
皆さん、最近「Spark」という言葉をよく耳にされませんか?
「Hadoop と同様ビッグデータを分散処理で扱うソリューション?」「インメモリーで稼動するので高速処理できる開発基盤?」 のような認識をされているかもしれません。
Sparkは分散処理のフレームワークですが、アナリティクス・ソリューションにおける分散処理を行うアプリケーション開発において、これらはいずれも重要な特徴です。
今回のてくさぽBLOGでは、ビッグデータの分析アプリケーション開発基盤をご提案するうえでの特徴についてお話します。
ビッグデータの分析といっても、決まったパターンの分析では価値ある情報を手に入れることは困難です。
「勝つための何かを見つけ出す」 ためには「様々な切り口で分析を繰り返す」ことが必要です。
しかしながら、従来の基盤や体制ではこの「繰り返し」に効率よく対応できないため、以下の要件が必要となります。
- アプリケーション処理の高速化
- 迅速なアプリケーション開発
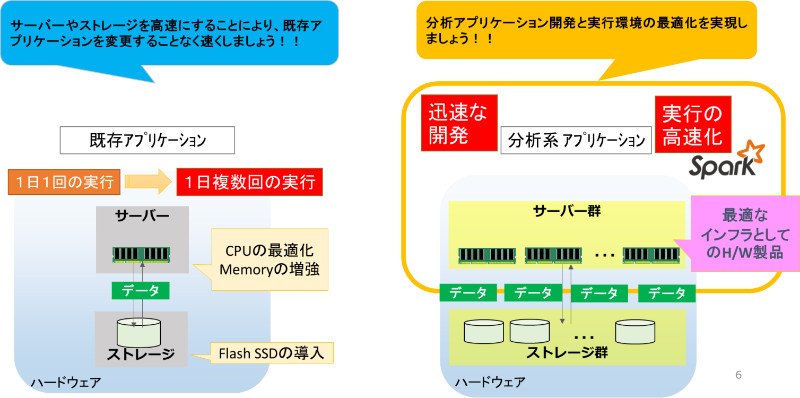
1.アプリケーション処理の高速化
今までは、インフラの能力を高めることで、1日1回しかできなかった分析を1日に何回も分析しようと考えていました。
しかし、力技で回数を増やすだけでは「様々な切り口で分析を繰り返す」ことはできません。
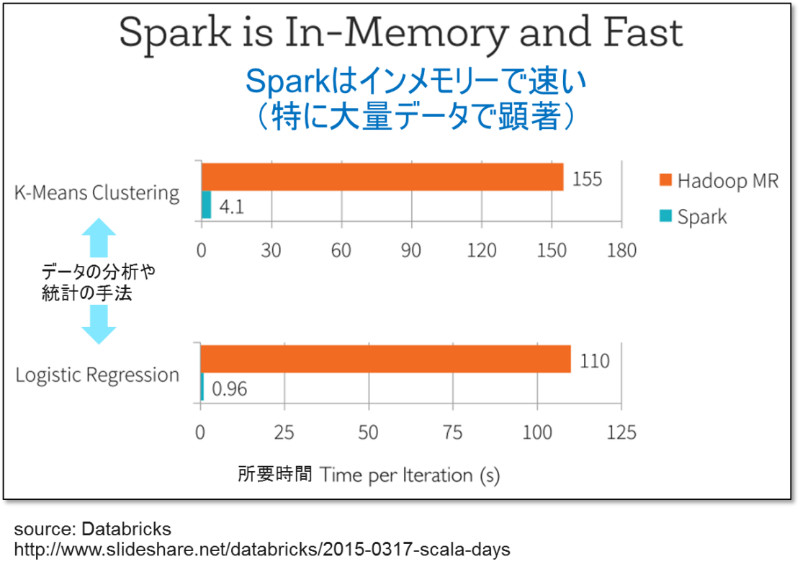
そこで、インメモリで分散アプリケーションを実行する環境であるSparkの出番です。
一般的にメモリ書き込み処理は SSD への処理に比べて1,000倍程度早くアクセスができます。つまり、同じ処理を実行した場合には、かかる時間が1,000倍違うということです。これは、単純計算で1日1回の処理が限界だったものが1,000回処理できるということを示しており、 Spark を使うことでアプリケーション処理の高速化が実現できるのです。
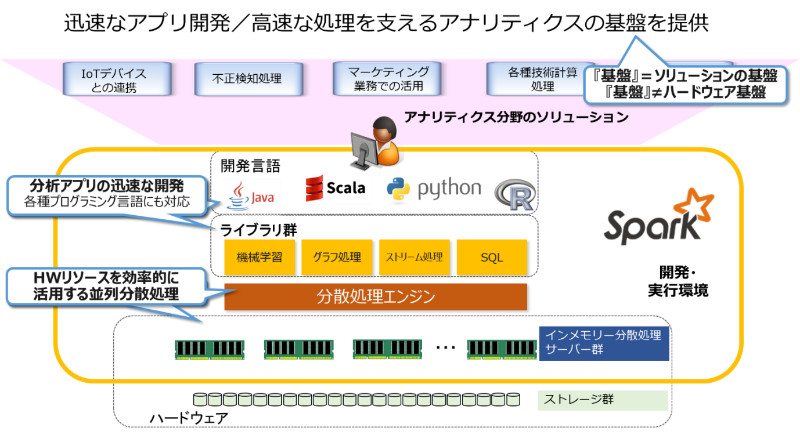
2.迅速なアプリケーション開発
また、様々な切り口のアプリケーションを開発するには、「アプリケーションをいち早く開発しかつ実行する」ことも重要です。アジャイル開発という言葉もよく耳にしますよね?
インメモリーの技術によりアプリケーションが迅速に処理できるようになったことで、素早く結果を得られるようになります。得られた結果を元に、さらに新たな仮説を立てて分析を実行するためにはアジャイル開発が最も有効な方法です。
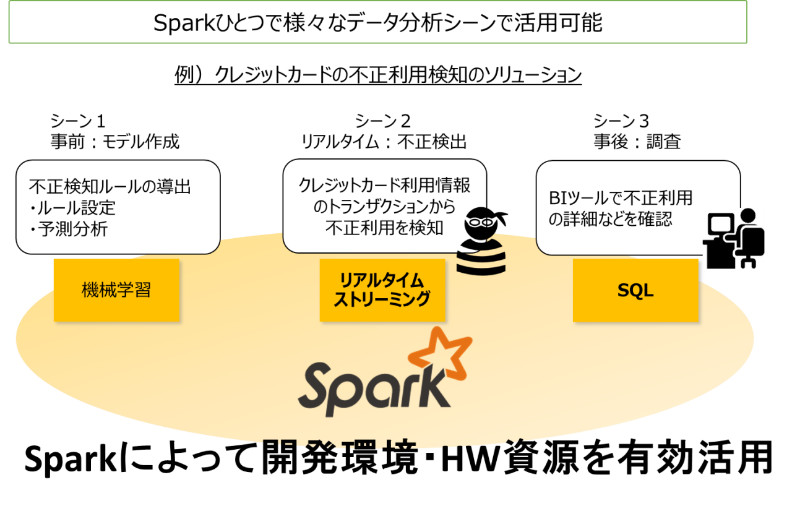
たとえば、下図のクレジットカードの不正利用検知ソリューションでは、一つの環境で3つの分析シーンに対応することができます。
このように、様々なシーンで活用されるアプリケーションを Spark ひとつで実現することができるのが大きな特徴であり、アプリケーション基盤が「サイロ」にならず、開発環境・HW 資源を有効活用することができます。
開発環境と実行環境を一体化できる Spark は、アジャイル開発に向いているソリューションと言えるでしょう。
加えて、Spark には分析アプリケーションの迅速な開発を支援する Scala、Python、R、Java といった「開発言語」とアナリティクス分野で利用される「ライブラリ群」が充実しているということも、迅速なアプリケーション開発を支える重要なポイントです。
3.Spectrum Conductor With Spark のご紹介
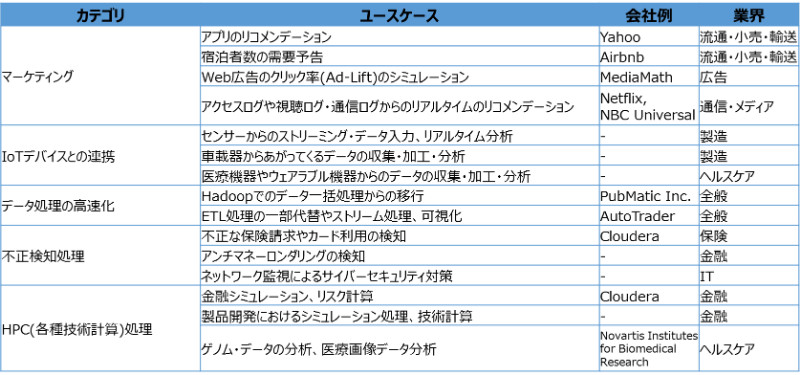
下表のように、Sparkは既に様々な業界でのデータ処理/分析のユースケースに適用されています。
幅広い分野で重要なアナリティクスのインフラ要素として、今後ますます利用が拡大すると考えられ非常に注目されています。
Spark を動かす環境は色々ありますが、ここではソリューションの一つとして Spectrum Conductor with Spark(SCwS)という製品をご紹介しましょう。
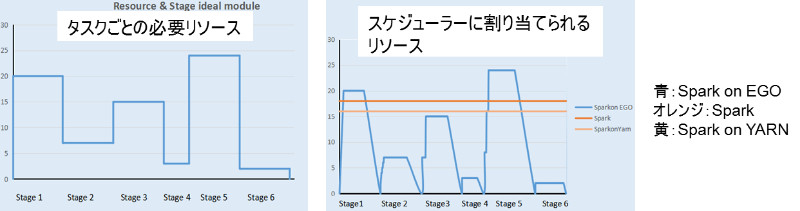
Sparkを使っていると、下図のようにユーザー毎に異なる環境が欲しくなることがあります。
又、Spark は非常に開発のスピードが速いため、ユーザーによって利用したい Spark のバージョンが異なることもあります。
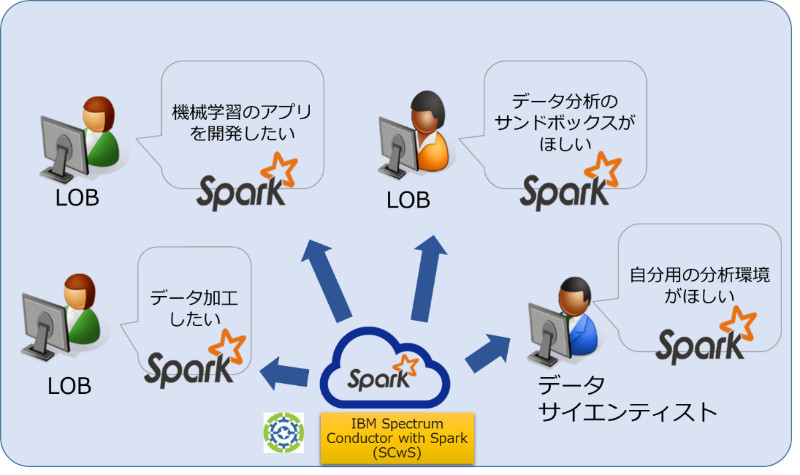
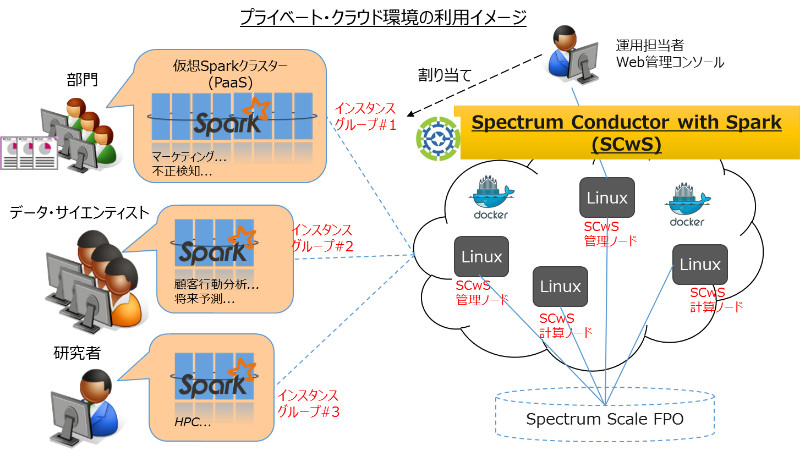
Spectrum Conductor with Spark なら、ユーザーやグループの要件に合わせて、必要な大きさ、バージョンの環境(インスタンスグループ)を仮想的に割り当てることが可能です。
Spark の特徴である、アプリケーション開発と実行のサイクルを迅速に回す環境にプラスして、より自由度の高い環境を提供できるだけでなく、高機能なスケジューラーでリソースの使用効率を高めることも可能です。
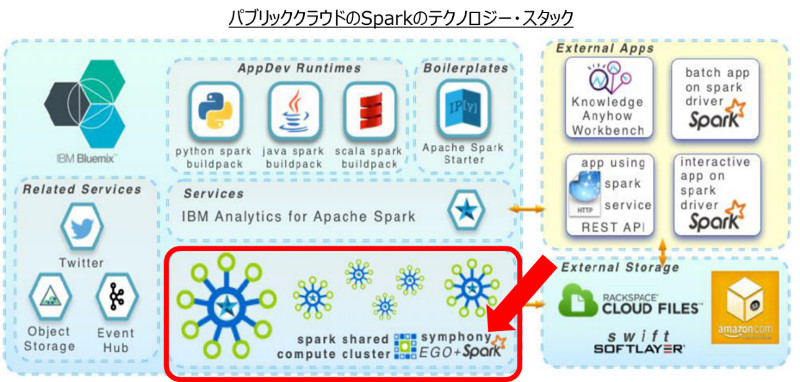
実は、IBM Bluemix で Spark クラウドサービスが提供されています。
この裏側でリソースのスケジューリング、ユーザーごとのセキュリティ分離、環境のプロビジョニングを支えているのが Platform Computing の EGO という優れたスケジューリング技術です。
Spectrum Conductor with Spark は、 Hadoop で通常利用されている YARN スケジューラーより優れたこの技術が利用されています。
4.Spark対応のIBM Systems Hardware製品
最後に、Systems HardwareとしてSparkに対応している製品をまとめてご紹介いたします。
ビッグデータ分析の基盤を構築したい!
- データ量300TB以下
- →IBM Data Engine for Hadoop/Spark (IDEHS)
- Power S812LC
- →IBM Data Engine for Hadoop/Spark (IDEHS)
- データ量300TB以上
- →IBM Data Engine for Analytics (IDEA)
- Power S822L
- IBM Elastic Storage Server (ESS)
- Spectrum Scale
- →IBM Data Engine for Analytics (IDEA)
さらに、先日 Hadoop をリードするベンダーである Hortonworks と IBM は、Hortonworks Data Platform (HDP) をPower Systems 上でサポートすることを表明しました。
これからますますこの分野のビジネスが加速され、Power Systemsの長所を生かせるようになってきますね!
5.まとめ
今回は Spark とはどういう特徴のあるものなのか、そしてどういう使い方をすることで効果的に利用できるのかを簡単にご紹介いたしました。
又、そのための環境について IBM製品をいくつか取り上げてご紹介させていただきました。
Spark を使う環境は今後どんどん増えていくでしょう。
まだ Spark を扱われていないパートナー様も近いうちに携わることになるのではないでしょうか?
その時には、このブログを少しでも思い出していただければ幸いです。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp