
こんにちは。
てくさぽBLOGメンバーの村上です。
本ブログは、IBM Power Virtual Server をトライしてみた内容や感想をご紹介するブログです。
シリーズ化していますので、まずインデックスのご紹介をします。
インデックス
・IBM Power Virtual ServerでAIX環境を作ってみた
・IBM Power Virtual ServerのAIX環境にSWを導入してみた
・IBM Power Virtual ServerのAIX環境を日本ロケールにしてみた
・IBM Power Virtual ServerのAIX環境をバックアップしてみた(Part.1) ←今回
・IBM Power Virtual ServerのAIX環境をバックアップしてみた(Part.2)
・IBM Power Virtual ServerのAIX環境とIBM Cloud x86環境を接続してみた
今回は、AIX環境のバックアップ手順のご紹介です。
検証環境で2種類のバックアップ方法を試しましたので、Part.1(本ブログ)とPart.2に分けてご紹介いたします。
Power Virtual Server バックアップ方法
Power Virtual Server の AIX インスタンスでは、以下の4種類のバックアップ方法が推奨されています。
※技術寄りな人が最初に読む_IBMCloud柔らか層本 を参照(情報は20210811版より抜粋)
| 取得方法 | 提供方法 | 取得対象 |
| Image Capture | IBM Cloud で提供される | 任意のVolumeGroup |
| Flash Copy | IBM Cloud で提供される | 任意のVolumeGroup |
| mksysb / savevg | AIX OS標準でサポートされる方式 | 任意のVolumeGroup |
| バックアップ・ソフトウェア利用 | お客さまが別途ソフトウェアを購入 | OS領域以外のデータ領域 |
上記の表の太字にしていない「mksysb / savevg」と「バックアップ・ソフトウェア利用」のバックアップ方法は、オンプレミス環境で頻繁に利用されているのでイメージが付きやすいと思います。
そのため、IBM Cloud の機能で提供されている「Image Capture」と「Flash Copy」のバックアップ方法を試すことにしました。
今回は 「AIX環境をバックアップしてみた Part.1」として、Image Capture によるバックアップ取得手順と、そのバックアップデータを IBM Cloud Object Storage に保管する手順をご紹介します。
セクション
以下の1)~4)のセクションに分けてご紹介します。
1) Image Capture の説明
2) Image Capture によるバックアップ取得
3) IBM Cloud Object Storage の準備
4) IBM Cloud Object Storage への保管
準備工程にかかる時間は別として、2) の「 Image Capture によるバックアップ取得」は数十秒(バックアップ容量が20GB(USEDは13GB))、4) の「IBM Cloud Object Storage への保管」は約17分程度(圧縮後のデータ容量が6.6GB)でした。
検証はAIXのインスタンスで行いましたが、IBM i のインスタンスでも同等の手順で操作を行うことができます。
利用したクライアント端末(私のPC)は、Windows10 pro バージョン2004です。
1) Image Capture の説明
Image Capture は Power Virtual Server の WEBインターフェース画面で簡単に実行することができます。
