
文字、音声、画像、位置情報など、私たちの身の回りには多種多様なデータが存在しています。
「ビッグデータ活用」や「データドリブン経営」といった言葉が旬なキーワードとなっていますが、理由の1つとして市場やニーズの変化が速い、ということがあります。
この変化の激しい時代において、大量データを市場環境の分析や顧客ニーズの把握などに活かしていくことは、今日の企業にとって競争を勝ち抜くための重要な経営課題となっています。
すでに一部の企業はデータ分析基盤を導入し、多種多様なデータを効率的に分析することで市場の変化を迅速に捉え、自社製品・サービスの改善に活用しています。
そこで本コラムでは、データ分析基盤の基本的な構成や選定ポイントなどを解説します。
Index
データ分析基盤とは?
データ分析基盤は、多種多様なデータを統合した上で分析・活用するためのソリューションです。Excel や CSVファイルを数個利用してデータを分析するだけであれば、大がかりなデータ分析基盤を用意する必要はないでしょう。
しかし、「大量のデータを分析したい」「複数の担当者で分担して分析したい」といった場合には、効率よく分析を行うためにデータ分析基盤の構築が必要となります。
代表的なのは AI を利用する際です。定期的かつ繰り返し分析を行う必要があるので、データ分析基盤があるとスピーディーに手間をかけず結果を出すことができるようになります。
データ分析基盤は主に以下の機能があります。
-
- データを貯める
- 貯めたデータを分析するために整形・加工・クレンジングする
- 分析ツールを実行するためにデータを保管する
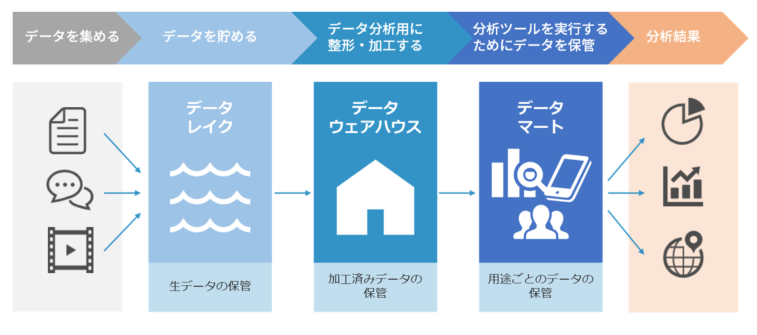
1.データを貯める(データレイク)
データレイク(Data Lake)は、業務システムやデータベースといったデータソースから収集したデータを保管する役割を担う、まさに「データの湖」のような存在です。
データレイクには、何ら加工を加えていない生データ(ローデータ)の状態でデータを保管します。データ分析の過程では、その目的や扱うデータの内容に応じて、非構造化データの構造化データへの変換、データ形式の変換、データクレンジングといった様々な加工を施します。
一方で、加工したデータを元の状態に戻さなければならない場合もあります。そのような場合にも、データレイクに生データを保管していれば、速やかに加工前の元データを手に入れることが可能です。
2.貯めたデータを分析するために整形・加工・クレンジングする
(データウェアハウス)
データウェアハウス(Data Warehouse)はデータレイクとは異なり、分析しやすいように加工したデータを保管する役割を担います。
データレイクや個別のデータソースに存在しているデータを ETL(Extract/Transform/Load)ツールで抽出し、分析用途に合わせて加工した上でデータウェアハウスに格納します。
幅広いデータソースから収集した多種多様なデータを用いて分析を行うという場合には、あらかじめ加工済みのデータをデータウェアハウスに集めておいた方が分析をスムーズに進めることができます。
3.分析ツールを実行するためにデータを保管する(データマート)
データマート (Data Mart)は、特定の用途で必要となる加工済みのデータのみを保管する役割を担います。
データウェアハウスは、データレイクや個別のデータソースから取り出して加工したデータをすべて保管します。
一方でデータマートは、「売上分析」「顧客行動分析」といった用途に合わせたデータのみを格納します。用途が限られている分、データウェアハウスよりも小規模なサイズでコストを抑えて構築することが可能です。
そのため、データ分析の目的が限定的な場合にはデータウェアハウスを用いることなく、データマートのみでデータ分析基盤を構築する場合もあります。
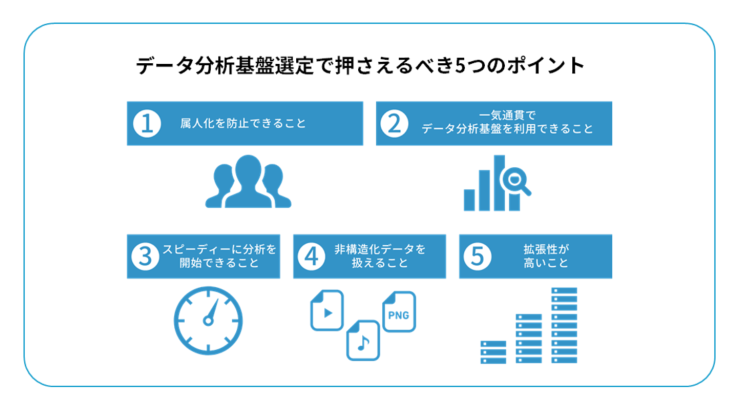
データ分析基盤選定で押さえるべき5つのポイント
実際にデータ分析基盤を選定する際には、次の5つのポイントを押さえることが重要です。
1. 属人化を防止できること
データ分析基盤の構築・運用には高い専門性が欠かせないため、専門スキルを持った一部のデータエンジニアだけが利用するといった形で属人化してしまいがちです。
属人化した状態では担当者の退職や異動にともなう引き継ぎがうまくいかず、データ分析の継続が困難になってしまう可能性があります。そのため、データ分析基盤選びでは属人化を防止できるかどうかが重要な選定ポイントになります。
例えば、分析用途に合わせたデータを管理画面上で簡単に抽出できるようなデータ分析基盤であれば、より幅広いメンバーがデータ分析を担うことができるようになり、属人化の防止につながるでしょう。
2. 一気通貫でデータ分析基盤を利用できること
前述のとおり、一般的にデータ分析基盤は、データレイク・データウェアハウス・データマートといった複数のソリューションを組み合わせて構築します。
この構築段階で設計を最適化することができず、「構築後の改修や別のソリューションの追加などで思わぬコストが発生してしまった…」というのはよく聞くところです。
さらに、ソリューション間でのデータ連携の不具合によるサイロ化も懸念されます。
このようなリスクを低減するには、複数のソリューションを組み合わせるのではなく、データエンジニアやデータサイエンティスト、ビジネスユーザーといった様々な役割の人が一気通貫で利用できるようなソリューションを選ぶ必要があります。
3. スピーディーに分析を開始できること
分析にあたってデータマートを作成することは珍しくありませんが、データウェアハウスからバッチ処理で物理的にデータを抽出してくるので、データ量が多い場合にはどうしても時間がかかってしまいます。
一方で、データをマッピングすることで仮想的なデータセットを作成できるソリューションも登場しています。このようなソリューションであれば、バッチ処理によって物理的にデータを抽出するよりも素早くデータ分析を開始することが可能です。
4. 非構造化データを扱えること
従来、企業が扱うデータの多くはリレーショナルデータベースや CSVデータのように、列と行の概念を持った構造化データでした。
一方で、最近では電子メール、会議を録音した音声ファイル、PDF形式の契約書といった列と行の概念を持たない非構造化データが多くなっています。
IoTやスマートデバイスの進歩によってさらに膨大な量の非構造化データが流通するようになっている状況を踏まえると、非構造化データにも対応したデータ分析基盤を選ぶことが重要です。
最近では、AIを活用することで非構造化データの分析を効率化しているデータ分析基盤も出てきています。
5. 拡張性が高いこと
スマートデバイスや IoT の普及によってデータ流通量が急増。2022年の世界のデータ流通量は、2017年時点と比べて3倍以上に達すると予測されています(※1)。
このような状況を踏まえると、データ量の増大を見越してホストやリソースの追加が容易で拡張性の高いデータ分析基盤を選ぶ必要があります。
※1:総務省「令和元年版 情報通信白書」
IBM Cloud Pak for Dataについて
本コラムは、データ分析基盤の構成要素や選定時のポイントについて解説しました。
IBM Cloud Pak for Data は、企業のデータ活用を強力に推進するデータ分析基盤です。Red Hat OpenShift Container Platform 上で稼働し、クラウド・自社データセンターなど環境を選ばずに利用することができます。
また、IBM Cloud Pak for Data はコンテナ化されているため、自社のデータ環境に合わせてリソース・可用性を柔軟に調整することができます。まさに企業で利用するためのデータ分析基盤として最適な製品です。
こちらのホワイトペーパーでは、今回ご紹介したデータ分析基盤選定のポイントと合わせて IBM Cloud Pak for Data が選ばれる理由を解説しています。データ分析基盤の導入をご検討中の方は、ぜひ、ご一読ください。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBM Cloud Pak for Data (製品情報)
– データを洞察へと変換する方法をよりシンプルにし、自動化します。 - IBM Cloud Pak for Dataが企業のデータ活用に選ばれる3つの理由 (ホワイトペーパー)
– データ分析基盤選定で押さえるべき5つのポイントもご紹介! - 今、デジタルサービスに求められる必須要件とは!?アプリケーションのコンテナ化で得られる5つのメリット (コラム)
– 今注目されている「コンテナ化」。コンテナ化とは?そのメリットとは? - 全ての企業が AI カンパニーになる!「IBM THINK Digital 2020」に参加した (ブログ)
– 全世界から9万人以上の参加者が! - IBM Cloud Paks シリーズ ご紹介資料 (資料) ※会員専用ページ
– 6つの Cloud Paks について、お客様の理解度に応じて必要な資料を選択できる形式になっています。