
こんにちは。
てくさぽBLOGメンバーの河野です。
突然ですが、「Driverless AI」ってご存知ですか?
近年データ量はますます増加の一途をたどっていますが、このいわゆるビッグデータを AI を利用して分析・予測をするソリューションが、この Driverless AI です。
Driverless AI は、汎用的な AI(強いAI)ではなく、特化型の AI(弱いAI)の位置づけです。つまり、機械学習が欠かせない AI になります。
「機械学習ってすごく大変だ…」と、つい先日まで私もそう思っていました。
しかしこの Driverless AI は、なんと機械学習の自動化ツールが備わっており、高度な知識やスキルを持たずともいとも簡単に扱えるのです!
とはいえ、「本当に初心者でもできるのかな?」
ということで、今回実際にその Driverless AI を試してみました!(ちなみに私はデータ分析は未経験です)
H2O社が開発したDriverless AI
Driverless AIという製品は米国の AI エリート集団、「 H2O.ai 」が開発したソリューションです。
今までデータ分析や予測といった業務は専門家が行っていましたが、Driverless AI は その専門家に成り代わり、業務の一部を引き受けてくれます。そのため、スキル面での人材確保でもう頭を抱える必要はありません!
専門的な知識がなくても Driverless AI を使ってデータ分析や予測業務等、日々増加するデータを活用することができるため、ますますビジネスチャンスを広げられるでしょう。
Driverless AIを使った不動産売買価格のシミュレーションモデル作成
今回の環境
- ノートPC(CPU : i5-8350U 1.7GHz、メモリ : 8GB、HDD:238GB、OS : Windows10)
- 分析データ(今回はREINS のウェブサイト「REINS Market Information」を検索して入手した不動産売買データ)
Driverless AI の導入環境については、H2O.ai 社 Web ページ「Driverless AIのインストールとアップグレード」に記載されています。
Linux X86_64、IBM Power、Mac OS X、Windows10 Pro の環境をサポートしています。
Windows10Pro 版は GPU のサポートがありませんが、今回はすぐに試したかったので、普段業務で使っている自分のノート PC に導入してみました。仕様としては、最小メモリが 16GB 以上となっていますが、使っている PC のメモリは 8GB しかありません。これも「普段使いの自分の PC で動くかどうか」というの1つの実験です。
Driverless AI の導入手順
1. Driverless AIのアプリケーションのダウンロード・導入
H2O.ai 社のホームページを読みますと、Driverless AI の導入パッケージは、それぞれの環境ごとに docker、RPM、DEB 等、複数用意されております。Windows10Pro のガイドを読むと、docker と DEB イメージの2種類用意されていました。
ここに docker イメージ利用は推奨しない、と書かれていますので、素直に DEB イメージで導入することにします。
ただし、DEB インストールをする場合でも、普段使いの Windows10 を若干カスタマイズしないと使えません。それは、Windows に Linux(Ubuntu)を導入してその上で Driverless AI が動くのです。ただその設定は、比較的簡単で、Windows10 の設定画面を呼び出して「Windows Subsystem for Linux(WSL)」を ON して、この環境にUbuntu 18.04 LTS(Microsoft Storeから無償で入手)を導入するだけです。