<Image Capture とは>
| 説明 | ・IBM Cloud で提供され、LPARのOVAイメージ(※)が出力される ・OVAイメージを使って別のインスタンスのデプロイが可能となる |
| 主な用途 | ・移行 ・複製(マスターイメージの管理) ・遠隔地保管 |
| 対象 | rootvg を含む任意のボリューム |
| 保管場所 | ・Image Catalog ・IBM Cloud Object Storage |
| 取得時の LPAR停止有無 |
不要 ※ ファイルの整合性担保のためにLPARを停止することが推奨される |
| 制約事項 など |
・手順を検証した上でバックアップとしても運用可能 ・サービス内の同時実行数は「1」 ・合計のボリュームサイズは最大10TB ・Flash Copy に比べると時間がかかる |
(※) OVAイメージとは、Open Virtual Appliance の略で、仮想サーバの構成や状態を丸ごとデータとしてファイルに写し取ったデータ形式のことです。
本来、Image Capture は移行や複製を目的とするようなのですが、制約事項に記載した通り、手順を確立する必要はあるもののバックアップとして利用できそうです。
また、制約事項に「Flash Copy より時間はかかる」とありますが、AIXユーザは mksysb や savevg の長時間バックアップに慣れているので、Flash Copy のような高速バックアップに比べて時間がかかる、くらいなら問題ないと感じます。
2) Image Capture によるバックアップ取得
前置きの説明が長くなりましたが、ここからは実際のバックアップ取得の手順となります。
IBM Cloud にログインし、インスタンスの詳細画面を表示します。
(インスタンスの詳細画面の表示方法は以前のブログに記載しています
【やってみた】IBM Power Virtual Server のAIX環境にSWを導入してみた )
・「サーバ詳細」の右上に表示されている「VMアクション」のプルダウンをクリックし、「取り込んでエクスポート」をクリックします。
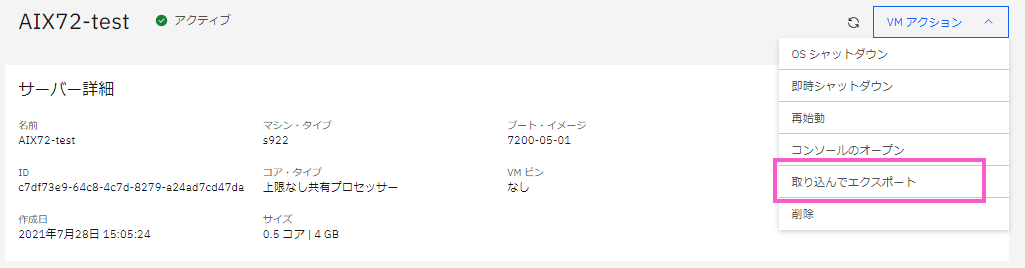
「AIX72-test の取り込みおよびエクスポート」画面が表示されます。
・バックアップ対象ボリュームを選択します。
・エクスポート先は「イメージ・カタログ」を選択します。
・「カタログ・イメージ名」に任意の名前を入れます。「AIX72_CP」という名前にしました。
・「取り込んでエクスポート」をクリックします。この操作がバックアップ実行ボタンです。
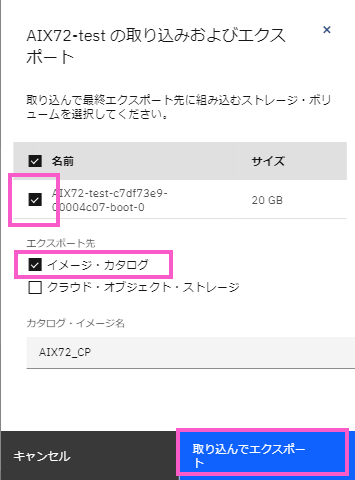
バックアップが進行しているメッセージが出力されます。
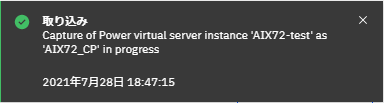
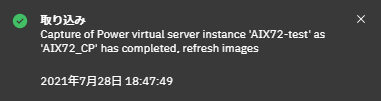
上記のメッセージのように「completed」が表示されたらバックアップが完了です。
取得したバックアップデータを確認します。
・WEBインターフェース画面の左ペインの「ブート・イメージ」をクリックします。
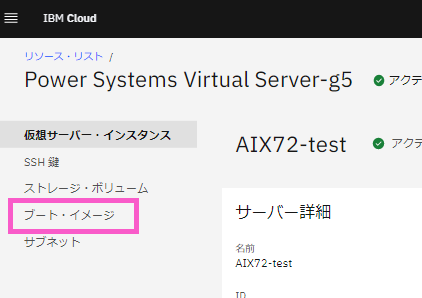
・「ブートイメージ」のリストに、先ほどバックアップを取得した「AIX72_CP」がリストアップされていることを確認します。
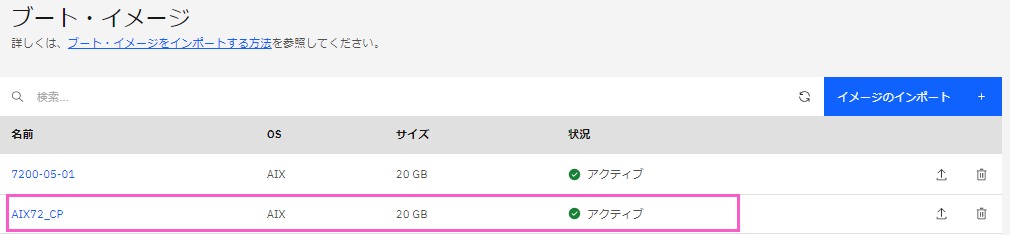
※「AIX72_CP」の上に表示されている「7200-05-01」は、インスタンス「AIX72-test」作成時にできるイメージです。
以上で、簡単にバックアップが取得できました!
