
IBM Watson(ワトソン)が人間の真のパートナーとなる日
「この事案を早く進めたいだけど判断材料が足りなくて後手後手に」・・・・皆さんはそんな経験ありませんか?
限界ある記憶力と時間の中で、私たちに適切な判断材料や新鮮なアイデアを与えてくれるシステムが欲しい、スピーディに適切な判断ができたら毎日楽しく過ごせるのだろうな、と思うことはよくありますよね。
人間は知識と経験に基づいてあらゆる可能性を考え出し、行動に移すことができます。ただ、知識や経験の蓄積には限界があります。
一方、コンピューターは、莫大なデータを蓄積することができますが、人間の右脳のような働きは苦手とされてきました。
しかし、もうそれは過去の話。IBMが打ち出した新しいコンピューター・システムの概念「コグニティブ・コンピューティング」は、人間のようなコンピューターなのです。
コグニティブ(Cognitive)は英単語では「経験的知識に基づく」という意味ですが、
このコグニティブ・コンピューティングがどんな夢をかなえてくれるものなのか、3回に渡ってお話していきたいと思います。
コグニティブ・コンピューティングを知る近道として、IBM Watsonについてお話したいと思います。
IBM Watson(ワトソン)はどう答えてくれるのか?
米のクイズ番組「Jeopardy!(ジョパディ!)」でクイズ王たちを破ったIBM Watsonは単なる検索システムではありません。
たとえば、ある質問に対して、Watsonはこんな風に回答候補を出してきます。
候補1. 綾瀬はるか 70%
候補2. スカーレット・ヨハンソン 55%
候補3. タチアナ・マスラニー 30%
(この質問文が何かは本文の最後に)
回答候補に、根拠に応じた確信度もスコアリングされています。
Jeopardy! では、Watsonは確信度が低い候補しか見つけられない場合には、自信のない回答者と同じように回答ボタンを押さずに静観するという振る舞いをするよう設計されていました。
さて、この確信度とはどのようなものなのでしょうか?
Watsonは複数の回答候補を出しますが、それは検索結果ではなく、予測結果です。それぞれの予測結果の根拠を予測モデルに当てはめて、確信度としてスコアリングしているのです。単語のヒット数をベースにスコアリングするGoogleとはココが違います。
ここで、あれ?と思われた方も多いのではないでしょうか?
予測モデルを作成し確信度を導き出すシステムはWatson以外にもありますね。
そう、Analytics分野で広いシェアを持つSPSSという予測分析ソフトウェアを思い出した方もいらしたかもしれません。
SPSSは、統計アルゴリズムを使って、過去の購買データなどから商品Aを買った人はどういう人かを分析し、顧客層毎の商品Aの購買確率をはじき出すことができるソフトウェアです。
よく使われる、ある顧客層にどういう商品カテゴリーが、来月どれ位の確率で売れるか、という問いかけに、複数の商品の回答候補と購買確率という確信度を提示する、という点でWatsonと似ているようにも思えます。
では、Watsonは何が違うのでしょうか。
なぜコグニティブか?
1.扱うデータが違う
SPSSは購買情報や商品マスタといった数値データを扱いますが、Watsonはテキストデータを扱えます。みなさんが想像できるように、数値に比べてテキストデータは、単純な集計を行うだけでも遥かに扱いにくく、まして、それをベースとした予測などは難しいと思われてきました。
例えばある企業のコールセンターで使われる膨大なFAQデータがあります。このFAQを見ながら問合せに応えるオペレータの効率化をWatsonで実現する例を考えてみましょう。
つまり、お客様の質問に対して、どの回答候補の確信度が一番高いかを導き出すという仕組みです。
これらはテキストデータをベースにするため、多くの技術を必要とします。構文解析、意味解析、文脈解析といった自然言語処理でFAQの中身を理解・整理し、問い合わせに対する回答を学習しモデル化するという多くのテクノロジーを必要とします。ここが、数値データを扱うより遥かに複雑で難しいのです。
2.言葉で対話ができる
さて、人間は当たり前ですが言葉を話します。数値データを扱う代表的な言語はSQLですが、“select”や”insert”のように似せてはいるものの自然な言語ではありません。
一方、前述のコールセンターFAQは質問も回答も言語そのものであり、その言語を読み解くために複雑なテクノロジーの多くが費やされています。つまり、質問も回答も全て自然言語で出来る、だからコグニティブなのです。
そして、これを実現するWatsonの素晴らしいテクノロジーの一つに、IBMが永年研究してきたDeepQAという存在があります。
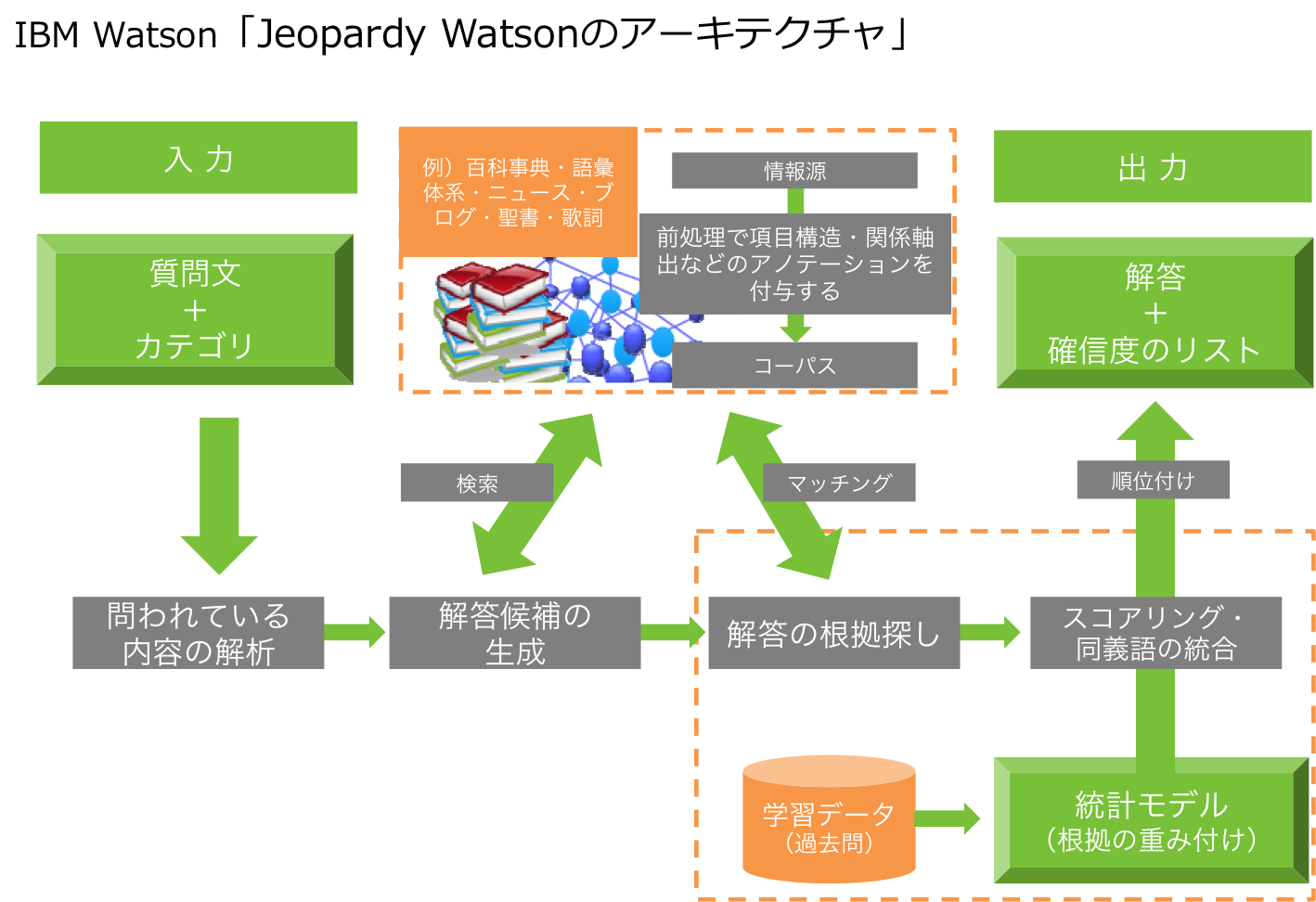
DeepQAはWatsonのコアテクノロジーである質疑応答の仕組みで、大きく2つの機能で成り立っています。(図1:DeepQAの概要)
まず、質問文のニュアンスや文脈を解析し、解答予測のための仮説が生成され、回答候補を列挙します。
質問文のバリエーションは無限にありますし、仮説を探すための情報源も膨大な量です。また、ここで候補を見落としてしまっては取り返しがつかないので、数百以上にも及ぶ候補が列挙されます。
次に、それらの候補からより正しい答えを選択するため、根拠探しと根拠に応じた確信度のスコアリングをしていきます。
確信度のスコアリングでは、機械学習によって予測精度を向上させています。
機械学習は、数値データを扱う前述のSPSSなどでも使われている手法ですが、人間だとトライ&エラーで導き出さざるを得ない回答予測のアルゴリズムを、過去のやりとりをベースにコンピューターを使って学習させ、そこから最適な回答を導き出し、さらに学習を続ける、ということをさせています。
図1 DeepQAの概要(出典IBM)
IBM Watson(ワトソン)の導入って大変?
DeepQAが、素晴らしいテクノロジーであることをご理解いただけたと同時に、Watsonを活用したビジネスを考える上で、学習データや統計モデルの設計・作成・メインテナンスが必要であることもご理解いただけたと思います。Watsonとて知らないことには答えられないのです。
汎用的かつニーズが高いものは、Watson for Oncology(がん診断支援)のように、IBMからユースケースが提供されていくでしょう。
ただ、地域特性を持った旅行業向けWatsonやある企業の業務向けWatsonなど、個々の特化型ビジネスでのWatson活用を考えると、ソリューションやサービス毎に最適化された学習データや統計モデルを作る必要があるわけです。
そこで、このDeepQAテクノロジーをもう少し簡単に実現できるソリューションとして、IBM Watson Explorer(WEX)というWatson製品をお勧めします。
Watson Explorerはコンテンツ分析ソフトウェアで、数値データだけでなくテキストデータも高速にテキストマイングが可能です。言語の意味を理解し、利用頻度の高い分析パターンや、実装を簡素化する様々なテンプレートが用意されており、視覚化による新たな知見を発見することができます。
三井住友海上火災では、このWEXを採用し、お客さまサービスの品質向上を実現しています。
お客さまが「なぜ(Why)」問い合わせされたのかを分析することで、今まで以上に効果的な傾向分析と確かな未来予測が可能となり、Webでの情報発信や要員の適正配置などにも活用しています。
このWEXについては次回詳しくご紹介したいと思います。
日本語の対応がスタート
先日、Watson日本語版APIの提供がいよいよスタートしました。
このAPIでは、DeepQAテクノロジーを活用した質疑応答ソリューションの1つ「文献などから正しい答えを探し出す」エンゲージメント機能が提供されますが、Watsonには創造的な発見を可能にしたり、判断を支援したりするソリューションも用意されています。Watson APIについは第三回でご紹介したいと思います。
おまけ
冒頭の回答候補の質問は、“遺伝子操作やクローンを題材にした作品がたくさんありますが、最近日本でドラマ化された海外作品にも出演している、カンヌ国際映画祭エントリー経験のある女優は誰か?” でした。
正解は1の、綾瀬はるかさんで、私がはまっているドラマ「私を離さないで」というイギリス作品に主演しています。ちなみに、クローン/海外作品/ドラマ/カンヌ という単語でGoogle検索すると、回答候補3のタチアナ・マスラニーさんが頻出でした。

はまっているといえば、いま一番欲しいWatson商品はこの“CogniToys”です(笑)