この導入に関しては、YouTube を参考にすると誰でもセッティングできます。素晴らしい世の中になりました。
Ubuntu を WSL に導入した後は、H2O.ai のホームページから DEB イメージの導入パッケージを自分の PC へダウンロードするだけですが、このサイズが半端ない(3GB以上)ので、ネットワーク環境によっては少々時間がかかります。
ダウンロードが完了した後、DEBイメージからインストールを実施しました。
DEB からの導入については、Linux である Ubuntu のプロンプト画面からコマンドで実施します。詳細は割愛しますが、H2O.ai 社のホームページ通りにコマンドを実行すると Ubuntu に詳しくない人でも知らずに導入ができますので、ぜひお試しください。
さあ、さっそく Driverless AI を使ってみたいところですが、その前に、H2O.ai 社が許可している21日間有効なトライアル・ライセンスを取得しておきます。
このトライアル・ライセンスの取得がとても簡単でした。H2O.ai 社のホームページから Web 申請をすると10分ほどでライセンス・キーがメールで送付されます。
図1:トライアルキーの申請書画面
すでに稼働しているDriverless AIですが、使う時はブラウザ(Google Chrome を使いました)からポート番号を呼び出して実行します。これはどのオペレーティングシステムの環境でも同じ手順になります。今回は、自分の PC で動いているので “http://localhost:12345” を指定しました。
図2:検索バーでlocalhost:12345 を指定

図3:サインイン画面に遷移
図3のサインイン画面に任意のユーザー ID とパスワードを入力して Driverless AI の GUI 画面を立ち上げました。ライセンスを要求してきますので、入手済みのトライアル用ライセンス・キー(かなり長い)をコピペで適用して、すぐに使えるようになりました。
この間サイズが大きいのでダウンロードに時間がかかりましたが、そのほかの設定や導入は至ってシンプルな印象です。慣れていない方には、ややこしいと感じられるかもしれませんが、YouTube などでも説明されていますし、「何とかなる」と感じました。
2.分析モデル作成
今回の検証では、現実にある業務として、不動産の売り出し価格を機械学習させて適切な(売れ残らず、利益もとれる)販売価格の推論モデルを作成しました。
Driverless AI で以下の3つのステップを実行します。
- データアップロード:
不動産売買データを Excel で表にし、そのExcelファイルを Driverless AI へドラッグ&ドロップ。 - ターゲットを選択:
GUI メニューを使って列名をクリック。 - Experiment -モデル作成実行-:
GUI 画面の赤枠のボタンをクリック。
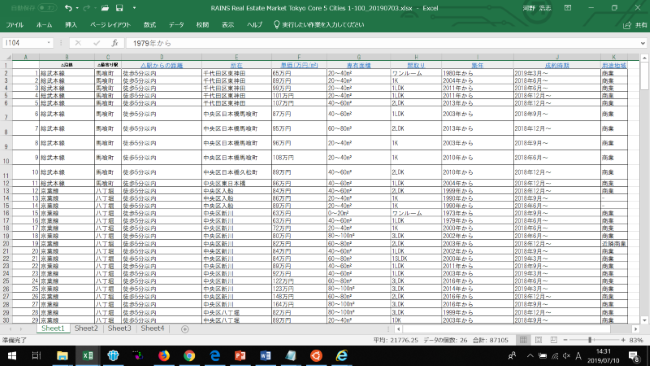
図4:不動産価格情報を検索したのち、画面のコピーから作成したファイル
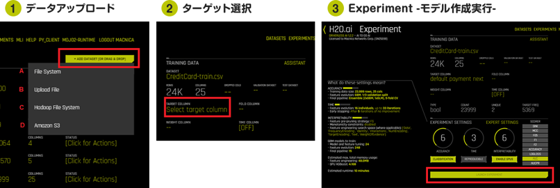
図5:Driverless AI実行画面
以上の処理はすぐ終わりましたが、検索画面コピーだけで作った図4のデータはテキスト・データだけのため(例えば価格は、150万円という表示であって、1,500,000という数字ではない)、回帰解析は作成されませんでした。
統計解析のプロから見ると当たり前のことなのでしょうけれども、初心者には、ファイルを与えてみて、試して、目で見れた結果が大事なのです。
そこで、最初に使ったデータの ”単価”、”専有面積”、”駅からの徒歩時間”など、数値であるべきものは数値に変換してみました。(図6参照)
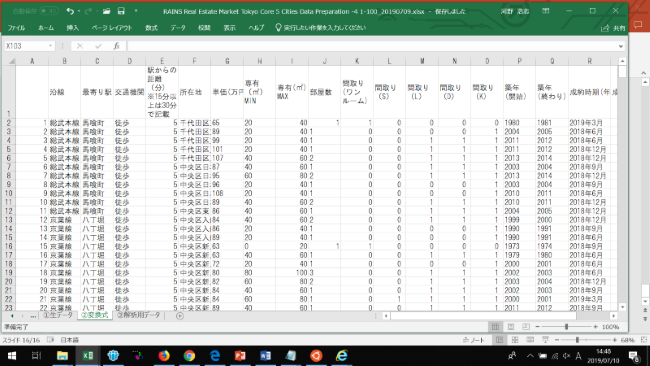
図6:価格等を数値データ変換したファイル
この図6の Excel ファイルを使って再度 Driverless AI の機械学習ステップ1から3を実行したところ、今度はモデルが作成されました。
「本当に初心者でもできたー!」
ただし、GPGPU を持たないWindows10Pro版 のため、Driverless AI のデフォルト値ではなかなか機械学習が終わらず…途中で実行をキャンセルし、パラメーターを操作して低い精度に変更してから(といっても操作はマウスでクリックするだけです)、ステップ3を実行したところ予測モデルが完成しました。
こんなところも GUI オペレーションでやりながら対応していけるのは、ありがたい。
納得のすごさ!Driverless AI
今までのツールでは、学習データを作った後もデータ欠損やどのパターンで推論するのか等のデータ整備作業を行わないと予測モデルが作成できなかったり、データ整備後もどのような分析を行うかをデータ・サイエンティストが試行錯誤する、というプロセスが必要でした。
が、この Driverless AI は、ある程度のデータ欠損には自動対応してくれます!さらに推論パターン(推論モデル)もデータから自動判断して予測モデルを作成してくれるのです!
そのため、本当に AI や機械学習の初心者でも推論モデルを作成することができてしまいました!
完成した予測モデルの精度は、実際の販売価格と比較することでわかります。
また、さらに性能アップをしたい場合は、インプットするファイルのデータの数を増やしたり、精度パラメーター (GUI から簡単に増減できます)を上げるなどしてとても簡単に実施できそうです。次は、こうしたチューニングをやってみたいと思います。
※ノート PC での実行では、データ数を増やすと演算負荷増大に繋がり、相当時間がかかる可能性があります。このような場合は、機械学習計算性能を最大化する GPGPU 演算が可能なサーバー環境(IBM PowerAC922 のように NVIDIA TeslaV100GPU を搭載するサーバー)で実行すれば、推論モデルは、より高速で作成できます。
※弊社では、AC922 で Driverless AI の実行環境(PoC 環境)の貸出しをしています。是非こちらもご活用ください!
「IBM AIソリューション PoC環境ご利用ガイド」
まとめ
ビジネスで利用する AI で重要なことは、ビジネス課題の解決に役立てるということです。
例えば、製品生産計画策定のために統計解析ツールや AI を使った生産予測をすでに行っている企業においてスムーズに業務が遂行されているケースはいいのですが、解析課題が多すぎて現状体制ではこなせなくなっている場合は、なにかしらの対策をしなければなりません。
しかし、通常の統計解析ツールや AI を使いこなすためにはかなりの勉強と経験を必要とするため、すぐに解決できないことが多いようです。育成ではなく外から人材確保するにも、企業間での採用競争が高まっており、なかなか優良な人材を確保できていないのが実情ではないでしょうか。
また、たとえ技術者がいたとしてもその人材が退職してしまうと途端に業務が滞ってしまう、という懸念もあります。
業務の AI 化というのはこれらの課題を補ってくれるツールである一方、使いこなすのもとても大変です。そのような状況において、AI を使った分析業務を簡略化したり既存の業務の補足をしてくれる Driverless AI は、まさに今の時代に待ち望まれていたソリューションだと言えるでしょう!
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp