
こんにちは。
てくさぽBLOGメンバーの村上です。
本ブログは、IBM Power Virtual Server をトライしてみた内容や感想をご紹介するブログです。
シリーズ化していますので、まずインデックスのご紹介をします。
インデックス
・IBM Power Virtual ServerでAIX環境を作ってみた
・IBM Power Virtual ServerのAIX環境にSWを導入してみた
・IBM Power Virtual ServerのAIX環境を日本ロケールにしてみた
・IBM Power Virtual ServerのAIX環境をバックアップしてみた(Part.1)
・IBM Power Virtual ServerのAIX環境をバックアップしてみた(Part.2) ←今回
・IBM Power Virtual ServerのAIX環境とIBM Cloud x86環境を接続してみた
今回は、AIX環境のバックアップ手順のご紹介です。
検証環境で2種類のバックアップ方法を試しましたので、Part.1 とPart.2(本ブログ)に分けてご紹介しています。
本ブログでは 「AIX環境をバックアップしてみた Part.2」として、FlashCopy によるバックアップ手順をご紹介します。
セクション
以下の1)~4)のセクションに分けてご紹介します。
1) FlashCopy の説明
2) IBM Cloud CLI 導入
3) FlashCopy によるバックアップの事前準備
4) FlashCopy の実施
検証はAIXのインスタンスで行いましたが、IBM i のインスタンスでも同等の手順で操作を行うことができます。
利用したクライアント端末(私のPC)は、Windows10 pro バージョン2004です。
1) FlashCopy の説明
Power Virtual Server で実装する FlashCopy は以下の仕様となっています(IBM Cloud 柔らか層本 20210915版より)。
| 説明 | ・IBM Cloud で提供されており、外部ストレージ装置のコピーを実施する ・バックアップ/リストアの時間が大幅に削減できる ・NWデータ転送量を削減できる |
| 主な用途 | ・データベース領域のバックアップ(容量が大きいものにおススメ) ・VM全体のバックアップ |
| 対象 | rootvg を含む任意のボリューム |
| 保管場所 | 外部ストレージ装置 |
| 取得時の LPAR停止有無 |
不要 ※ ファイルの整合性担保のためにバックアップ前にはアプリの静止、LPAR停止が推奨される |
| 制約事項 など |
・リストア時はアプリ静止、LPAR停止が推奨 ・GUIは未実装であり、API呼び出しでのみ実行可能(2021年9月 時点) ・FlashCopy 先のストレージは無償で利用可能 ・インスタンス削除と同時にFlashCopy データも消失する |
FlashCopyとは、「Snapshot 」「Clone 」「Point in time Copy」とも呼ばれ、ある一時点のボリュームのコピーを作成する機能です。コピー元とコピー先は異なるLUN(ストレージのボリューム単位)を使用することができ、バックアップ手法として利用されています。
