
こんにちは。
てくさぽBLOGメンバーの佐野です。
およそ9か月前にCloud Pak for Dataのトライアルに関する記事を書きましたが、その後「触ってみてどういうものか理解できた!」「機能が豊富すぎて全部を理解するのは難しい」などの反響も頂きました。
この9か月の間にいくつかCloud Pak for Data関連のアップデートがありましたのでその情報をお届けします。
大きなトピックとして2点あります。
・トライアルだけでなくビデオでの説明・紙芝居のような操作確認をIBM Demosでご提供
・Cloud Pak for Data v3.0の出荷開始
まずはIBM Demosに関することから共有します。
1.IBM Demos
「Cloud Pak ExperienceというサイトでCloud Pak for Dataのトライアルができますよー」と利用方法含めて前回の記事で記載しました。
しかし、チュートリアルに従って簡単な利用方法を確認できるとはいえ、環境だけあっても「具体的にどんな機能があるんだ?」「こういう使い方できるんだろうか?」というところは自力で探して理解するしかありませんでした。
そこに対しての解決策の一つとなるのが”IBM Demos”です。
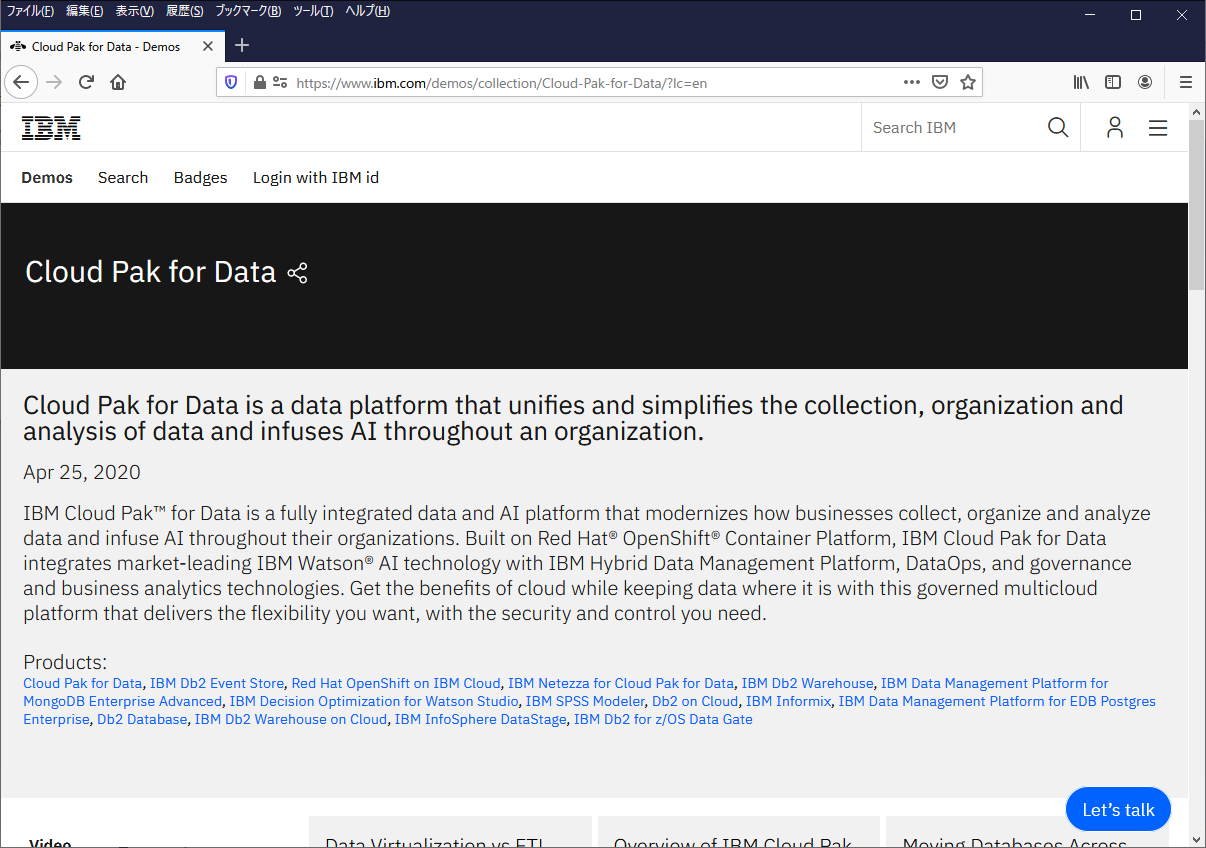
