
IBMの岡田です。前回の「全包囲網。。。最新 IBMストレージ 概要」はいかがでしたか?
今回は、今流行りのコンテナ環境とIBMのストレージがどのようにこれらの環境に対応しているのかに触れてみたいと思います。
コンテナって何?
ある調査によると、クラウドファーストを掲げて次々とクラウド環境に IT を移していくといった流れは世界中の ITワークロードの5分の1ほど移ったところで一段落していると言われています。今日では従来型IT環境、仮想化環境、プライベートクラウド環境などのオンプレミス環境と、複数から成るパブリッククラウド環境を上手く使い分ける時代に入ってきたという人もいます。
何れにせよ、今後の IT はこう言った環境の種類に依存することなく、適材適所かつ必要に応じていかなる環境でも同じようにアプリケーション開発や検証ができ、完成されたアプリケーションをどこでも同じように作動させることができ、場合によってはそれぞれの環境で連携して動くと言った技術が必要になってきます。
この要求に応えることができるのがコンテナ技術です。
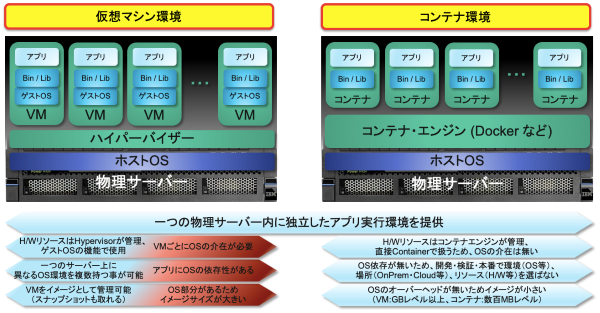
図1. 仮想環境とコンテナの比較
コンテナのメリット
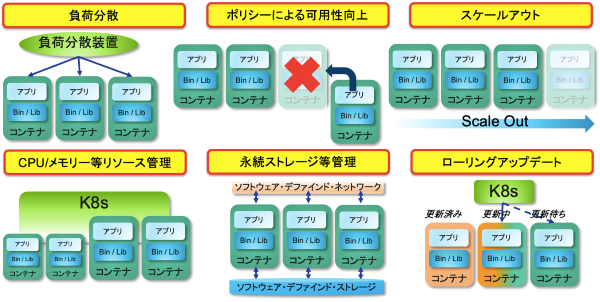
図2.コンテナを使うことのメリット
どうしてコンテナ技術を用いるとこれらの要求を解決することができるのでしょうか?
それはコンテナ技術を用いることで、動かすべき対象つまりアプリケーションと、動かすための環境つまりインフラストラクチャーを明確に分けることができ、前者は同じコンテナ基盤であればどこでも同じように動かすことができ、後者はどんなプラットフォームでもこのコンテナ基盤を使えばどこでも同じ動作環境をアプリケーションに提供することができるからです。
別の見方をすると、従来型IT環境では機能要件と非機能要件を分けて考えることが時には困難な場合もありましたが、コンテナ環境ではこれらを明確に分けることができるわけです(図3参照)。
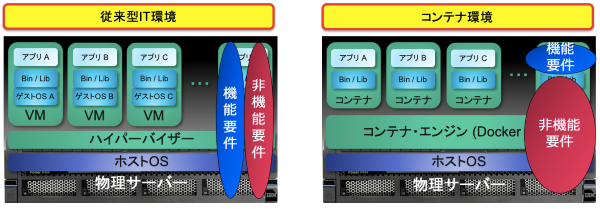
図3. 従来型IT環境とコンテナ環境での考え方の違い
Red Hat OpenShift について
このようなコンテナですが、その方式はいくつか存在し、ここ数年いろいろな方々が実際に触っていくうちに自然と多くの人に使われるものが絞られてきました。
また、その周りを司る管理機能についてもやはり幾つかの方式からここに至ってある程度代表的なものに絞られてきました。いわゆるデファクトという呼び方をしたりするものですが、恐らく現在デファクトのコンテナ用オーケストレーターと言えるものは Kubernetes ではないでしょうか?
この Kubernetes についての詳しい話はネット上にも沢山出てくると思いますので、ここではこれ以上触れません。
ちなみに最近はよくこの Kubernetes を “K8s” と書くことがあります。この K8s の “8” は Kubernetes の頭の “K” と最後の “s” に挟まれた “ubernete” の8文字を表しています。
Ruby 関連で i18n が internationalization を指すのと同じことです。そもそも IT の根本は如何にシステムを使って楽するかという怠け者の発想ですのでこんな略し方もわかる気がしますね。
(以下このブログでは、”Kubernetes” を “K8s” と表記します。)
さて本題に戻ります。
K8s 環境は実際にちゃんと作ろうとすると、周辺機能を選びつつ構築していくことが必要となります。
またこれらは通常 OSS で組むこととなるため、ミッションクリティカルな環境への適用は、何かあった際のクイックなサポート等の面から非常に難しくなります。
Red Hat OpenShift は、K8s を中心に置き、必要な周辺モジュールを全てパッケージ化した上で評価を完了させてある商用パッケージです。
そのため、要らぬところに労力を割くことなく、正しい K8s環境を短時間で構築することができます。しかも、商用であるがゆえに保守等もちゃんと付いています。
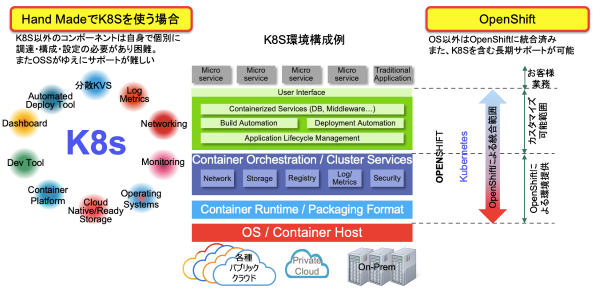
図4.OpenShift について
IBM はこの OpenShift をベースに各用途向けにコンテナ化された IBMソフトウェアを搭載し、パッケージ化した6つの IBM Cloud Pak というソリューションを提供しています。
(※詳しくは「製品・ソリューション/ソフトウェア」内で紹介されている、各種 IBM Cloud Pak をご参照ください。)
コンテナ環境下でのストレージのあり方
コンテナのメリットは先程ご説明しましたが、その中でも特にポータビリティという点は十分に考えられたソリューションです。
しかし、果たしてそれだけで十分でしょうか?
アプリケーションの作りにもよりますが、普通にコンテナ内のストレージを使いアプリケーションを動かすと、コンテナが不要となり消し去った際データも一緒に消えてしまいます。
複数のコンテナを並列に動かすような作りの場合にはデータを連携する必要があるかもしれません。
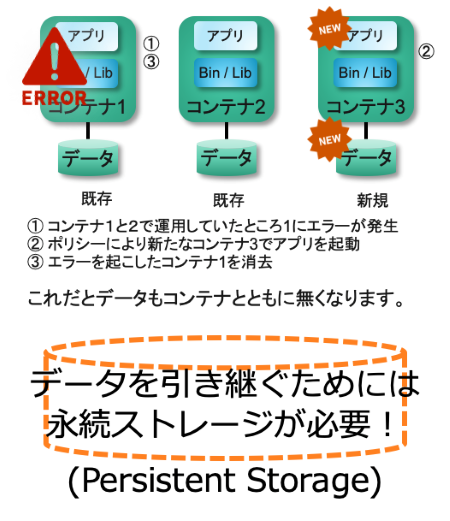
図5.永続ストレージの必要性
つまり、コンテナから独立したデータの器が必要となります。
これが永続ストレージというものです(図5参照)。
最近の IT の記述書などでよく “PV” という文字を見かけます。それは “Persistent Volume” の略であり、永続ストレージはその PV を使って定義づけられます。
では、永続ストレージにはどのような接続形態があるのでしょうか?
永続ストレージの接続形態
図6で示す通り、永続ストレージにはいくつかの形態があります。ちなみに一番左は通常のコンテナでのストレージのあり方で、この方法だとコンテナと共にデータは消えることとなります。
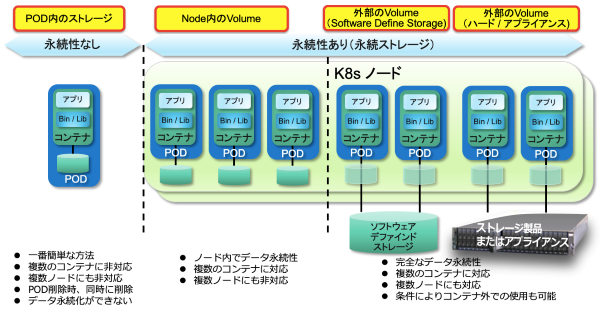
図6. K8s 環境でのストレージのあり方
ノード内の永続ストレージという点では OpenShift においては Red Hat OpenShift Container Storage が使われます。こちらはノード依存性がありますので複数ノードにまたがって連携することはできません。
それに対し、外部にストレージを保つ方法があります。ソフトウェア・デファインド・ストレージかハードウェア製品かに関わらず、K8s ノード外にあるストレージを使うため、仮にノードごとに何らかの理由で停止するようなことがあってもデータはキープされます。
(※どのような製品が対応可能かは後ほど触れます。)
これらの接続方法は、実は K8s のバージョンによって変わってきます。
ここでは K8s を包含した OpenShift のバージョンでお話しします。
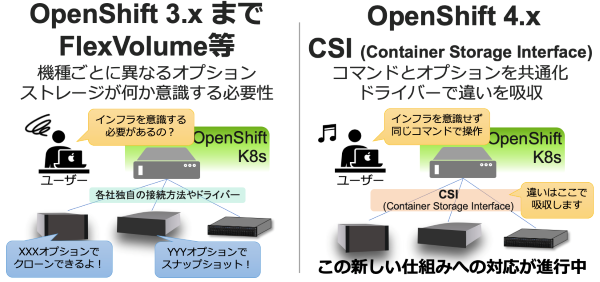
図7. OpenShift のバージョンによる接続方法の違い
CSI
CSI とは Container Storage Interface の略です。K8s のストレージはこうあるべきという考えに基づき、K8s とは独立にプロトコルを標準化したものです。
よって、CSI を使うことで K8s ユーザーはストレージのメーカーや製品を意識することなく同じに使うことができるようになります。逆に言うと各メーカーの優位性を出すことが難しくなります。
とは言え、IBMストレージとしては後述の通りハードウェア製品とソフトウェア・デファインド・ストレージ製品との連携でより便利に使うことが可能です。
IBM のストレージ対応
さて、ここまではどちらかと言うとコンテナ側のお話をしてきましたが、いよいよ IBM のストレージの対応についてお話していきましょう。
ブロックストレージ編
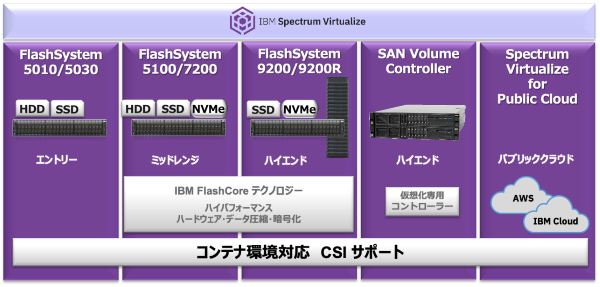
図8. IBM のブロックストレージの CSI 対応状況
IBM FlashSystem は、IBMストレージのブロックストレージにあたります。
FlashSystem はいち早く CSI にも対応しています。
もちろん FlashSystem 同様 IBM Spectrum Virtualize ファミリーのアプライアンス製品 SAN Volume Controller も、ソフトウェア・デファインド・ストレージとしてクラウド上にポーティング済みの IBM Spectrum Virtualize for Public Cloud も、対応済みです。
オンプレミスとパブリック・クラウド間でのデータ連携も永続ストレージ間で実施できるため、コンテナ上のアプリのポータビリティをオンプレミスとパブリック・クラウドの間でデータも含めて実現することができます。
実際、図2で示したコンテナのメリットは、ちゃんと永続ストレージを使ってどのプラットフォーム上でもできないと完璧にこなすことはできません。これが IBM のコンテナ対応のバリューです。
当然のことながら、フラグシップであるところの DS8000シリーズも CSI 対応済みです。
ファイルストレージ編
次にファイルストレージについて見てみましょう。

図9. IBM のファイルストレージの CSI 対応状況
IBMのファイルストレージと言えば、IBM Spectrum Scale というソフトウェア・デファインド・ストレージ製品ですが、アプライアンス製品として IBM Elastic Storage Server という製品があります。(第一回目のブログでもご紹介しましたね。)
この ESS についても CSI 対応済みということになります。
こちらも IBM Spectrum Scale の機能を使ってプラットフォーム間でデータを連携することができます(Active File Management 機能は後日別の回での解説を予定しています)。
IBM Spectrum Scale を用いると、ある面白いこともできます。
これも詳しくは後日解説しますが、少しだけお話すると、IBM Spectrum Scale は NAS、オブジェクトストレージを含むマルチプロトコル対応です。CSI で静的プロビジョニングを用いてコンテナからアクセスできるようにすると、既存で NAS 等で使っているボリュームを見せることも可能となります。
さらに IBM Spectrum Scale は Unified Access という機能で同じファイルを NAS としてもオブジェクト・ストレージとしても共有できる機能があるため、コンテナでも同一ファイルを使うことが可能となり、実質的に従来型IT とコンテナとの間でもデータが連携できることになります。
従来型のシステムとコンテナのアプリ間でデータ連携できることのメリットは、まさに最初に述べた環境を用途などで使い分ける現在の IT環境には無くてはならない機能です。
これも IBMストレージの大きなメリットです。
ハードウェア製品、アプライアンス製品、ソフトウェア製品を通じてブロックストレージ、ファイルストレージ共に IBM はコンテナ対応済みであると言えます。
オブジェクト・ストレージ編
オブジェクト・ストレージは基本的に RESTful API による HTTP 接続が使われます。
よってコンテナに限ったことではありませんが、ブロックやファイルストレージとは異なり、独自ドライバや CSI を介する必要はなく、アプリケーションから直接 I/O することが可能です。
IBM は IBM Cloud Object Storage というソフトウェア・デファインド・ストレージを扱っています。
また IBM Spectrum Scale もオブジェクト・ストレージとして使用可能です。
オブジェクト・ストレージについては AI&Bigデータの回で詳しくお話することにしましょう。
ソフトウェア・デファインド・ストレージのもう一つの対応

図10. IBM Storage Suite for IBM Cloud Paks
現在取り扱っているコンテナ対応済みソフトウェア・デファインド・ストレージを取りまとめて、IBM Storage Suite for IBM Cloud Paks という名前で IBM Cloud Paks 向けに提供を始めました。
ここには IBM の前述のソフトウェア・デファインド・ストレージ製品3つと、メタデータ、タグマネージメントといった機能を持った IBM Spectrum Discover、それに Red Hat OpenShift でネイティブなRed Hat OpenShift Container Storage と根強いファンの多い Red Hat Ceph Storage を加えた6つをワンパッケージにしました。
この Suite 製品の面白いところは、OCS(Red Hat OpenShift Container Storage)の契約 VPC数(契約対象の仮想プロセッサコア数)に応じた容量分を自由に何種類でも組合わせて使うことができるというところです(もちろん単体で全容量使うのもありです)。
この手のコンテナ環境・クラウド環境でストレージを使うことは、はじめは何をどのくらい使うべきかわかっていない状況だったりするものです。特にアジャイル、アジャイルと言われる昨今、「とにかくやってみよう」という傾向が強いのも事実です。
そんな時にこのパッケージを使うと、容量を超えない限りどのストレージをいくら使っても自由ですので、使ってみて決めていくということができます。
まさに現在のクラウド時代にふさわしいストレージパッケージと言えるでしょう。
今回のまとめ
ここまで見てきた通り、IBM のストレージ製品は2020年7月現在取り扱っているものとしてはブロック、ファイル、オブジェクト・ストレージであり、これらすべてコンテナ対応が完了しています。
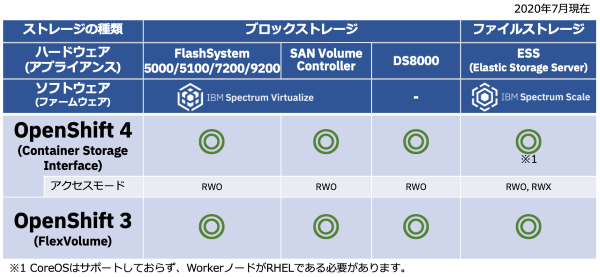
図11. IBMストレージの OpenShift 対応状況
Red Hat OpenShift あるいは各種 IBM Cloud Pak においては、接続性も含めて検証済みであり安全にお使いいただけます。
もしコンテナ環境をご検討中であれば、ハードウェアもクラウド上のソフトウェア・デファインド・ストレージもあり上下のデータ連携が可能な IBM のストレージ製品を、ぜひご活用ください!
お読みいただきまして、ありがとうございます。
次回はハイブリッド・クラウド、マルチ・クラウドに適切なストレージについてお話する予定です。お楽しみに!
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBMストレージ製品 (製品情報)
- 全包囲網。。。最新 IBMストレージ 概要 (ブログ)
- 最新のデータライフサイクル管理とは?(前編)(ブログ)
- 最新のデータライフサイクル管理とは?(後編)(ブログ)
- ハイブリッド/マルチクラウド時代だからこそIBMのストレージ (ブログ)
- AI導入はどこまで現実的? 5大ハードルとその解決策を解説 (ホワイトペーパー)
- 普及が進む、機械学習による異常検知。導入の課題はここまで解決している (コラム)