FlashCopy 先のディスクは課金されず無料で利用することができますが、バックアップデータの実体をWEBインターフェースの画面で確認することはできません。また、インスタンスを削除するタイミングで FlashCopy のデータも消失するため、バックアップデータはICOSなどへのデータのエクスポートが推奨されています。
2) IBM Cloud CLI 導入
FlashCopy を実施する前に、実施環境(ローカルPC)の準備を行います。
Power Virtual Server の FlashCopy は「IBM Cloud API 」を利用します。残念ながらWEBインターフェース画面では FlashCopy 機能が提供されていません(2021年9月時点)。
FlashCopy の実行は「IBM Cloud API 」で行いますが、Power Virtual Server へのログインやFlashCopy に必要なパラメータ取得などで 「IBM Cloud CLI 」も利用します。
| IBM Cloud API とは 仮想サーバを簡単にデプロイおよび構成するために利用されるAPI(アプリケーション・プログラム・インターフェイス) :利用する場合、モジュールとしてのインストールは不要 |
| IBM Cloud CLI とは IBM Cloud のリソースを管理するためのCLI(コマンド・ライン・インターフェイス) :利用する場合、モジュールとしてのインストールが必要 |
「IBM Cloud CLI 」を利用するためには、ローカルPCに「IBM Cloud CLI」のモジュールをインストールする必要があります。
では、IBM Cloud CLI のインストール作業を行っていきます。
・WEBブラウザーを利用して、GitHub の IBM Cloud リポジトリーにアクセスします。
・IBM Cloud CLI を導入するPCのOSを選択します(私のPCは下記のピンク色で囲んだOS)。
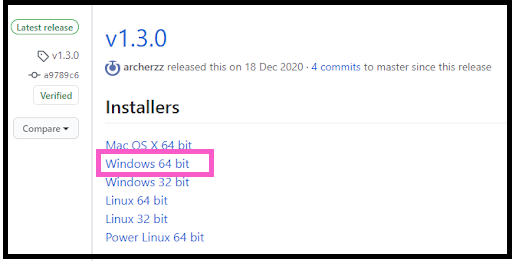
IBM Cloud CLI のインストーラーがローカルPC内にダウンロードされました。
※ 上記は2021年1月時点のバージョンで、2021年9月時点の最新版は v2.0.3 です。
・ローカルPC内にダウンロードしたインストーラーをダブルクリックして起動します。
![]()
「IBM Cloud CLI の インストール・ウィザード」が表示されます。
・「Next」をクリックします
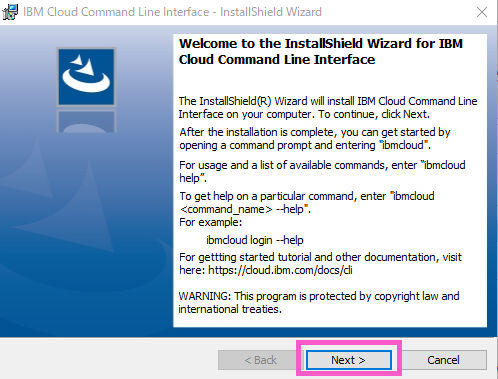
「License Agreement 」の画面が表示されます
・「I accept the terms in the license agreement」にチェックを入れます
・「Next」をクリックします
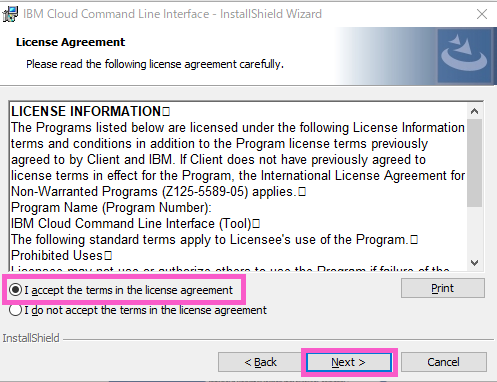
「Ready to Install the Program」の画面が表示されます。
・「Install」をクリックします
「The installation completed successfully」のメッセージでインストールが正常に終了した画面が表示されます。
・「Finish」をクリックします
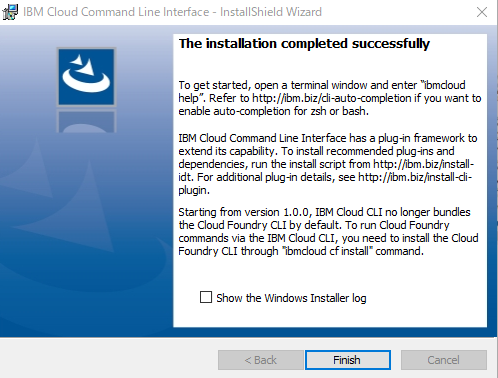
IBM Cloud CLI のインストールが完了です!
IBM Cloud CLI が正常にインストールされていることを確認します。
これ以降の作業では、CUI を利用して検証を行います。CUI は Windows標準搭載の「Windows PowerShell」を利用します。(※画面ショットの 固有の値はマスキングします)
・Windows PowerShell を起動し IBM Cloud CLI のバージョン確認コマンドを入力します。
> ibmcloud -v
![]()
上記の通り、IBM Cloud CLI 1.3.0 でした。私のPC内の IBM Cloud CLI は、2021年1月頃に導入したので、かなりバージョンが古くなっているようです。
・IBM Cloud CLIのバージョンアップを行います。
> ibmcloud update
→「今すぐ更新しますか?[Y/n]」で「Y」を入力
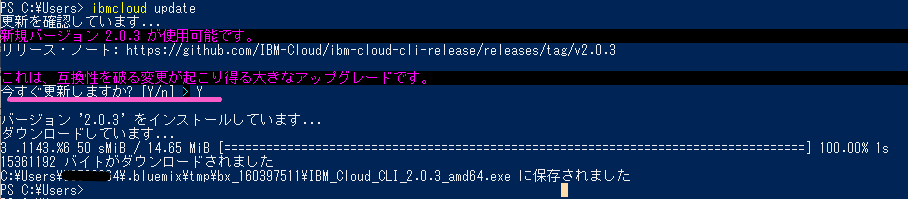
自動でIBM Cloud CLI のインストーラーが立ち上がります。
・インストールウィザードの画面で「Next」→「Finish」と進めます
・インストールウィザードが終了したらIBM Cloud CLI のバージョンを確認します。
> ibmcloud -v
![]()
IBM Cloud CLI 2.0.3 にUpdateできていることが確認できました。
次に、Power Virtual Server 専用のプラグイン(power-iaas/pi )を導入します。IBM Cloud CLI で Power Virtual Server を操作するためには、専用のプラグインが必要になるためです。
・ibmcloud コマンドでプラグインの一覧を表示します
> ibmcloud plugin repo-plugins -r “IBM Cloud”
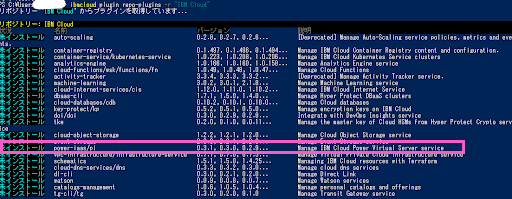
・「power-iaas/pi」が「未インストール」になっていることを確認し「power-iaas/pi」を導入します。
> ibmcloud plugin install power-iaas
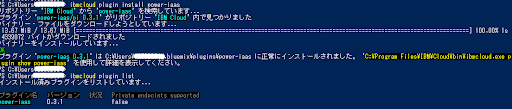
プラグインが導入出来ました。
・導入したプラグインのバージョンを確認します
> ibmcloud plugin list

「状況」欄に「更新が使用可能です」と出力されている場合、プラグインのバージョンが古くなっています。
・プラグインをUpdateします
> ibmcloud plugin update

最新バージョンにUpdateでき、「状況」が空欄になりました。
3) FlashCopy によるバックアップの事前準備
FlashCopy を実施する前にFlashCopyに必要なパラメーターを用意します(パラメータは IBM Cloud API Docs の「Create a PVM instance snapshot」に記載されています)。
単純に出力できないパラメーターは変数に代入していきます。
FlashCopy に必要なパラメーター(変数)は以下となります。
| 内容 | パラメーター/ 変数 |
| ①IBM Cloud へログイン | – |
| ②認証情報 | A. $TOKEN : IBM Cloud IAM アクセストークン B. $CRN:Cloud Resource Name |
| ③Pathのパラメータ | C. $CLOUD_INSTANCE_ID :Cloud Instance ID D. $PVM_INSTANCE_ID:PVM Instance ID |
| ④Bodyのパラメータ | ・name ・description E. $VOL_ID:Volume ID |
それでは、上記の①~④の順番で、パラメータ(変数)を取得していきます。
① IBM Cloud へログイン
・IBM Cloud へログインします(対話式コマンドでログインを行います)。
> ibmcloud login
→「Email」にIBM Cloud ログインIDを入力
→「Password」にIBM Cloud ログイン時のパスワードを入力
→「アカウント選択」で利用するアカウントが複数ある場合はアカウントNo.を選択
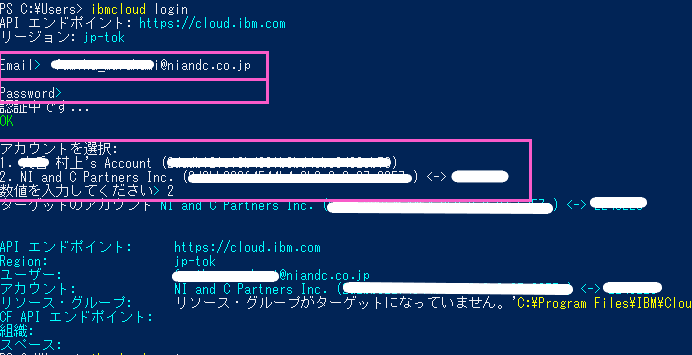
IBM Cloud にログインができました。
②では、Power Virtual Server の認証情報を取得します。
Power Virtual Server で IBM Cloud API を利用するためには、すべてのリクエストに 「IBM Cloud IAM アクセストークン」 と 「CRN※」が必要で、これは認証情報と呼ばれます。
※ CRN:Cloud Resource Name の略。Power Virtual Server のインスタンスID と テナントIDが含まれたもの。
A. IBM Cloud IAM アクセストークンの取得
・IBM Cloud CLI を利用しアクセストークンを出力します。
> ibmcloud iam oauth-tokens

・必要なストリングをjsonを利用して抽出し、結果を「$TOKEN 」変数に入れます。
> $TOKEN = (ibmcloud iam oauth-tokens –output JSON | ConvertFrom-Json ).iam_token
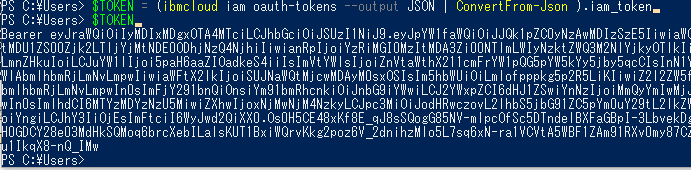
IBM Cloud IAM アクセストークンのパラメータ変数「$TOKEN」 が取得できました。
B. CRNの取得
・IBM Cloud CLI を利用しCRNを出力します。
> ibmcloud pi service-list
・出力したCRN ID のストリングを抜き出し「$CRN」変数に代入します。
> $CRN = ( ibmcloud pi service-list –json | ConvertFrom-Json).crn
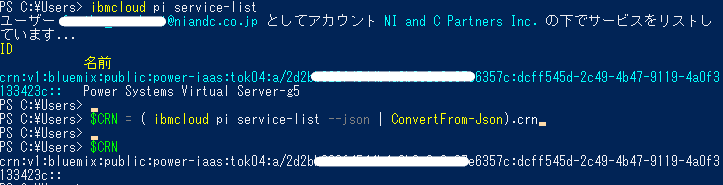
「$CRN」が取得できました。
③ Pathのパラメータ取得
③では、FlashCopy の実行文の Path 部分に設定するパラメータを取得します。
Cloud Instance ID を取得するためには「テナント ID」が必要です。「テナント ID」は「IBM Cloud のアカウントID」のことで、以下の通り、IBMCloud のWEB画面でも確認できます(https://cloud.ibm.com/account/settings)。
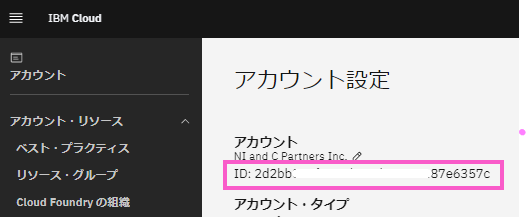
上記で確認できるIDをIBM Cloud CLI とAPI で取得します。
・IBM Cloud CLI を利用し「$TENANT_ID」変数に IBM Cloud アカウントID(テナントID)を代入します。
> $TENANT_ID = (ibmcloud account show –output JSON | ConvertFrom-Json ).account_id

・IBM Cloud API を利用し、テナント状況「$TENANT_STATE」変数を作成します。
$TENANT_STATE = ( `
>> curl.exe -X GET `
>> https://tok.power-iaas.cloud.ibm.com//pcloud/v1/tenants/$TENANT_ID `
>> -H “Authorization: $TOKEN” `
>> -H “CRN: $CRN” `
>> -H “Content-Type: application/json” `
>> | ConvertFrom-Json )
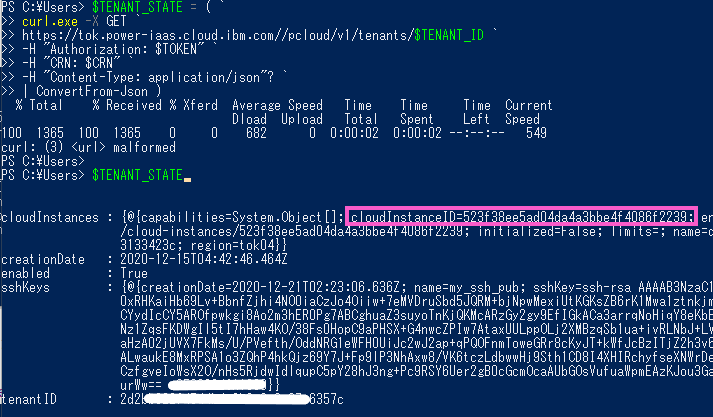
・「$TENANT_STATE 」の「cloudInstances」キーに「cloudInstanceID」が含まれているため(上記のピンク色で囲んだ値)、この値を「$CLOUD_INSTANCE_ID」変数に代入します。
> $TENANT_STATE.cloudInstances
> $CLOUD_INSTANCE_ID = ( $TENANT_STATE.cloudInstances).cloudInstanceID
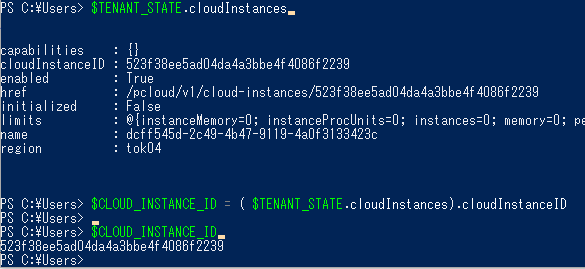
「$CLOUD_INSTANCE_ID」 が取得できました。
D. PVM Instance ID の取得
PVM Instance ID は、Power Virtual Server のインスタンスID のことです。下記の通り、IBM Cloud のWEB画面からも確認できます。
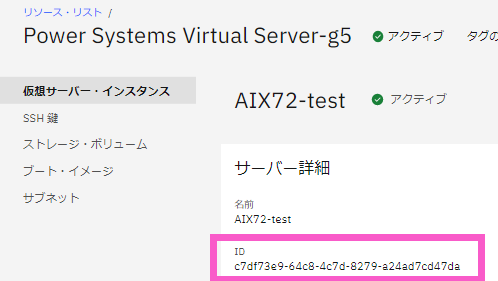
・IBM Cloud CLI を利用してインスタンス情報を取得し結果を「$INSTANCE」変数に代入します。
> $INSTANCE = ( ibmcloud pi instances –json | ConvertFrom-Json )

・「$INSTANCE」変数の「Payload.pvmInstances」キーの配下「pvmInstanceID」キーの値を「$PVM_INSTANCE_ID」変数に代入します。
>$PVM_INSTANCE_ID = ( $INSTANCE.Payload.pvmInstances.pvmInstanceID)

「$PVM_INSTANCE_ID」 が取得できました。
④ Body のパラメータ取得
④では、FlashCopy 実行文の Body 部分に設定するパラメータを取得します。
「name」と「description」は任意の値で構いません。
・ name : test
・ description : snapshot-test
と設定することにしました。
E. Volume ID の取得
ややこしいのですが、Volume ID は Volume Name を指しています。実際に、Volume ID というパラメーターもあるので間違えないように注意が必要です。Volume ID は、以下の通りWEB画面でも確認できます。
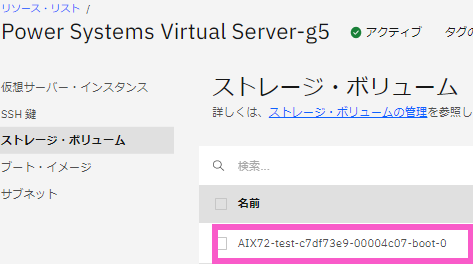
・IBM Cloud CLIを利用してインスタンス名をリストし、インスタンスに紐づくボリュームを調べます。
> ibmcloud pi instances
> ibmcloud pi instance-list-volumes AIX72-test
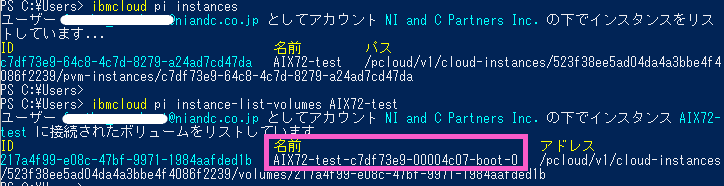
・上記のピンク色で囲んだ値を「$VOL_ID」変数に代入します。
> $VOL_ID =(ibmcloud pi instance-list-volumes AIX72-test –json |ConvertFrom-Json ).Payload.volumes.name

「$VOL_ID」 が取得できました。
4) FlashCopy の実施
すべてのパラメータが取得できたので、いよいよ(やっと) FlashCopy を実行します。
・念のため、3)で取得したパラメータ(変数)がきちんと出力されるか確認します。
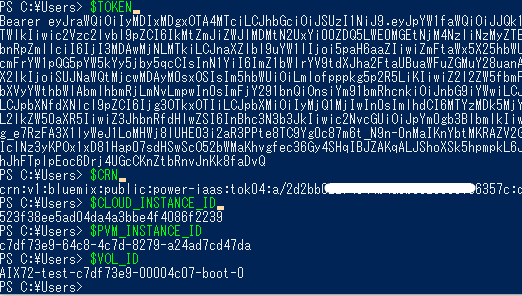
FlashCopy の実行文は IBM Cloud API Doc に記載がある以下の文です。この実行文を例に、上記の取得したパラメーター(変数)を当てはめて FlashCopy を実行します。
| curl -X POST https://us-east.power-iaas.cloud.ibm.com/pcloud/v1/cloud-instances/ ${CLOUD_INSTANCE_ID}/ pvm-instances/{pvm_instance_id}/snapshots -H ‘Authorization: Bearer <>’ -H ‘CRN: crn:v1…’ -H ‘Content-Type: application/json’ -d ‘{ “name”: “VM1-SS”, “description”: “Snapshot for VM1”, “volumeIDs”:[“VM1-7397dc00-0000035b-boot-0”] }’ |
上記の実行文の通り、色々と試してみましたが、Body の部分( -d 以降) が PowerShell ではうまく実行できません。
そのため、Qiitaのブログを参考にさせていただき、Body は変数に当てはめて FlashCopy を実行しました(他の部分もかなり参考にさせていただいているブログです!)。
・FlashCopy 実行文のBody の部分のみ変数に当てはめます。
> $BODY = ‘{“name”: “test”, “description”: “snapshot-test”,”volumeIDs”: [“‘ + $VOL_ID + ‘”] }’

・IBM Cloud API を利用して、FlashCopy を実行します。
> ( $BODY | curl.exe -X POST `
>> https://tok.power-iaas.cloud.ibm.com/pcloud/v1/cloud-instances/
$CLOUD_INSTANCE_ID/pvm-instances/$PVM_INSTANCE_ID/snapshots `
>> -H “Authorization: $TOKEN” `
>> -H “CRN: $CRN” `
>> -H “Content-Type: application/json” `
>> -d `@- )

FlashCopy が完了しました!
・FlashCopy が正常に完了していることを IBM Cloud API を利用して確認します。(参考「Get all snapshots for this PVM instance」)
> curl.exe -X GET `
>> https://tok.power-iaas.cloud.ibm.com/pcloud/v1/cloud-instances/
$CLOUD_INSTANCE_ID/pvm-instances/$PVM_INSTANCE_ID/snapshots `
>> -H “Authorization: $TOKEN” `
>> -H “CRN: $CRN” `
>> -H “Content-Type: application/json”
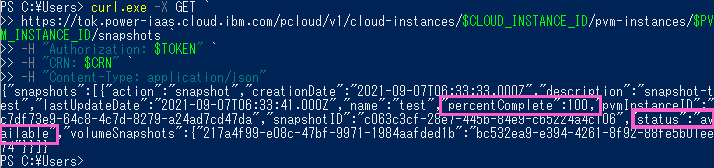
上記のピンク色で囲んだ値が FlashCopy の結果を示しています。
「percentComplete」が「100」、「status」が「available」であれば、FlashCopy が成功しています。
FlashCopy が成功していることを確認できました!
この後、AIX環境に変更を加えて、取得したFlashCopy のデータのリストアを行い、変更前の状態に戻っているところまで確認しましたが、長くなりましたのでブログはここで終了します。
リストアは「Restore a PVM Instance snapshot」を参考にし、今回のバックアップ手順で取得したパラメータを利用すると簡単に実行できました。
次のブログでは、IBM Cloud IA環境との接続手順をご紹介します。↓
☆準備中です☆【やってみた】IBM Power Virtual Server AIX環境と IBM Cloud IA環境を接続してみた
最後に
今回の検証は、IBM Cloud API Docs や Qiita に投稿されているブログ を参考にさせていただきました。
Part.1 のImage Capture を利用したバックアップ方法と比べると、今回は慣れないAPIを利用したこともあり調査にとても時間が掛かりました。また、バックアップ処理自体はあっという間でも事前準備にも時間を取られました。
そのため、スピードを求められる開発環境や検証環境には、Image Capture の利用がおすすめです。
実際の運用に組み込むとしたら、FlashCopyでしょうか。
OS、ストレージ、データベース、アプリケーション。バックアップ対象も方法も様々で、バックアップ方法のドキュメントを読んでもイメージが湧かないことがよくありますが、実際に検証をしてみることで、イメージが湧き、メリットやデメリットを捉えることができるので、お客さまにも伝えやすくなります。
今後も時間を見つけ、こつこつ検証をしていきたいと思います。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp