
AI 活用が期待される分野の1つが「需要予測」です。
工場での生産量や仕入れ、販売量から営業成績、不動産の価格変動など、従来はベテランスタッフの経験や勘に頼ることが多かった領域を AI で代替できれば大きな効果につながります。
AI・機械学習のなかでも導入が進んでいる需要予測ですが、いざ自社で導入するとなると懸念も大きいもの。
本記事では、需要予測に成功したケースと失敗したケースの違いとともに、その分岐点がどこにあるのかを考えます。
Index
- 「需要予測」では、精度UPのための試行錯誤が必須
- 成功・失敗の分岐点は「必要なデータが揃っているか」
- データサイエンティストに代わるツールの登場で、AI導入のハードルは下がっている
- 「H2O Driverless AI」をPoC環境でお試しいただけます
- この記事に関するお問い合わせ
- 関連情報
「需要予測」では、精度UPのための試行錯誤が必須
AI による「需要予測」では、過去のデータや気象情報、周辺市場といった変動要素などを学習し、変化のトレンドを導き出すことで次の変化を予測します。
「ベテランの経験や勘」と言われているものもこれらの情報をベースにしているはずですが、どの情報をもとに考えているのか明確になっていないケースが多く、「経験や勘」を別のメンバーに引き継ぐにはかなりの時間がかかってしまいます。
AI を利用すれば「どの情報が関連しているか」「より影響が大きい情報がどれか」などが可視化され、データをもとにした需要予測が可能になります。
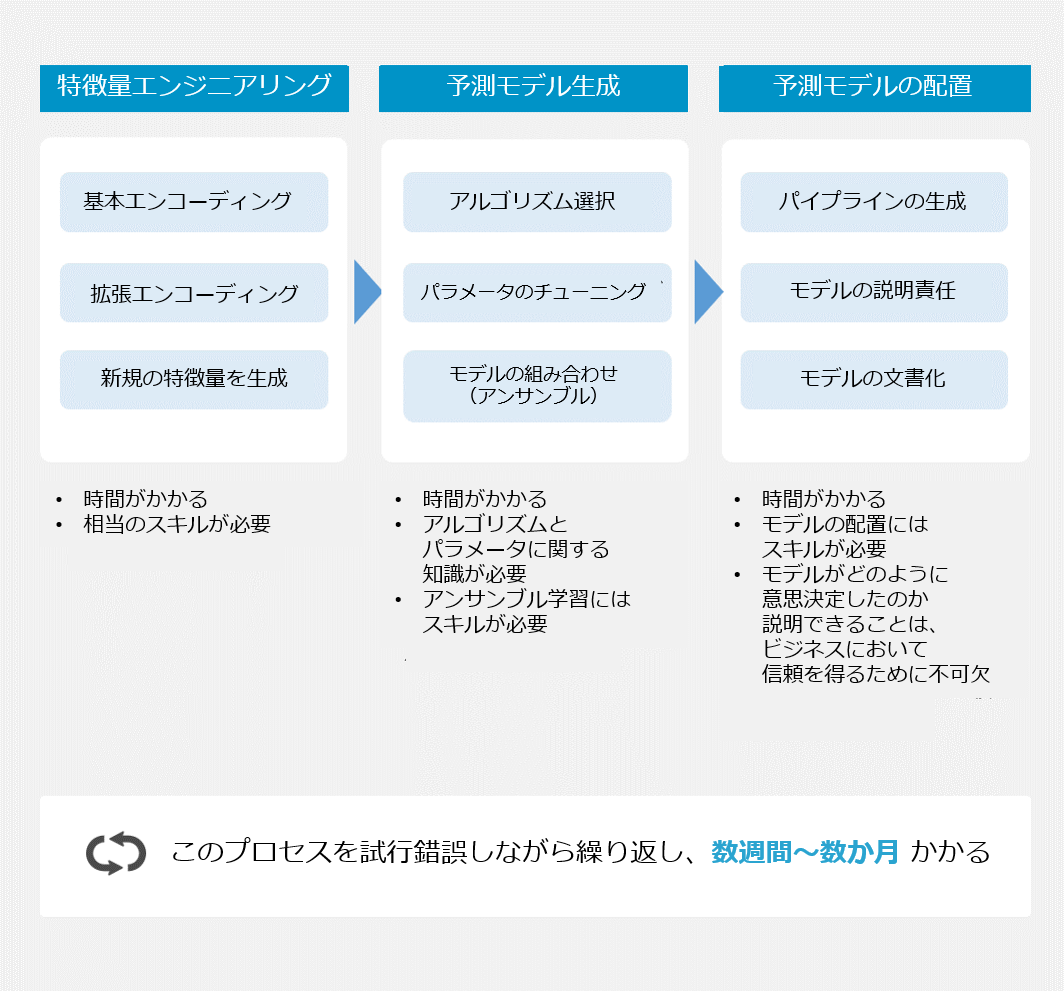
もちろん AI も最初から正確な予測ができるわけではなく、様々なデータを学習させ、試行錯誤しながら精度を改善する必要があります。
一般的には、直近1年間について AI による予測データと実績データを突き合わせることで検証し、相関性の高いデータや結果への影響度が大きいデータを見極めながらチューニングを繰り返します。
成功・失敗の分岐点は「必要なデータが揃っているか」
AI による需要予測も、成功するケースと精度があがらず失敗に終わるケースがあります。両者の違いはどこにあるのでしょうか?
成功ケースを見ると、信用できるデータを大量に確保できており、その中から需要予測につながるデータを特定することで高い精度での予測を実現しています。
一方失敗したケースの要因としては、関連するデータの種類が少ない、データの精度が信用できない、予測モデルの設計に問題がある、などが挙げられます。
このように、成功と失敗の分岐点には「必要なデータが揃っているかどうか」が大きく関わってきます。
上述したとおり、AI にできるのは「大量のデータから相関関係を導くこと」です。そのために必要なデータがなければ、AI を導入しても期待する成果は得られません。
また、必要なデータといっても予測したい内容に直接関係するものばかりでなく、様々な観点から関連するデータが揃っていることも重要ですし、適切な予測モデルを採用したうえでデータごとに関連性・重みづけをチューニングする必要があります。
需要予測を成功させるためには、関連するデータの質と量を揃えるとともに、適切なモデルを設計できるデータサイエンティストの存在が不可欠と言えそうです。
データサイエンティストに代わるツールの登場で、
AI導入のハードルは下がっている
AI 導入を成功させるには必要なデータを揃えることが重要…とはいえ、データを用意するのは一筋縄ではいきません。
「社内にどのようなデータがあるのか分からない」「必要なデータがどこにあるか分からない」「手入力のためデータの精度が不安定」「部門間で連携できない」など様々なハードルがあるほか、そもそも「属人的な要素が強く、データ化できない」というケースも。
まずはデータ連携を進め、データを統合管理できる環境を整備することも大切です。
予測モデルの設計やデータの重みづけに関しては、専門知識・スキルを持つデータサイエンティストが担っており、精度を上げるためにチューニングを繰り返し、かなりの時間がかかるのが一般的でした。
しかし、これらの作業を自動化する “H2O Driverless AI” のようなツールが登場したことでハードルが大きく下がっているのも事実。高い分析スキルを持つ人材がいなくても、短期間で一定の成果を導くことは十分可能になってきています。
これまで二の足を踏んでいた企業も、そろそろ本格的に AI 導入を検討するタイミングと言えるのではないでしょうか?
「H2O Driverless AI」をPoC環境でお試しいただけます
記事内で取り上げた「H2O Driverless AI」のPoC環境をご用意していますので、検証などの用途でご利用いただけます。ご利用いただき効果や使い易さなど、検証から導入の可否を判断できるのが大きなメリットです。
AIによる機械学習の導入をお考えの企業様には、要件定義前の検討段階でのご利用をおすすめしております。
PoC環境の利用をご希望の場合は、お取引のあるパートナー様経由での申請をお願いいたします。お取引のあるパートナー様が不明の場合はお問い合わせください。
※競合製品取り扱い企業様のお申し込みについてはお断りする場合がありますので、予めご了承ください。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBM Maximo Visual Inspection (旧 IBM Visual Insights) (製品情報)
– D/L の経験とノウハウを、誰もが使いやすい GUI でのツールとして画像・動画に関するディープラーニングに特化して提供します。 - AI導入はどこまで現実的? 5大ハードルとその解決策を解説 (ホワイトペーパー)
– よく聞かれるAIの5つのハードルについて、解決策とあわせて解説します。 - 【やってみた】H2O DriverlessAIをIBM Power System AC922で動かして競馬予想する (その1) (ブログ)
– Driverless AI で競馬の予測 (回帰分析) に挑戦しました。 - 【やってみた】超簡単データ分析!H2O Driverless AI を使ってみた (ブログ)
– 「本当に初心者でもできるのかな?」ということで、今回実際にその Driverless AI を試してみました! - 普及が進む、機械学習による異常検知。導入の課題はここまで解決している (コラム)
– 機械学習の活用が進む現状。導入の課題とその解決策までをまとめて紹介します。 - Driverless AI ご紹介資料 (資料) ※会員専用ページ
– IBM i や AIX ユーザへの提案のポイントを取り纏めた資料です。 - IBM AI ソリューションの事例ご紹介(IBM PowerAI Vison、Driverless AI)(事例) ※会員専用ページ
– 業種毎の活用ケースや導入事例をはじめ、案件発掘事例についてご紹介しています。