IBM Demosのサイトにアクセスをするといろいろな製品のデモや概要説明ビデオなどを探すことができます。
この中にCloud Pak for Dataもありますので、Cloud Pak for Dataに関する内容を閲覧することができます。
下の図の赤枠で括った箇所をクリックすると、IBM Demos内のCloud Pak for Dataサイトに飛びます。
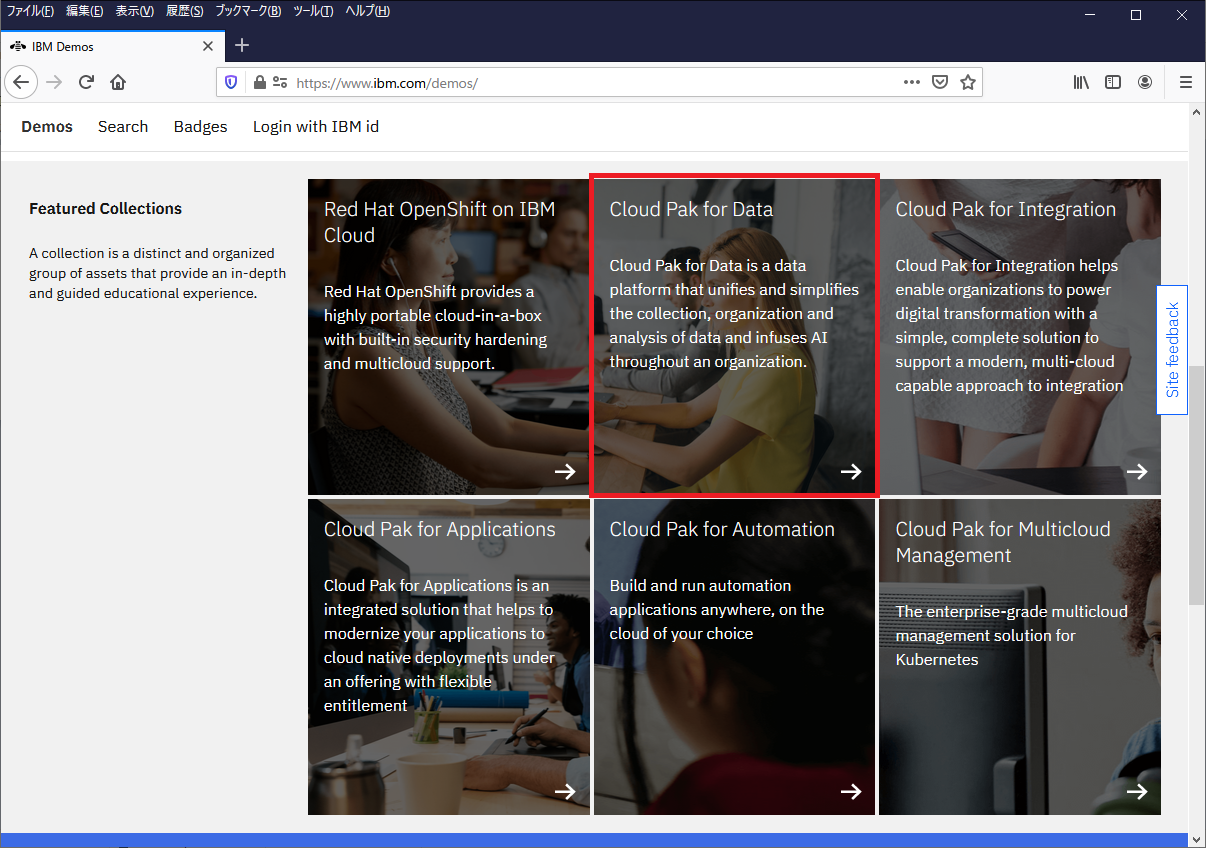
サイトの表示は英語ですが、URLの最後の「?lc=en」を「?lc=ja」に変えることで日本語表示に変更することができます。ただ、一部違和感がある表現があったり、日本語字幕入りのビデオしか表示されないため、本記事では英語表示のままで説明をします。
IBM Demosはいくつかのパートに分かれています。Cloud Pak for Dataでは以下の3つです。
・Video
・Product Tour
・Hands on Lab
Videoでは概要を把握できるような説明ビデオが流れます。一部は日本語字幕有なので、英語が分からなくても内容が理解できるようになっています。
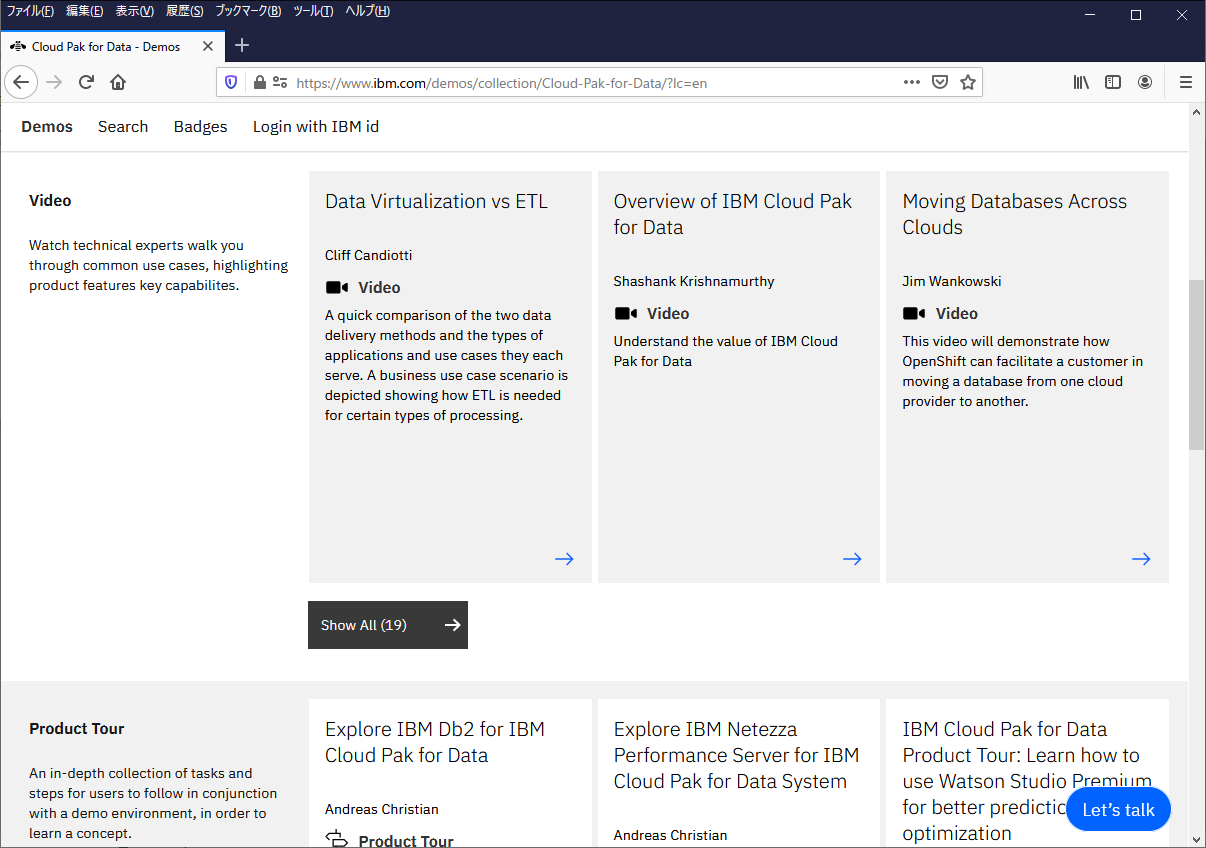
私のお勧めは「Overview of IBM Cloud Pak for Data」です。このビデオではCloud Pak for Dataの概要を理解することができます。他にはCloud Pak for Dataの特長の一つであるデータ仮想化の機能について説明している「IBM Cloud Pak for Data – Intro to Data Virtualization」も(英語ですが)見ておいた方がよいと思います。
Product Tourでは特定の機能を製品画面の操作をすることでより深く把握することができます。ただし、自由な操作はできずに、シナリオに沿った操作を紙芝居のようにできるぐらいです。
本記事の執筆時点では4つのみですが、ご自身が使いたい機能がこの中にあるようでしたら操作方法が分かりますので確認した方がよいでしょう。
Hands on Labsではトライアル用マシンを使って実際の操作を体験することができます。ここから先はIBM idが無いと操作ができません。「Experience IBM Cloud Pak for Data」ではIBM Demosから離れてCloud Pak Experienceへ移動します。
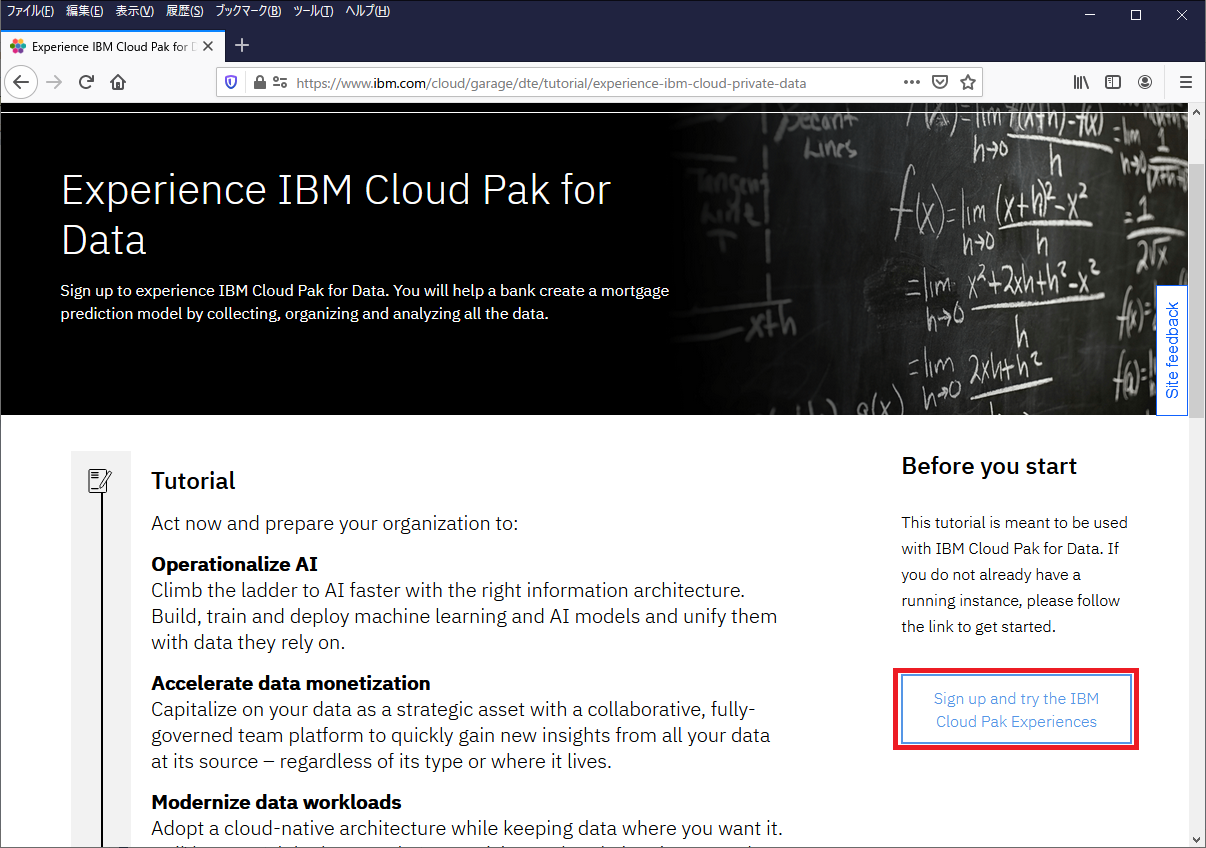
Cloud Pak Experience
Cloud Pak Experienceですが、Cloud Pak for Dataのトライアル環境です。画面が前のブログと若干異なりますが、画面左側に表示されているHands-on Learning項目のCloud Pakシリーズのリンクを押すとIBM Demosに遷移する動作は変わっていません。
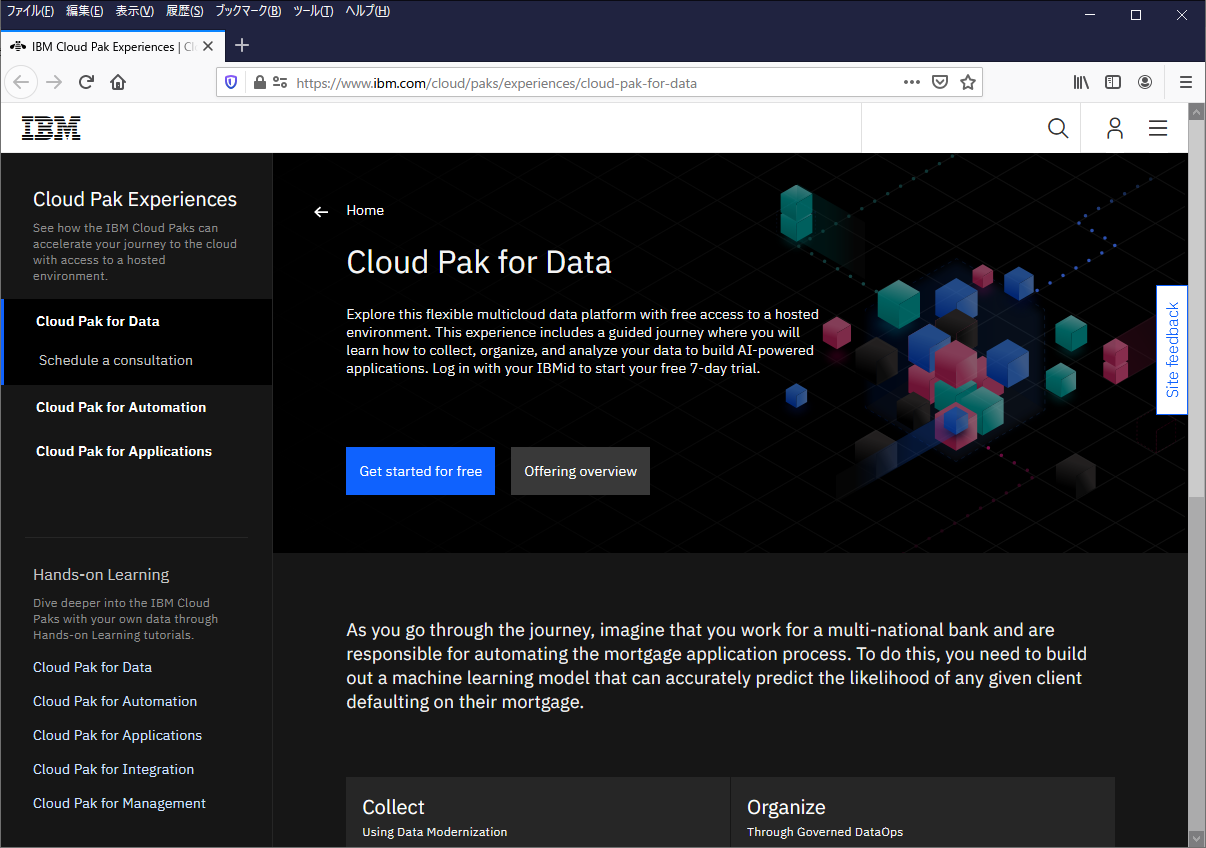
トライアルを始めるといっても、いくつかの基本的なシナリオの操作をすることがベースなので、まずはデータを収集するための”Collect”から始めましょう。
画面を少し下に移動して「Log in to explore」を押します。
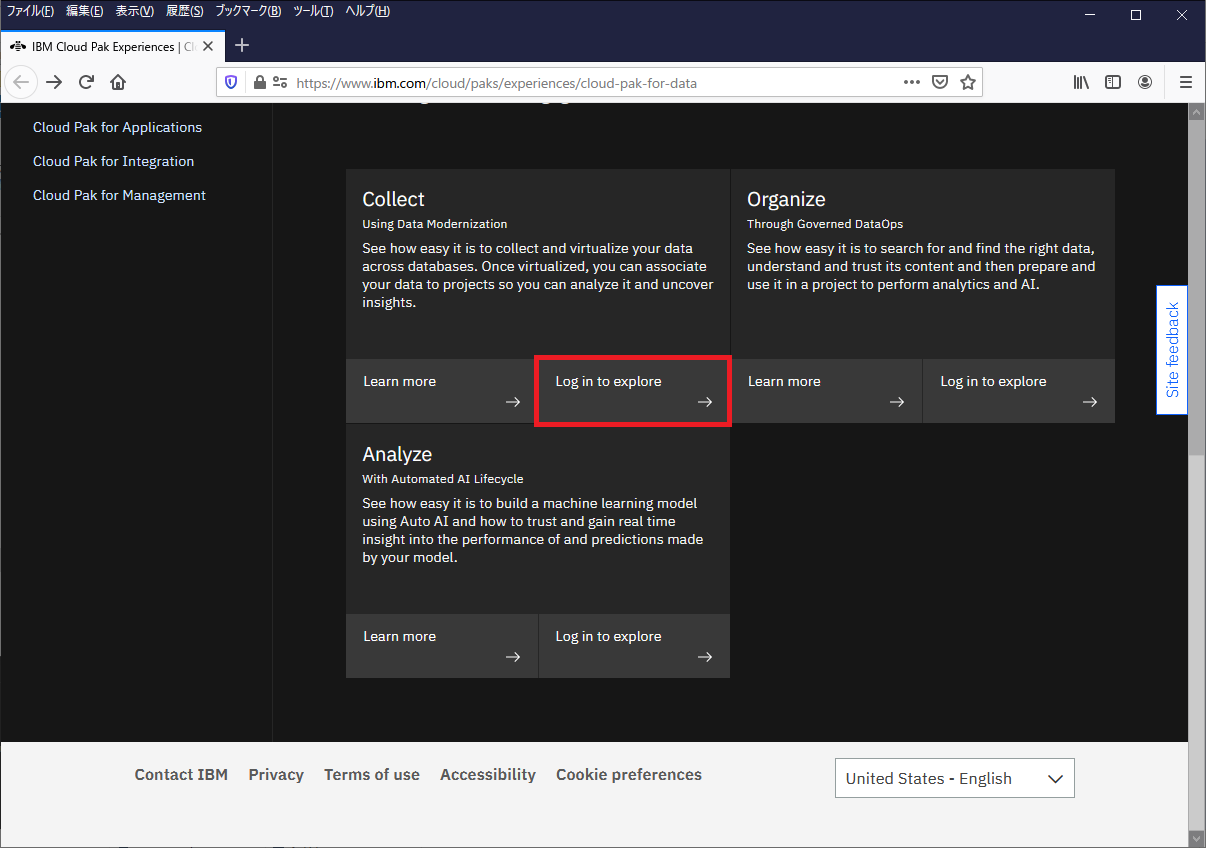 IBMidを持っている人はIBMidとパスワードを入力し先に進みます。お持ちでない人はIBMidを作成します。画面の真ん中に「IBMid の作成」というリンクがあるのでこちらから作成してください。
IBMidを持っている人はIBMidとパスワードを入力し先に進みます。お持ちでない人はIBMidを作成します。画面の真ん中に「IBMid の作成」というリンクがあるのでこちらから作成してください。
こんな画面が出ることもあるようですが、問題なければ「次に進む」を押します。
デモ環境へアクセスするために、利用条件やプライバシーに関する同意を求められますので、内容を読んだうえで「次へ」を押します。
Cloud Pak Experienceのサイトにログインした状態で戻ってきました。「Explore」を押して早速Cloud Pak for Dataを体験してみましょう。
Exploreを押すと「しばらく待て」というメッセージがでるので、少し待ちます。
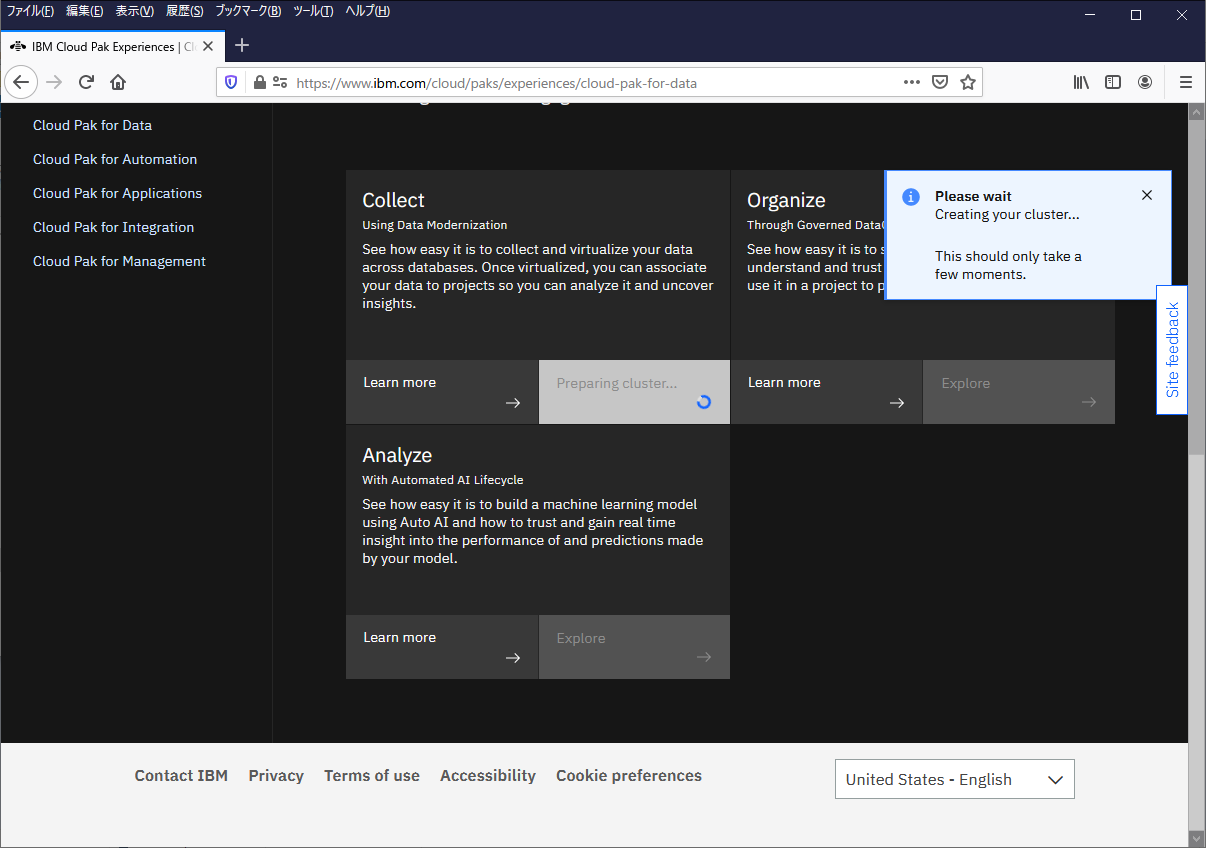
しばらく待つと自動的に画面が遷移します。
ここで自分自身で操作するか、ガイド付きかを選択できます。今回は「Let’s go!」を押します。
ここから先は詳細を飛ばしますが、画面表示が日本語になっているのがうれしいですね。日本語で操作ができるなら見た目でも何が書いてあるのか理解しやすいですし、自力でなんとかなりそうな気もしてきます。
ただ、ガイド文は英語なので、どういうことをしようとしているのか?を読むのが大変かもしれません。
本ブログを書いている時点で、Cloud Pak Experience環境で使っているCloud Pak for Dataのバージョンは「3.0.1 enterprise」という最新バージョンでした。
なので、導入を検討しているようなステップにある場合でも画面や操作感が変わらない状態で確認できます。
是非、データ分析基盤の導入を検討する際にはCloud Pak Experienceを使ってみて下さい。
2.Cloud Pak for Data v3アップデート情報
Cloud Pak for Data v3が2020/6/19に出荷開始となりました。主なアップデート内容は以下になります。
- DataOps機能拡張
- Watson Knowledge Catalog機能拡張およびデータ仮想化連携強化
- セキュリティ強化
- ⾮構造化データ管理の拡張(InstaScan)
- AIの機能拡張
- ML Ops
- Auto AIの機能拡張
- コンポーネントの拡張
- Planning Analytics、Virtual Data Pipeline、Master Data Managementを含む新たなサービス群の追加
- 運用機能拡張
- 監査、バックアップといった運用機能強化
- OpenShift v4.3対応
- UIの変更
- Cloud Pak for Dataライセンス名称の変更(Cloud Native→Standardへ変更)及びnon-productionライセンスの提供(Enterpriseのみ)
紙面の関係上、具体的な機能のアップデートは省略してコンポーネント拡張とライセンスについてご説明します。
Cloud Pak for Data v3で利用できるコンポーネントの一覧を図にまとめました。

ベースコンポーネント列にある製品(機能)はCloud Pak for Dataを購入すれば利用できます。追加サービス列にある製品(機能)はCloud Pak for Dataライセンスには含まれず、個別にライセンスを購入する必要があります。
表の中でも青文字で書かれた製品が今回のv3の提供に伴って追加となっています。この提供形態はv2.5からですが、追加サービスはどんどん増えているので今後の拡張にも期待できます。
追加サービスを購入する場合、例えばDataStageは個別の製品ライセンスとしても販売していますので既にDataStage自体をご利用になられているお客様もいらっしゃるのではないかと思います。
そういったお客様がCloud Pak for Dataへ移行しやすくなるように、一部の追加サービス製品においては既存環境のライセンスをCloud Pak for Dataの追加サービスに置き換えることで既存環境・Cloud Pak for Data環境どちらでも利用可能となるものもあります。
具体的な例を図に表しました。
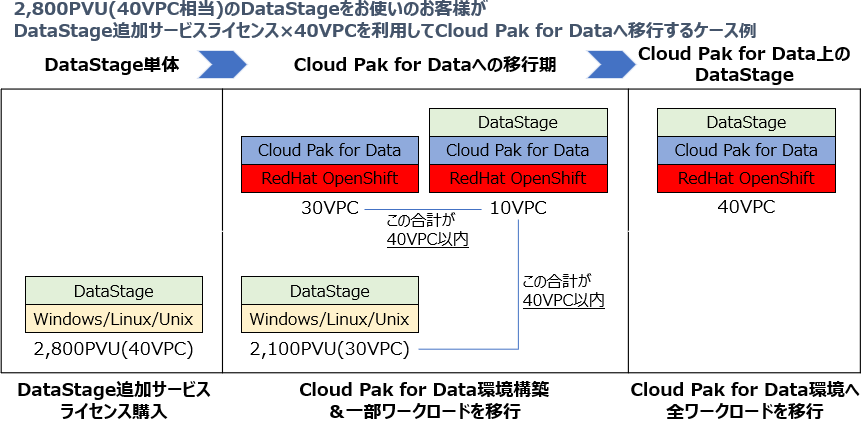
この例では既に2,800PVU(40VPC相当)のDataStage環境をお使いのお客様がCloud Pak for Data DataStage追加サービス×40VPCへ置き換えたケースです。
図に示しているいずれのシーンにおいても、ライセンスを追加購入する必要がないため、Cloud Pak for Dataへ移行している最中であっても、もちろんCloud Pak for Dataへ移行した後であっても追加のライセンス費用はかかりません。
また、単体製品としてのDataStageからCloud Pak for Data DataStage追加サービスへのトレードアップもできますので、ゼロからライセンス買い直しをせずにCloud Pak for Dataを利用することができるようになり、非常にお得です。
注:ライセンス情報・コンポーネント情報は更新される場合がありますので最新情報を必ずご確認下さい。
3.まとめ
Cloud Pak for Dataはまだまだ発展しており、更新情報も全部ご説明ができていませんが情報てんこ盛りになってしまいました。
データ分析基盤をご検討頂いている方には自社のデータ分析をどのように効率できるのか、是非ともCloud Pak for Dataを体験頂き、その体験をするためにこの記事がお役に立てれば幸いです。
また、別のコラムやホワイトペーパーでデータ分析基盤について解説していますので、そちらもあわせてご確認下さい。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp