
IBM Cloud Pak for Applicationsの新規販売は終了いたしました。
今後のアプリケーションランタイムソリューションは、
こんにちは。
てくさぽBLOGメンバーの岡田です。
全3回「IBM Cloud Pak for Applicationsを導入してみた」シリーズの、“OpenShift導入編” です。
- IBM Cloud Pak for Applicationsを導入してみた(概要編)
- IBM Cloud Pak for Applicationsを導入してみた(OpenShift導入編) ← 今回
- IBM Cloud Pak for Applicationsを導入してみた(ICP4 Applications導入編)
本記事では、我々が実際にやってみてつまづいたポイントや AWS 特有の注意事項も記載していますので、ぜひ最後までお読みください。
1. はじめに
概要編でも述べていますが、IBM Cloud Paks(以下 Paks)は OpenShift 上で稼働するアプリケーションのため、Paks を利用するためには OpenShift の構築が必要となります。
今回の検証では最小構成での検証を実施するために、以下の環境で実施しました。
- AWS 上での構築
- OpenShift バージョン4.2(検証時最新)
- User-Provisioned Infrastructure(UPI)方式・・・ユーザーがインフラ環境を事前に用意してインストールを行う方法
- CloudFormation テンプレートの使用
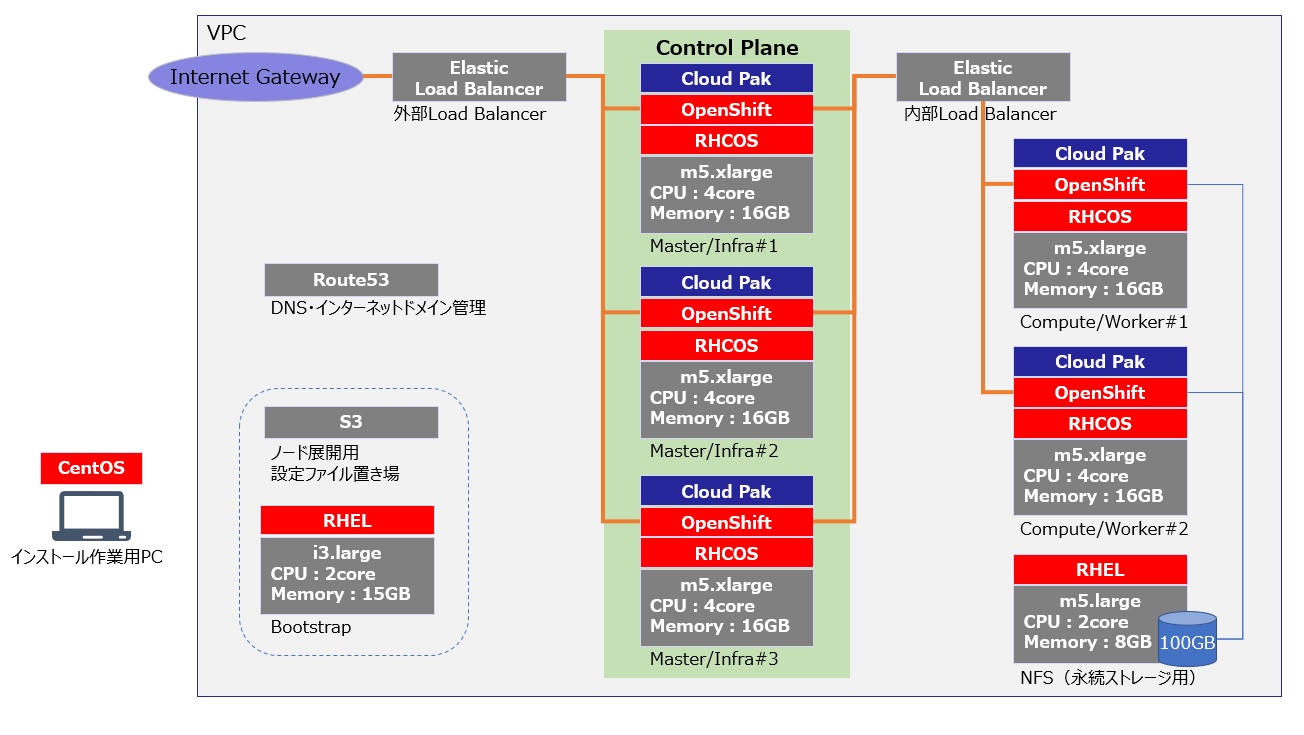
さて、以下が今回インストールする全体構成になります。Masterノード3台、Workerノード2台の構成です。
また本検証では、以下の Red Hat 社マニュアルページを利用しました。
インストールで利用する jsonファイル、yamlファイルの中身はこのマニュアル内の記載からコピー・アンド・ペーストして作成します。
「1.5. CLOUDFORMATION テンプレートの使用による、AWS でのユーザーによってプロビジョニングされたインフラストラクチャーへのクラスターのインストール」
2. 事前準備
2-1. 作業用Linux環境準備
OpenShiftのインストール作業に必要なLinux(Cent OS)環境を準備します。
詳細な手順はリンク先を参照ください。
(1)Cent OS インストールとディレクトリ作成
(2)AWS CLI インストール
(3)jqパッケージのインストール
2-2. インターネットドメインの取得とRoute53への登録
インターネット上から OpenShift クラスターにアクセスするためにインターネットドメインを利用できるようにAWS Route53で独自ドメインを取得・登録しました。
インターネットドメイン名:example.com(仮称)
2-3. インストールファイルの取得
OpenShiftのインストールに利用するファイルをRed Hatサイトからダウンロードします。
3. OpenShift 導入手順
3-1.AWS 環境構築
まずは AWS 環境を構築します。
今回は以下の全7項目を順番に実施しました。
詳細な手順はリンク先を参照ください。
(1)SSH プライベートキーの生成およびエージェントへの追加
(2)AWS のインストール設定ファイルの作成
(3)インフラストラクチャー名の抽出
(4)AWS での VPC の作成 ※つまづきポイントをこの後ご紹介
(5)AWS でのネットワークおよび負荷分散コンポーネントの作成
(6)AWS でのセキュリティーグループおよびロールの作成
(7)AWS インフラストラクチャーの RHCOS AMI
「(4)AWSでのVPCの作成」でのつまづきポイント
VPC作成のCloudFormationコマンドを実行した際にエラーが発生したので、原因と解決方法をご紹介します。
↓このコマンドでエラーが出ていますが、どこが間違っているか分かりますか?
# aws cloudformation create-stack –stack-name createvpc –template-body conf/cf_newvpc.yaml –parameters conf/cf_newvpc.json
Error parsing parameter ‘–parameters’: Expected: ‘=’, received: ‘EOF’ for input:
conf/cf_newvpc.json
パッと見、おかしいところが無さそうなのですがエラーとなっています。
検証メンバーで調査&トライ・アンド・エラーすること小一時間。。。原因は単純でした。
ファイル名を”file://”で指定していなかったのでyamlファイルやjsonファイルが読み込めなかったのです。以下が正しいコマンドになります。”file://”の後ろはフルパスで指定しているので”/”が3つ並んでます。
# aws cloudformation create-stack –stack-name createvpc –template-body file:///os42/conf/cf_newvpc.yaml –parameters file:///os42/conf/cf_newvpc.json
3-2. OpenShift導入
今回は以下の全10項目を順番に実施しました。
こちらも詳細な手順はリンク先を参照ください。
(1)Bootstrapノード作成
(2)コントロールプレーン(Masterノード)の作成
(3)Workerノードの作成
(4)Bootstrapノードの初期化
(5)CLI のインストール
(6)クラスターへのログイン
(7)マシンの CSR の承認 ※つまづきポイントをこの後ご紹介
(8)Operator の初期設定
(9)Bootstrapノードの削除
(10)クラスターのインストールを完了
「(7)マシンの CSR の承認」でのつまづきポイント
“oc get nodes”コマンドを実行してもマスターノードのみを認識しワーカーノードを認識しなかったので、その解決方法を紹介します。
下記のとおり、oc get nodes を実行してもマスターノードしか認識していません。
# oc get nodes
NAME STATUS ROLES AGE VERSION
ip-10-0-50-xxx.ap-northeast-1.compute.internal Ready master 21h v1.14.6+8fc50dea9
ip-10-0-58-xxx.ap-northeast-1.compute.internal Ready master 21h v1.14.6+8fc50dea9
ip-10-0-59-xxx.ap-northeast-1.compute.internal Ready master 21h v1.14.6+8fc50dea9
保留中の証明書署名要求 (CSR) を確認するとPending になっています。
# oc get csr
NAME AGE REQUESTOR CONDITION
csr-485lx 22m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
csr-9qjqw 18m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
・
・
以下、省略
そこでまずは個々のCSRを承認していきましたがコマンド実行してもすぐに反映されない、また保留状態のCSRが増えていくという状態になりました。
# oc adm certificate approve csr-9qjqw
certificatesigningrequest.certificates.k8s.io/csr-9qjqw approved
# oc get csr
NAME AGE REQUESTOR CONDITION
csr-9qjqw 53m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-485lx 22m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
・
・
以下、省略
CSRが増える一方で状況が悪化しており、出てきたCSRを個別に処理するのもキリがないためこの時点で一度諦めました。
翌日にまとめて CSR を承認するコマンドを探して実行すると、ワーカーノードが認識できました。
# oc get csr -ojson | jq -r ‘.items[] | select(.status == {} ) | .metadata.name’ | xargs oc adm certificate approve
certificatesigningrequest.certificates.k8s.io/csr-2fn5z approved
certificatesigningrequest.certificates.k8s.io/csr-4cj8b approved
certificatesigningrequest.certificates.k8s.io/csr-4lpv7 approved
・
・
以下、省略
※少しタイムラグがあるので、何回か状況確認・Approve処理を行う必要がありました。10分ぐらい間隔をあけた方がよかったです。
oc get nodesコマンドで全ノードの STATUSがReady であることを確認できます。
# oc get nodes
NAME STATUS ROLES AGE VERSION
ip-10-0-48-xxx.ap-northeast-1.compute.internal Ready worker 57s v1.14.6+8fc50dea9
ip-10-0-49-xxx.ap-northeast-1.compute.internal Ready worker 42m v1.14.6+8fc50dea9
ip-10-0-50-xxx.ap-northeast-1.compute.internal Ready master 22h v1.14.6+8fc50dea9
ip-10-0-58-xxx.ap-northeast-1.compute.internal Ready master 22h v1.14.6+8fc50dea9
ip-10-0-59-xxx.ap-northeast-1.compute.internal Ready master 22h v1.14.6+8fc50dea9
まとめて承認するコマンドが見つからなかったら、と思うとゾッとします。読者の方は事前に調べておきましょうね。
4. AWS特有の注意事項
AWSネットワークの理解は必須
Red Hat社のマニュアルページの内容を利用して jsonファイルと yamlファイルを用意し、CloudFormationコマンドを実行すれば AWS コンポーネントや OpenShift ノードなど必要なコンポーネントが自動的に作成されますが、自動的に作成されるが故に、ロードバランサー、サブネット、EC2インスタンスなどのコンポーネント間の接続の関係性が分かりづらいと思いました。
AWS マネージメントコンソールでなにが作成されたかを確認できますが、AWS のネットワークを理解していないと全体像の把握が難しくその点が苦労しました。
CloudFormation 特有のインストール時のクセを理解し慣れる
CloudFormation でのインストールでは、それ以前に実行して出力された値を次の CloudFormation コマンドで用いる jsonファイルに転記して利用する、という操作を繰り返します。特に UPI方式では転記する項目も回数も多かったので、Excel でどの項目がどのフェーズの jsonファイルに転記するのかを整理してインストールを進めました。
またそのような CloudFormation の特徴から、事前に設定ファイルをすべて用意して順番に実行する、ということができませんのでインストール作業は時間に余裕を持って行いましょう。
5. まとめ
本記事で OpenShift を AWS 上で UPI インストールする流れを確認いただけましたでしょうか。
必要なインフラのコンポーネントをインストーラが自動的に作成してくれる IPI (Installer Provisioned Infrastructure) 方式と比べると作業工程が多くなりますが、本番環境のお客様要件に対し常に IPI方式で構築できるとは限らないと想定し、UPI方式を学んでおくことは大変有用だと思いますので参考になれば幸いです。
本記事の内容で構築した環境に、この後 Paks をインストールすることが可能となります。Paks の種類によって必要リソースは異なりますが UPI方式での手順は同じです。
次回は、この OpenShift の環境に Cloud Pak for Application をインストールしてみた内容をお伝えします。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp
関連情報
- 全ての企業が AI カンパニーになる!「IBM THINK Digital 2020」に参加した (ブログ)
– 全世界から9万人以上の参加者が! - 【やってみた】IBM Cloud Pak for Applications導入してみた:概要編 (ブログ)
– シリーズ第1回目!概要編として検証の目的・背景や環境周りをご紹介します。 - 【やってみた】Cloud Pak for Applications 導入してみた:Cloud Pak for Applications 導入編 (ブログ)
– AWS 上に構築した Openshift 環境に Cloud Pak for Applications をインストールしてみました。 - 今、デジタルサービスに求められる必須要件とは!? アプリケーションのコンテナ化で得られる5つのメリット (コラム)
– 今注目されている「コンテナ化」。コンテナ化とは?そのメリットとは? - IBM Cloud Paks シリーズ ご紹介資料 (資料) ※会員専用ページ
– 6つの Cloud Paks について、お客様の理解度に応じて必要な資料を選択できる形式になっています。
【外部ページ】
- IBM Cloud Pak for Applications (IBMサイト)