通常は数十分かかるようなバックアップが1分もかからずに実行できたので驚きました。
次のセクションでは、取得したバックアップを別の場所(IBM Cloud Object Storage)にエクスポートします。
3) IBM Cloud Object Storage の準備
2) で取得したバックアップをIBM Cloud Object Storageにエクスポートする前に、IBM Cloud Object Storage のサービスを作成する必要があります(IBM Cloud Object Storage は、これ以降、ICOS と記載します)。
バックアップをICOS上にエクスポートすることで、Power Virtual Server のサービスが削除された後もバックアップデータを残しておくことができます。
ICOS には無料のライトプランが以下の条件で提供されており、今回は以下の条件に当てはまるのでライトプランを利用します。
| ・1サービス、1ICOS ・最大25GBのストレージ容量 ・最大20,000 GET 要求/月 ・最大2,000 PUT 要求/月 ・最大10GB/月 のデータの取得 ・最大5GBのパブリック・アウトバウンドライト・プラン・サービスは、非アクティブで 30 日経過すると削除されます。 |
では、ICOSの環境を準備します。
(ICOSの準備は手順が少し長いですが、難しくないので ぜひお付き合いください)
・IBM Cloud のWEB画面右上の「カタログ」をクリックします。
![]()
・検索バーに「object」と入力し、一番上にリストされる「Object Storage」を選択します。
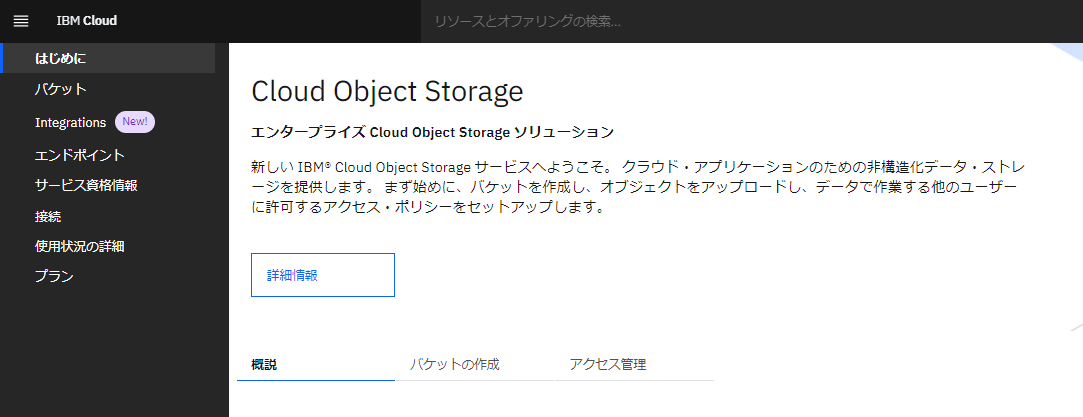
以下の様に、ICOS のサービス作成画面が表示されます。
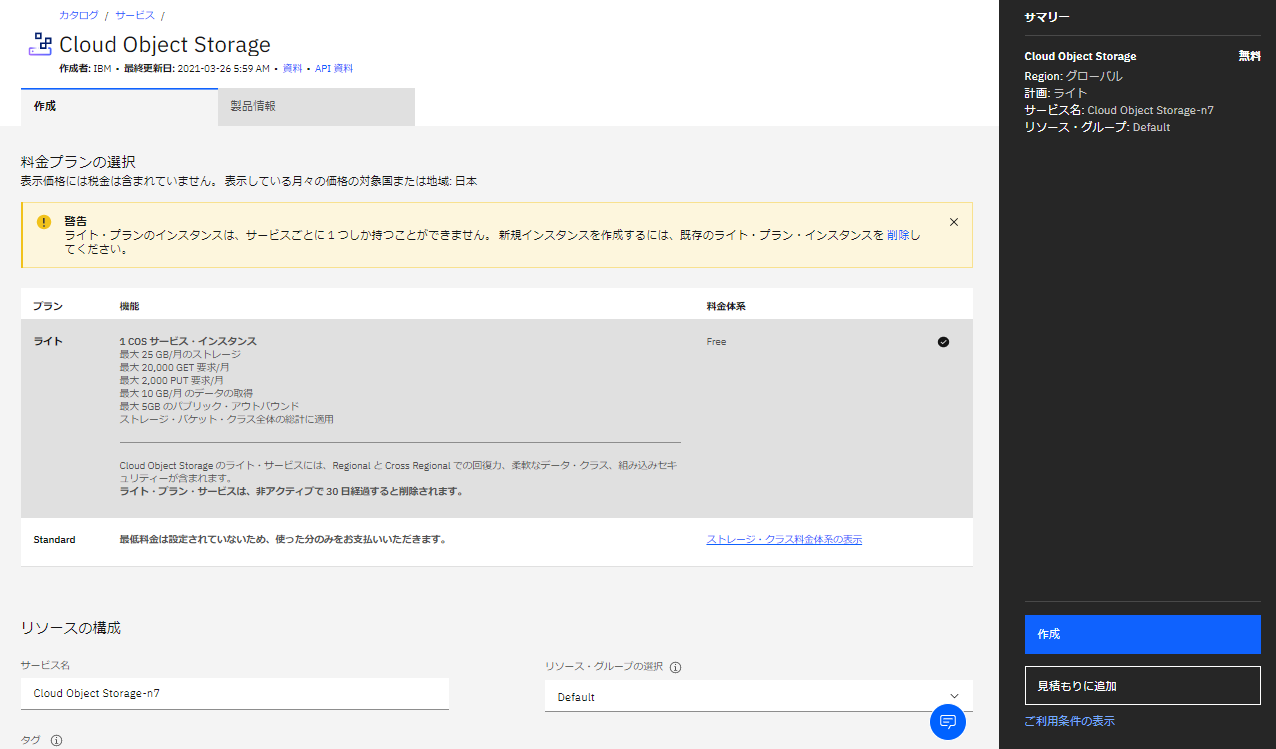
・「リソースの構成」の「サービス名」の欄に任意のサービス名を記載します。今回は「COS-TEST」という名前にしました。

・ライトプランなので金額が無料であることを確認し「作成」をクリックします。
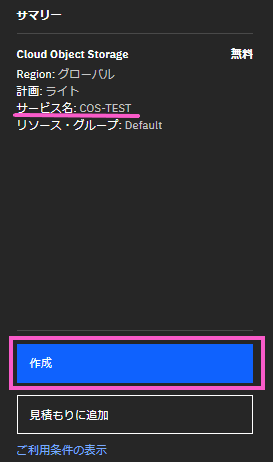
ICOS サービスが作成できると下記の画面が表示されます。
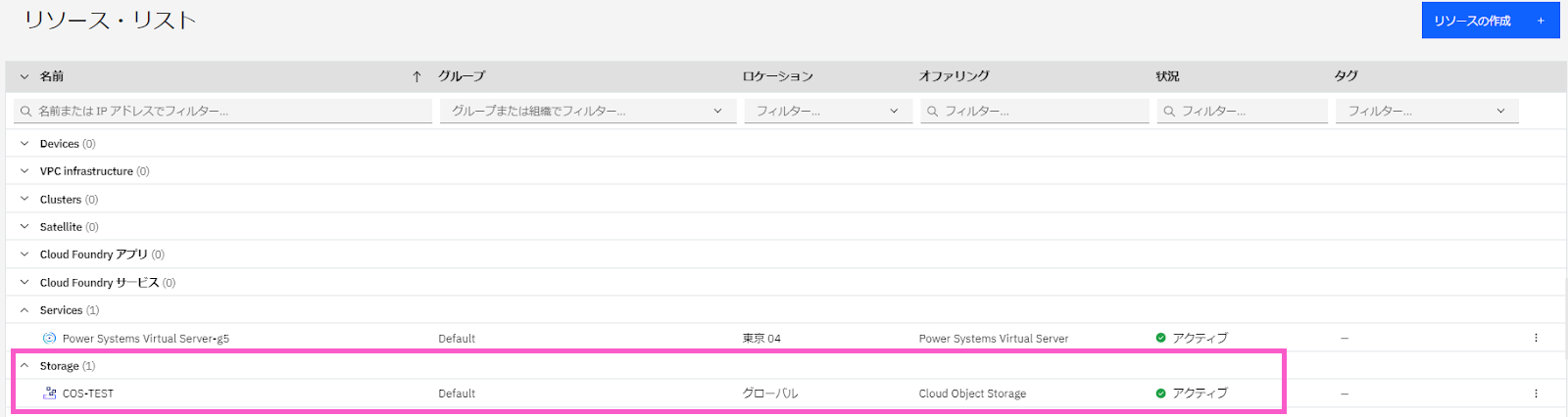
ICOSサービスは、以下の通り、リソース・リストで確認でき、「ストレージ」のプルダウン以下にリストされます。
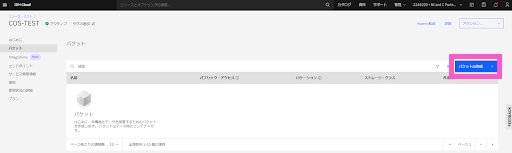
次は、「COS-TEST」内にバケットを作成します。
