
こんにちは。企画推進部の久田です。
今回は、昨今話題のブロックチェーンについて、考えたいと思います。
ブロックチェーンというキーワードは、ここ1~2年で露出が増えてきました。
仮想通貨の盛り上がりにより、「ブロックチェーン」に注目が集まってきていると思われますが、その「ブロックチェーン」や「仮想通貨」と聞いて、皆様はどのようなイメージを持たれますか?
日本では残念ながら一般的に、ブロックチェーン → 仮想通貨 → ビットコイン → 資産消失… という流れでなかなか良いイメージを持たれていない、というのが現状です。
世界に目を向けると、実は2008年頃からブロックチェーンへの取り組みが始まっており、ブロックチェーン技術への期待がどんどん高まっています。それは、オープンソースかつ中央集権的でないこの技術はある意味、上手く応用すれば、多岐に渡って使途が広がると考えられているからです。
日本企業のブロックチェーンへの取り組み状況
従業員数500人以上の日本企業を対象として2018年2月にガートナーが実施したブロックチェーンへの取り組み状況に関する調査の結果、42.6%の企業が、調査など初期的なものも含めブロックチェーンに何かしらの形で取り組んでいることが明らかになりました。
(図1. 日本企業のブロックチェーンへの取り組み状況参照)
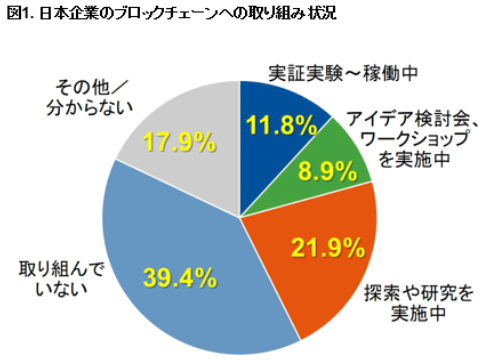
出典:ガートナープレスリリース 「ガートナー、ブロックチェーンへの取り組みに関する調査結果を発表 40%以上の日本企業は既に何らかの取り組みを開始していることが明らかに」2018年4月5日
「3年以内にブロックチェーンに取り組む日本企業は、60%程度に達するとガートナーでは予測しています。将来を見通した場合、ブロックチェーンの応用から社会が変化していくことは、ほぼ間違いないとみています」
出典:ガートナープレスリリース 「ガートナー、ブロックチェーンへの取り組みに関する調査結果を発表 40%以上の日本企業は既に何らかの取り組みを開始していることが明らかに」2018年4月5日
という状況のようです。数年後にはブロックチェーン技術を利用して新ビジネス創出は必然的な流れになってくると考えます。
そもそもブロックチェーンとは?
まず、「ブロックチェーン」について基本的なところの押さえとして、Wikipedia には、
「ブロックチェーン(英語: Blockchain、ブロックチェインとも)とは、分散型台帳技術、または、分散型ネットワークである。ビットコインの中核技術(サトシ・ナカモトが開発)を原型とするデータベースである。ブロックと呼ばれる順序付けられたレコードの連続的に増加するリストを持つ。各ブロックには、タイムスタンプと前のブロックへのリンクが含まれている。理論上、一度記録すると、ブロック内のデータを遡及的に変更することはできない。」
出典:「ブロックチェーン」 Wikipedia
とあります。従いまして「一度記録すると、ブロック内のデータを遡及的に変更することができない」ことが特徴で、主だった活用はデータ改ざんが許されない金融情報などでの活用から広がっていくと期待されています。
次はブロックチェーンの技術を活用した国際送金の例になります。
国連の難民支援に活用されているブロックチェーン
MIT TECHNOLOGY REVIEW の記事によると、ヨルダンにおける国連の難民支援にブロックチェーンが一役買っているとのことです。
2017年にWFP(World Food Programme)は食料支援全体の30%に相当する13億ドル強を金融機関に送金し、何百万食に相当する資金が手数料などとして消えてしまった(実際の食事にならなかった)。ブロックチェーンを利用することで(これはまだ初期の結果ではあるが)、手数料などを98%減らせたという。
出典:「ヨルダン現地ルポブロックチェーンが変える国連難民支援のいま」、『MITテクノロジーレビュー』(https://www.technologyreview.jp/)、角川アスキー総合研究所、アクセス日:(2018年10月17日)
ファイル共有などを行うための P2P 技術をベースとしています。中央集権的なサーバーを持たず分散型でデータを確保することが特徴で、大規模な投資を抑え、確実な台帳管理を可能にしています。
大規模投資を必要としない仮想通貨の根幹技術が、世界的な食料支援金の資金管理に活用され社会貢献している、というのは、日本でのイメージを払拭する活用方法ではないでしょうか。
地方自治体でも取り組みが開始されています
石川県加賀市では、ブロックチェーンの技術を中心に電子行政などの社会コスト削減と利便性向上や地域活性化分野の研究に取り組み始めています。
電子化の点ではブロックチェーンでなくても可能ですが、強固なセキュリティを必要とする場合には結果としてコストが嵩むケースが多いと思います。そこをブロックチェーン技術でコスト低減を図りつつ高いセキュリティの実現でコスト削減を目指されております。また、更にIT活用を進め、庁内での作業について自動化を促進して、市民が役所へ出向くといった面倒で時間のかかる作業への軽減も目指されております。
まずファーストステップとしては、本人認証基盤「KYC(Know Your Customer)認証基盤」を構築し、地域内サービスの認証を一元化することによるコスト削減や、集積したデータを活用した研究開発などから着手されるようです。
出典:「PC-Webzine 人口減少などの課題をブロックチェーン技術で解決へ~加賀市の取り組み~」
茨城県つくば市でのケースでは、ブロックチェーンの技術とマイナンバーカードを用いて国内初のインターネット投票の実証実験が実施されました。
実証実験では、投票内容の改ざん防止や秘匿性を確保しつつ、適正で効率的な投票の実現を目的として実施され、結果、投票の正当性、秘密投票、非改ざん性が、ブロックチェーン技術を活用した今回の投票によって実証されたと報告されております。
出典:「仮想通貨Watch つくば市、ブロックチェーンとマイナンバーカードを活用したネット投票を実施」
出典:「仮想通貨Watch つくば市のネット投票実証実験が成功、パイプドビッツが構築した投票システム」
このように日本のそれも地方自治体においてもブロックチェーン技術の活用は始まっています。今後、官民問わずこの流れは加速することが予想されます。
増々盛り上がるブロックチェーン技術をどのように活用すれば良いのか?
私見になりますが、日本ではガートナーのレポートからもわかるように、「Blockchain は取り組むべき技術ではあるが、どこから始めて良いかわからない」、という状況にあります。しかし、今後増々データ量が増え続けるという現実において、”どのデータを信用して良いか”、”改ざんされない安全なデータであることの証明はどうすれば良いか”という観点の取り組みが必要になってきます。そうなると、ブロックチェーンの技術が、様々な仕組みに取り込まれていくと考えるのが妥当でしょう。
どのように取り組むべきか、という点では、国内外400社以上のお客様とブロックチェーン構築した知見をもとにしたIBM Blockchain スタートアップ・プログラムを通じて、ノウハウを享受することが、ブロックチェーンに対するファーストステップの取り組みとして良いのではないかと考えます。
多数のブロックチェーン技術活用事例を保有する日本アイ・ビー・エム
あらゆる企業で Blockchain の取り組みが検討されていると思いますが日本ブロックチェーン協会の会員でJBAブロックチェーン部門の日本アイ・ビー・エムでは「Hyperledger Fabric」の基盤を用いて、サプライチェーンや地方創生への取り組み、委託作業や契約締結の可視化など、多数事例(知見)があります。
日本アイ・ビー・エムではIBM Cloudサービスである「IBM Blockchain Platform」の提供を通じて、「開発」「ガバナンス」「運用」までを包括したソリューションの提供が可能であり、具体的には「分散台帳(*1)」、「スマート・コントラクト(*2)」、「合意形成(*3)」、「暗号技術(*4)」の機能などを通じて、IBM Cloud 経由で本番利用に求められるシステム性能と高度なセキュリティーの提供をいたします。
(*1)分散台帳:取引履歴と資産の状況を保存し共有
(*2)スマート・コントラクト:取引ルールを規定し処理を自動化
(*3)合意形成:取引をシステム上で確定
(*4)暗号技術:匿名性や秘匿性レベルを選択して取引の安全性を確保および認証
まとめ
既に地方創生の分野で研究や実証実験に着手しているように、あらゆる分野でブロックチェーン技術の活用が広がってくると考えられます。
自動車や建設業界においては複数企業との連携で製造や建設が成立しているため、現場で取り扱うデータの管理という点でも有益な技術になります。
透明性という観点では、IoTとの連携による第一次産業でも活用されるだけではなく、増々 企業や各国での研究(取り組み)が盛んになり、今までは考えがつかなかった取り組みが生まれてくる可能性があります。
最新技術だけではなく、あらゆる動向にアンテナを張り巡らし、市場の流れという点も意識することも重要ではないでしょうか。