- シェア
-

【早わかり】IBM Cloud Object Storageを見積してみよう
こんにちは、エヌアイシー・パートナーズ高村です。
今回の【早わかり】ではIBM CloudサービスのIBM Cloud Object Storageの見積方法をご紹介したいと思います。
冒頭から余談ですがIBM Cloud Object Storageは”IBM COS”や”ICOS”と略されるようです。資料などを検索するとIBM COSと略す資料が若干多かったので、このブログではIBM COSと記載します。
IBM COSの概要
まずはじめに、簡単にIBM COSのご紹介です。IBM COSはオブジェクトストレージといわれるストレージになります。オブジェクトストレージとはその名のとおり、データをオブジェクト単位で扱うストレージです。よく耳にするストレージとしては、ブロックストレージ、ファイルストレージがありますので表にまとめてみました。
ブロックストレージ
| データ保存方法 | 記憶領域を論理ボリュームという単位で分割、さらに内部を固定長のブロックに切り出し、そのブロックにデータを保存 |
|---|---|
| プロトコル | FC、SCSI、iSCSI、FCoE |
| 主なIBM製品 | IBM SpectrumVirtualize (Flash System製品など) |
ファイルストレージ
| データ保存方法 | フォルダ、ディレクトリといった形式で階層的に管理、保存 |
|---|---|
| プロトコル | CIFS、NAS、FTP |
| 主なIBM製品 | IBM Spectrum Scale、IBM Elastic Storage System |
オブジェクトストレージ
| データ保存方法 | データ・ファイルをオブジェクトと呼ばれる断片に分割し、それらのオブジェクトを単一のリポジトリーに保存 |
|---|---|
| プロトコル | HTTP/HTTPS(REST API) |
| 主なIBM製品 | IBM Cloud Object Storage |
ファイルストレージはディレクトリごとの保存サイズに上限がありますが、オブジェクトストレージは階層のないフラットな空間に保存されるので大量のデータ保存に向いていますね。
IBM COSの特徴
IBM COSですが、主な特徴をご紹介します。
1.多様な提供形態
IBM Cloudサービスでの提供とオンプレミス環境で利用可能です。オンプレミス環境ではSoftware Defined Storageまたはアプライアンス製品がございます。例えばバックアップストレージはIBM CloudサービスのIBM COSを使用するなどハイブリッドでのご利用も可能で、お客様のニーズにあった提供形態を選択することができます。
2.高い信頼性、可用性
Information Dispersal Algorithm(IDA:情報伝播アルゴリズム)という技術により、保存データ容量を抑えるとともに、データを強固に守ります。またIBM Cloudサービスでのご利用ですが、レジリエンシーオプションの選択によってリージョンを超えてデータを複数のデータセンターに分散格納する”クロスリージョン”、同一地域内にある複数のデータセンターに分散する”リージョン”のオプションを選択でき高可用性を実現しています。
3.コスト削減
IBM Cloudサービスの場合、1GB/月から使える安価な従量課金モデルとなっています。また4つのストレージクラスがあり、特にSmart Tierは毎月のアクセスを追跡し 3つの価格設定(Hot、Cool、Cold)から1カ月の使用量に応じた料金を算出します。これは変更が頻繁に起こるワークロードや予測しづらいワークロードに有用で、コスト最適化を実現できます。
IBM COSの概要が見えてきましたね。ここでは細かい機能説明は記載しませんが、詳細な情報が欲しいという方はお気軽に文末に記載の お問合せ先 までご連絡ください。
見積ですが、提供形態によって見積方法が異なります。今回はIBM Cloudサービスを利用する際のIBM COS見積方法をご紹介します。
1) IBM COS見積に必要な情報
IBM COSの見積には以下表中の情報が必要になります。
| 項目 | 説明 |
|---|---|
| レジリエンシー | 以下3つのオプションから選択 Cross Region : 一つのGeo内の3つのRegionに跨ってデータが保管され、最高の可用性と回復性に優れる Regional : 一つのRegion内の複数のゾーンに跨って保管され、可用性とパフォーマンスに優れる Single Site : 一つのデータセンター内の複数のデバイスに跨って保管され最も局地性に優れる |
| ロケーション | データ保管するロケーション:上記のレジリエンシーの選択によって異なる。日本では東京、大阪が選択可能 |
| ストレージクラス | 以下4つのストレージクラスから選択 Smart Tier:アクセス頻度が動的または予測不可能、hot,cool,coldの料金レートに自動分類し毎月のストレージコストを最適化 Standard:アクセス頻度が高い Vault:Standardよりアクセス頻度が低い Cold Vault:最小限のアクセスでよい |
| ストレージ容量(GB/月) | 月に利用するストレージ容量(GB単位) |
| クラスA(1,000回当り)呼び出し | データへの書き込みに対する要求の数、1,000回単位で課金 |
| クラスB(10,000回当り)呼び出し | データへの読み取りに対する要求の数、10,000回単位の課金 |
| データ取得(GB/月) | IBM COSからダウンロードするデータの量(GB単位) |
今回は以下の想定で見積してみたいと思います。通常はバックアップストレージとして利用します。障害が発生し、データのリストアが必要になった場合にIBM COSからデータダウンロードを行う想定です。よって緊急時のデータ取得費用も確認するため、データ取得は”年1回10,000GBダウンロード”として算出してみたいと思います。
・レジリエンシー⇒Regional
・ロケーション⇒東京
・ストレージクラス⇒Smart Tier
・ストレージ容量(GB/月)⇒50,000GB/月
・クラスA(1,000回当り)呼び出し⇒1
・クラスB(10,000回当り)呼び出し⇒1
・データ取得⇒年1回に10,000GBダウンロードを想定
2) IBM COSの見積方法
①以下URL先のIBM CloudのCloud Object Storageのサイトへ入ります。ここではIBM Cloudのログインは不要です。IBM Cloudのアカウントを持っていない方でも見積もることができるので気軽に確認できますね。
https://cloud.ibm.com/objectstorage/create#pricing
②要件に沿って、赤枠をクリックして設定します。通貨は米国にします。
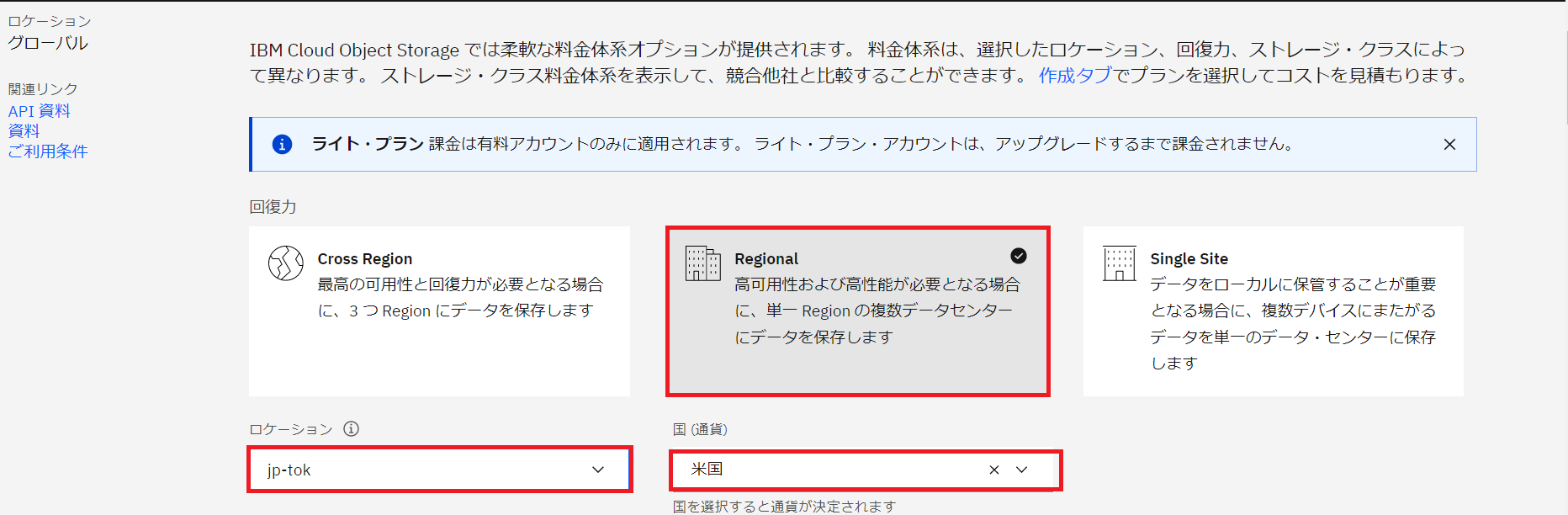
選択すると下に各項目毎に月額が表示されるので、ストレージ・クラス料金体系の赤枠内Smart Tierを確認します。※金額は2022年11月時点の金額になります。
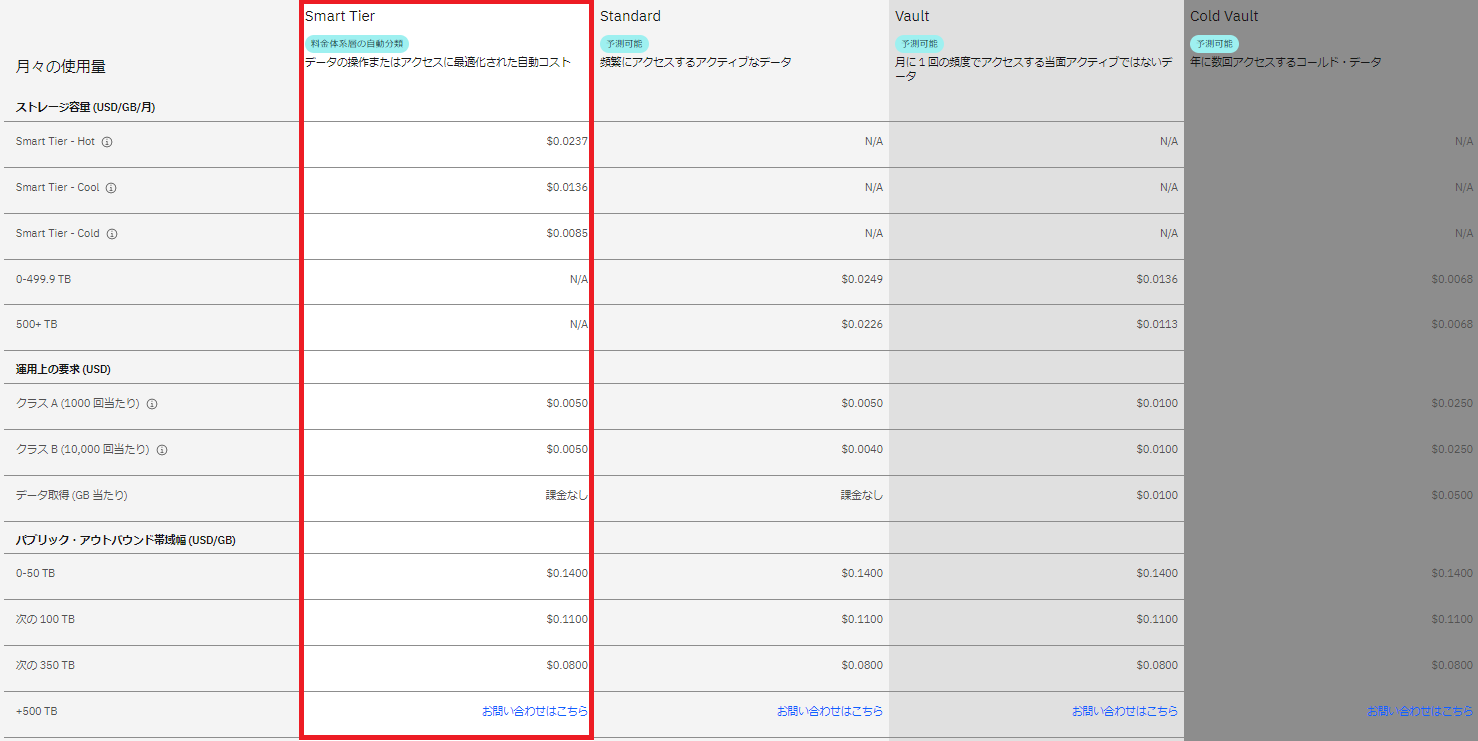
③各項目の費用が出たので、要件から計算します。Smart-Tierは自動コスト最適化が適用されるので厳密な金額は出せません。よって今回はSmart Tierで一番費用の高いHotの料金で計算しようと思います。またデータ取得は年1回ダウンロード想定なので、ダウンロード月の費用とダウンロード無しの月の費用を算出してみます。※通貨は$で算出していますので、適宜日本円に換算してご確認ください。
年1回ダウンロード月の費用は表中青字の金額になります。
| 項目 | 単価 | 数量 | 小計 |
|---|---|---|---|
| ①ストレージ容量(Smart Tier,GB) | $0.0237 | 50,000 | $1,185 |
| ②クラスA(1,000回当り)呼び出し | $0.005 | 1 | $0.005 |
| ③クラスB(10,000回当り)呼び出し | $0.005 | 1 | $0.005 |
| ④データ取得(GB) | $0.14 | 10,000 | $1,400 |
| 総合計/月 | $2,585.01 |
ダウロード無しの月額費用は、上記④の費用を除いた金額になるため、$1,185.01/月になります。
さいごに
いかがでしょうか。見積にあたって少し計算がありますが、数分で費用を確認できます。
IBM Cloudを利用する際はバックアップストレージとしてご利用される案件も多いと思いますので是非ご提案活動にお役立てください。
お問合せ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:voice_partners@niandc.co.jp