
“SPSS” は1968年に誕生し、汎用機の時代からデータの解析に広く使われており、歴史、実績のある製品です。2009年の IBM による買収で IBM SPSS製品ファミリーとなりました。
当ページでは、なぜ SPSS は今も世界中の多くの現場で採用/利用されているのか、実際にユーザー (企業) への提案やトレーニングを担当しているスペシャリストにその本質を聞き、ポイントをまとめています。これから SPSS を使ってみようと思うユーザーの参考となれば幸いです。
(注記)SPSS 製品は複数のエディションで構成されるファミリー製品ですが、
当記事では、SPSS Statistics もしくは SPSS Modeler を主として記載しています。
結論:GUI が秀逸のため採用、利用されている
SPSS はその GUI による操作性がユーザに受け入れられている。製品の採用を検討しているユーザは「これなら自分たちでも利用できそうだ!」と評価し、採用している。
実際の利用ユーザにとっては業務効率をあげるだけでなく処理フローがグラフィカルに分かるため、担当者変更による引き継ぎの負担が低いことがポイントとなっている。
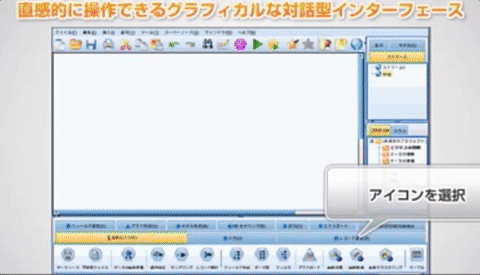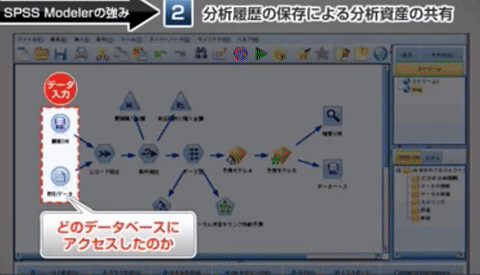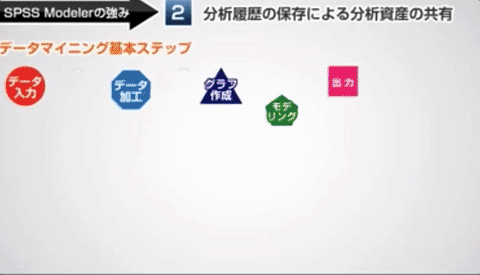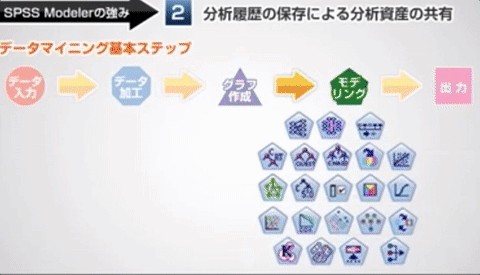
SPSS 製品は業務部門主導で・・・
また、SPSS 製品は、製品選定から導入を含め業務部門システム、業務の実担当が主導となることが多く、情報システム部門の負担も低い「情シスにやさしい」製品と言える。
利用用途は小売・流通業における販売データの分析、会員データ分析、製造業における販売製品の需要予測、また、事故の予防保全から経営状況の予測と幅広く使われ、売上向上や顧客ロイヤルティの向上に成果をあげている。
<現場で受け入れらている主な理由>
|
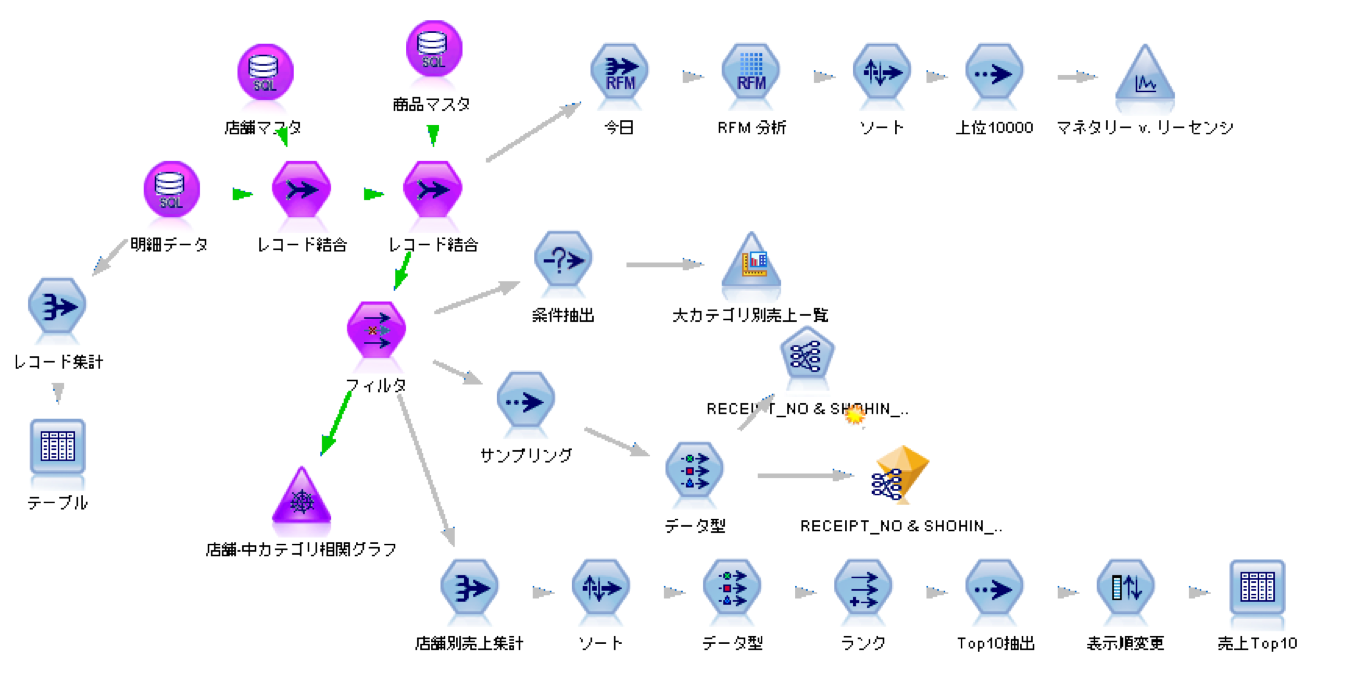
図:SPSS Modeler のGUIイメージ
SPSS 選定の決め手
スペシャリスト曰く「お客様の多くは最初は高度な分析経験はないところからスタートしている」。つまり、これから分析担当者を育てようというユーザが多いのである。
SPSS製品は、無償トライアルが Webサイトからダウンロード可能であり、導入費用自体も比較的安価である点もスタートしやすいポイントだ。
また、分析したい業務やデータにSPSSが適しているかの検討においては、標準で提供されている豊富なサンプルデータや処理フローから目的に合致したモデルを探すこともできる。
筆者も以前、Webアクセスログを分析したい!というきっかけから自身で SPSS Modeler をインストールし、評価したことがある。
分析者を育てるためのトレーニングも、現場にとって気になるポイントだろう。
「3日間ほどの有償トレーニングを受ければ、エンジニアでなくとも SPSS の操作についてはマスターできるし、SPSS の画面から呼び出すヘルプを見ながら操作していくユーザも多い」とスペシャリストは言う。
まずは容易に使ってみることができ、また、ベンダーの支援やトレーニングを受けながら業務に活かしていくことが可能な製品なのである。この点も分析担当を育てたいという企業にとって朗報であり、1つの評価ポイントとなるのであろう。
< 3日間のトレーニングで操作はマスターできる >

SPSS 導入時のポイント
SPSS 選定までの流れについて紹介してきたが、ここで、SPSS の実際の導入、インストール時に考慮するポイントを伝えながら製品の守備範囲についても触れておこう。
先述してきたように、SPSS は 気軽に自身の PC に導入して使えるが、製品としてはクライアント-サーバ型も提供されている。
SPSS の稼働環境としてどちらの形態を選択するかは、利用部署が複数にわかれるなどデータを共有する必要があるのか、また、データサイズ、分析頻度、ユーザ数なども判断材料となる。
例えば、データサイズを基準に検討する場合、数百万件〜1千万件もの規模になるとサーバ側で処理させることが望ましいため、クライアント―サーバー型をお勧めしている。
SPSS は、小規模環境でのパーソナル的な利用はもちろんのこと、大量データを扱う環境での活用も十分可能な製品なのである。
他社製品と比較した強み
冒頭に示した結論のとおり “GUI が秀逸である点”、つまり操作性の良さが SPSS の最大の強みである。
製品選定では「他製品と比較しても機能面ではそれほど変わらない」という良くあるパターンにおいて、GUI の操作性が優れているという特出した点は選定するポイントとなる。
アナリティクスの大手 SAS の製品や Visual Mining Studio などのマイニングツールを比較し、それぞれの強みを検討するユーザもあるが、操作性で SPSS を選んで間違いはなさそうだ。
大学で広く使われているのも学生でも利用できる操作性であるという証明になるであろう。
また、SPSS は長く使われている歴史のある製品で、不具合 (バグ) が非常に少ないことも有名である。その点も選択理由の 1つとなっていることが容易に推察できる。
R (アール) からの移行ユーザは?
“操作性の良さ” という点での例をもう1つ挙げよう。
今このページを見ている皆さんの中には R もしくは R言語と呼ばれるオープンソースのフリーソフトウェアの名称を聞いたことがある方も多いと思われる。
R は世界中の研究者が使っているツールだが、R言語のプログラミング知識が前提となる。
プログラミング知識が前提となる R言語に対し、プログラミング知識が無いユーザーであっても GUI操作で設定できるのが SPSS製品の1つの優れた点でもある。
Rユーザーや R を使った解析の資産がある場合、SPSS で無償で提供されている「SPSS Statistics-Integration Plug-In for R」というプラグインを利用し、両方の特性を活かした連携が可能となる。
実際に R から SPSS へ移行するユーザー、また、R と SPSS 両方を利用している現場も多くあるようだ。
様々な業務、システムに組み込まれているSPSS

最後に、数多くの SPSS導入を支援してきたスペシャリストからは、SPSS の提案、採用の際に見受けられるケースについて以下のような話を聞くことができた。
皆さんも SPSS製品の提案の際には、ぜひ、参考にして欲しい。
|
利用が広がる SPSS
弊社 (エヌアイシー・パートナーズ株式会社) は、ディストリビューターといわれるハードウェア、ソフトウェア製品を販売会社に提供する企業だが、実際の販売データをみてもSPSS ファミリーは新規導入やライセンス追加、保守の更新など取引量が増える傾向がある。
これは「ビッグデータ」という言葉が流行して久しいが、実際は「目の前にあるデータを活用できていないユーザーがまだまだ多い」というスペシャリストの言葉とも重なり、実際の世相を現しているのではないだろうか。
データの活用については、これから本格的な取り組みを始めるという企業、ユーザーも多くあるだろう。これからもデータ分析ツールは必要とされ、SPSS 製品の普及もまだまだ続くに違いない。
データ活用をビジネスに活かしたいと考えている読者は是非とも「無償トライアル」の SPSS 製品を試してみてください。
また、SPSS 製品に関してご不明なことがありましたら、弊社ビジネスパートナーや、こちらの お問い合わせ先 より お気軽にお問合せください。
最後までお読みいただきありがとうございました。