・リソース・リストにリストされた「COS-TEST」をクリックします。
・「バケットを作成」をクリックします。
・「バケットのカスタマイズ」をクリックします。

「カスタム・バケット」の画面に移動します。
・「固有のバケット名」に任意の名称を入れます。今回は「cos-test-2021」としました。
・「回復力」は初期状態の「Regional」を選択したままとします。
・「ロケーション」は「jp-tok」を選択します。
・「ストレージ・クラス」は初期状態の「Smart Tier」を選択したままとします。
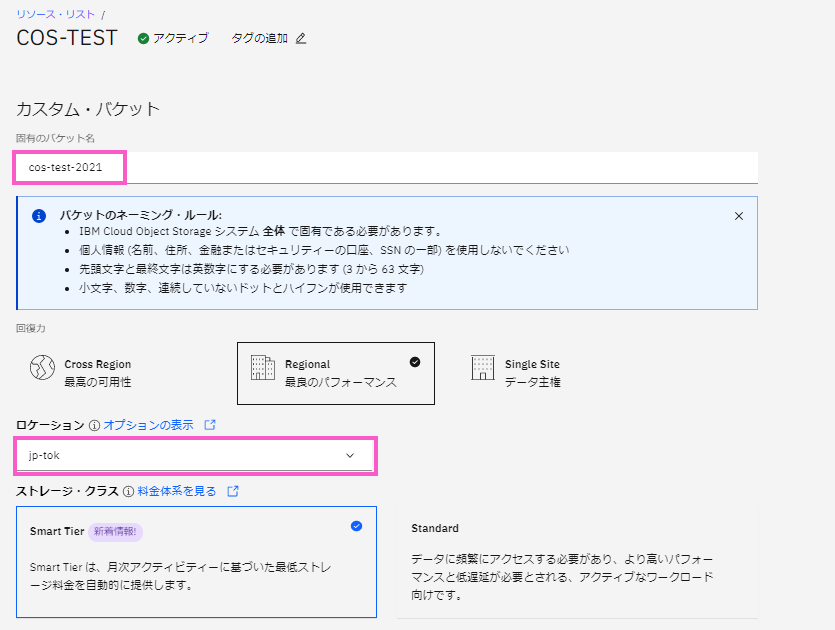
・その他の項目は初期状態のままとし、画面の一番下にスクロールして「バケットの作成」をクリックします。

バケットが作成できました。
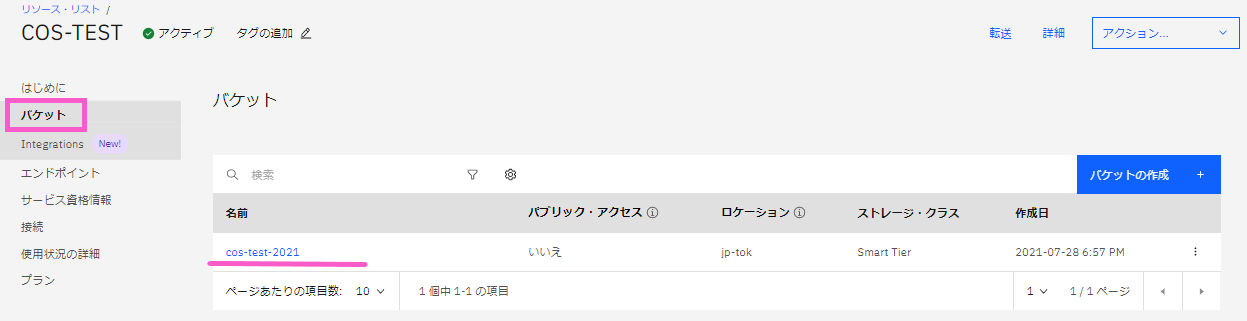
このバケットにアクセス・ポリシーを設定します。
・上記の画面で「cos-test-2021」をクリックします。
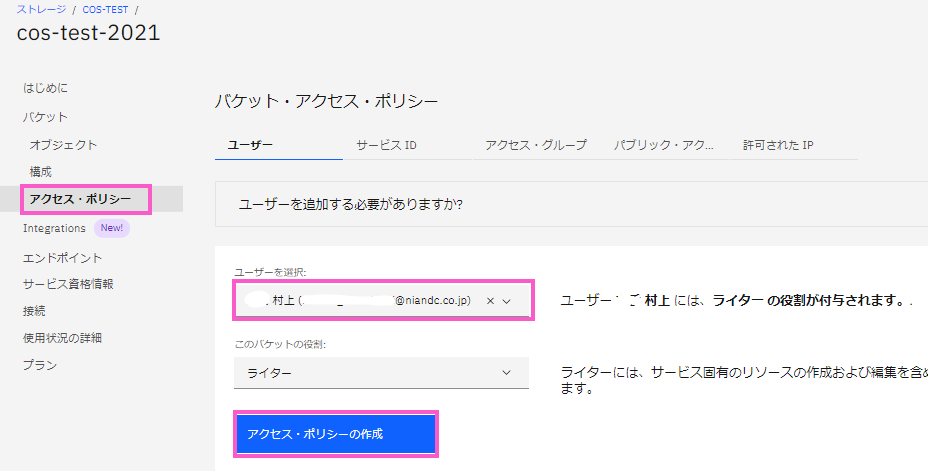
・左ペインに表示される「アクセス・ポリシー」をクリックします。
・「ユーザを選択」のプルダウンから権限を付与するユーザを選択します。
・「このパケットの役割」は初期状態の「ライター」を選択します。
・「アクセス・ポリシーの作成」をクリックします。
アクセス・ポリシーの設定が完了すると以下が出力されます。

ICOSサービス資格情報を生成します。
・左ペインより「サービス資格情報」を選択し、「サービス資格情報」の画面上に表示される「新規資格情報」をクリックします。
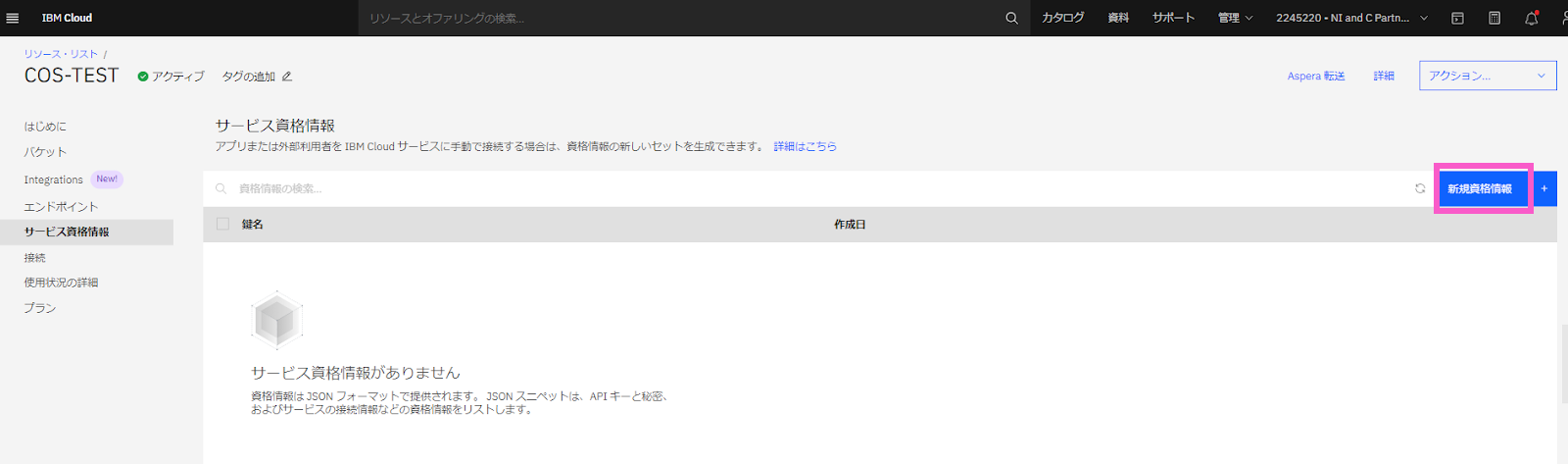
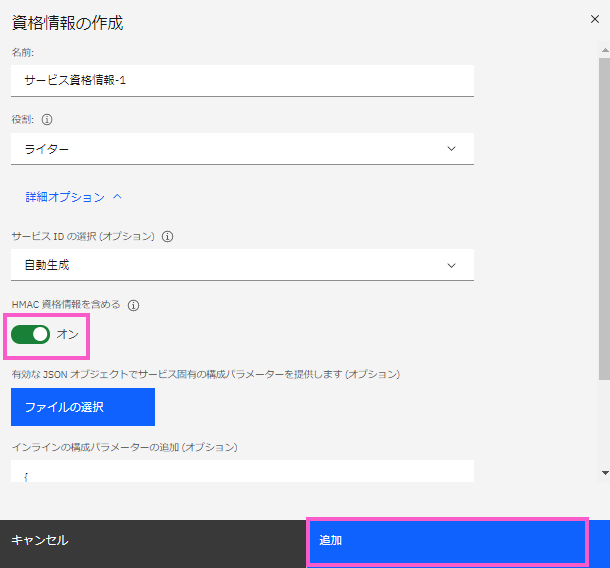
「資格情報の作成」の画面となります。
・「HMAC資格情報を含める」を「オン」にします。
・内容を確認して「追加」をクリックします。
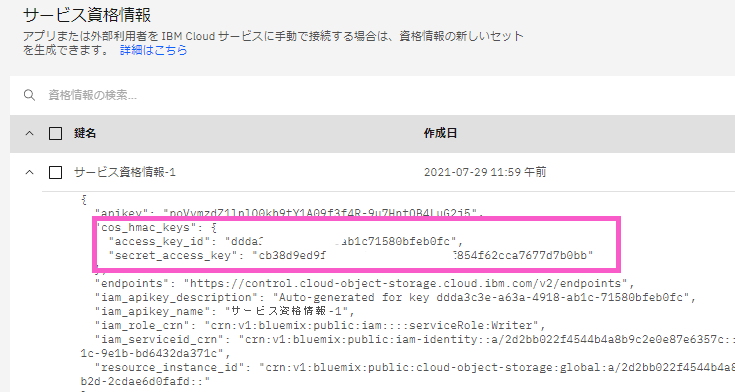
サービスの資格情報が生成されました。
・「cos_hmac_keys」の情報は、ICOSへバックアップデータをエクスポートする際に利用するのでコピペしておきます。
ICOSの準備が完了しました。
さて、次はバックアップイメージのエクスポート作業です。
4) IBM Cloud Object Storage への保管
2)で取得したバックアップイメージを、3) で作成したICOSのバケット内にエクスポートします。
・2)で取得したバックアップイメージを表示します。
・ブート・イメージ「AIX72_CP」の右側にある上矢印のマークをクリックします。これがエクスポートのボタンです。
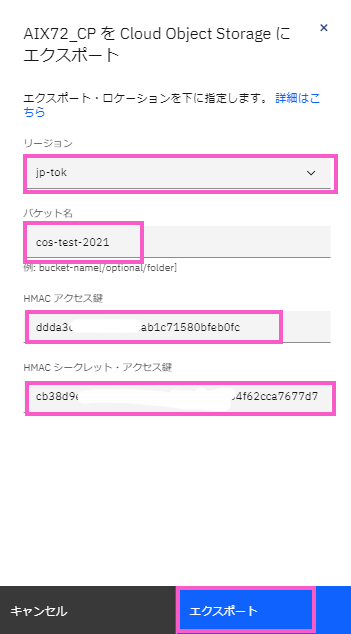
「AIX72_CPを Cloud Object Storage にエクスポート」の画面が表示されます。
・「リージョン」は「jp-tok」を選択します。
・「バケット名」は3)で作成した「cos-test-2021」を入力します。
・「HMACアクセス鍵」には、3) の手順でコピーしたサービス資格情報を入力します。
・「HMAXシークレット・アクセス鍵」にも、3) の手順でコピーしたサービス資格情報を入力します。
・すべての内容を確認し「エクスポート」をクリックします。
エクスポートの進捗は、ポップアップで画面に表示されます(すぐにポップアップが消えてしまい画面ショットは取れませんでした・・)。
バックアップイメージのエクスポートが完了したら、以下のようにICOSの「オブジェクト」画面にオブジェクトが追加されます。
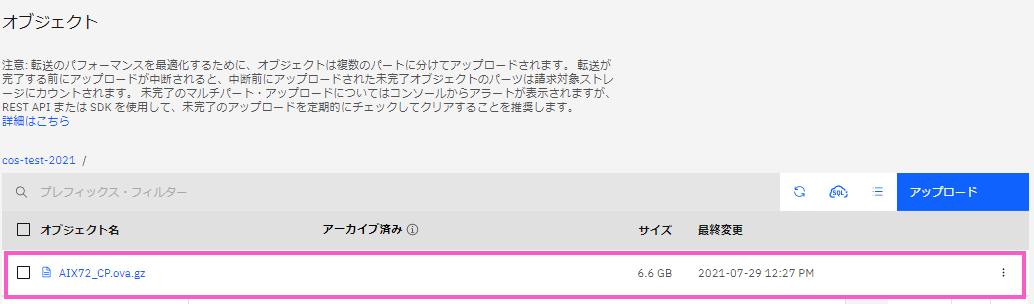
バックアップイメージのエクスポートが完了しました!
6.6GB のバックアップイメージがエクスポートされたことが分かります。
(OVAイメージは自動で圧縮されていました)
エクスポートは約17分程度で完了しました。約6.6MB/秒 の転送速度です。 ICOSはIBM Cloud の x86側のサービスを利用しているのもあり、転送速度はちょっと遅いですね。
転送速度を上げるためには、Aspera の利用を検討してみてもよいかもしれません(利用する際は別料金です)。
ICOSを初めて利用する際はICOSの準備に少し手間がかかりましたが、バックアップイメージのエクスポートはとても簡単でした!
次のブログでは、AIXインスタンスのバックアップ手順 Part.2をご紹介しています。
【やってみた】IBM Power Virtual Server のAIX環境をバックアップしてみた Part.2
最後に
実は、Power Virtual Server のバックアップの検証は2021年2月に完了していました。
本ブログを書くタイミングで、久しぶりにPower Virtual Server を触ってみると、ちょこちょこと仕様(画面の見え方など)が変わっていることに気づきまして、検証をやり直しました。
さすが、更新が頻繁に入っているPower Virtual Server ですね。
(情報発信は時間を置かずにすぐにやらないといけませんね!)
最新情報を逃さないよう、頻繁にチェックしていきたいと思います。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp