- シェア
-

【てくさぽBLOG】IBM Power10メモリの秘密
皆様こんにちは。
エヌアイシー・パートナーズ てくさぽBLOGメンバーの佐藤です。
IBM Power10サーバー、大変好評をいただいております。
今回は Power10 の重要な改良ポイントの一つであるメモリの技術について、DDRメモリの限界と問題点を交えながら深堀していきます。
DDRメモリの限界
DDRメモリは業界標準のメモリです。
スマートフォンから PC、サーバーまで広く採用されています。世代を重ねるごとに高速化されており、最新は DDR5メモリとなります。
Power9 でも DDR4メモリインターフェイスを採用していましたが、Power10 からは OpenMemoryInterface(以下 OMI)インターフェイスに変更されました。
DDR の問題点はメモリチップ自体というより、そのやり取りである “パラレル信号” にあります。
パラレル信号においてより高速なメモリアクセスをするためには、信号数を増やすかクロックを上げるほかありません。これ以上の信号数を増やすことは容易ではない為、世代ごとにクロックの高速化を行ってきました。
しかしながら、クロックの高速化に伴って問題が発生しています。特にこの問題はサーバー製品において顕著で、限界に達しつつあります。
パラレル信号の等長性
パラレル信号は等長である必要があります。
すべての信号が同時並列にメモリと CPU の間を行ったり来たりします。
メモリと CPU の端子の距離は端子やソケットの物理位置によって異なるため、マザーボード上のメモリ配線は蛇行し複雑なパターンを描いています。
さらに世代を追うごとに配線長の制限も厳しく、CPUとメモリの間配線はできるだけ最短でかつ同じ長さである必要があります。
これによってマザーボードのレイアウト設計は非常に制限が多く、世代を追うごとに複雑さが増している状態です。
メモリチャンネル
クロックを上げるほど配線はシビアになるため、クロックは簡単には上げられません。
しかしながら1ソケットあたりの CPUコア数は増加の一途をたどっているため、メモリ帯域は必要です。
そのため、これまでは同時アクセス可能なメモリチャンネル数を増やし、2チャンネル、4チャンネル、6チャンネル、8チャンネルとチャンネル数を増やしてきました。
DDRメモリの課題
1. スペース&価格
メモリチャンネル数を増やすとマザーボード上の配線が増えます。
サーバー製品ですと障害時の交換を考慮するとラップトップパソコンのようにマザーボード上に直接メモリチップをマウントすることは難しく、結果として大量のメモリソケットがマザーボード上のスペースを占拠し、配線のための多層基板がマザーボード価格を押し上げています。
CPU とメモリソケットのレイアウトにも制限があり、一般的な19インチラックでは16チャンネルメモリ、2ソケット、32メモリソケット/ノードが限界になります。
2. 高速化が難しい
PCIe と DDR の新しい世代はほぼ同時期のリリースで、最新は PCIeGen5 と DDR5 です。
過去も含めて比較すると、基本的に同一世代の PCIe が DDRメモリの転送速度を上回っているということが分ります。
この点が、DDRメモリが抱える課題のひとつと言えるでしょう。
※出典:「転送速度」(ウィキペディア)
OMIのメリット -DDRメモリの課題を解決するには?-
ここから OMI の話に移ります。
優れた生産性がありながらも制限の厳しいパラレル転送方式の DDRメモリですが、シリアル化すれば、高速転送が可能となり非常に使い勝手がよくなります。
具体的には、SoC を通した DDRメモリチップのシリアル変換です。
以下にそのメリットを紹介します。
1. 省スペース化
Power10 に採用されている OMIメモリは物理的に非常に小型です。
これは、シリアル化によってピン数を減らすことができたためです。
DDR4 ではメモリ1枚あたり72本、DDR5 では80本もの配線が必要ですが、OMI ではディファレンシャル信号で 8Bitのため、たった16本の配線で済みます。

図1:Power10のOMIメモリ
(一般的なDDRメモリと比較すると端子部分は非常に小さくメモリチップレイアウトの自由度が高い)
結果的に、Power10 E1080モデルでは標準的な19インチラックサイズにもかかわらず4ソケット構成で、かつそれぞれ16チャンネルメモリを実現しています。

図2:Power10 E1080モデルの内部構成
(中央CPUソケット右がメモリソケット、32ソケットに見えるが、左右にソケットがある)
2. 高速化
メモリソケットの物理サイズが小型化し少ない配線で済むとなるとどうなるでしょうか?
メモリチャンネル数の増加による高速化が可能になります。
他社の CPU では最新世代であっても8チャンネルメモリが限度で、DDR4 3200 の8チャンネルでは最大転送が約200GB/s、発表されたばかりの DDR5 4800 の8チャンネルですら最大転送は約300GB/sです。
Power10 は16チャンネルメモリのため、現時点で最大転送は約400GB/s、双方向では約 800GB/s にもなります。
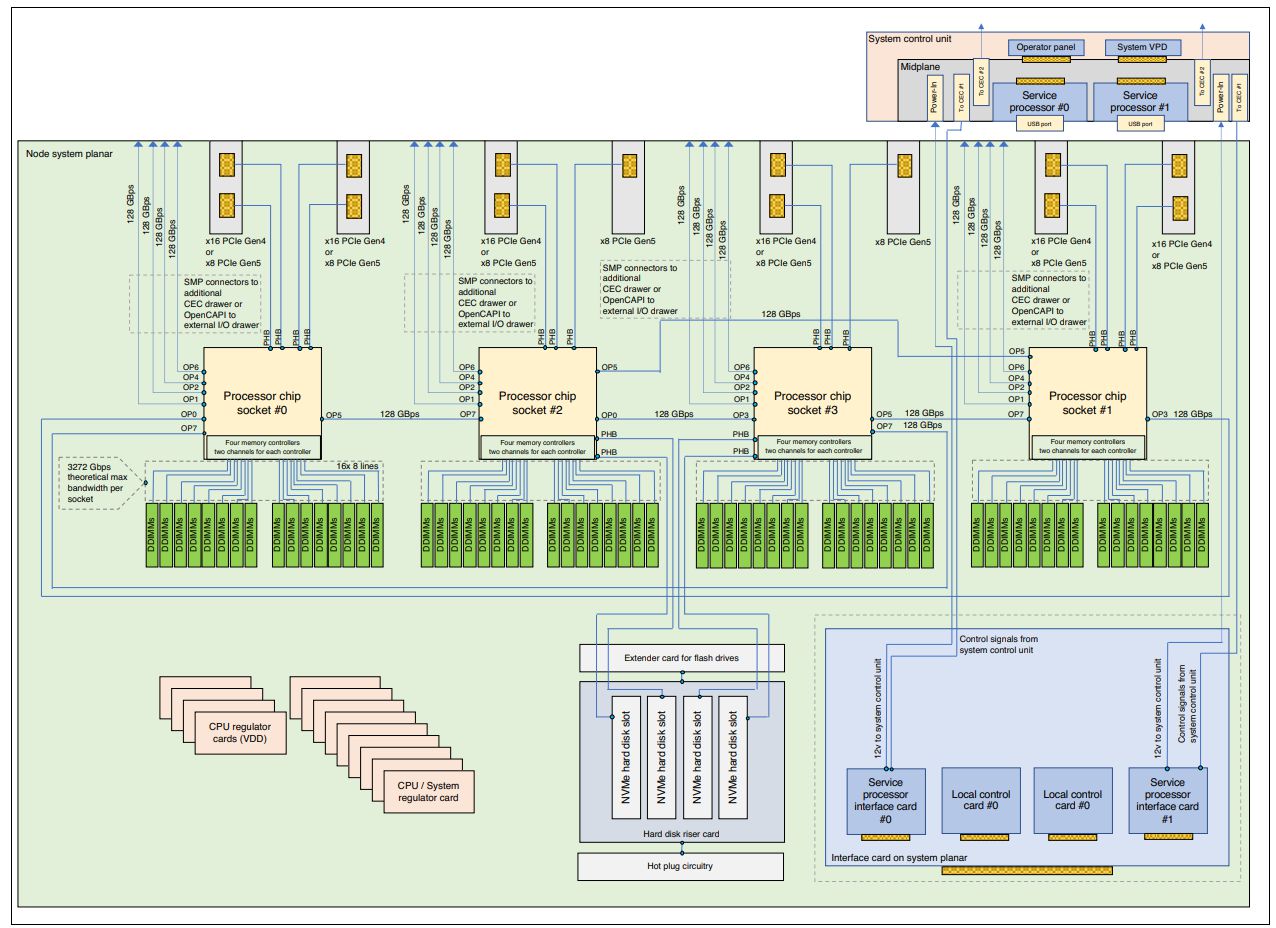
図3:Power10 E1080モデツのブロック図
(3272Gbps theoretiacal max bandwidth per socket, 16チャンネルメモリ×4ソケットというのは驚異的)
3. 高可用性
シリアル化した際のメリットとして、レーン転送があります。
転送経路にエラーが発生した場合、縮退して動かすことができます。
OMIメモリは通常25Gbps×8レーンで動作しますが、縮退して×4レーンでの動作もサポートされています。
4. 暗号化
SoC を経由してデータを書き込むため、データの暗号化が可能です。
クラウドが増えてきた今、仮想化されたメモリ空間のとなりは攻撃者となりえます。
サイドチャネル攻撃は直接的な該当区画への攻撃ではなく、攻撃者自身のメモリ空間に対し、特定パターンでの書き込みにより隣接したメモリ空間を予測する攻撃です。
そのため、通常のセキュリティ対策では防ぐことができません。
パスワードは HDD や SSD上では暗号化されますが通常メモリ上では平文で展開されるため、メモリ暗号化はこのような攻撃に非常に有効な対策です。
5. 将来性
OMI のメリットはそれだけではありません。
現在は DDR4メモリのみですが、メモリーコントローラーチップが対応すれば DDR5 や GDDR といったより広帯域のメモリに対応することが可能です。
現在の OMI の帯域は1レーンあたり25Gbpsのみですが、Power10自体は32Gbpsも対応しており、CPUとして最大で512GB/s、双方向では1024GB/sに対応しています。
将来の拡張にも対応可能なインターフェイスと言えます。
最後に
報道発表の通り、OMIメモリを推進していた OpenCAPI は Compute Express Link(CXL)に譲渡されました。
今後 CXLメモリとして OMI と同様のメモリが登場する可能性はありますが、2023年現在、CXL に対応した CPU は登場していません。
OMIメモリは従来の DDRメモリの制限を開放し、省スペース化、高速化、高可用性、暗号化を実現しているメモリです。
現在、この優れた性能を提供できるのは Power10 のみです。
※出典:「CXL Consortium and OpenCAPI Consortium Sign Letter of Intent to Transfer OpenCAPI Specifications to CXL」(computeexpresslink.org)
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp