
こんにちは。
てくさぽBLOGメンバーの高村です。
ビジネスへの生成AI の取り込みに注目が集まっている今日、watsonx.ai をどう活用すればいいのか、多くのお客様からお問い合わせ頂いています。
そこで前回の「【てくさぽBLOG】IBM watsonx.aiを使ってみた(Part2)」では、watsonx.ai のユースケースとして Retrieval-Augmented Generation(以下 RAG)をご紹介しました。
今回は、RAG の仕組みを利用し AIチャットボットを提供する「watsonx Assistant(以下 Assistant)」と検索エンジン機能を提供する「Watson Discovery(以下 Discovery)」、「watsonx.ai」を組み合わせた連携ソリューションをご紹介します。
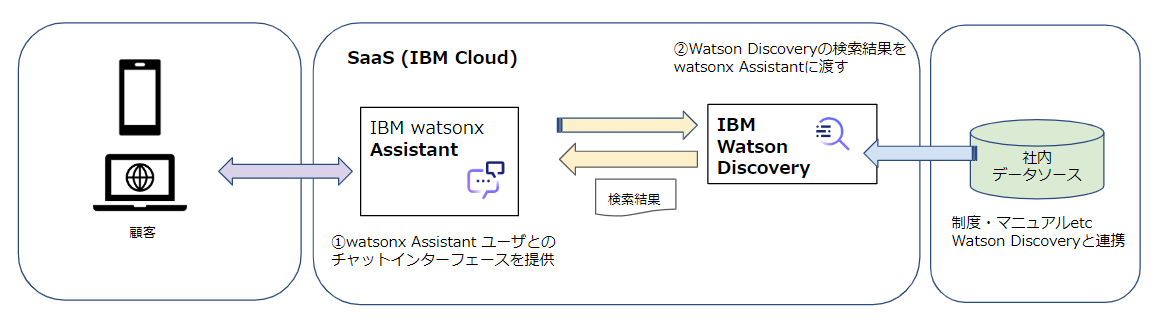
AssistantとDiscoveryの連携
本来なら各製品を一つのブログで詳しくご説明したいところですが、今回は連携した結果についてのご紹介となりますので、Assistant と Discovery については今後のブログであらためてご紹介したいと思います。
Assistant は watsonx の大規模言語モデルが搭載され、自然言語の問い合わせを理解し、適切な回答を返すことができるチャットボット機能を提供する製品です。
一方 Discovery はドキュメントから適切な情報を検索する検索エンジン機能、パターンや傾向を読み取る分析エンジンとしての機能を備えた製品です。
Assistant と Discovery を組合わせたユースケースでは Assistant にあらかじめ回答を用意してルールベースで回答させ、答えることが難しい問い合わせに対しては Discovery の検索結果を利用して回答します。
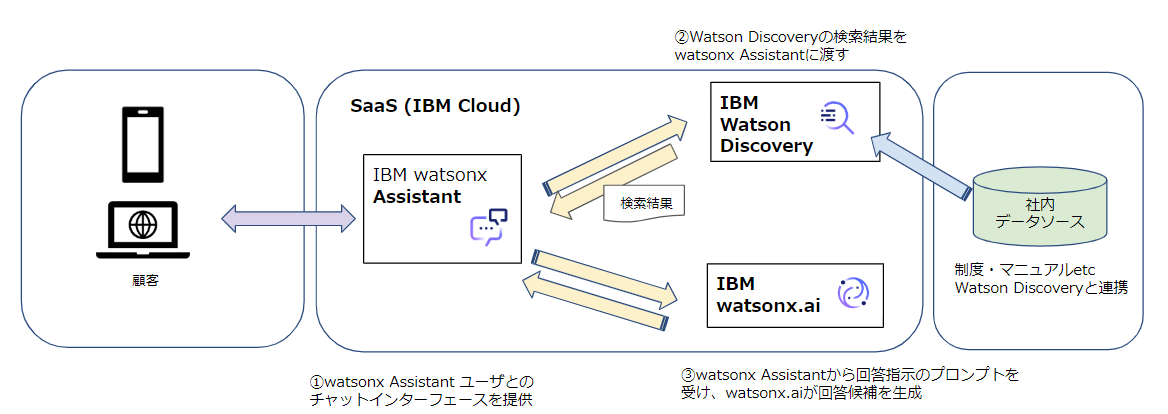
watsonx.aiを取り入れた連携
上記の連携では Discovery の検索結果がユーザーに表示される仕組みとなっていますが、watsonx.ai を介して回答を提供することでDiscovery が得た検索結果をさらに整理し、より理解しやすい形での返答が実現できます。
Assistant + Discovery + watsonx.aiを連携してみた
Assistant、Discovery、watsonx.ai を連携してみます。
事前準備
利用環境
今回は IBM Cloud で提供される SaaS を利用して検証します。
なお、Assistant と Discovery の Plusプランは30日間無償期間が付属されていますので、是非ご活用ください。
- watsonx Assistant:Plusプラン(30日間無償期間あり、以降は有償)
- Watson Discovery:Plusプラン(30日間無償期間あり、以降は有償)
- watsonx.ai:Essentialプラン(有償)
検証の目的
検証では構築手順の他、以下の点を確認します。
- 「Assistant + Discovery + watsonx.ai」と「Assistant + Discovery」の連携による回答の違いを比較
- 言語モデルを変えて問い合わせを行い、回答の違いの比較
実施手順
以下の流れで検証を実施します。
- Assistantのプロビジョニング
- Discoveryのプロビジョニング、検索対象とするデータの取り込み
※取り込むデータは「IBM Power S1014 データシート」のS1014のPDF - watsonx.aiのプロビジョニング
- Assistantの初期設定
- Assistantのカスタム拡張機能からDiscoveryを繋げる
- Assistantのカスタム拡張機能からwatsonx.aiを繋げる
- Assistantアクションの作成、問い合わせの検証
- 言語モデルを変えて問い合わせの検証
検証実施
1. Assistantのプロビジョニング
はじめに Assistant のプロビジョニングを行います。
- IBM Cloud にログインし、カタログ画面から “Assistant” を選択します。
- ロケーションとプランを選択し「作成」をクリックします。
- しばらくすると以下の画面の様に、Assistant がプロビジョニングされます。
2. Discoveryのプロビジョニング
次に Discovery をプロビジョニングします。
- カタログ画面から “Discovery” を選択します。
- ロケーションとプランを選択し「作成」をクリックします。
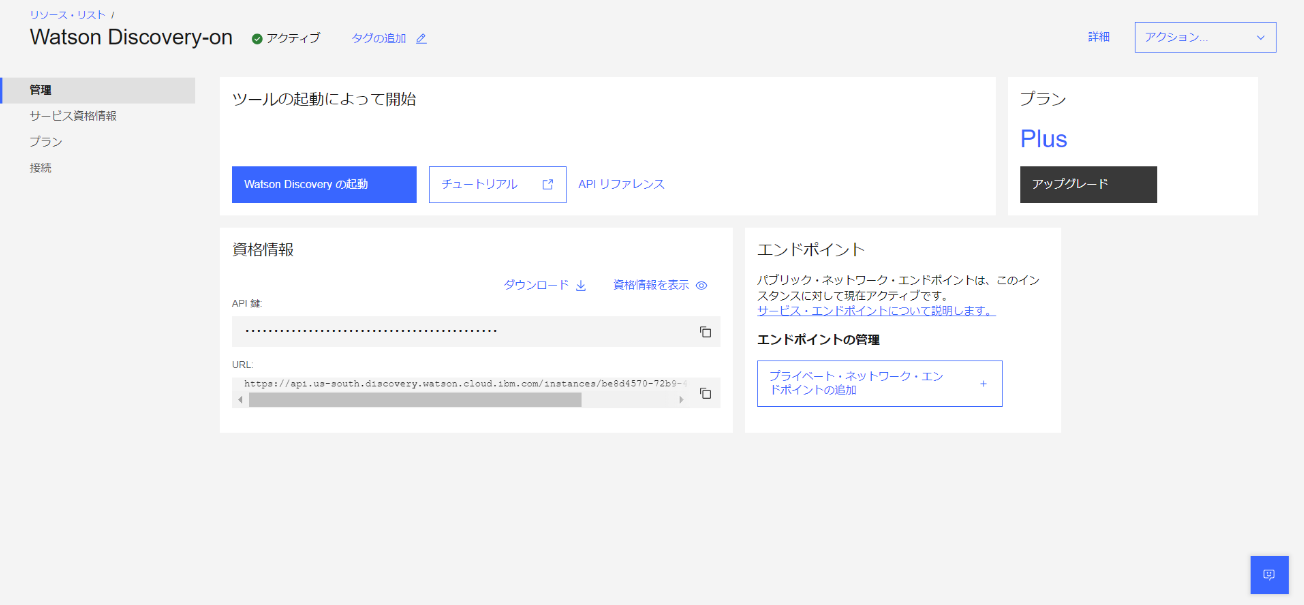
- しばらくすると以下の画面の様に、Discovery がプロビジョニングされます。
※ここで、資格情報内にある「API鍵」と「URL」をメモに控えます
- 「Watson Discoveryの起動」をクリックし「New Project +」をクリックします。
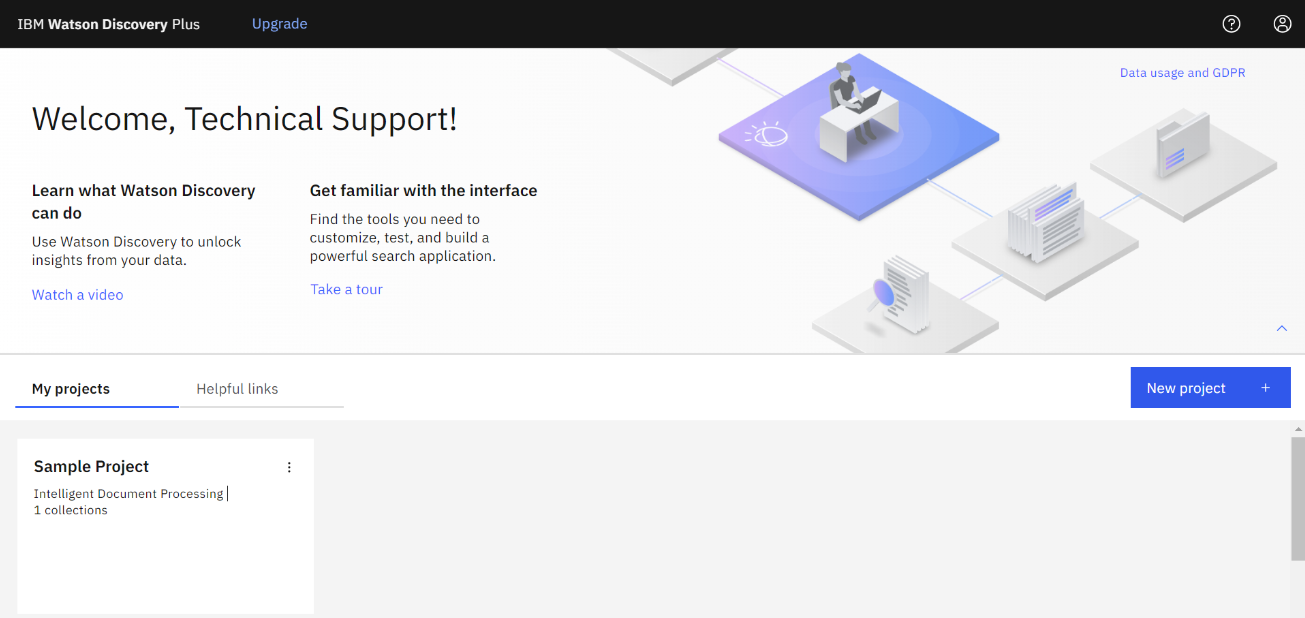
- Project name に任意の名前を入力、Project type では「Conversational Serch」を選択し「Next」をクリックします。
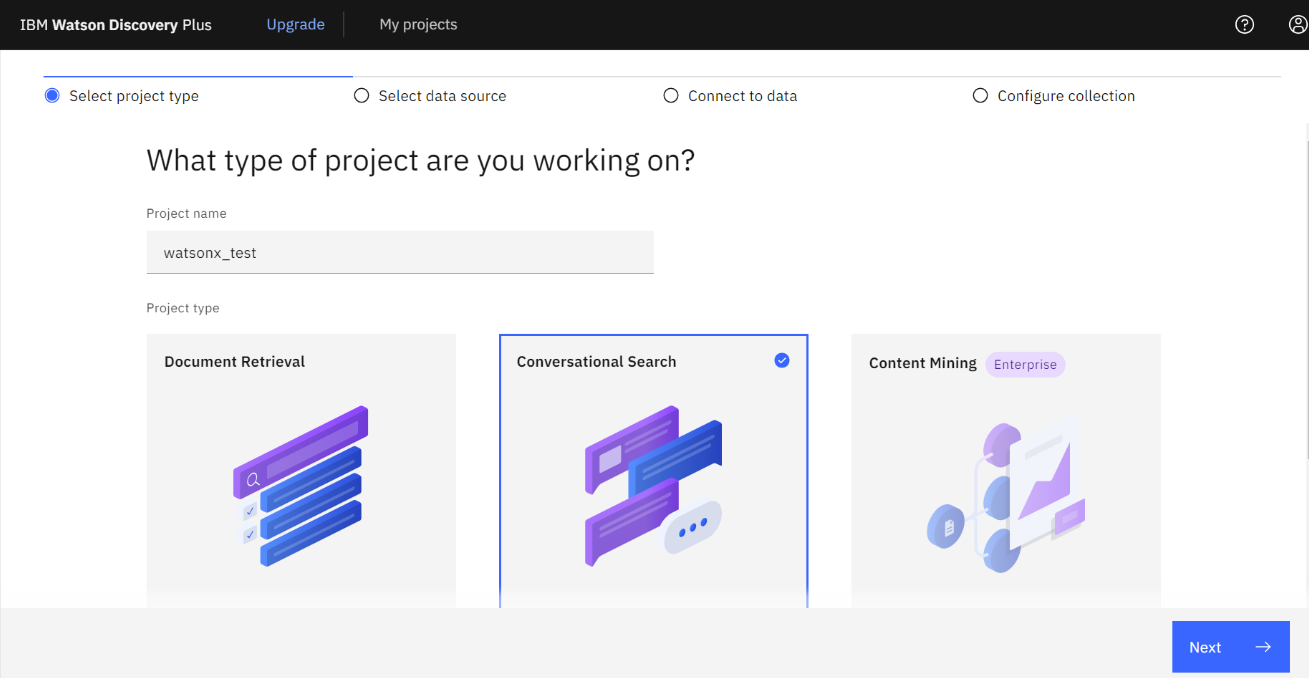
- 作成されたプロジェクトをクリックします。
- 「Integration Deploy」をクリックします。
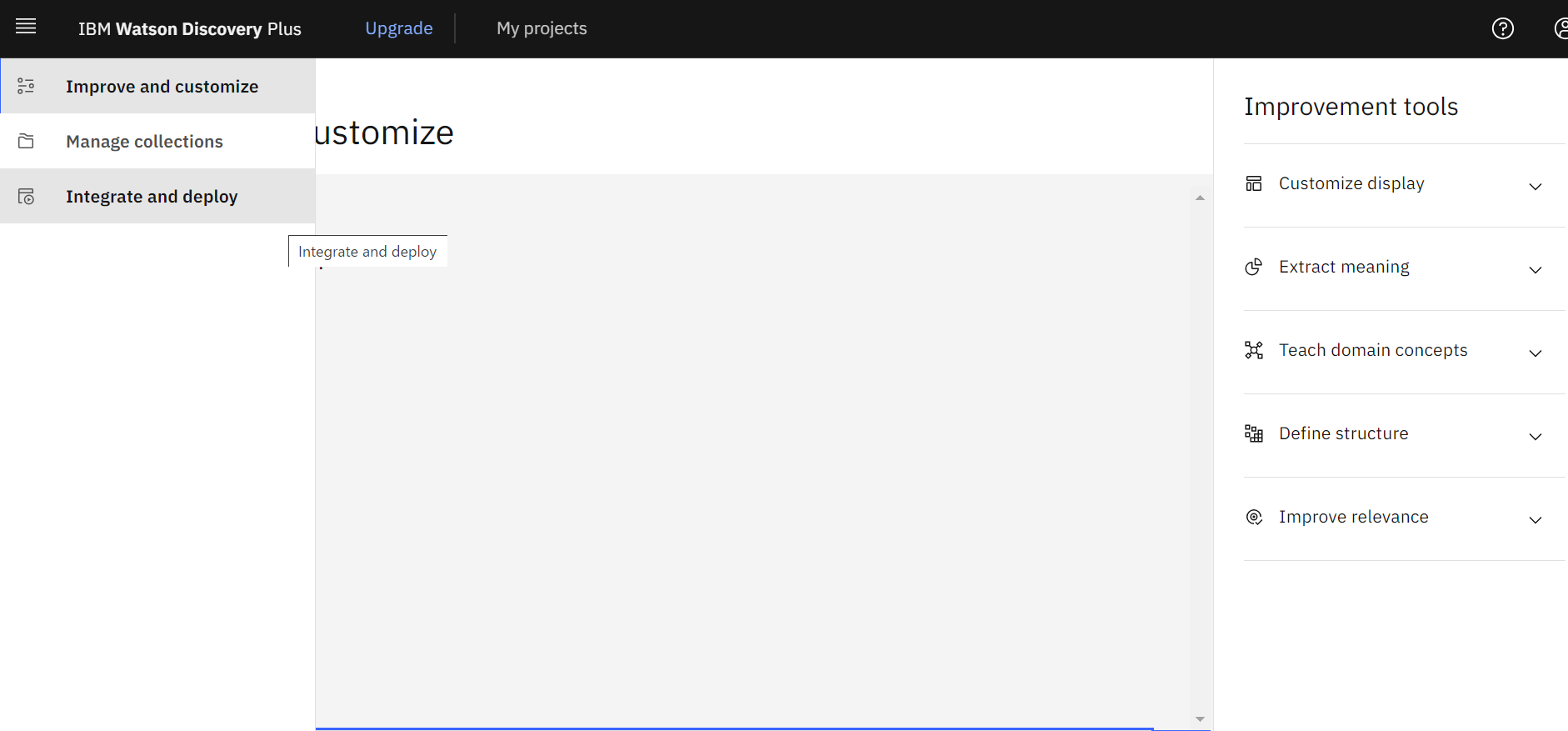
- 「API Information」タブをクリックし「Project ID」をメモに控えます。
次に検索対象の PDF を Discovery に取り込みます。
- 「Manage collections」から「New collection +」をクリックし、「Collection name」に任意の名前を入力、「Select language」を「Japanese」に設定します。
- Upload files の領域に PDF をドラッグアンドドロップして「Finish」をクリックします。
アップロードが完了しました。
次に、Smart Document Understanding機能(以下 SDU)を利用して PDF内のヘッダーやテキストなどのフィールドを定義します。
SDU は、PDFをはじめとする非構造化データの文書構造を理解して検索や分析の精度を向上させる機能です。
例えばタイトルと定義した箇所を検索キーとしたり、検索対象をテキストと定義した箇所のみとするなど可能になります。
- 「Identify Field」タブをクリックします。
- 取り込んだ PDF が表示されるので右側の Field labels からヘッダー箇所やタイトル箇所などをドラッグアンドドロップして指定していきます。
- ページの定義が終わったら「Submit page」をクリックして次の頁を定義していきます。
SDU では数ページ指定すると自動的にヘッダー箇所やテキスト箇所を認識してくれるので、何ページもあるドキュメントには便利な機能です。
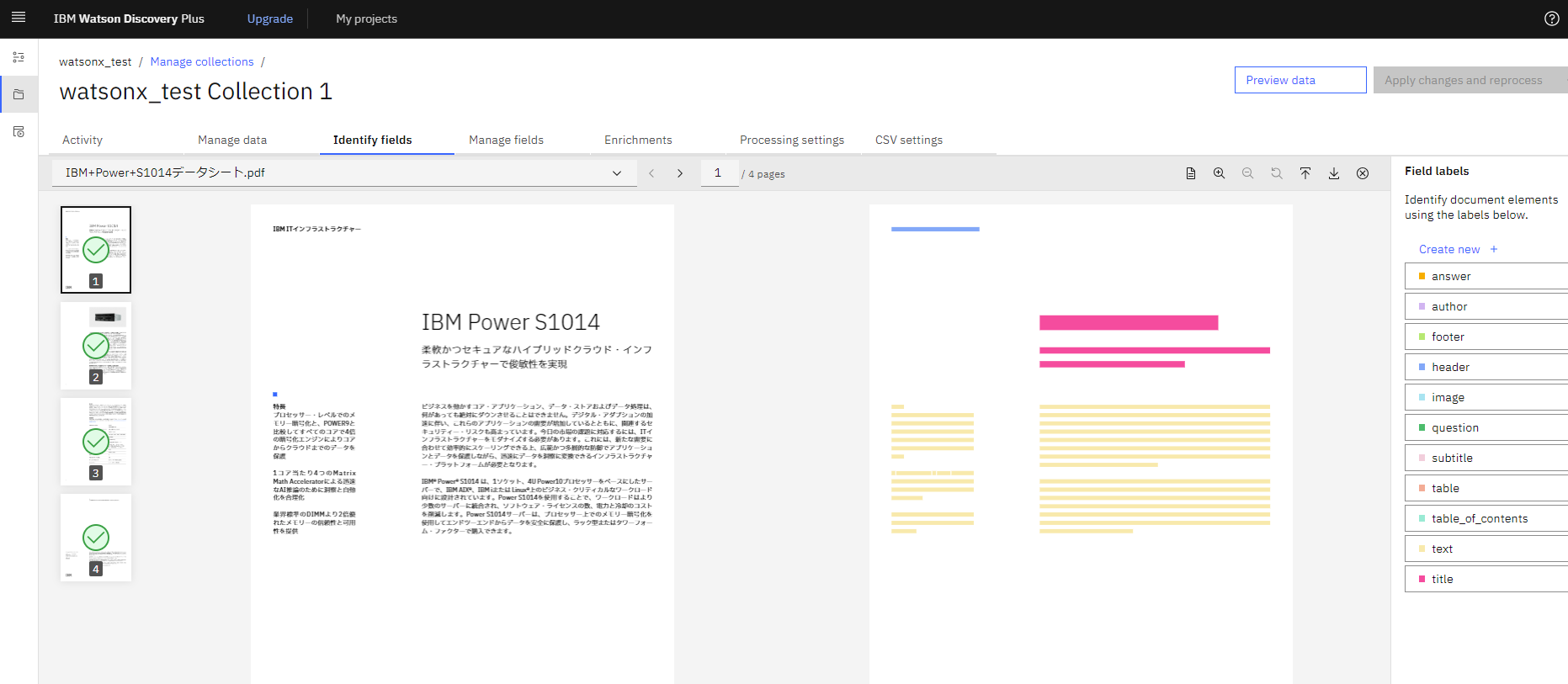
今回は SDU を使って PDF の文書構造を定義しました。
SDU以外の Discovery の機能については、また別の機会にご紹介したいと思います。
3. watsonx.aiのプロビジョニング
※watsonx.ai のプロビジョニング方法は「【てくさぽBLOG】IBM watsonx.aiを使ってみた(Part1)」をご参照ください。
4. Assistantの初期設定
Assistant の初期設定を行います。
- Assistant を起動します。
- 起動後、以下の項目を入力します。
- Assistant name:任意の名前を入力
- Assistant Language:「English」を選択
※日本語を選択することが可能ですが、Assistant のスターターキットは英語での利用を想定しているため今回はEinglishを選択します
- Assistant の公開先を「web」に設定します。
※”Tell us about your self” 以降はご自身の情報を入力ください - 入力後「Next」をクリックします。
- デフォルトのチャットUI を利用するため「Next」をクリックします。
- プレビュー画面が表示されるので「Create」をクリックします。
(以下の画面は「Create」が隠れてしまっています)
「Congratulations!」と表示されたら初期設定は完了です。
5. Assistantのカスタム拡張機能からDiscoveryを繋げる
「Githubのassistant-toolkit」から “watson-discovery-query-openapi.jsonファイル” をダウンロードします。
- Assistant のメニューから「Integration」をクリックします。
- 下にスクロールし「Build custom extension」をクリックします。
- 以下の画面が表示されるので「Next」をクリックします。
- 「Extension name」に任意の名前を入力し「Next」をクリックします。
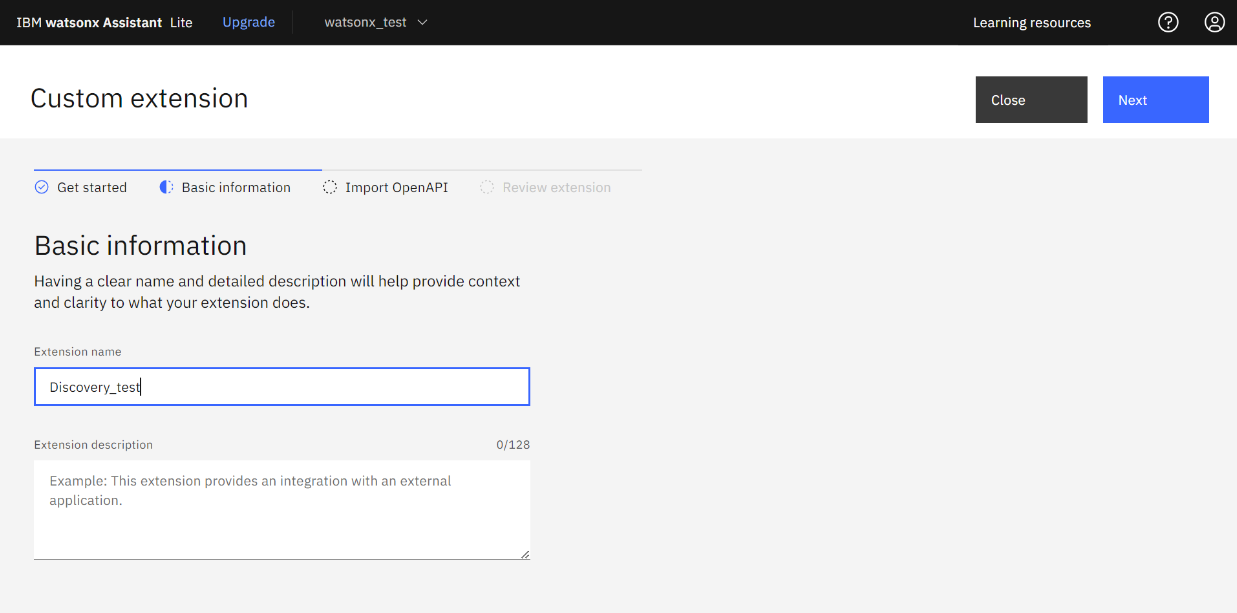
- 先程ダウンロードした watson-discovery-query-openapi.jsonファイルをドラッグアンドドロップでアップロードします。
- 以下の画面が表示されるので「Finish」をクリックします。
- 追加した Extension の「Add +」をクリックします。
- 以下の画面が表示されるので「Next」をクリックします。
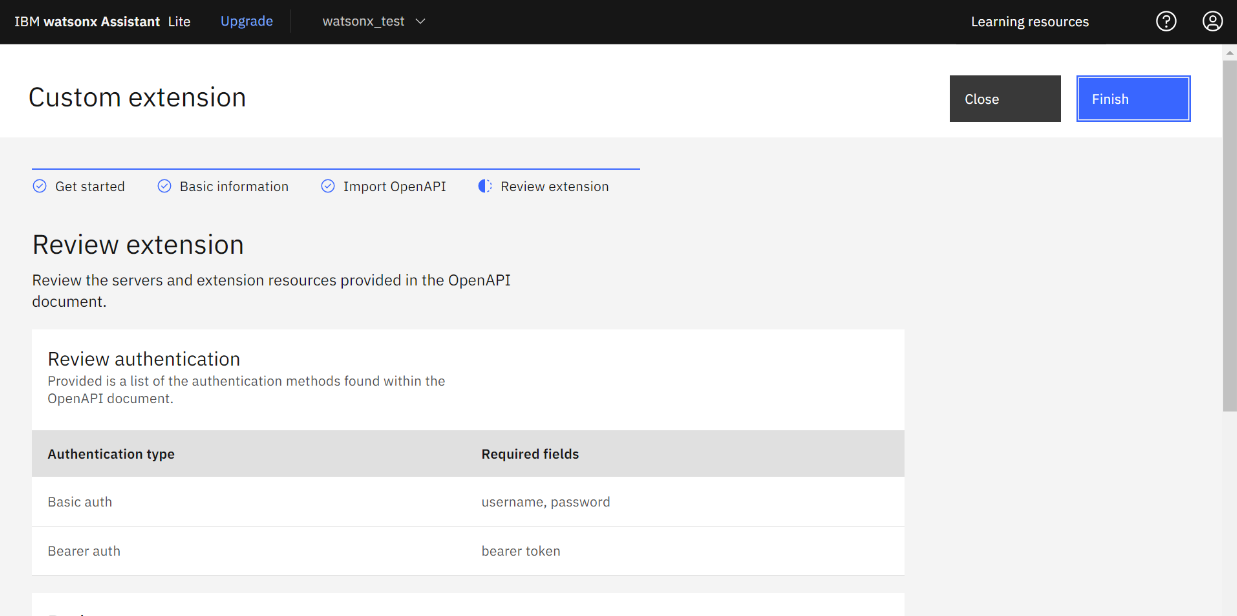
- 以下の画面が表示されるので、選択および入力します。
- Authentication type:「Basic auth」を選択
- Username:「apikey」と入力
- Password:メモに控えたWatson DiscoveryのAPI鍵
- discovery_url:メモに控えたWatson DiscoveryのURLから”http://”を除いた値
※以下の画面ショットは discovery_url入力箇所が切れてしまっていますが、実際は「Servers」の下に discovery_url の項目があります
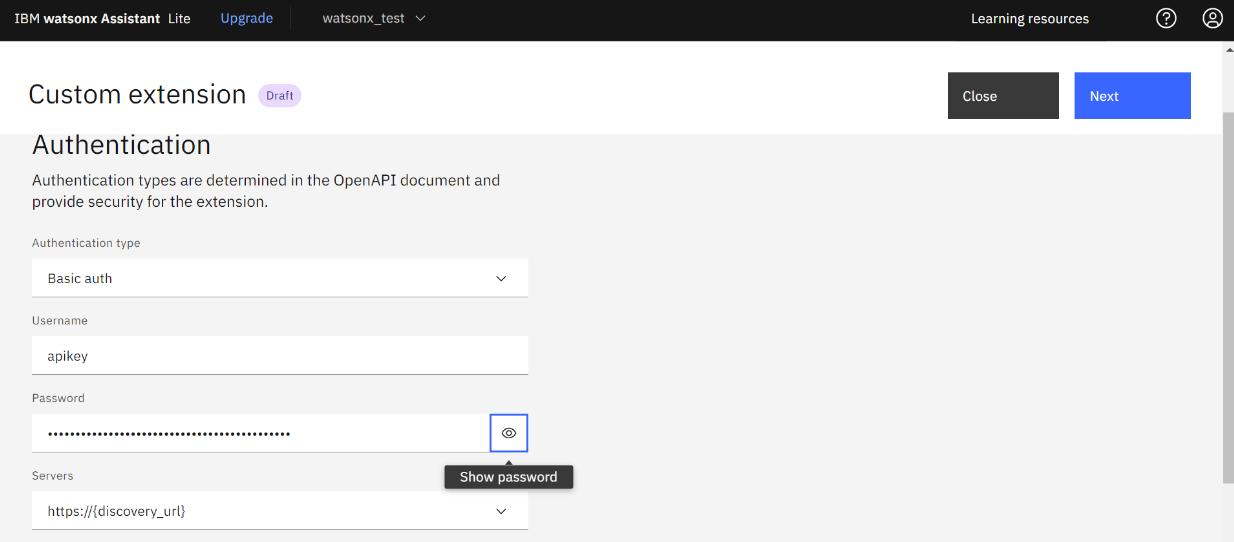
- 以下の画面が表示されるので「Finish」をクリックします。
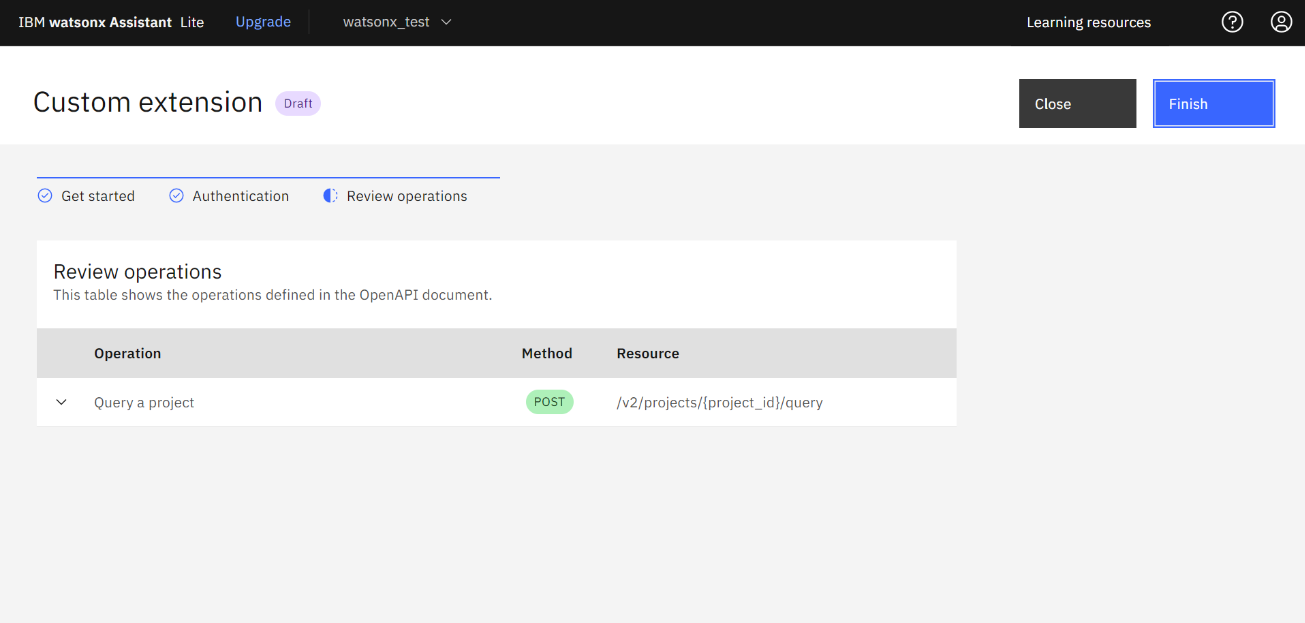
- Extension が「Open」となっていることを確認します。
これで watsonx Assistant と Watson Discovery が連携できました。
6. Assistantのカスタム拡張機能からwatsonx.aiを繋げる
次に、Assistant のカスタム拡張機能から watsonx.ai を利用できるように設定します。
設定には IBM Cloud の APIキーと watsonx.ai のプロジェクトID が必要です。
取得方法は「【てくさぽBLOG】IBM watsonx.aiを使ってみた(Part2)」をご参照ください。
なお、今回は東京リージョンで watsonx.ai をプロビジョニングします。
- Github の「assistant-toolkit」から “watsonx-openapi.json” をダウンロードします。
- Visual Studio Code などで東京リージョンの URL に編集し保存します。
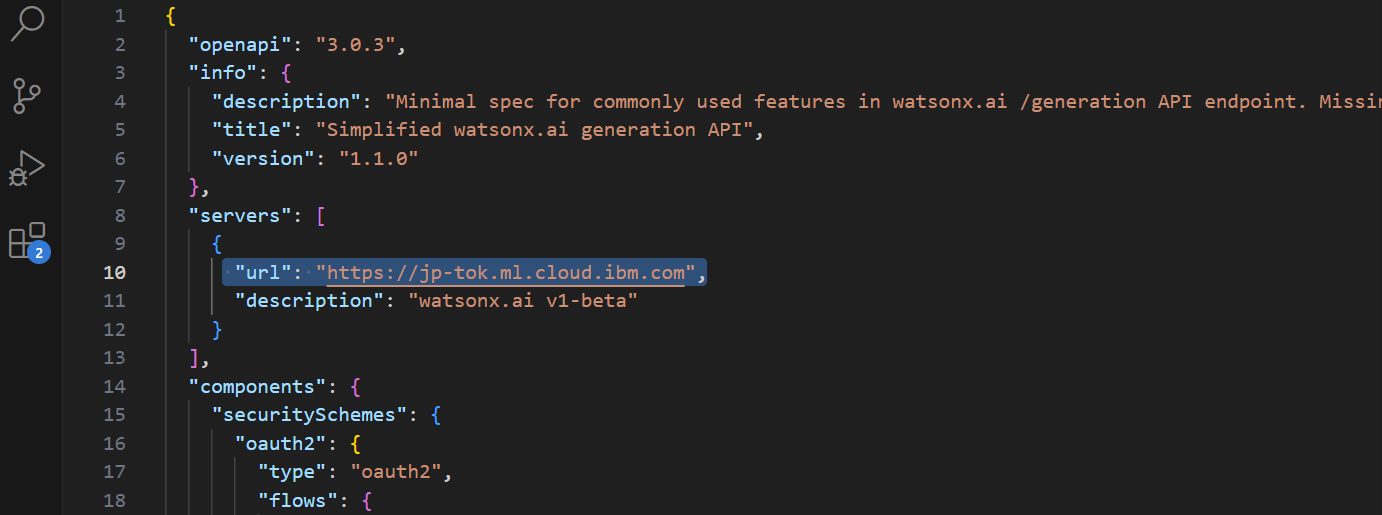
- Discovery の連携と同様に、Assistant のメニューから「Integration」「Build custom extension」をクリックします。
- 以下の画面が表示されるので、任意の Extension name を入力して「Next」をクリックします。
- 編集した watson-discovery-query-openapi.jsonファイルをドラッグアンドドロップでアップロードして「Next」をクリックします。
- 以下の画面が表示されるので「Finish」をクリックします。
- 追加した Extension の「Add +」をクリックします。
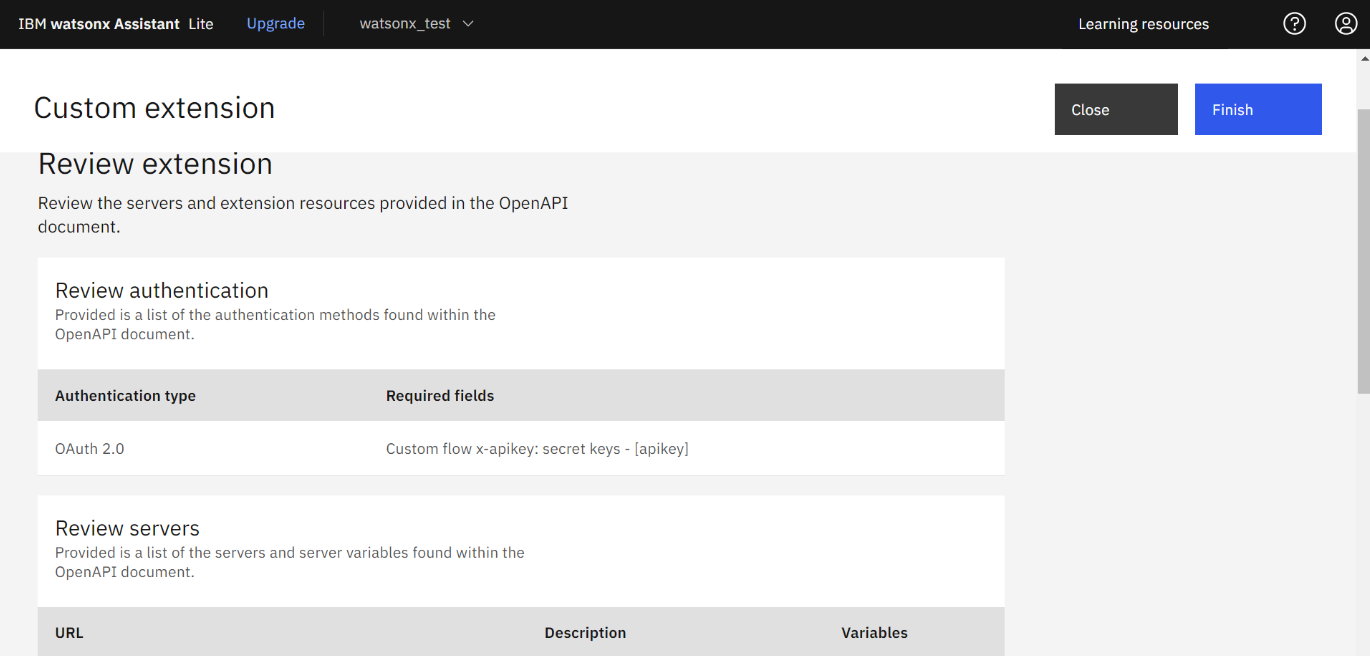
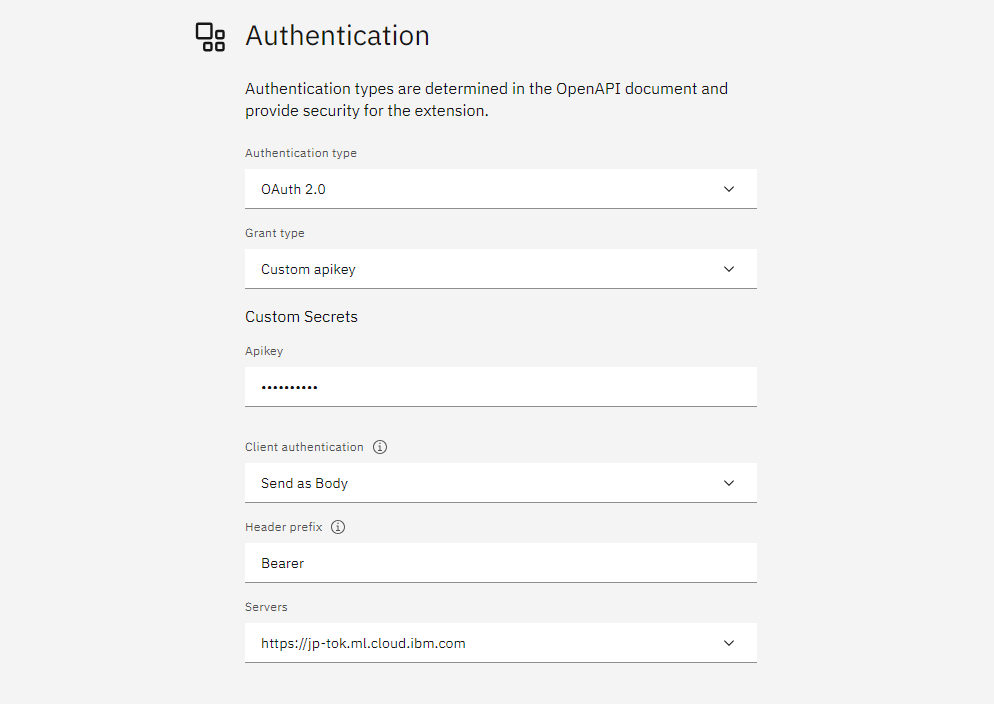
- 以下の画面が表示されるので、選択および入力します。
- Authentication type:「Oauth 2.0」を選択
- Grant type:「Custom apikey」を入力
- apikey:取得済みのIBM CloudのAPIキー
- Client authentication:「Send as Body」を選択
- Header prefix:Bearer(デフォルト)
- Servers:https://jp-tok.ml.cloud.ibm.com(自動入力)
- 以下の画面が表示されるので「Finish」をクリックします。
- Extension が「Open」となっていることを確認します。
これで Assistant と watsonx.ai が連携できました。
7. Assistantアクションの作成、問い合わせの検証
Github の「assistant-toolkit」から “discovery-watsonx-actions.json” をダウンロードします。
- Assistant の「Actions」から「Global Setting」をクリックします。

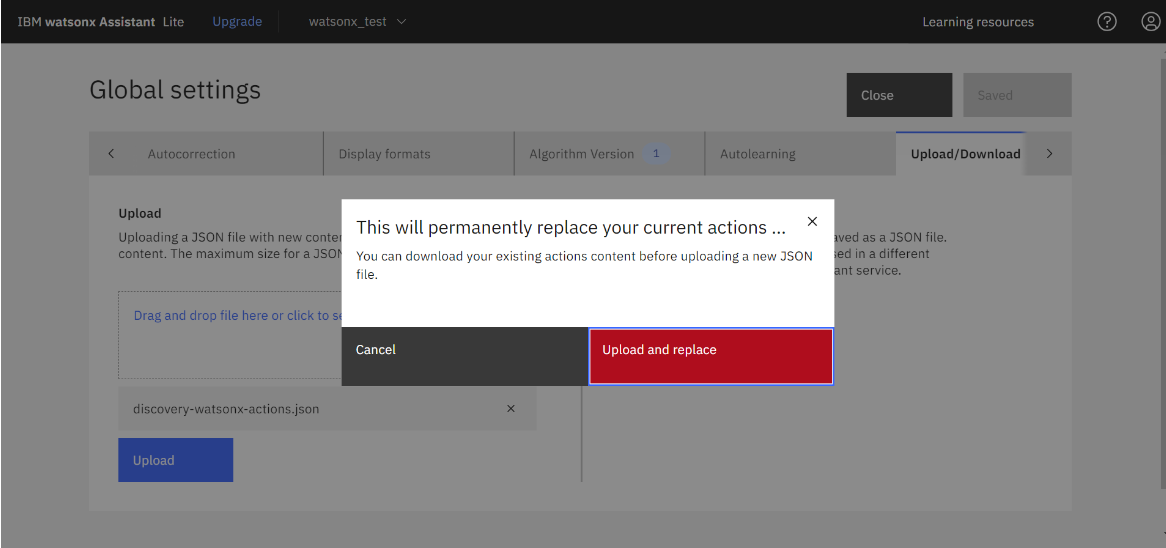
- 「Upload/Download」タブをクリックし、Uploadスペースに discovery-watsonx-actions.json をドラッグアンドドロップしてアップロードします。
- 以下の画面が表示されるので「Upload and replace」をクリックします。
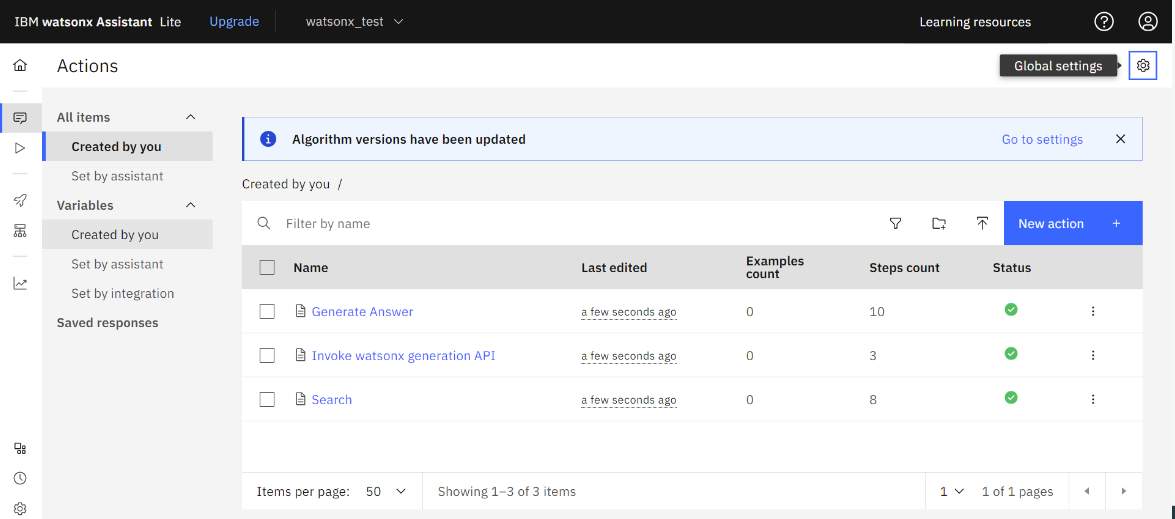
- 以下の画面の通り、3つのアクションが作成されます。
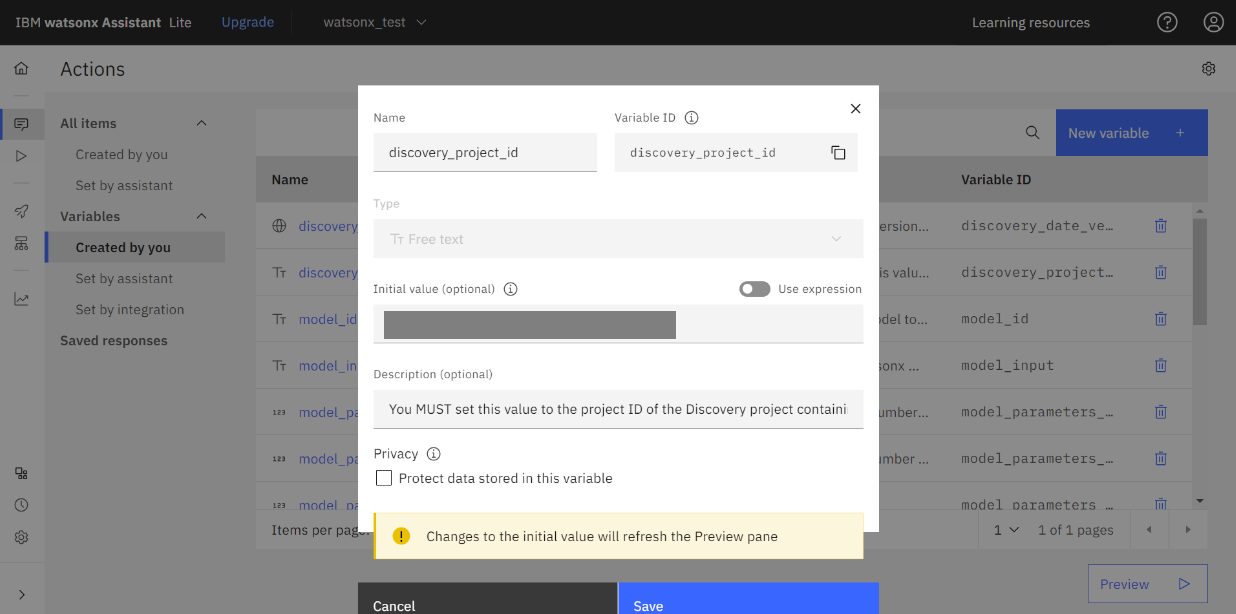
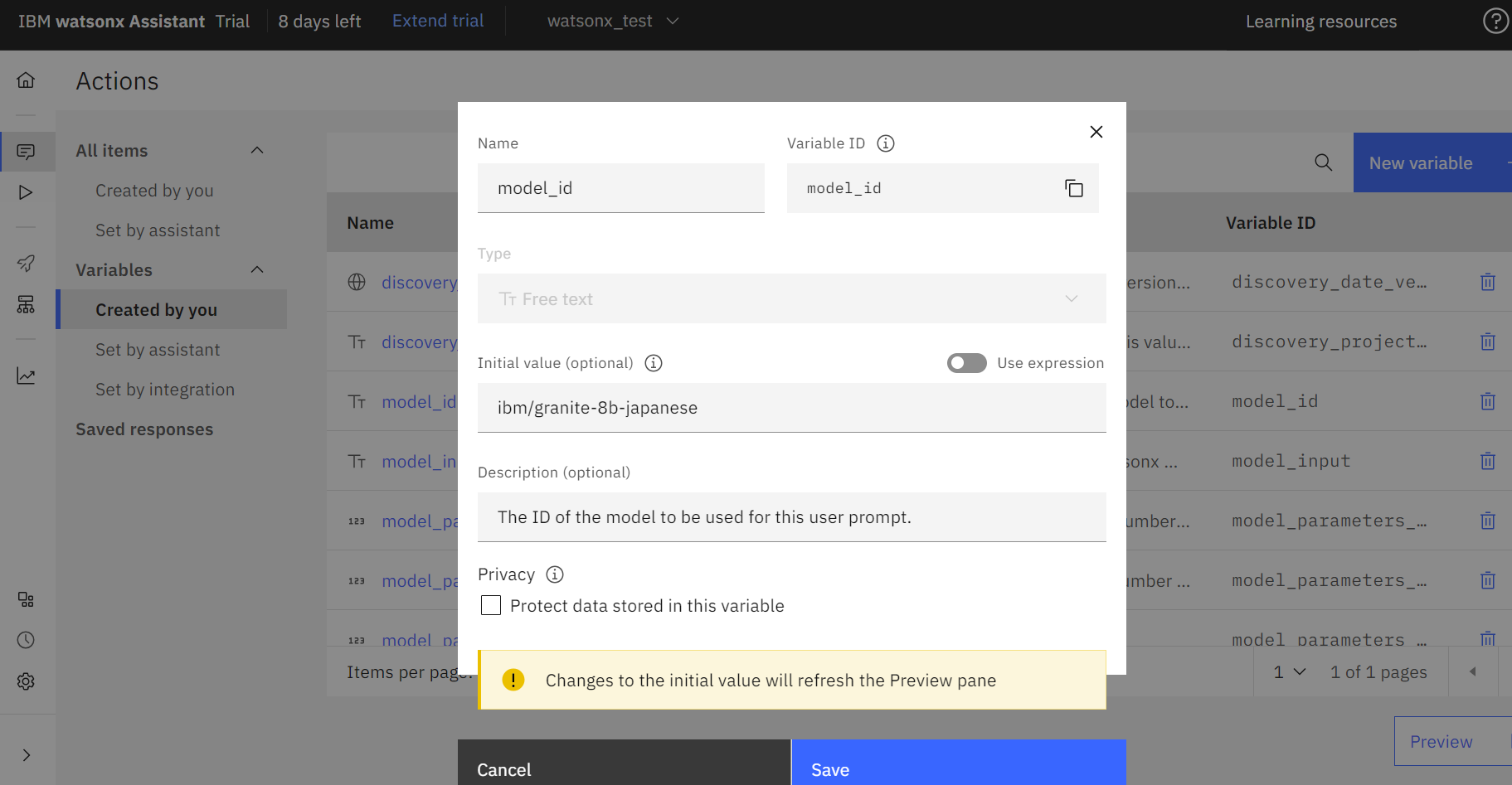
- メニューから「Variables」「Created by you」をクリックします。
- 「discovery_project_id」の値をメモに控えていた Discovery のプロジェクトID を入力し「Save」をクリックします。
