザの回答に利用されることが無いよう、セキュリティ対策が求められます。
このように、企業が求める精度の高い AIモデルを実現でき、他社との差別化及び生産性向上を図ることが可能なサービスが watsonx.ai です。
watsonx.aiとは?
サービス提供形態
はじめにサービス提供形態をご紹介します。
2023年10月時点、watsonx.ai は IBM Cloud からの SaaS提供のみとなっています。
また、watsonx.ai を利用するには従来から提供されている Watson Studio(機械学習モデルを開発するための統合環境)と Watson Machine Learning(機械学習環境)の2つのサービスが必要です。
IBM Cloud のカタログ上では「watsonx.ai」という名前のサービスは無く、Watson Studio をプロビジョニングし Watson Machine Learning を紐づけることで、watsonx.ai が利用できるようになります。
料金は Lite/Essentials/Standard のプランが提供されています。(2023年10月時点)
Lite は容量制限のある無料プランです。機能を試したい場合はこのプランをご選択ください。
Essennsials、Standard は以下の①②③を合計した料金プラン(月額請求)です。
①プランの基本料金 ※Essentials の基本料金は$0/月です(2023年10月時点)
②基盤モデルの利用料
③Watson StudioとWatson Machine Learningの利用料
watsonx.aiの特徴
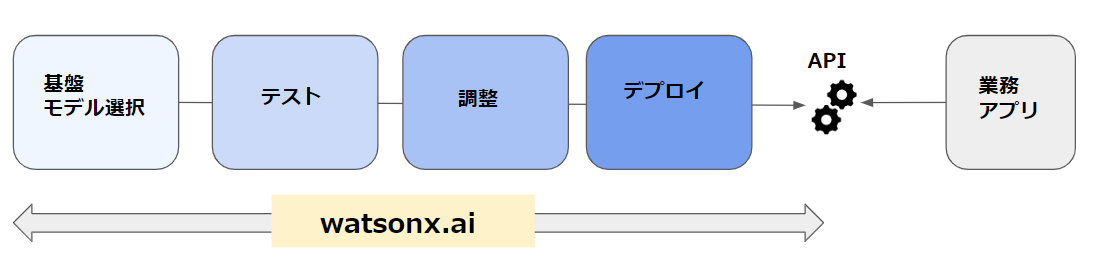
以下の図の通り、watsonx.ai は基盤モデルの選択から調整、テスト、デプロイまでを一貫して行うことができる AI開発スタジオです。
基盤モデル(Foundation Model)
watsonx.ai は基盤モデル(Foundation Model)を利用した AI開発スタジオです。
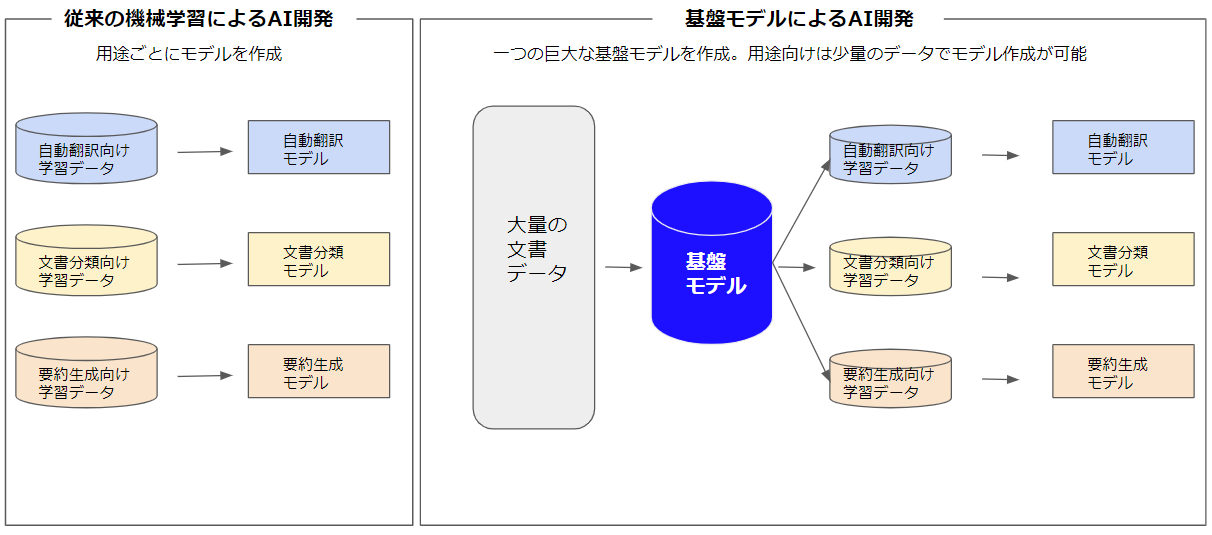
従来の機械学習による AI開発は用途ごとにモデルを作成していましたが、基盤モデルによる AI開発は大量のデータで事前学習を行い、一つの基盤モデルを作成し、用途別に少量のデータでカスタマイズしモデルを作成します。
これにより用途向けのモデルは少量のデータで学習が可能となり、今までのような学習時間やリソースを大幅に削減できます。
IBM独自の基盤モデル、サード・パーティーの基盤モデルを提供
watsonx.ai は IBM独自の基盤モデル、サード・パーティーのモデルを提供しており、用途によって選択することは勿論、最先端な技術をサービスに取り入れることが可能です。
2023年10月現在、IBM独自の基盤モデルは2つ、Hugging Face などのサード・パーティーの基盤モデルは7つ提供されています。
詳細は「watsonx.ai で使用可能なサポート対象のファウンデーション・モデル」(IBMサイト)をご確認ください。
プロンプト・ラボ
watsonx.ai では抽出や生成、分類などのタスクをプロンプトラボで調整します。
プロンプトラボには最大トークン数などのパラメータを調整する機能やサンプルプロンプトも提供されており、迅速なデプロイが可能です。こちらは後ほど試してみようと思います。
今後基盤モデルのチューニング・スタジオも提供予定です。アップデートが楽しみですね。
プロンプト・ラボを使ってみる
watsonx.ai をプロビジョニングし、UI画面からプロンプト・ラボを使用してみましょう。
(※前提としてIBM Cloudアカウントが作成されていることとします)
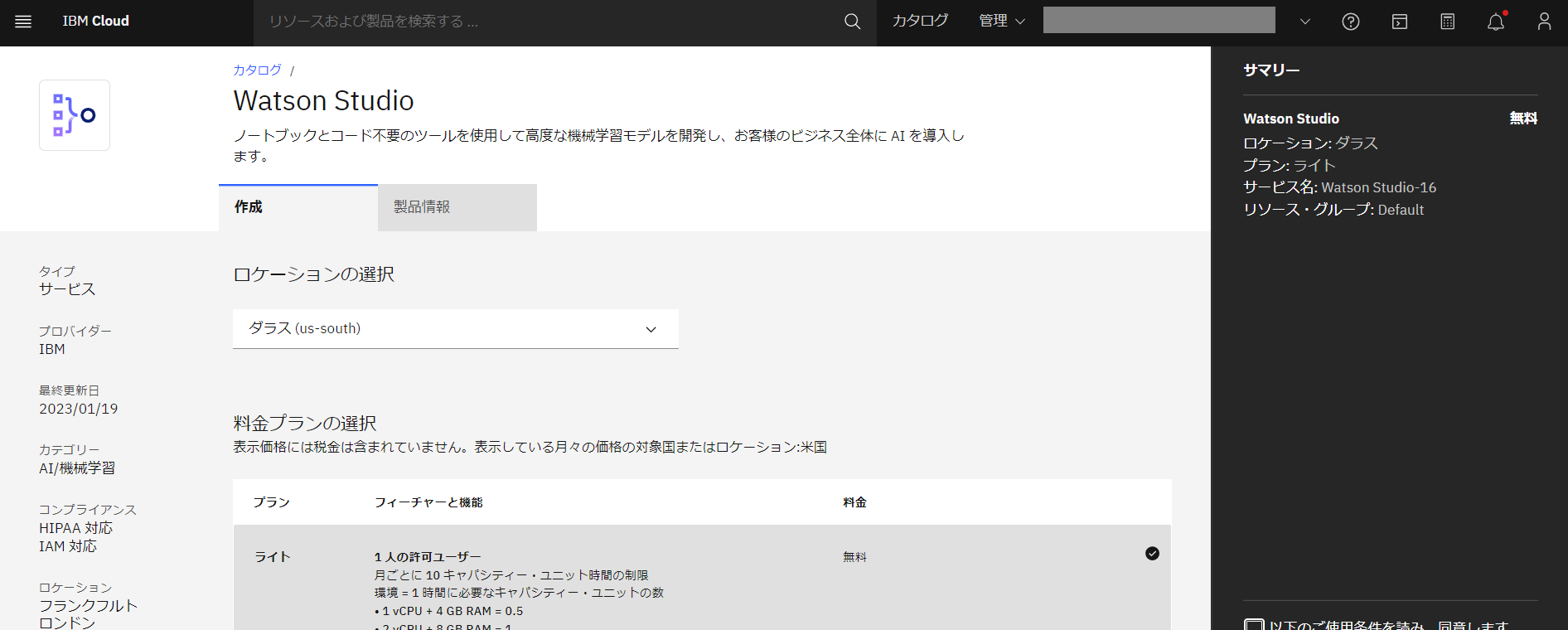
- IBM Cloud のカタログ画面から「Watson Studio」を検索し、クリックします。

- 料金プランはライトプラン、ロケーションは「ダラス(us-south)」を選択します。
※基盤モデルの推論とプロンプト・ラボはダラスとフランクフルトのリージョンでのみ使用可能
- 以下の画面が表示されるので「Launch in」をプルダウンしてプラットフォームを「IBM watsonx」にします。
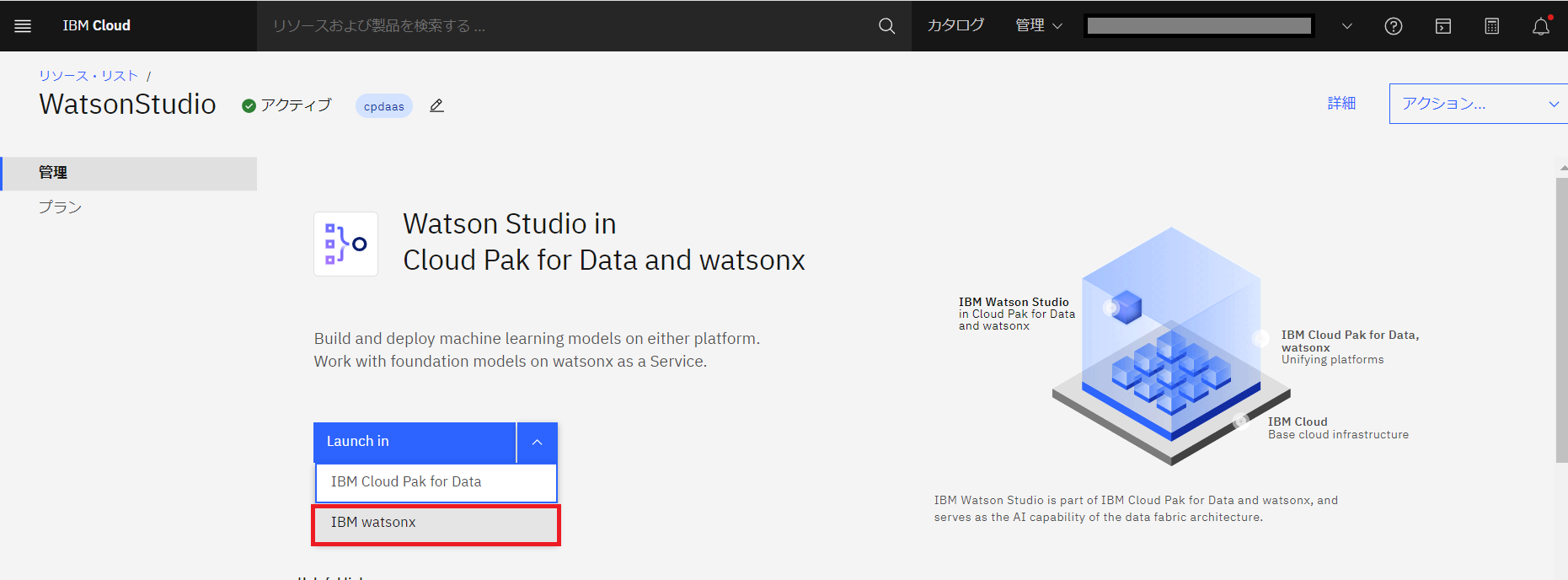
- 以下の画面が表示されるので閉じます。

- 以下の画面が表示されるので閉じます。

- 以下の画面で「新規プロジェクト +」をクリックします。
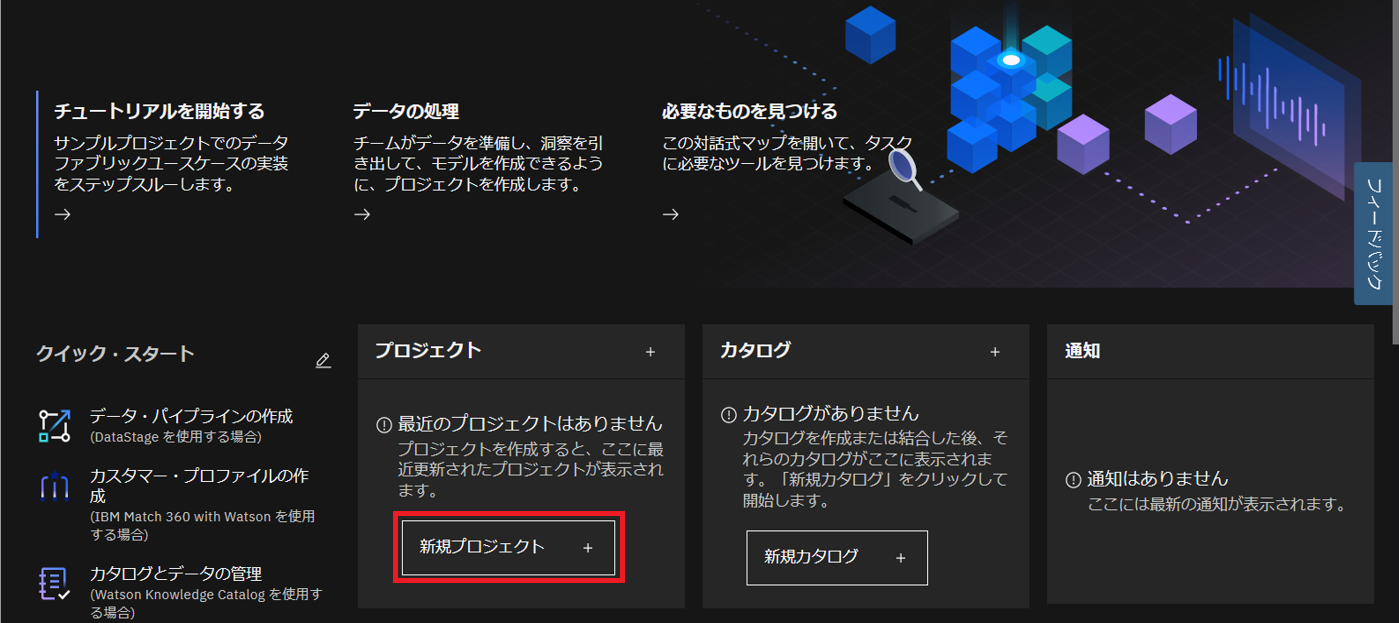
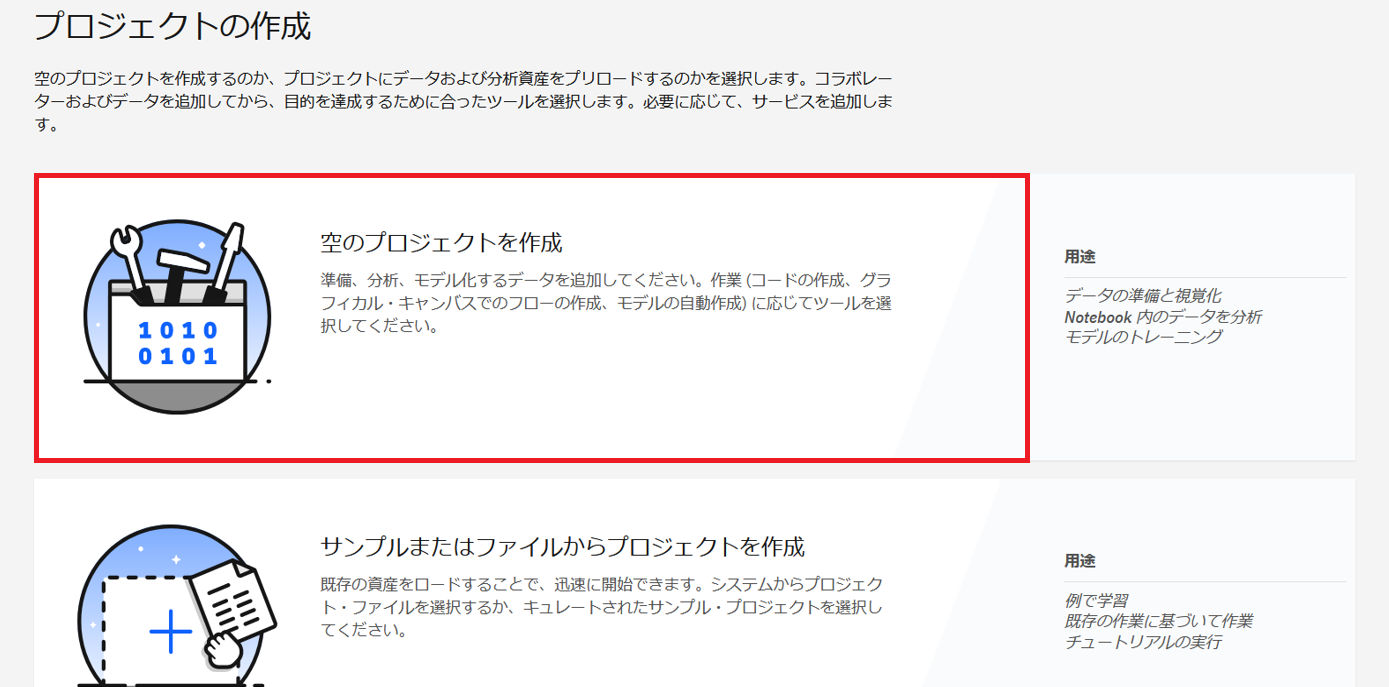
- プロジェクト作成画面で「空のプロジェクトを作成」をクリックします。
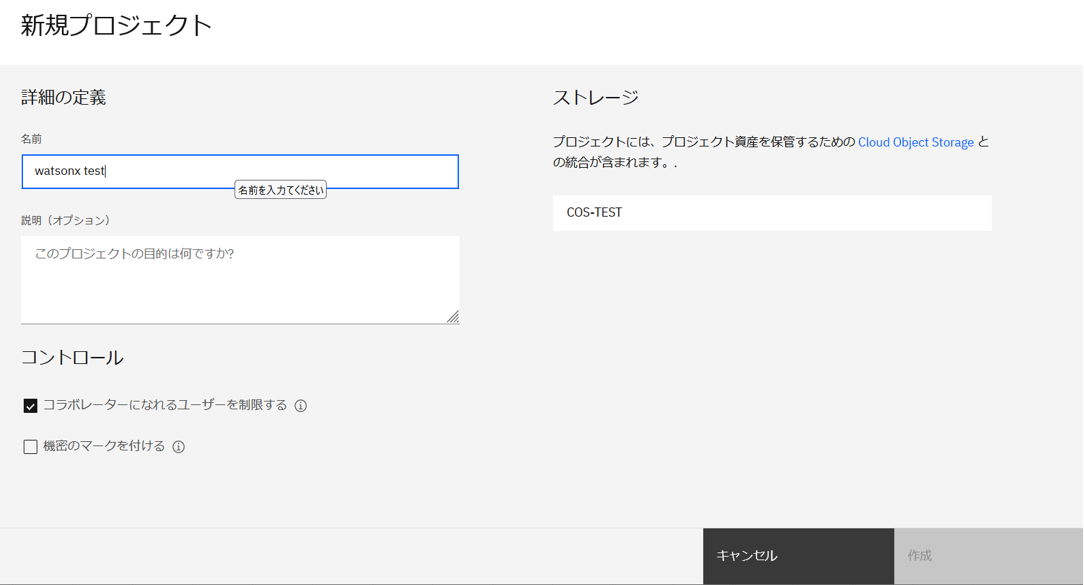
- 新規プロジェクト作成画面で任意の名前を入力し「作成」をクリックします。
- プロジェクトが作成されました。
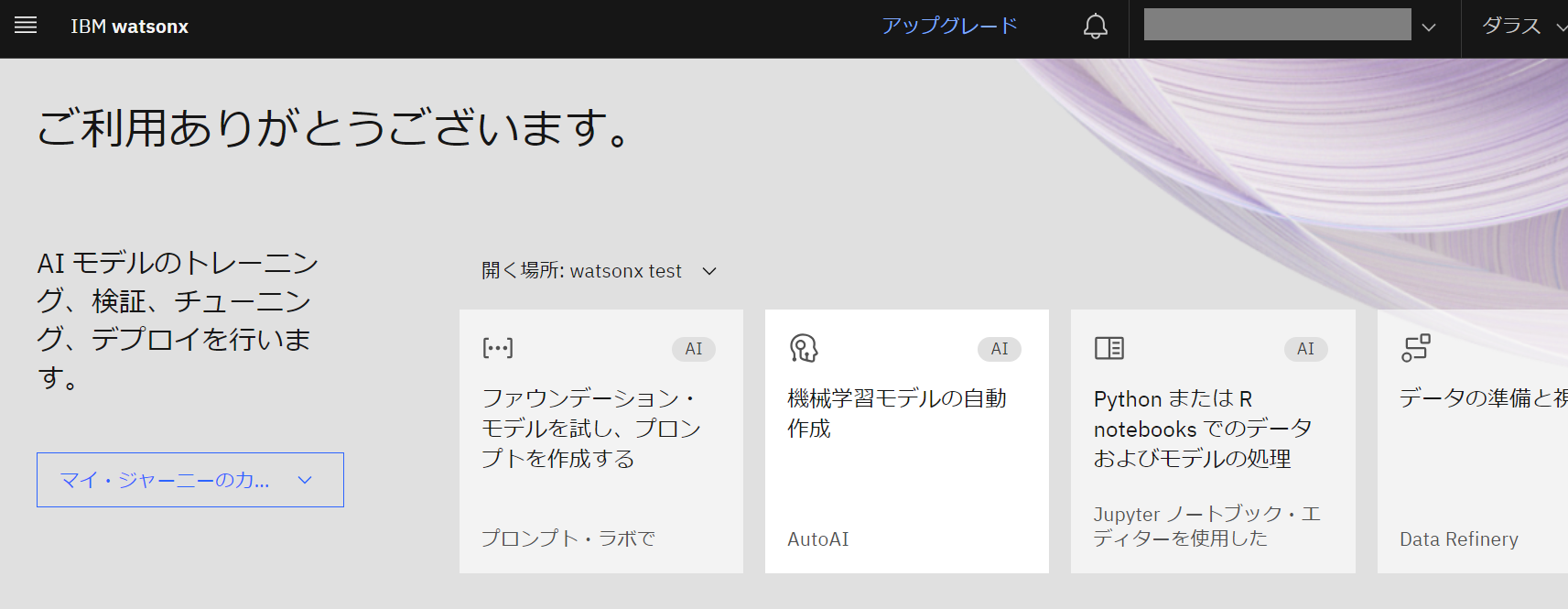
- 左側メニューから「すべてのプロジェクトの表示」をクリックし、作成したプロジェクトを選択します。
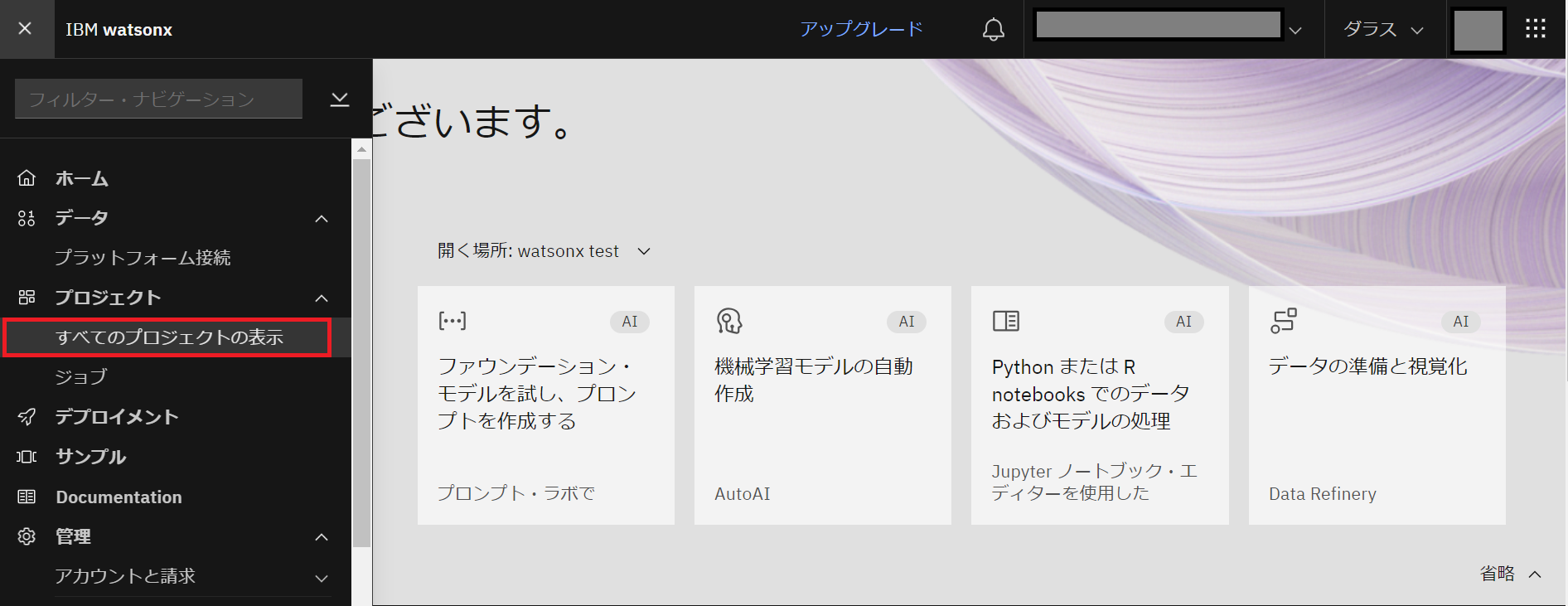
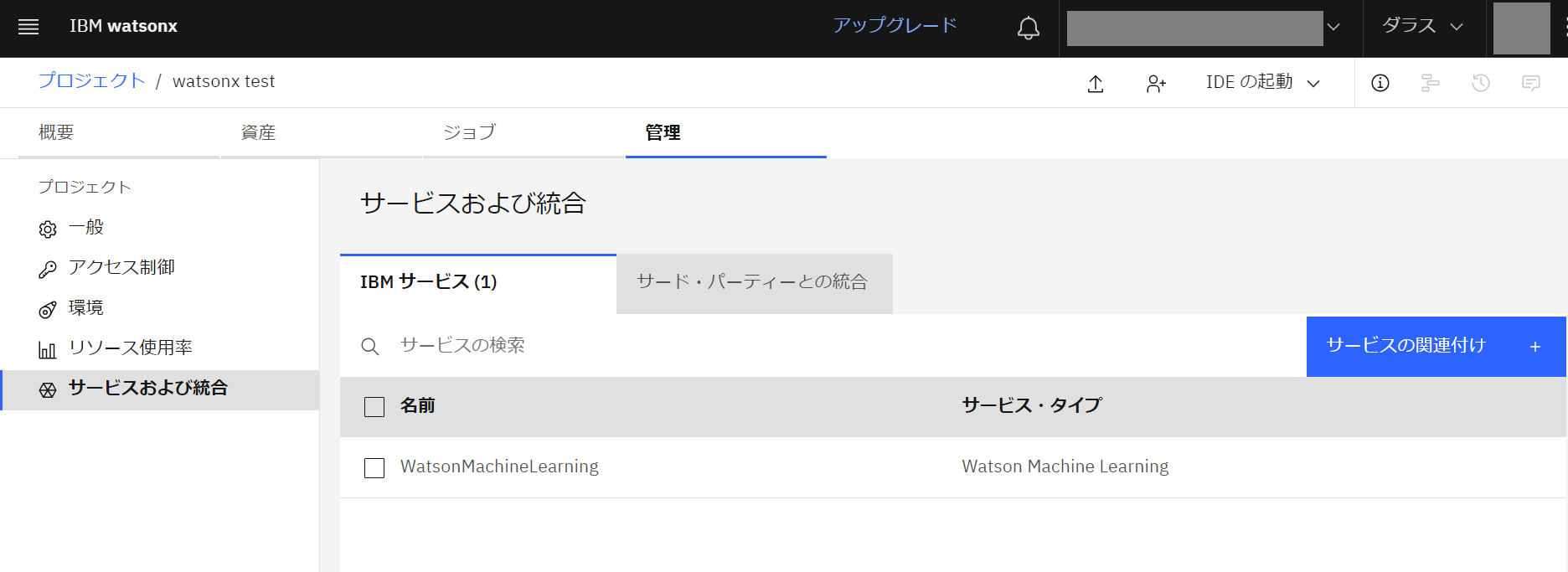
- 「サービスおよび統合」を選択し「サービスの関連付け +」をクリックします。
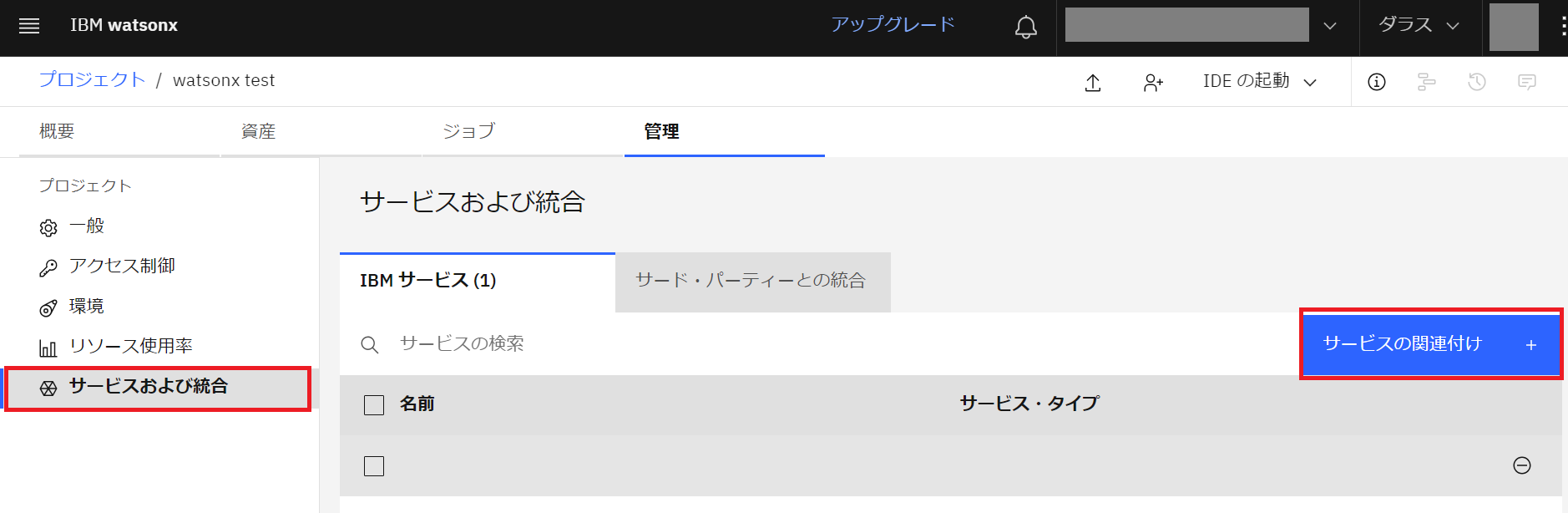
- 「Watson Machine Learning」にチェックを入れサービスを関連付けます。
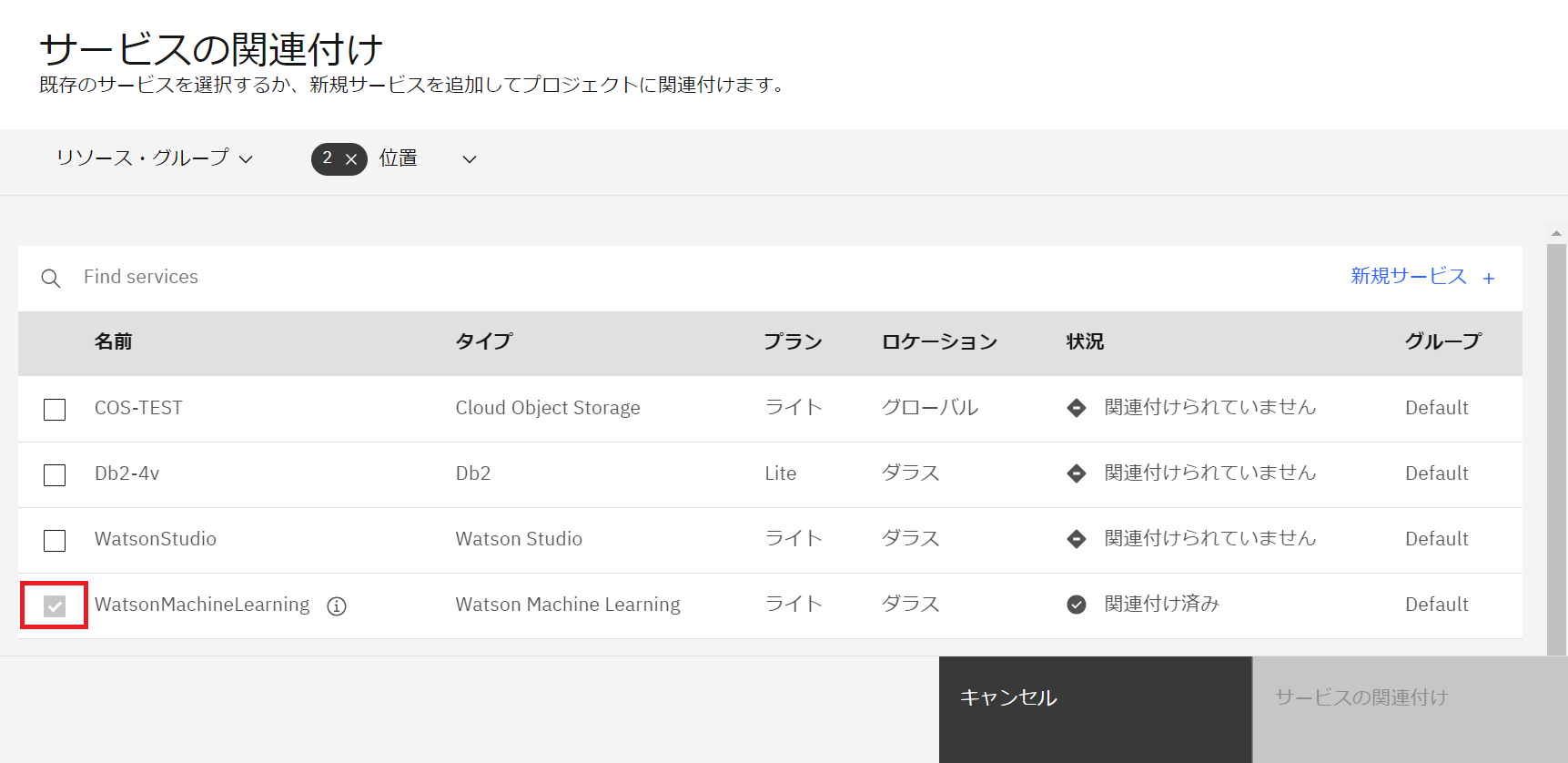
- Watson Machine Learning が関連付けられました。
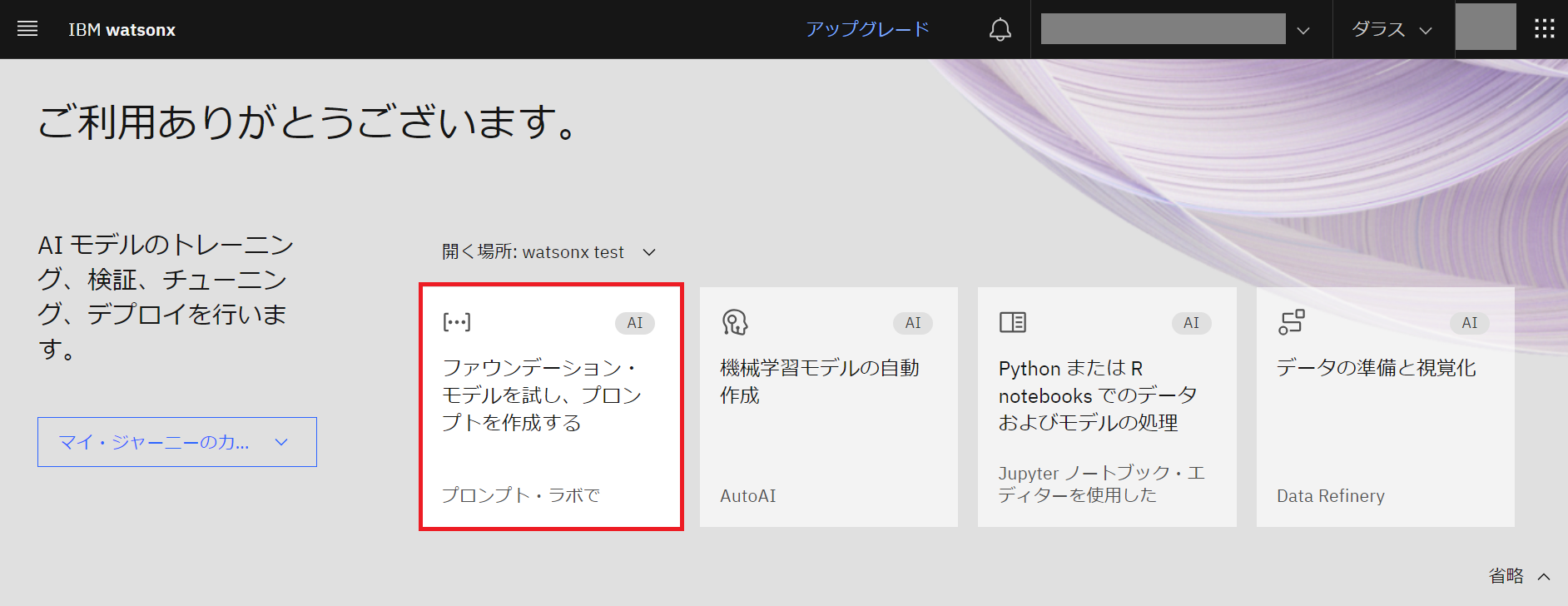
- ホーム画面に戻り「ファウンデーション・モデルを試し、プロンプトを作成する」をクリックします。
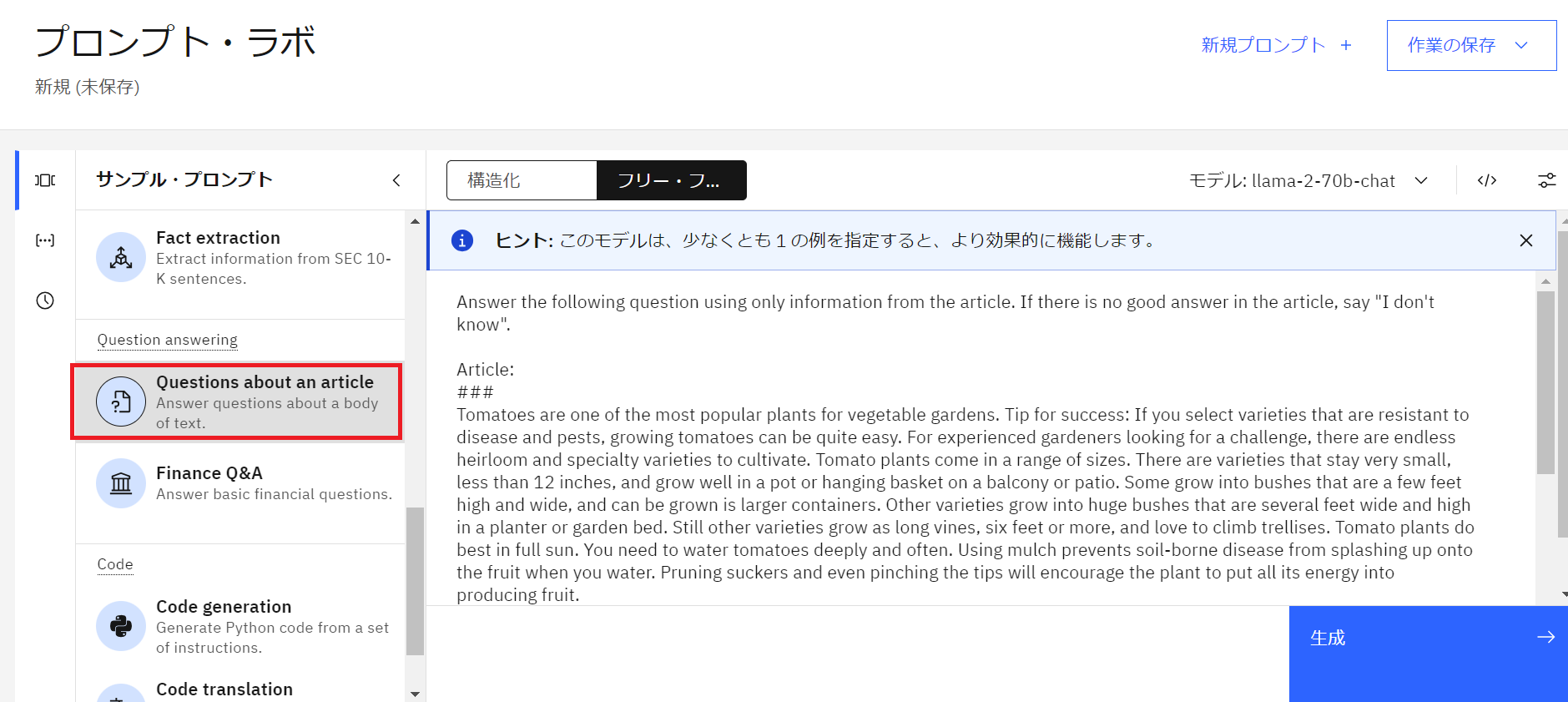
- サンプル・プロンプトから「Questions about an article」を選択し、命令箇所に命令と対象のArticleを入力します。
(今回はサンプル・プロンプトを使用してみます)
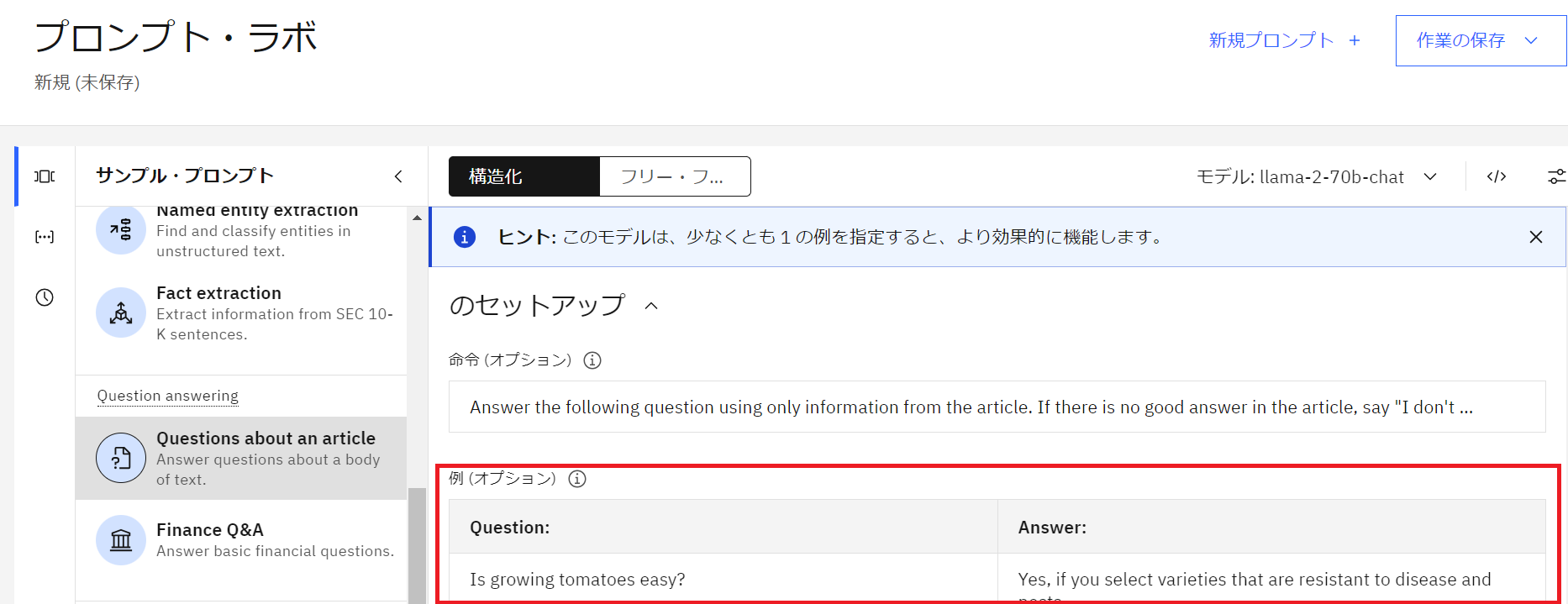
- 「llama-2-70b-chat」は一つ以上の例を指定するとより効果的に機能するため、例の箇所に QuestionとAnswer の例を入力します。
(このプロンプトは基盤モデル「llama-2-70b-chat」を指定しています)
- Question へ「トマトの栽培になぜマルチを使用すべきなのか」と入力し「生成」をクリックします。
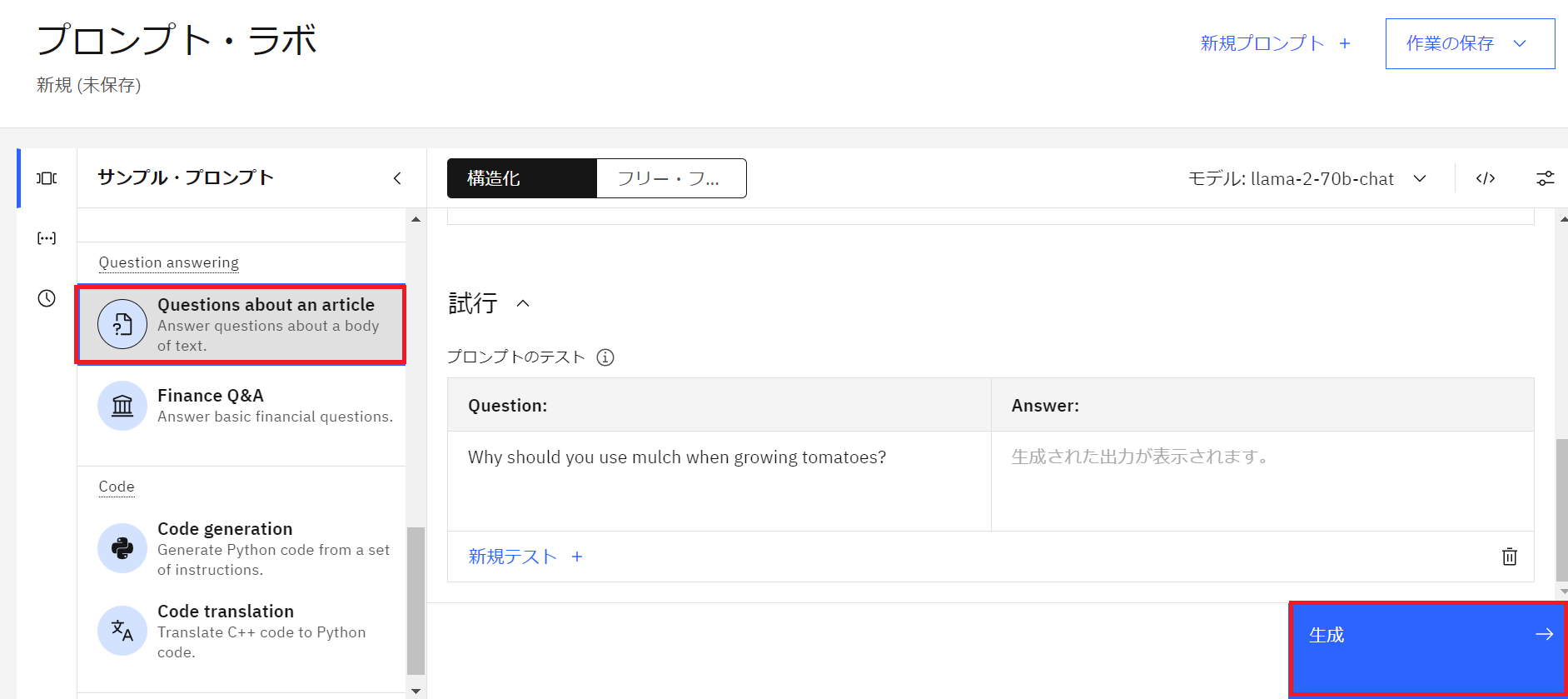
- Answer の箇所に回答が生成されました。
(原文と照らし合わせると、適切な箇所を参考にして生成していることがわかります)
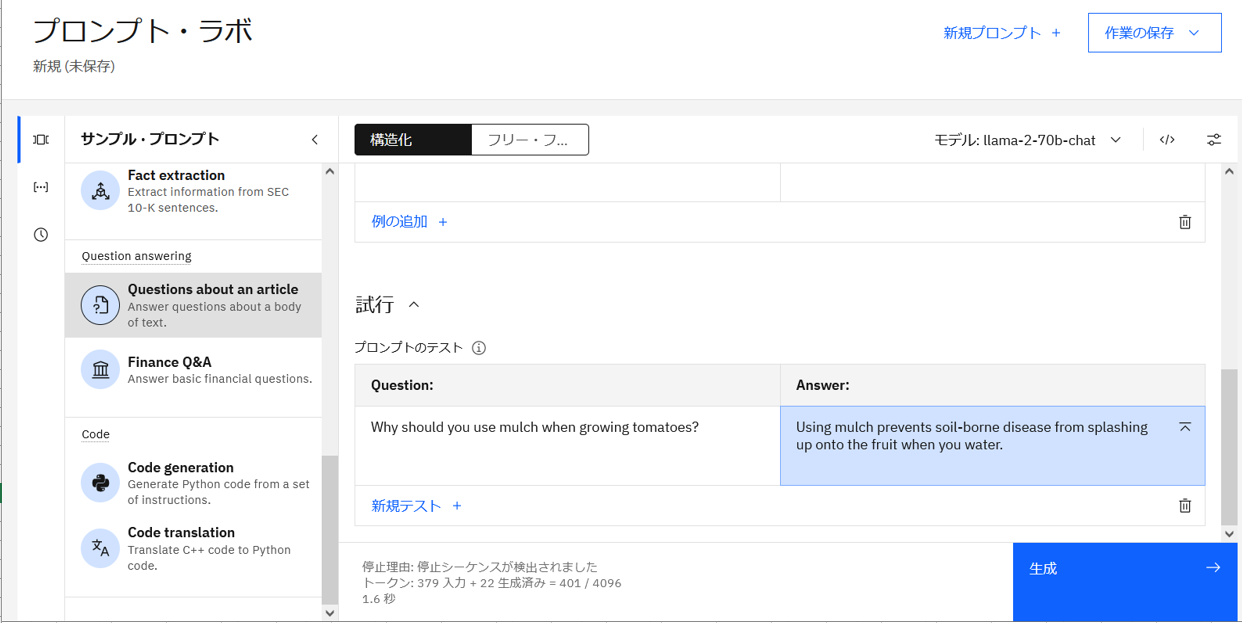

- なお、「モデルパラメータ」をクリックすると最大トークン数などのパラメータ調整もすることが可能です。

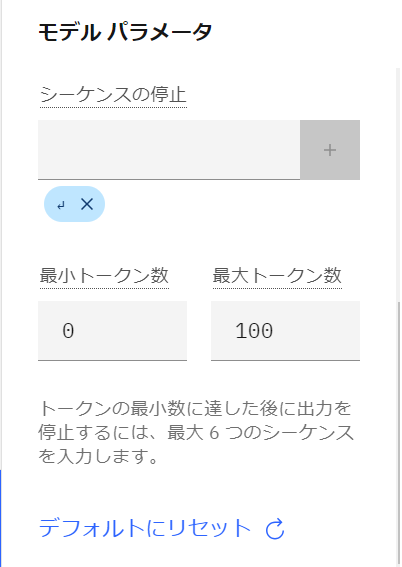
UI画面もわかり易く、サンプルをベースに目的のプロンプトを作成できそうです。
他にもコールメモの要約やコード生成などのサンプル・プロンプトがありますが、ここでのご紹介は割愛させていただきます。
基盤モデルは IBM独自の基盤モデルやオープンソースの基盤モデルが選択できますが、どれを選べばよいのか迷うところです。
基盤モデルを選択においては「watsonx.ai でのファウンデーション・モデルの選択」(IBMサイト)に考慮点が掲載されていますので、こちらを参考に選択いただければと思います。
さいごに
いかがでしたでしょうか。
watsonx.ai のご紹介とサービスのプロビジョニング、UI画面にてプロンプトを使ってみた感想をご紹介しました。
watsonx.ai には複数の基盤モデルが用意され、今後基盤モデルのチューニングスタジオもリリース予定されています。
目的にあったモデルの選定、検証は考慮が必要ですが、カスタマイズの幅が広く、ビジネスの目的にあったAIモデルを実現できますね。
次回の Part2 では、watsonx.ai を利用した Retrieval-Augmented Generation(RAG)の検証結果をご紹介します。
watsonx.ai をビジネスにどのように繋げられるかのヒントになると思いますので、ぜひご覧いただければ幸いです。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp