
生成AI の利用や導入が進む中、日本でも業務効率化や生産性の向上、課題解決、成長につなげられるなど、様々なメリットをもたらす AI活用の重要性が認識されるようになってきました。
そこで今回は、生成AI の利用における現状と課題に対して有効な解決策となるエンタープライズ向けの AIモデルの利用サイクルにおいて、データの準備、モデルのチューニング、信頼性やパフォーマンス監視にいたる範囲をカバーする企業向けの AIモデル作成・運用プラットフォーム「IBM watsonx(ワトソンエックス)」を紹介します。
| 目次 |
|---|
生成AIを取り巻く世の中の動向
ChatGPTの急速な広がり
OpenAI から2022年11月30日にリリースされた大規模言語モデル「ChatGPT」は、従来の大規模言語モデルよりも高度な会話を行うことができるその性能の高さから、全世界で「異次元のAI」として話題となりました。
リリース時の ChatGPT は GPT-3 および GPT-3.5 をベースとし、ユーザーが入力したテキストに AI が返答をするというシンプルなツールでしたが、それでも爆発的な勢いで世界中に普及し、リリースからわずか2ヵ月でユーザー数は1億人に到達しました。
改良版の GPT-4 は高度な論理的思考力を持ち、その精度の高さはアメリカの司法試験に合格できるレベルに達するとされているだけではなく、日本語をはじめとする多くの言語にも対応しており、GPT-3.5 を英語で利用する場合の精度を凌駕しています。
2023年11月に発表された GPT-4 Turbo では、従来の16倍となる300ページを超える長い文書を扱えるほかトークンの料金も引き下げられ、連携するソフトが作りやすくなっています。
ChatGPT の利用は日本でも急速に広がり、生成AI の驚異的な進化が、私たちの生活だけでなくビジネスの仕組みさえも変えようとしています。
AIはデータを燃料に競争優位性を確立するためのエンジン
大量のデータを学習することにより要約や分析、提案などの業務で高い能力を発揮する生成AI は、今後ビジネス予測や調整・問題解決・テクノロジーデザイン・プログラミングなど、分野を問わず様々なスキルに影響をおよぼすことが見込まれています。
経済産業省のデジタル時代の人材政策に関する検討会がまとめた「生成AI時代のDX推進に必要な人材・スキルの考え方(令和5年8月)」*1 では、以下の様に述べられています。
“ゴールドマン・サックスの調査によると、今後、米国の業務の 1/4 は AI により自動化される可能 性があると予測されている。また Access Partnership の調査によると、今後、日本の全労働 力のうち、約 70%の労働人口層が AI の影響を受けると予測されている”
これらの予測が示すように、企業視点で見る生成AI は DX推進を後押しするとともに企業全体の価値を高め、データを燃料に競争優位性を確立するためのエンジンとしてビジネスでの活用が期待されているのです。
*1「生成AI時代のDX推進に必要な人材・スキルの考え方(令和5年8月)」(経済産業省/デジタル時代の人材政策に関する検討会)
ダウンロード(PDF 0.2MB)企業における生成AI活用の課題
大規模言語モデルは時に“嘘”をつく
ビジネス活用でも大きく期待されている生成AI ですが、解決しなければならない大きな課題があります。
その1つが、ChatGPT に代表される大規模言語モデル(LLM)が、時に幻覚を見ているかのようにもっともらしい “嘘” をつく(事実に基づかない情報を生成する)「生成AIの幻覚(ハルシネーション)」と呼ばれる現象です。
LLM は「言葉と言葉のつながり」を学習し、その学習結果に基づいてある単語に続く単語を確率として算出し、可能性が高い「つながりそうな」単語(正確には「トークン」と呼ばれる文字のつながりを細かく区切ったもの)を続けます。
この仕組みにおいては個々の単語が持つ意味は考慮されません。
そのため、LLM のハルシネーションが発生してしまいます。
これが、LLM の生成する回答の信頼性に「検証が必須」とされる理由でもあります。
生成AIのセキュリティ・コンプライアンスリスク
生成AI を企業が活用する上で解決しなければならない課題はもう1つあります。
それは「生成AI経由の情報漏えいリスク」です。
例えば、ChatGPT による情報漏えいリスクには「入力内容(機密情報)がAIの学習に利用され、第三者に情報が渡ること」が挙げられます。
また、生成AI の学習に使われているデータ(具体的には、著作物を無断で学習データとして利用している場合)にもリスクの考慮が必要です。
このケースでは生成AI でのアウトプットに著作物が含まれてしまい、そのまま利用すると著作権違反に繋がってしまいます。
入力内容(社内情報)の利用
ChatGPT の開発企業である OpenAI社は、プライバシーポリシーに以下の目的での個人情報利用の可能性を明記しています。
- 本サービスの提供、管理、維持、分析
- 本サービスの改善・調査
- お客様とのコミュニケーション
- 新しいプログラム及びサービスの開発
- 本サービスの詐欺、犯罪行為、不正使用を防止し、当社(OpenAI)のITシステム、アーキテクチャ、及びネットワークのセキュリティ確保
- 事業譲渡
- 法的義務及び法的手続の遵守、当社および当社の関連会社、お客様またはそのほかの第三者の権利・プライバシー・安全・財産の保護
ChatGPT に入力した機密情報が社外サーバーに保存されるだけでなく、他のユーザーが ChatGPT を利用した際に機密情報が返答に使われる可能性も否定できません。
また法律上の要請のほか特定の条件下では、顧客への通知なしに第三者に個人情報を提供する可能性があることも明示されています。
ChatGPT を利用する際には、Opt Out すると共にリスクの低いデータを使うことが、情報漏えいリスクを低減するための対策の一つとなります。
※出典:プライバシーポリシー(https://openai.com/ja/policies/privacy-policy)
企業のユースケースやコンプライアンス要件を満たす「IBM watsonx」
エンタープライズ向け次世代AIプラットフォーム「IBM watsonx」
単なる AI の使用だけにとどまらず、AIモデルの学習、調整、展開を管理し、それらが生み出す価値すべてを企業が保有し、ビジネスへの活用を可能にするのが「IBM watsonx」です。
先進のオープン・テクノロジーで様々な AIモデルが作成可能な AI基盤を提供します。
企業のユースケースやコンプライアンス要件を満たし、基盤モデル(ファウンデーションモデル)ベースでの企業固有AIモデルの作成を支援します。
watsonx は企業向けのビジネス分野を対象とした AIモデル作成・運用プラットフォームで、「AI学習・生成・チューニング」「学習データ管理」「ライフサイクル管理」の3つの機能で構成されています。
これらを組み合わせることで、ユーザーによる AIモデルのトレーニング、チューニング、デブロイを支援し、データがある場所に関係なくワークロードのスケーリングとより信頼できる AIワークフローを設計できるだけではなく、AI を業務に取り入れる際の課題を解消します。
さらに、学習済みの汎用の基盤モデルには IBM の信頼できるデータ・セットに基づいて学習しているモデルも用意しているため、透明性が高く責任ある AI 実現のために担保すべきガバナンスも備えており、法律、規制、倫理、不正確さに関する懸念も排除できます。
ビジネスでの AI活用を想定して設計された watsonx は、単なる AI の使用にとどまらず、AI の価値を創出するエンタープライズ向けの次世代AIプラットフォームと言えるでしょう。
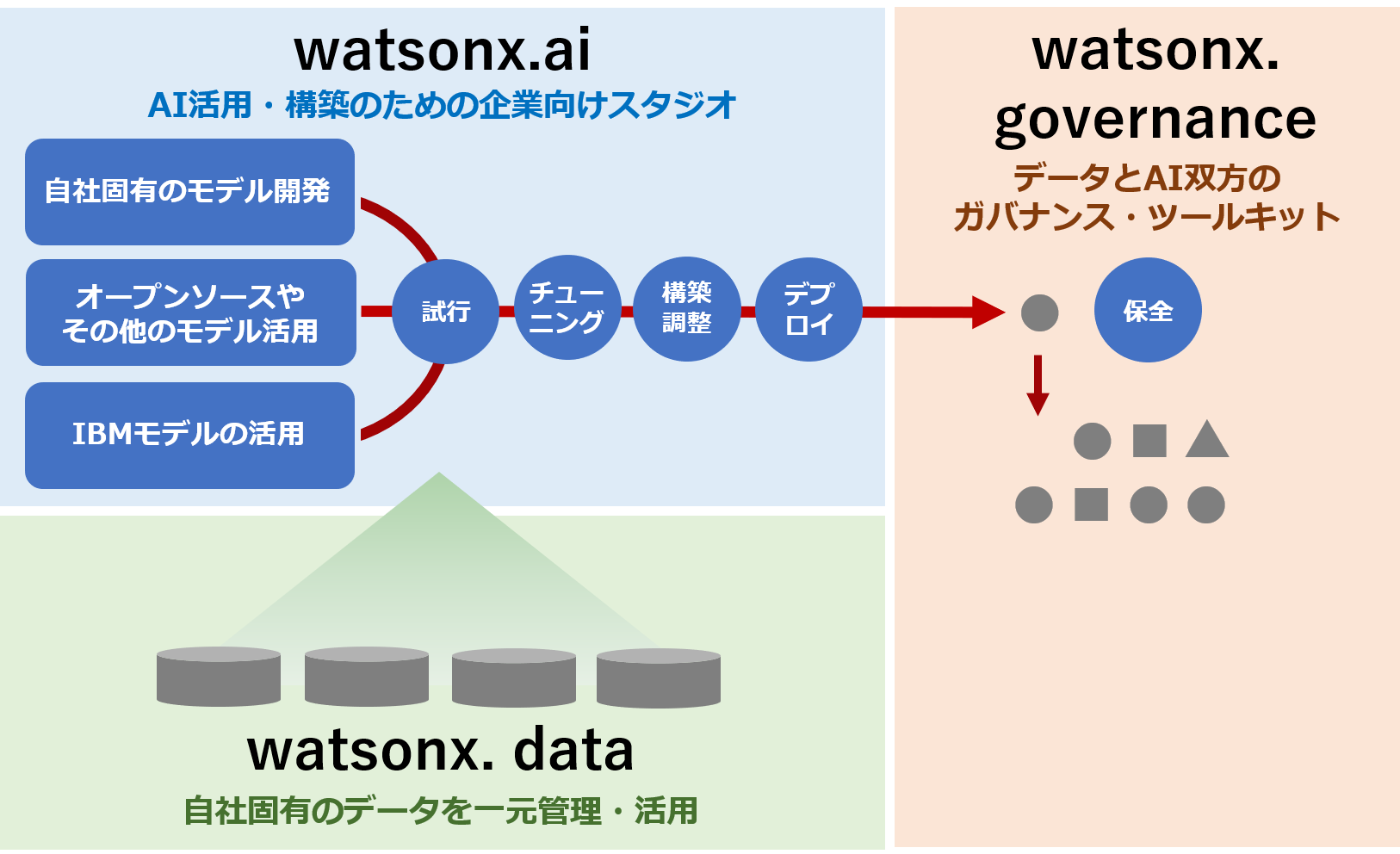
図1. 基盤モデルをはじめとしたAIモデルを活用・構築し、企業独自の価値創造を支援する「watsonx」
watsonxの3つの機能
watsonx は次の3つの機能により、「AIモデルの利用サイクルにおけるデータの準備」「モデルの開発やチューニング」「信頼性やパフォーマンス監視」にいたる範囲をすべてカバーします。
これらの AI支援機能によって、カスタマー・サービスの自動化やコードの生成、人事などの主要ワークフローの自動化など、様々なビジネス・プロセスやアプリケーション開発において、専門知識がなくても業務の遂行が可能になります。
AI作成スタジオ(AI学習・生成・チューニング)「watsonx.ai」
watsonx を構成する3機能の中核をなすのが、AIモデルのトレーニングや検証、チューニングを担う AIモデル作成スタジオ「watsonx.ai」です。
watsonx.ai は、IBM独自のファウンデーションモデルを活用した AI構築のためのオープンな企業向けスタジオ(ツール・機能群)で、企業独自の競争力と差別化を保持するために基盤モデルを活用・構築することができます。
IBM が作成したファウンデーションモデル「Granite」もしくは Hugging Face *2 ライブラリーからのオープンソースモデルで使用を開始し、学習、評価、チューニング、展開にわたり、基盤モデルや生成AIビジネスでの本格利用を支えます。
また独自のデータで追加学習する機能により、カスタマイズされた独自のファウンデーションモデルの構築も可能です。
自社固有モデルを開発し利用できるため、共有モデルと比べセキュリティリスクは大幅に低減できます。
Granite は、モデルの学習に使用されたすべてのデータ・セットが IBM内で定義されたガバナンス、リスク、コンプライアンス(GRC)のレビュー・プロセスを経た監査可能な信頼できるモデルであるため、企業向けとして最適です。
さらに、後ほど紹介するライフサイクル管理ツール「watsonx.governance」と連携し、AIライフサイクルにわたる統制やリスク・コンプライアンス管理を含めた維持・運用を実現します。
*2. Hugging Face(ハギングフェイス):
機械学習モデルを「構築」「トレーニング」「デプロイ」できる開発プラットフォーム。
AI研究者や開発者が機械学習リファレンスオープンソースを活用して、機械学習モデルの「訓練」「共有」「利用」を容易にするためのツールやライブラリを提供している。
企業固有データの管理プラットフォーム(学習データ管理)「watsonx.data」
AI をビジネスのあらゆる領域で活用するために加工する仕組みを提供するのが、IBM の次世代型データ・ストア(データ管理プラットフォーム)「watsonx.data」です。
watsonx.data は、散在する企業の固有データを一元管理し複数のクエリエンジンとストレージ層に対するワークロードを最適化するとともに、自社の業務用途に合わせた AIモデルを watsonx.ai で作る際に必要となる自社固有の学習データ(基盤モデルに対する少量の追加学習データなど)を供給します。
watsonx.data はオープン・レイクハウス・アーキテクチャー上に構築されています。
データレイクの柔軟性にデータウェアハウスのパフォーマンスを組み合わせることで、オープンでハイブリッド、ガバナンスに対応したデータ・ストアとして、あらゆるデータを分析しあらゆる場所に AIワークロードを拡張することが可能です。
ライフサイクル管理ツール「watsonx.governance」
日常のワークフローへの AI導入が進むほど、ビジネス全体で責任ある倫理的な意思決定を推進するための「事前対応型ガバナンス」の必要性が高まります。
AIモデルのライフサイクルを管理し、データと AI双方のガバナンスを保つためのツールキットが「watsonx.governance」です。
watsonx.governance はサード・パーティー製のモデルに対しても、ソフトウェアによる自動化でデータサイエンス・プラットフォームの変更にともなう過剰な費用負担なしに、リスクの軽減や規制要件の管理、倫理的懸念への対処能力を強化します。
これにより、「どのようなデータを学習させたのか」「誰がデプロイしたのか」など各種のメタデータを管理し、AI のライフサイクルを統制します。
さらに、実際に本番で使っている AIモデルの挙動を監視することで、AIモデルの精度や公平性を確認できます。
基盤モデルで迅速かつ容易にカスタマイズ
従来の AI開発のアプローチは、翻訳や分類などの目的ごとのタスクに対し、これらに応じたターゲットの回答がすでにわかっている「ラベル付きの学習データ」を大量に集め学習させそれぞれの用途に応じた AIモデルを作るため、別の用途に転用できずコストがかかっていました。
watsonx はファウンデーションモデルを用意しており、これをベースに追加学習でチューニングすることで、ゼロから機械学習モデルを作成するよりも迅速かつ容易にカスタマイズして用途ごとの AIモデルを作成できます。
さらに、1つの基盤モデルで多様なタスクに適応できるため大幅に工数と期間を削減し、学習の負荷やコストが大きいという従来の問題を解消します。
まとめ:企業経営の最適化を目指すIBMの「AI+」データ/AI戦略
昨今、様々なベンダーが企業の業務やサービスのデータに AI要素を追加する「+AI」(AIファースト)を支援し始めています。
IBM においては、お客様の「業務・サービスの自動化」「業務・サービスの見直し」「企業のコア業務改善」などの課題を AI+ で解決しています。
企業経営の最適化を目指す AI+ の戦略を体現する IBM watsonxシリーズは、AI の活用を進める企業に最適なソリューションだと言えるでしょう。
エヌアイシー・パートナーズにお任せください
エヌアイシー・パートナーズは、IBMソフトウェア/ハードウェアの認定ディストリビューターとして、watsonxシリーズをはじめとする IBM製品に関するパートナー様のビジネスを強力にサポートいたします。
「お客様のニーズや要件に合わせてIBMのSWとHWを組み合わせた最適な提案がしたい」
「IBM製品の機能や適用方法についての問い合わせに適切に対応したい」
「IBM製品の特長や利点を活かしたお客様ビジネスへの最適な提案をしたい」
といったお悩みをお抱えの方は、お気軽にエヌアイシー・パートナーズへご相談ください。
お問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いいたします。