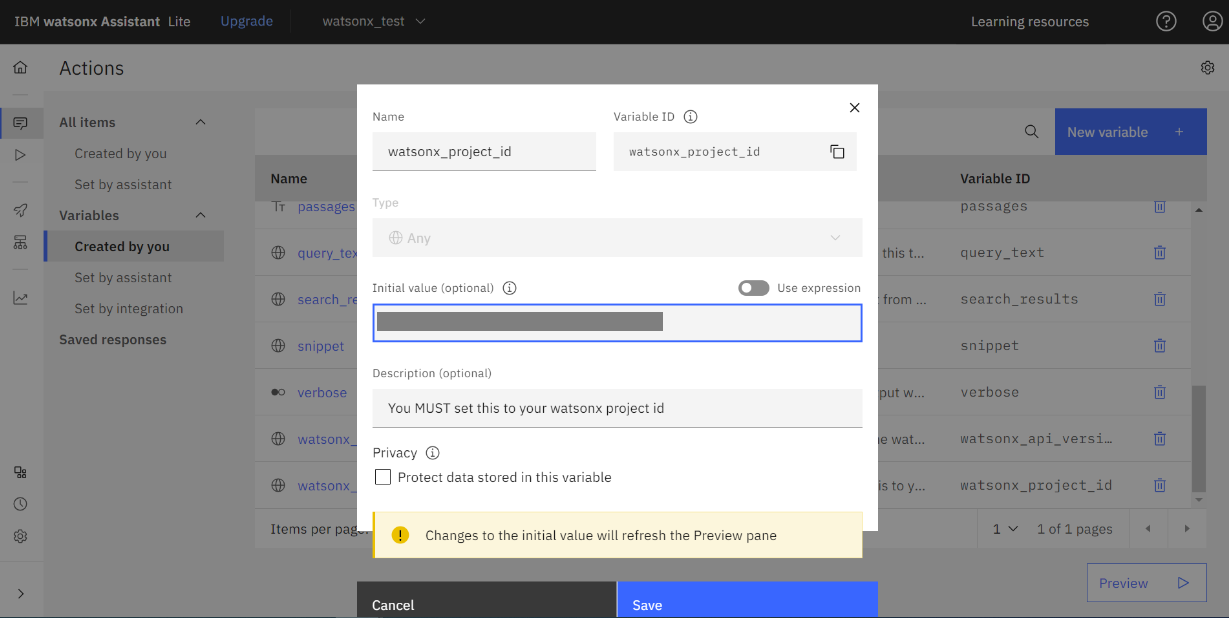
- 「watsonx_project_id」の値をメモに控えて置いた watsonx.ai のプロジェクトID を入力し「Save」をクリックします。
- 「model_id」の値で watsonx.ai で使用する言語モデルを指定します。2024年2月29日に GA された日本語で訓練された Granite-japaneseモデルを使用するため、「ibm/granite-8b-japanese」を入力し「Save」をクリックします。
(その他変数はデフォルト値とします)
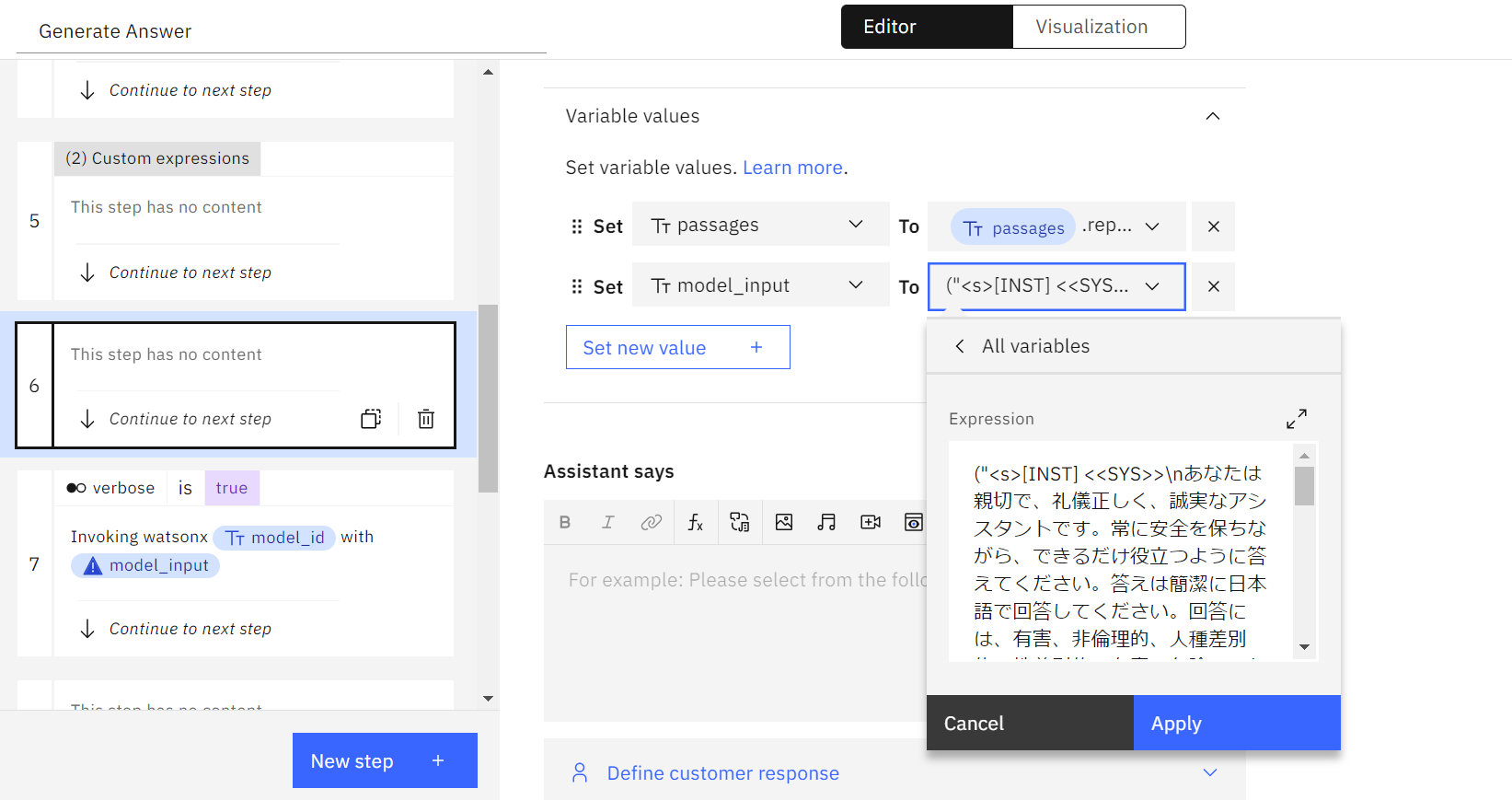
- 「Actions」から「Generate Answer」を選択し、「model_input」の値を以下の例の様に日本語に変更します。
| 例: (“<s>[INST] <<SYS>>\nあなたは親切で、礼儀正しく、誠実なアシスタントです。常に安全を保ちながら、できるだけ役立つように答えてください。答えは簡潔に日本語で回答してください。回答には、有害、非倫理的、人種差別的、性差別的、有毒、危険、または違法なコンテンツを含めてはいけません。回答が社会的に偏見がなく、本質的に前向きであることを確認してください。\n\n質問が意味をなさない場合、または事実に一貫性がない場合は、正しくないことに答えるのではなく、その理由を説明してください。質問の答えがわからない場合は、誤った情報を共有しないでください。\n<</SYS>>\n\n質問に答えることで、次のエージェントの応答を生成します。タイトルが付いたいくつかの文書が提供されます。答えが異なる文書から得られた場合は、あらゆる可能性について言及し、文書のタイトルを使用してトピックまたは領域を区切ってください。与えられた文書に基づいて回答できない場合は、回答がない旨を記載してください。\n\n”).concat(passages).concat(“\n\n[question]: “).concat(query_text).concat(“[/INST]”) |
以上で設定は完了です。
さっそく Assistant から問い合わせをしてみます。
- 右下の「Preview」をクリックします。
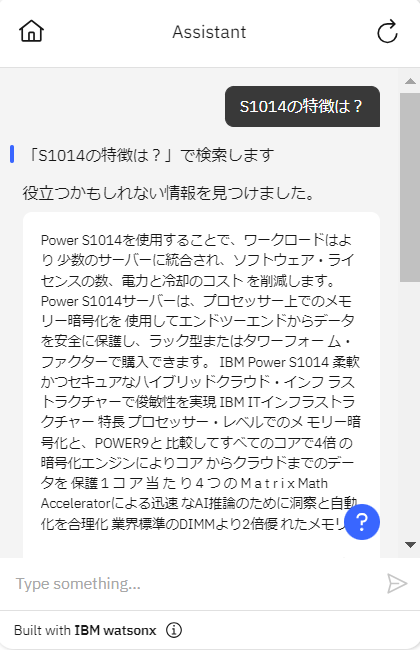
- チャットから S1014 の特徴について問い合わせしてみます。
約18秒後に以下の回答が返ってきました。
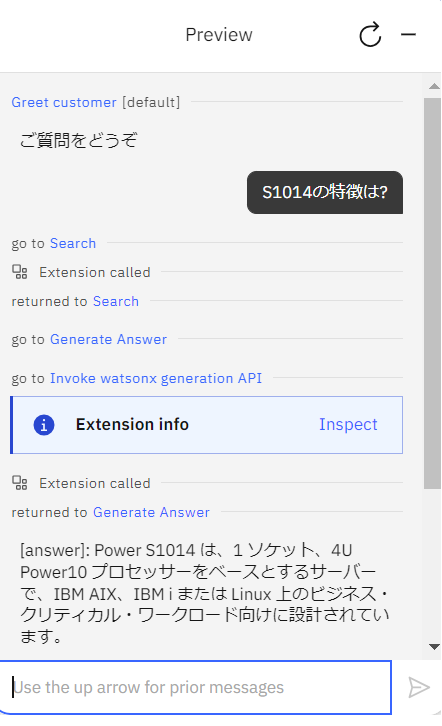
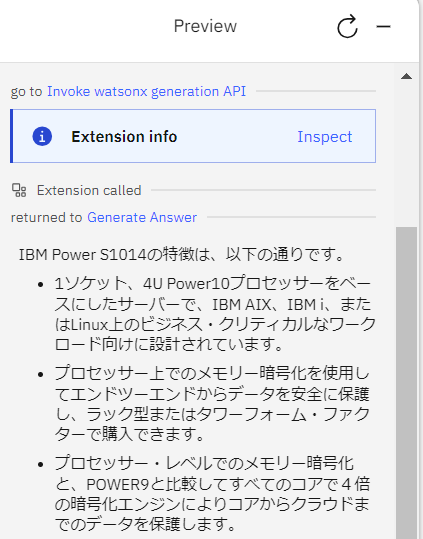
- 「Inspect」をクリックすると、Discovery の検索結果が以下の通り watsonx.ai に渡されていることがわかります。
| <s>[INST] <<SYS>> あなたは親切で、礼儀正しく、誠実なアシスタントです。常に安全を保ちながら、できるだけ役立つように答えてください。答えは簡潔に日本語で回答してください。回答には、有害、非倫理的、人種差別的、性差別的、有毒、危険、または違法なコンテンツを含めてはいけません。回答が社会的に偏見がなく、本質的に前向きであることを確認してください。 質問が意味をなさない場合、または事実に一貫性がない場合は、正しくないことに答えるのではなく、その理由を説明してください。質問の答えがわからない場合は、誤った情報を共有しないでください。 <</SYS>> 質問に答えることで、次のエージェントの応答を生成します。タイトルが付いたいくつかの文書が提供されます。答えが異なる文書から得られた場合は、あらゆる可能性について言及し、文書のタイトルを使用してトピックまたは領域を区切ってください。与えられた文書に基づいて回答できない場合は、回答がない旨を記載してください。[title]: IBM Power S1014 柔軟かつセキュアなハイブリッドクラウド・インフ ラストラクチャーで俊敏性を実現[document]: 1 コ ア 当 た り 4 つ の M a t r i x Math Acceleratorによる迅速 なAI推論のために洞察と自動 化を合理化 業界標準のDIMMより2倍優 れたメモリーの信頼性と可用 性を提供 IBM® Power® S1014 は、1ソケット、4U Power10プロセッサーをベースにしたサー バーで、IBM AIX®、IBM iまたは Linux®上のビジネス・クリティカルなワークロード 向けに設計されています。Power S1014を使用することで、ワークロードはより 少数のサーバーに統合され、ソフトウェア・ライセンスの数、電力と冷却のコスト を削減します。Power S1014サーバーは、プロセッサー上でのメモリー暗号化を 使用してエンドツーエンドからデータを安全に保護し、ラック型またはタワーフォー ム・ファクターで購入できます。 プロセッサー・レベルでのメモリー暗号化と、POWER9 と比較してすべてのコア で4倍の暗号化エンジンによりコアからクラウドまでのデータを保護 ますます高度に分散した環境に存在するデータには、もはや境界線を設定すること は不可能です。 [question]: S1014の特徴は?[/INST] |
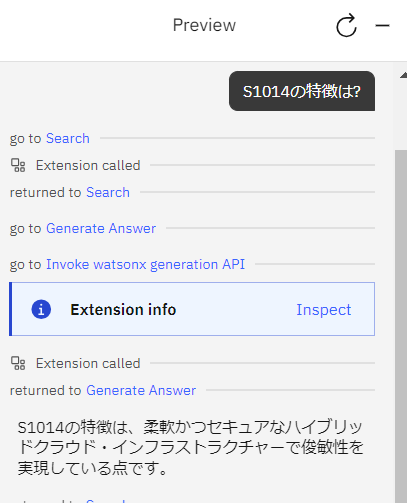
Assistant と Discovery のみの連携で検索した結果は以下の通りです。
watsonx.ai を使用した方がより簡潔で分かりやすい回答を得られることが分かります。
8. 言語モデルを変えて問い合わせの検証
言語モデルを “llama-2-70b” にして同様の問い合わせをしたところ、約24秒後に回答が返ってきました。
箇条書きで丁寧な印象です。
言語モデルを “elyza-japanese” にした際は10秒ほどで回答がありました。
主語として「S1014の特徴は」とあることで、問いに対する回答が分かりやすくなっています。
