
IBMの岡田です。
前回の「OpenShiftに代表されるコンテナ環境へのIBMストレージの対応」でも触れた通り、ここ数年の傾向として何でもかんでもクラウドに移行するという時代は過ぎ、従来型の IT インフラとクラウド環境とを上手く使い分け、あるいは連携しながら、目的の業務アプリケーションを動かしていく方向になりつつあります。いわゆるハイブリッドクラウドというものです。
そして、パブリッククラウド自体もそれぞれのサービスにより使い分ける風潮があり、今やパブリッククラウド・ユーザー企業の半分以上が、複数のパブリッククラウドを使っているのではないかと思われます。いわゆるマルチクラウドと呼べるものですね。
しかし、なかなか統合的に管理するというところにまでは至っておらず、クラウドを含めたサイロ化が起こっている状況です。
このような運用ではアプリケーションの適材適所はおろか、データさえ十分に使えていないことは明白です。
今回はこのようなハイブリッド/マルチクラウドの状況の中でデータを上手く連携し活用していくために、IBMのストレージにできるソリューションを紹介しましょう。
ハイブリッド/マルチクラウドの位置づけ
以下の図は、ハイブリッドクラウド、マルチクラウドを模式的に表したものです。
オンプレ環境のプライベートクラウドまで含んでマルチクラウドという人もいますし、従来型の物理サーバーや仮想化された VM 環境もハイブリッドクラウドのオンプレミス部分の一部と考える人もいます。人によっても会社によっても捉え方は色々ですが、ここでは敢えて従来型 IT もハイブリッドクラウドの一部として話をしたいと思います。
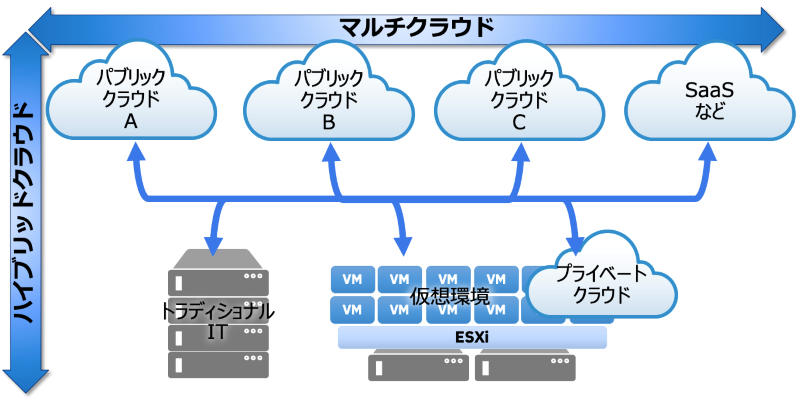
図1. ハイブリッドクラウドとマルチクラウド
IBM Spectrum Virtualize for Public Cloud とは!?
IBM Spectrum Virtualize for Public Cloud(SV4PC)は、第一回目、第二回目のブログでも登場した IBM のメインストリームとなるブロックストレージ、FlashSystem にも搭載されている管理機能ソフトウェア、これをパブリッククラウドでも使えるようしたものです。
つまり、SV4PC はハイブリッドクラウドやマルチクラウドに対応したストレージ製品です。
SV4PC を知れば FlashSystem を知ることができますので、SV4PC の機能を紐解いていきましょう。
外部仮想化機能
2003年、この Spectrum Virtualize ファミリーの元となる製品が生まれました。SAN Volume Controller、通称 SVC です。
今でもこの製品は最新のテクノロジーを装備してファミリーの一員です。(IBM Spectrum Virtualize for Public Cloud も Spectrum Virtualize ファミリー製品です。)
そこから脈々と受け継がれた外部仮想化という機能は、IBM および他社ストレージ製品約500種類を配下に接続可能で、これを仮想化して自身のストレージとして扱うことができるものです。
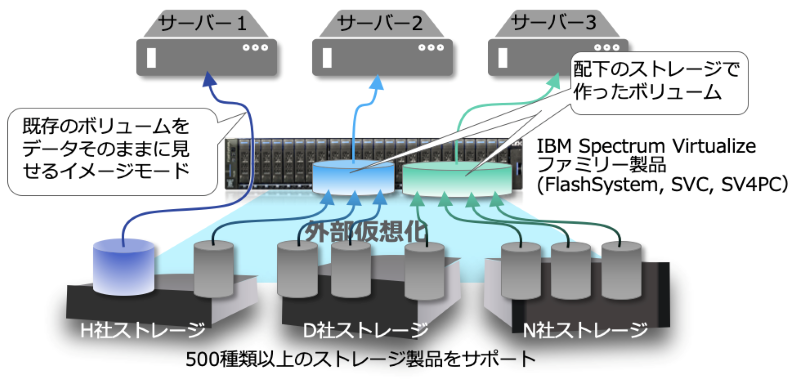
図2 外部仮想化機能
もちろん、既存で使われているストレージのボリュームや保存されたデータを生かしたまま配下に収めることができるため、オンライン・データ移行はもちろん、コピーサービス(スナップショット等の機能)を持たないストレージにそういった機能を与える事もできます。
この機能を使う事で、FlashSystem では他社製品を含めた古い製品から簡単に最新のテクノロジーにデ
パブリッククラウド上では、
これにより、最新のデータ削減機能の他、
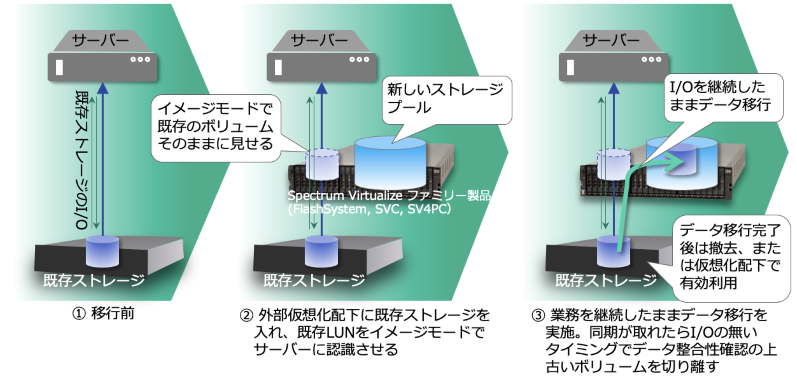
図3. データ移行のイメージ
様々なデータ削減機能
FlashSystem 5010 を除く Spectrum Virtualize ファミリーには、いくつかのデータ削減機能があります。
これらは DRP(Data Reduction Pool)というデータ削減にはなくてはならない機能を実装した Spectrum Virtualize ファミリー特有のストレージプール上で実現されます。また DRP での各処理単位はフラッシュ系デバイスに最適化されています。
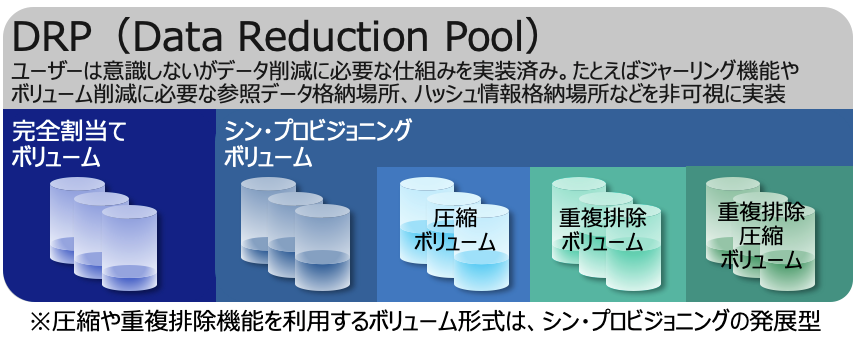
図4.Data Reduction Pool
具体的には「リアルタイムデータ圧縮機能」「重複排除機能」「
※詳しくは補足をご覧ください。
Spectrum Virtualizeファミリーのハイブリッドクラウド/マルチクラウド対応
触れてきた通り IBM の Spectrum Virtualize ファミリーであれば、オンプレミスの FlashSystem あるいは SVC とパブリッククラウド上の SV4PC とでデータ連携できるので、データの観点でハイブリッドクラウド対応ができます。
また、パブリッククラウド同士でデータ連携することもそれぞれに SV4PC を置くことで可能となり、マルチクラウド対応もできます(2020年7月時点、IBM Cloud と AWS に対応)。
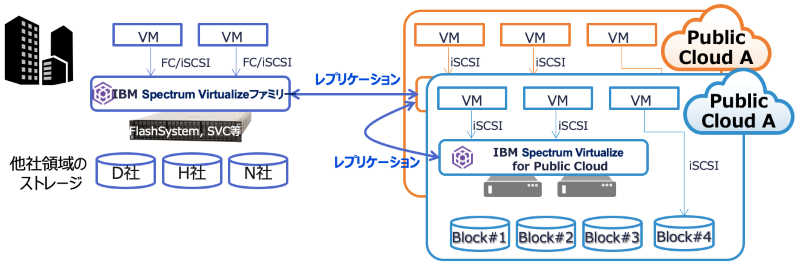
図5. ハイブリッド/マルチクラウドのデータ連携
さらにこの方法を使えば、他社の既存データも活かすことができます。外部仮想化機能が使えるからです。
つまり IBM の Spectrum Virtualize ファミリーを使うと、他社ストレージ製品も含めてハイブリッドクラウド対応できる事になります。
では、データをハイブリッド/マルチクラウド連携できると何が嬉しいのでしょうか。
ハイブリッドクラウド/マルチクラウドの利点
グローバルでは、一番広く使われているのが災害対策用途です。
被災時に本番環境が使えなくなった際も、パブリッククラウド側で仮想サーバー、コンテナなどを使い業務を継続できるからです。
今求められるデータ活用としては AI/アナリティクスなどと言うものもあります。
オンプレミスで使えるものもありますが、手軽にやろうとすると各パブリッククラウド上で提供している AI サービスを使うのが早いですね。最初に触れた通りサイロ化されたデータをパブリッククラウドと連携するにもハイブリッドクラウドは有効です。
バックアップ先としてパブリッククラウドを使うと、いらぬ投資をすることなく遠隔保管が可能となります。
通常テープを使った遠隔保管ですと保管場所である拠点、定期的な搬送といった固定費が発生します。最悪の場合、本番業務側が被災した場合にもデータをリストアしなければならないことを考えると、保管場所にリストアする仕組みが必要となります。これも大きな投資となるでしょう。
パブリッククラウドをバックアップ先とした場合それだけで遠隔保管が実現でき、必要な場合のみ仮想サーバーも立てることができるため DR としての役割も果たせるのです。
また、クラウドに業務を移行するというケースもまだまだ発生しますね。
この際クラウドプロバイダーが提供している方法もありますが、移行対象となるデータが多量にあると、なかなか与えられた方法を用いて計画通りに移行することは困難な場合があります。特にプロバイダーから送られたハードウェアを仲介して行う方法は、移行の間は業務を止めて対応する必要があります。これではビジネス的なインパクトが発生します。
ハイブリッドクラウド形態でのクラウド・オンプレミス間のデータ同期であれば業務を止めずに対応でき、万が一クラウドに移行したことで何らかの不具合を生じた場合にも即座に元の環境に戻すことができます。
これらの有益なハイブリッドクラウドのデータ連携にマルチクラウドのデータ連携要素が加わると、更に有益なことがあります。
最近の風潮としては、パブリッククラウド上にデータを置く場合でもミッションクリティカルなものの場合には、AZ(アベイラビリティーゾーン)を跨ってレプリケーションを取ることが一般的になってきています。冗長性を保つという意味では、異なるパブリッククラウドにコピーを持つことも有効でしょう。
このような用途にもマルチクラウド・データ連携は役に立ちます。
またメジャーなパブリッククラウドは、基本的にグローバル展開をしております。
自身で海外にサイトを立ち上げる必要なく、容易に海外展開できるといった利点や、国内でも東阪の災対環境も手軽に築くことも可能です。
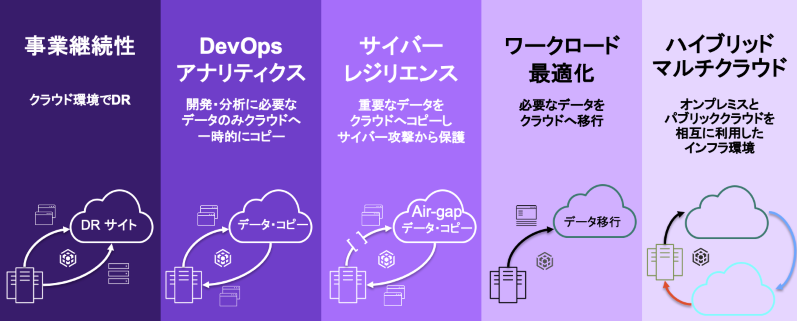
図6. ハイブリッド/マルチクラウドで実現できるソリューション
ハイブリッドクラウド・データ連携の具体例:クラウドへのデータ移行
パブリッククラウドに業務を移行する際に、ハイブリッドクラウドの接続形態を使うことで既存の業務を止めないオンラインデータ移行が可能です。(ただし既存ストレージの仮想化のための接続変更時は短時間ですが止める必要があります。)
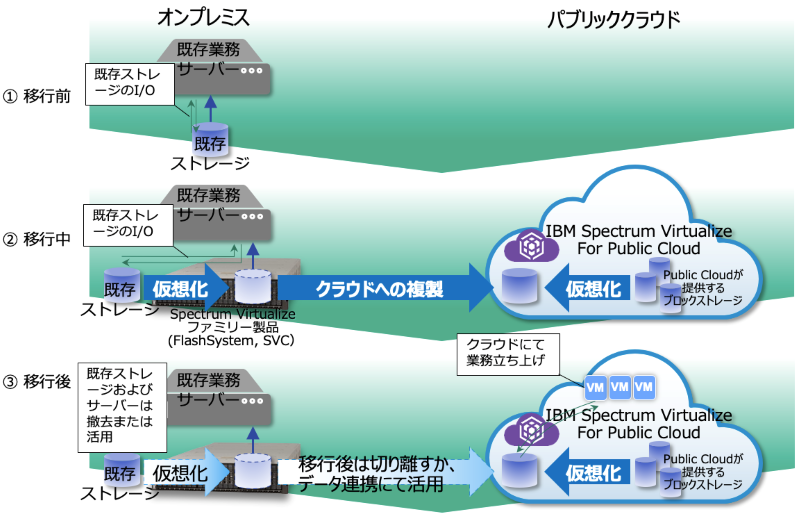
図7. ハイブリッドクラウド活用例・クラウドへのデータ移行
オンプレミスとパブリッククラウド、あるいはパブリッククラウド同士でのレプリケーションは方向を変えることも可能ですので、もししばらく使ってみて移行先で業務がうまくいかないなどの不具合が生じた場合は、データをオンプレミス側に戻すことも可能です。
他の活用例も結局はこのレプリケーションを使って双方を連携させることによりますので、アイディア次第でお客様の用途に合わせて色々な活用方法が見つかるかもしれません。
クラウド上ではこんな使い方も
SV4PC だけでも面白い使い方ができます。
多くのパブリッククラウドの環境下では、その環境内で使える仮想ブロックストレージが用意されています。
プロバイダーにもよりますが、大雑把に言ってしまえばクラウドは大規模な物理リソースを小出しにして使っている都合上、様々な制約があったり、性能の低いリソースを使わないとコストがかかりすぎるなど難しい局面も持っています。
例えば一つの仮想ブロックストレージの上限容量です。あるプロバイダーでは 16TB までしか使えなかったり、IOPS の上限にひっかかったりします。
このように、デフォルトのままではパフォーマンス要件をこなせないような場合でも、SV4PC で仮想ブロックストレージを複数束ねることで、仮想サーバー側に提供するストレージをスケールアウトすることができるので解決できたりもします。
また、データがホットな時期は SSD、旬が過ぎると HDD レベルで充分なデータを扱う場合、そもそも一時的なパフォーマンスのために全データを同じ SSD に置いておくのは無駄があります。
このような場合、最小限必要な SSD と充分な HDD を SV4PC で束ねつつ、前述の Easy Tier のような自動階層化機能を使うと、意識することなくホットデータは SSD で処理、その後は HDD へ配置されるので、クラウド上のストレージコストを全体的に減らすことができたりもします。
さらに、SV4PC のシン・プロビジョニング機能を使えば効率の良いコスト削減が可能となります。
通常の場合、仮想ブロックストレージの払い出しは見込み容量を先に決めてからその分払い出すことになり、運用後の拡張の手間を考えると、あらかじめ余裕を持った容量を払い出しがちです。この場合、実際に使用していなくとも払い出した容量は課金対象となります。
これに対しシン・プロビジョニングは、実際に存在する容量以上のストレージ空間を切り出すことができるのと、後から不足しそうな容量分の仮想ブロックストレージをストレージプールに加えることもできるので、最小限の容量から始めることができ、容量課金を削減することができます。
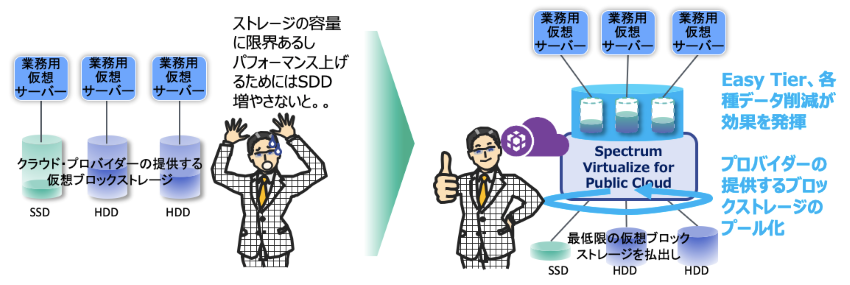
図8. パブリッククラウド上でのSV4PCの活用
なお何度も言いますが、SV4PC は今後のコンテナ環境にも対応しております。
ここまで見てきた通り、SV4PC はクラウド全盛の今だからこその機能を備えた Software Define Storage ソリューションであることが分かると思います。
いかがでしたか?
ハードウェアはもちろん技術の塊ですが、ソフトウェアのみでも十分に使える IBM Spectrum Virtualize ファミリー、少しは興味を持っていただけたのではないでしょうか?
次回は「最新のデータのライフサイクル管理」ということで ESS、Sepctrum Scale、オブジェクトストレージ、そして Spectrum Discover といった製品に触れてみたいと思います。
乞うご期待!
補足
1)リアルタイムデータ圧縮
バッチ処理で圧縮するのではなく、データの書き込み時に圧縮処理をして記憶域に書き込む圧縮方法です。FlashSystem 5030 と SV4PC を除きハードウェア・アクセラレータを活用できます。
もちろん 5030 および SV4PC もコントローラのリソースのみの処理ですが暗号化機能を実現しています。
圧縮率は、対象となるデータの種類によって異なりますが、一般にデータベース、メール、仮想サーバーイメージなどのファイルが高いと言われています。
以前はオフィスデータなども高かったのですが、最近はすでにオリジナルのオフィスファイル自体で圧縮済みですので、あまり効果は期待できなくなっていると言われます。
更に DRP の機能とは別に、IBM 特有の FlashCore モジュール(略して FCM。FlashSystem 5100, 7200, 9200/R で使用可能)であれば、モジュールそのものにインライン・ハードウェア圧縮機能があります。これはモジュール内のハードウェア的なデータの通り道にワイヤードロジックによる圧縮機能を設けているため、性能に影響を与えません。
ちなみにこのワイヤードロジックには暗号化機能も盛り込まれており、同様に性能に影響のない暗号化を実現しています。
2)重複排除
データのなかに同じパターンを見つけて、冗長なデータを削減することで容量を節約する機能です。特に仮想サーバーイメージなどには有効な手法です。
以前は非常に負荷がかかる作業だったため、バックアップなどに限定して使われていた技術ですが、昨今は性能の向上により、通常のストレージでも当たり前に使われる技術となりました。
以下は非常に単純化したインラインで扱われる重複排除のイメージです。バックアップ等での処理はこの限りではありません。
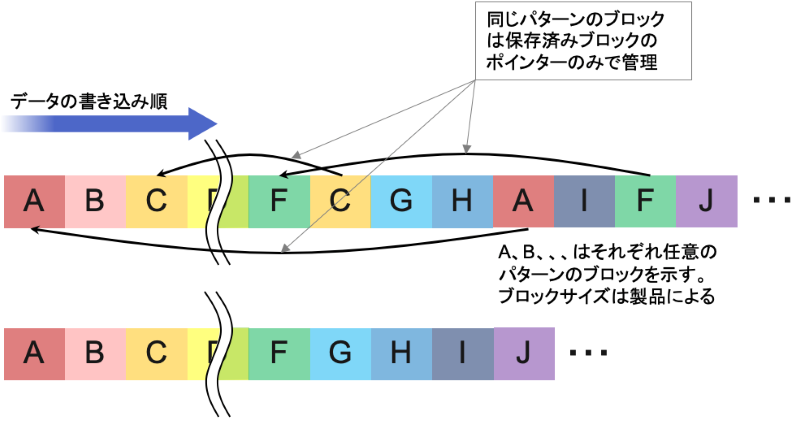
図9. 重複排除
実際はこう単純ではありません。
書かれたデータのパターンに応じたフィンガープリントと呼ばれる代替え値をハッシュ関数により導き、新たに書かれるデータのハッシュ値がすでに存在するフィンガープリントと一致している場合は、データそのものは書き込まず、参照するフィンガープリントのポインターのみを管理テーブルに記録する。これによりデータを間引くことができ、書き込み容量を削減することができるのです。
DRP 上での重複排除の特徴はフィンガープリントを同一ボリューム内のみならず、同じ DRP で定義された別のボリュームも含めて参照していることです(※図4参照)。同じプール内でバックアップなどのボリュームが定義された場合などに効果を発揮できるからです。
図4.Data Reduction Pool
3)シン・プロビジョニング
こちらは、データ削減と言うよりはサーバーから見た際の話になります。
通常、ストレージ装置側で定義したボリュームをそのまま OS で認識させ使用することになります。その際の容量は、ストレージ装置のボリューム定義そのままの容量となります。
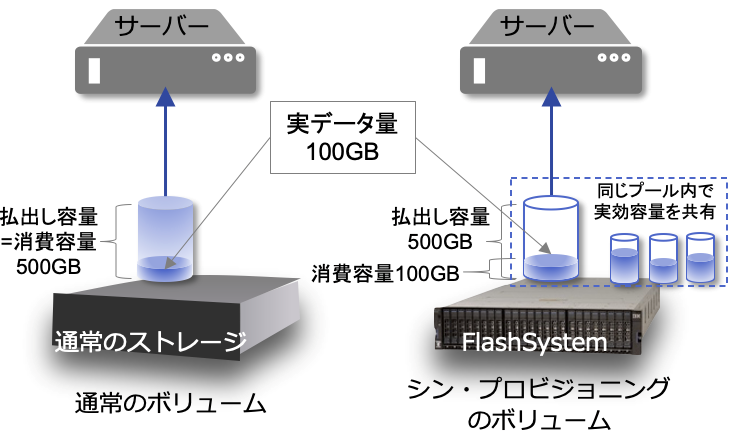
図10. シン・プロビジョニング
シン・プロビジョニングを使うと、その容量定義を物理的に存在しない容量も上乗せして定義することができます。この場合消費されるストレージ装置の容量は実際に書き込みが起こった時にそのデータ容量分ずつとなります。
もちろんその存在しない容量分に書き込みが発生するとエラーになりますので、そうなる前に物理容量を追加する必要があります。同じストレージプール内の複数のボリュームで、実際に存在する実効容量を共有して消費するといった使い方が効果的です。が、OS 側からは何も意識することがありません。
この方法は、実はパブリッククラウドのように払い出し容量で月額課金されるようなサービスでは、より有効な節約方法となります。
4)Easy Tier
Spectrum Virtualize ファミリーには、もう一つ特徴的な機能として自動階層化機能があります。
通常データの階層管理というと、ファイルレベルで実装するものをイメージされる方が多いのではないでしょうか?
Easy Tier はブロックレベルでありながらストレージの負荷情報を自ら学習し、アクセスの集中するホットなデータは Flash系のデバイス、アクセス頻度の低いデータは容量単価に優れる大容量・低速の HDD といった階層にデータを AI を使ってストレージの機能で動的に移動させる機能です。
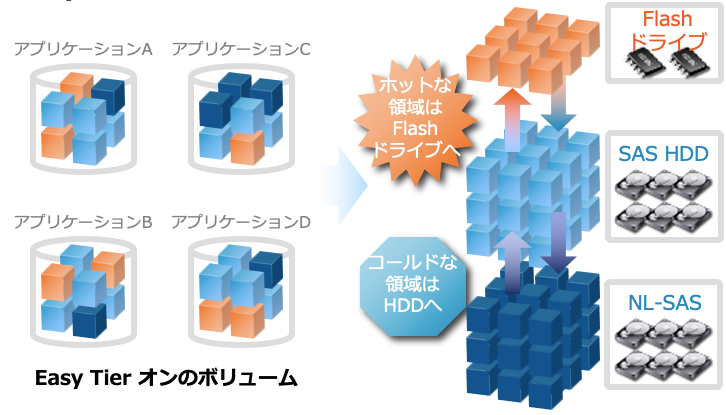
図11. EasyTierの動作イメージ
この機能を使うと高価な半導体系のストレージデバイスの容量を節約し、安価なハードディスクを増やすことで、パフォーマンスを下げずに全体の容量単価を下げることができます。
オンプレミスの FlashSystem はもちろん、払い出し容量で月額課金されるパブリッククラウドでも有効な節約手段となります。
5)コピーサービス
今や多くの廉価なストレージ装置もスナップショット、レプリケーションといった機能は当たり前になっています。
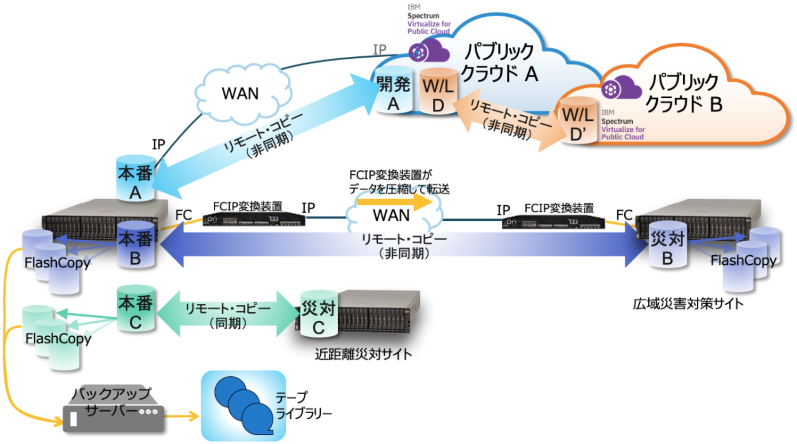
図12. 様々な用途に使えるコピーサービスの数々
スナップショットなどの瞬間のボリュームイメージを切り取る機能は、一般的にポイント・イン・タイム・コピーと呼び、IBM の場合は FlashCopy と言われる機能になります。
こちらは通常ストレージ装置内で使われる機能です。バックアップを取るときなどアプリケーションや RDB などと連携して、静止点をとるのに有効な機能です。
これに対して、ストレージ装置間で関連づけたボリューム同士で同期を取り、それぞれのボリュームを常に同じデータで満たす方法がレプリケーションです。
スナップミラー、ボリュームミラー、リモート・ミラーあるいはリモート・コピーなど、メーカーによって呼び方は様々ですが、基本的には時間的ズレのない同期型のものと、多少の時間的ズレを容認する非同期のものとに大別されます。
前者は銀行など災害などでのデータ損失を認めないような要件で使われ、拠点を跨ぐ場合、それなりの高価な設備(ネットワーク設備であったり拠点設備であったり)と共に使われます。後者はデータの多少の損失は容認するか、または別の方法(ログデータとかとの併用など)で補うかして、むしろ、より遠隔にデータを退避することを優先するなどの目的で使われます。広域災害などへの対策が多いですね。
考慮すべき事項に、特にレプリケーションは同じストレージ装置同士であると言う大前提があります。メーカーごとに使っている技術が異なるからです。
IBM の場合、Spectrum Virtualize ファミリーであれば相互接続が可能です。つまりオンプレミスのFlashSystem または SVC とパブリッククラウド上の SV4PC との接続が可能なのです。これが IBM ストレージがハイブリットクラウドに対応できると言う一つの根拠です。
もちろん前回触れた通り CSI(Container Storage Interface)にも対応していますので、コンテナ環境にも対応可能です。
接続方法について以前は、ストレージ機器同士の同期ということでより早く安全な FCP(Fibre Channel Protocol)に頼っていましたが、今日では非同期を前提に充分に IP 接続でも対応できるようになりました。
また、帯域以上のデータ転送を余儀無くされる初期同期が問題になりますが、前述のシン・プロビジョニング・ボリュームを対象とすることでボリューム全転送を必要とせず差分だけで可能となったり、データそのものも効率的な圧縮・重複排除の活用で小さくなったというのも大きいですね。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連ページ
- IBMストレージ製品 (製品情報)
- 全包囲網。。。最新 IBMストレージ 概要 (ブログ)
- OpenShiftに代表されるコンテナ環境へのIBMストレージの対応 (ブログ)
- 最新のデータライフサイクル管理とは?(前編)(ブログ)
- 最新のデータライフサイクル管理とは?(後編)(ブログ)
- AI導入はどこまで現実的? 5大ハードルとその解決策を解説 (ホワイトペーパー)
- 普及が進む、機械学習による異常検知。
導入の課題はここまで解決している (コラム)