言語モデルを変えて試した結果、llama-2-70B は箇条書きで回答し丁寧な印象を受けましたが、回答が得られるまでに24秒かかりました。
一方 Granite-japanese や elyza-japanese はシンプルな回答を生成し、Granite-japanese は18秒、elyza-japanese は10秒というより短い時間で回答を得られました。
Watson Discovery の検索結果に基づき watsonx.ai で回答を生成するので、ある程度時間がかかると予想していましたが、elyza-japanese は速い回答で主語を添えてわかりやすく回答してくれました。
また、llama-2-70B は汎用的で使いやすいモデルですが、プロントで「日本語で回答して」と指示をしても問い合わせ内容によっては英語で回答することがありました。
日本語の回答精度を求める場合は、Granite-japanese や elyza-japanese を使用した方が精度の高い回答を得ることができます。
モデルを変えて問い合わせてみると、モデルごとに得意なタスクが異なることがわかりました。
数百億のパラメータで訓練された大規模言語モデルを一概に選択するのではなく、言語やタスクの特性に合わせて最適なモデルを選定することが重要になりそうですね。
さいごに
いかがでしたでしょうか。
Github から提供されているスターターキットを使って Assistant、Discovery、watsonx.ai を繋げてみましたが、ほどんど躓くことなく UI から簡単に設定することができました。
接続自体に高度な難しさは感じませんでしたが、問い合わせに対して正確な情報を得るためには Assistant の検索設定を調整する必要があります。
今回は1つの PDFファイルの検索を行いましたが、複数の PDFファイルから情報を引き出す際には Assistant で query を設定することで特定の PDFファイルからの検索が可能です。
このように PDF などの非構造化データを検索対象として精度の高い回答を得るには、Discovery において文書の構造を明確に定義し、Assistant の検索設定を調整することが必要です。
実際にヘルプデスクなどの Webチャットで利用する場合は、Assistant にあらかじめ用意した回答をルールベースで回答させ、それでも解決できない問い合わせについては Discovery を通じて検索を行い、watsonx.ai を用いて回答を生成するという流れが効果的です。
ただし、生成AI によって生成される回答は常に”100%正確な回答”ではないので、より高い精度の回答を追求するためにはプロンプトの調整などチューニングを施すことが必要です。
その結果、より使いやすい Webチャットの実現が期待できます。
お問い合わせ
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp