
参加メンバーにインタビュー
皆さま、こんにちは。 企画部のWebサイト運営担当です。
去る 4月27日、28日にグランドプリンスホテル新高輪で開催された「IBM Watson Summit 2017」の参加レポートをお届けします。昨年の”参加してみた”レポート同様、Summit に参加した弊社エヌアイシー・パートナーズのメンバーにインタビューしました。
企画担当:では早速。まず、はじめに、昨年の Watson Summit と比較して感じた違いを「ひとこと」で教えてください。
昨年の Watson Summit と比較して
Kさん:昨年はみずほ銀行のコールセンターの事例が中心だったが今年は他社のコールセンターの事例も多かった。国内の大手銀行、生保は Watson の採用もしくは導入検討が進んでおり、裾野が広がってきたのだと思う。
Jさん:蔦屋(TSUTAYA)と地銀支店が連携した事例などもありましたね。
Aさん:昨年は「これからの時代はコグニティブだ」という言葉が多かったのですが、すでに実装している企業もあり、更に AI やチャットボットなど Watson に関連するテクノロジーもユーザ側がコグニティブを意識してなくても利用していると感じました。
また、この 1 年で日本IBM が直接受けた Watson 案件は 200 件を超えているという話を聞きました。いよいよ実案件でも Watson、と言った感じがしました。
代表的な事例まとめ( Watson の活用事例 2017年) ◆海外の Watson ◆日本の Watson
また、国内大手企業以外にもベンチャーや研究開発型の企業がWatsonの活用を開始している
|
企画担当:事例がどんどん増えているということですね。ところで、イベントの形式として昨年と違う点として、今年は会場に入る一般の参加者も有料のイベントになりましたよね。展示数が増え、内容も充実した思いますが、会場の様子はいかがでしょうか。
Aさん:参加者の総数は減っているはずですが、混み具合は去年と同じか、それ以上に感じましたよ。私どもの親会社である日本情報通信(株)はダイヤモンドの更に上のマーキー(Marquee)というトップのスポンサーとして出展していましたが、ブースエリアも賑わっていました。
ご参考:▼【出展レポート】 IBM Watson Summit 2017
-

- 会場風景
-

- 日本情報通信はトップレベルスポンサー
-

- 日本情報通信のブース
企画担当:なるほど、イベント会場盛況で内容としては先行事例だけでなく、Watson 採用事例の裾野が広がってきたのですね。本題に入る前に、Watson の話題がどれだけ盛り上がっていたかを企画部の Web 担当として、ちょっと違う視点で調べてみました。
ネットでみる Watson の盛り上がり
IBM Watson の注目度合いはネットの検索量でも推し量ることができます。下図は世界中の人が過去5年間の「IBM Watson」を検索したボリュームです。(Google Trendより)
トレンドラインは右肩あがりですね。(大きな谷間はクリスマス〜年末のシーズンです)
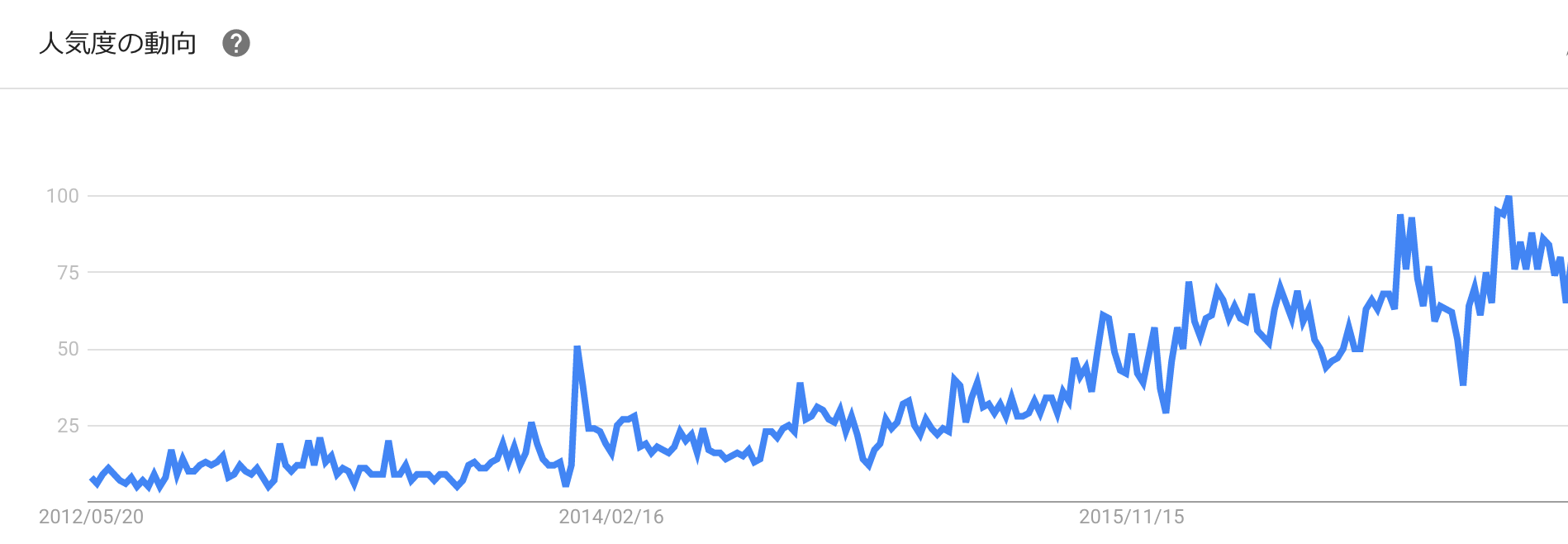
ついでに地域別の検索ボリュームをみると、1 位はシンガポール、次いでUS、インドと IT、開発の先進国と重なります。日本は 9 位でした。
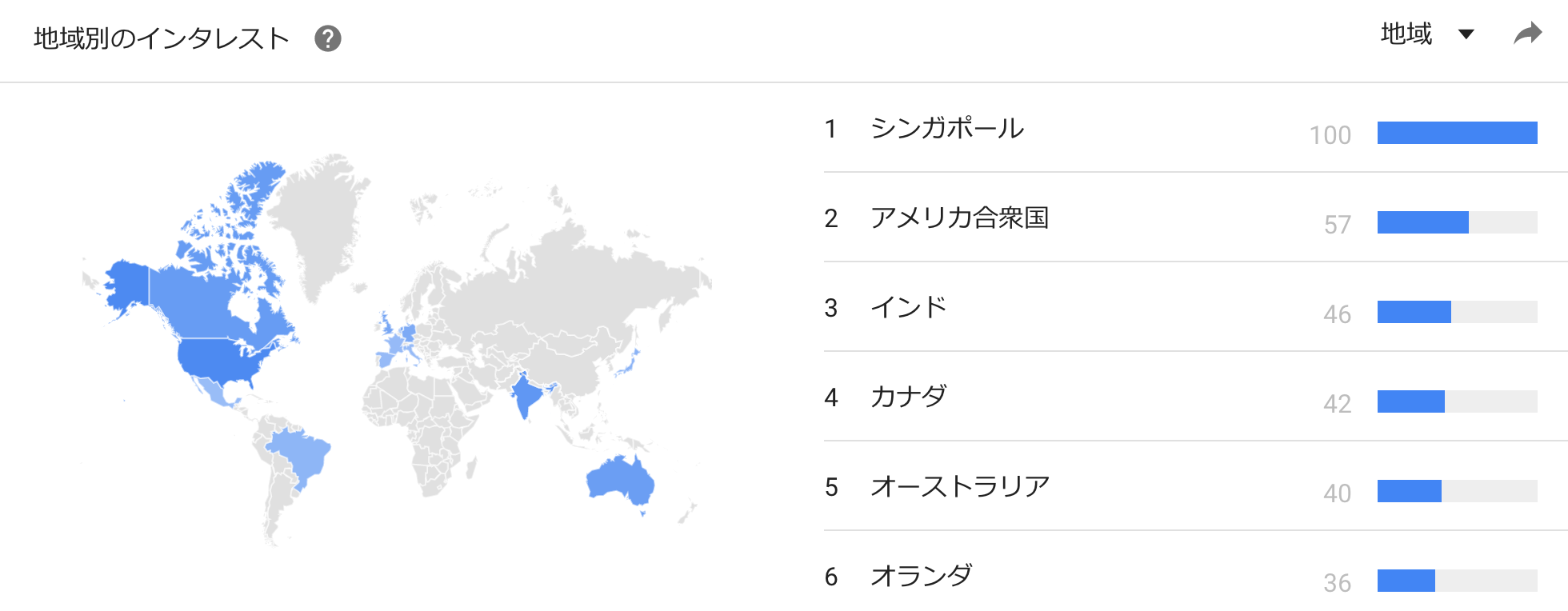
地域別の集計を都市別のメッシュを変えてみると・・・中央区が世界で 2 位です!
我が社も中央区にかまえていますのでその影響でしょうか(笑)
(ツッコミ:日本IBM本社も中央区です!)
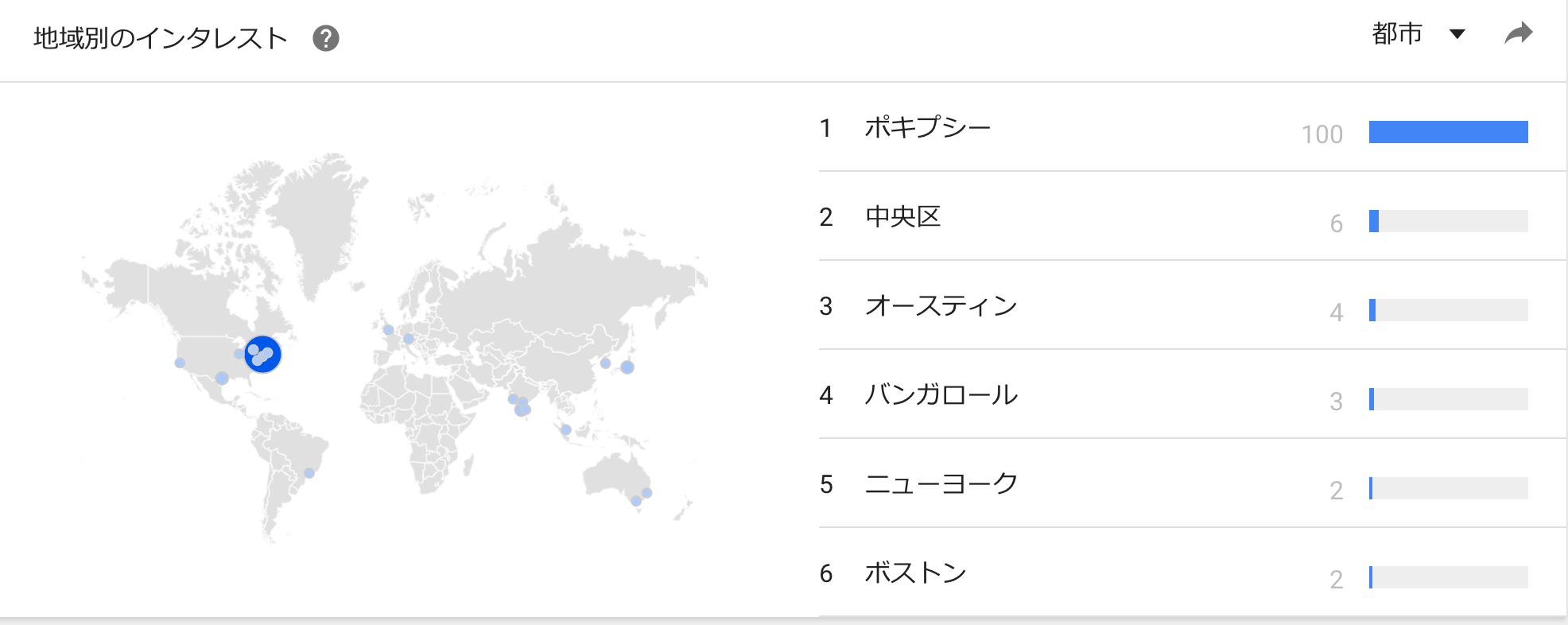
1 位のポキプシー、3 位のオースティンも IBM の研究所があり、 IT の中心都市ですからね、2 位 の中央区は検索の世界ではリードしています。
企画担当:また、昨年当サイトにて掲載の Watson Summit2016 の記事 もイベント開催1ヶ月程度前から期間中にかけて、アクセス数が 200%Up になっていました。大手メディアサイトではない弊社のページにアクセスしてくださって感謝です。
今年の Watson Summit で使われた「メッセージ」「キーワード」とは?
企画担当:このようにネットの世界でも注目されている IBM Watson について、Summit で感じたことをもっと伺おうと思います。今年の Summit の「メッセージ」はどのようなものか教えてください。メッセージが難しければ、良く使われていたキーワードでも良いです。
ハイブリッドクラウドに見る【非機能要件】と【Lift&Shift】というキーワード
Jさん:そうですね、今年の Watson Summit を一言でいうなら、「Cognitive on IBM Cloud」というメッセージを鮮明に感じました。
企画担当:Watson と Cloud が明確に一つに繋がったのですね。では、まず「IBM Cloud」についてのメッセージはいかがでしょう。
Aさん:クラウドというメッセージにおいて「非機能要件」という言葉は頻繁に聞きました。当初は「API connect を利用してオンプレからクラウドに上げると Watson が使えるんだよ」という事かと思ってましたが、そうではなく、オンプレをそのままクラウドに上げるのではなく、それぞれを分ける。というメッセージでした。

企画担当:「非機能要件」という言葉はあまり馴染みがなかったのですが、どういった定義なのでしょうか。
Jさん:「Lift&Shift」という言葉も一緒に使われていました。ハイブリッド・クラウドを構築するにあたって、既存のアプリケーションを変えなくてよいものと書き直してクラウドに持っていくものの 2つ に分けて考えるというところから来ています。この時に変えなくてよいものをパブリック・クラウドに持っていくと、従来はオンプレのアプリケーションの下層で動いていた管理、監視、制御などの部分もクラウド上で自分で構築する必要に迫られる。この部分を「非機能要件」と呼んでいます。
一方で、書き直すクラウドにもっていくアプリケーションの移行方法を「Lift&Shift」と呼んでいるようです。
Aさん:そうそう、オンプレをそのままパブリック・クラウドに上げるのは無理があるので、IBM Bluemix Infrastructure (Softlayer) では、ベアメタルを用意しているんですよ、オンプレからシステム管理も含めてベアメタルに持っていけばいんだよ、というメッセージですね。
Kさん:「非機能要件」と「Lift&Shift」については、どのセッションでも話題として出ていました。
企画担当:なるほど、IBM Bluemix Infrastructure(SoftLayer)の強みを活かしたアプローチですね。クラウドのキーワード、メッセージは他にもありましたか?
クラウド時代の戦略【オープンスタンダート】とは?
Jさん:IBM Cloud はBluemix という PaaS 環境がベースになっているので、まずはそこから入り、アプリケーションの差別化に Watson / コグニティブ が IBM の強みとなっています。さらにアプリケーションが使うデータがキーとなります。データという意味では IT 業界では DB のあるべき姿を考え、SQL と NonSQL のトピックになりがちですが、「データレイク」をキチンと管理しようという話をされています。
これらのデータの扱いについては、IBM は全て「オープンスタンダード」で答えています。つまり IBM というベンダー製品で抱え込むのではなく、仕様をオープンにしていく、オープンソースを活用するという意味です。IBM はオープンスタンダードに投資し、そこから出てきたテクノロジー、会社を買収するという戦略をとっていて、全方位で隙間がないように、ニッチなエリアに対しても同じ「オープンスタンダード」を戦略にしています。エンドユーザから見ても「ベンダーロックインを回避でき、自由度が広がる」という利点につながります。
Aさん:「データレイク」というキーワードは昨年のWatson Summitでも登場してましたね。

Sさん:私は 3 月にラスベガスで開催された IBM 最大のイベントInterconnect 2017 に参加してきましたが、テクニカルな面での IBM のメッセージは Watson Summit もほぼ同じでした。
IBM Bluemix Infrastructure (SoftLayer) 関連では Cloud Automation Manager というマルチクラウド、オンプレのいずれにも対応したデプロイ管理ツールがオープンスタンダードのひとつだと思います。マルチクラウドということは SoftLayer だけでなく、AWS や Azure なども対象となるということです。現在は、IBM Bluemix 上に無料で提供開始していて注目されています。
企画担当:Blumix 自体がオープン・クラウド・アーキテクチャーの実装プラットフォームですから戦略は理解しやすいですね。では次に、Watson に関連した製品・サービスという切り口ではどのようなメッセージ、キーワードが Summit で話題になっていましたか?
Watson の知識データ
Jさん:データの扱いについてですが、知識ベースの構築しかり、大事なのはデータを Watson で扱える状態にすることです。いわゆる「コーパス」と呼ばれる AI の知識データですね。ここをどう構築していくかが鍵でもあり、泥臭い領域ではあるのですが、このテキスト分析の行程で「Watson Knowledge Studio」を大々的にメッセージしていました。「Watson Knowledge Studio」は、開発者と各分野の専門家が協力して、特定の業界向で利用されている言葉の意味を理解する機械学習モデルを、開発者と知見者である専門家が協力して作成できるクラウド・ベースのアプリケーションです。ブラウザ環境ですし、無料トライアルもあるので試しに使ってみるユーザが増えると思います。
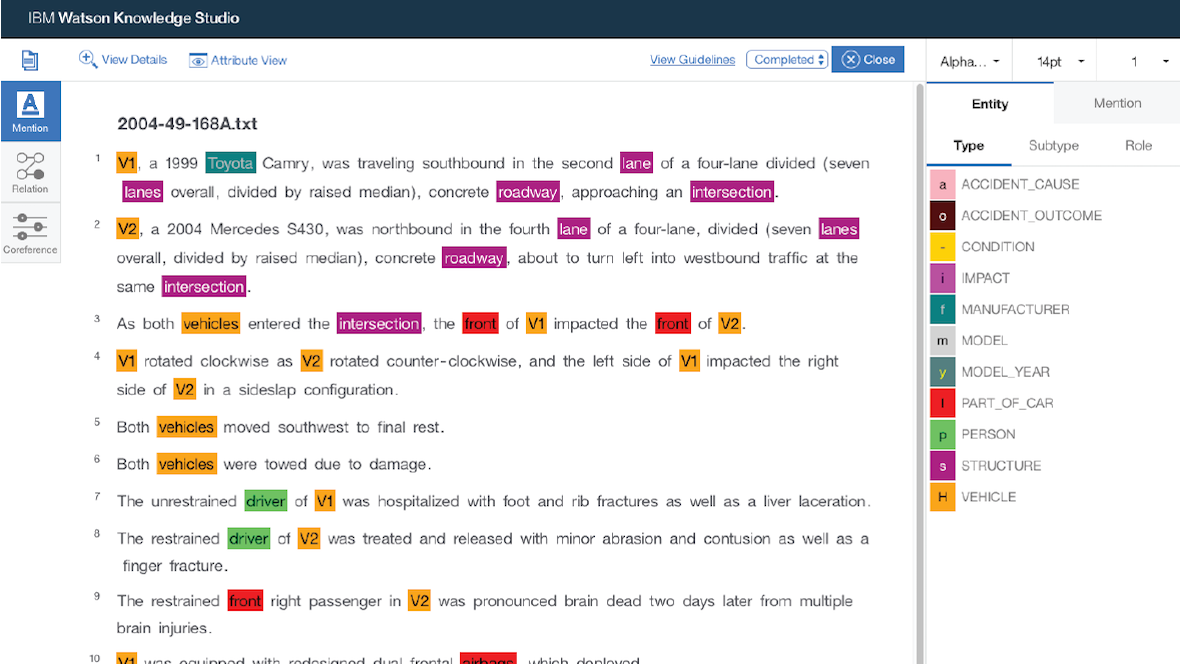
Watson Knowledge Studioの画面
企画担当:Web サイトを見ると「特定の業界向けのカスタム・アノテーター・コンポーネントを作成できる」と表記されていますが、要するに「業界特有の用語や知識のニュアンスを Watson に教えることができる」という感じですね。やはりテキスト分析は重要ですよね。
Aさん:ユーザのセッションで女性研究員2名によるテキスト分析の話がありました。大量のデータの中に、「川崎」という文字が出てきた時に人の名前なのか地名なのかをどのように識別させるかというトピックなど興味深い話でした。ユーザは色々試行錯誤されているようです。
学習済み Watson の提供
Jさん:一昔前の AI はルールの定義という作業でひとつひとつの言葉を定義する必要がありました。そして機械学習が主流になっていくのです。IBM ではこの領域は SPSS のテキストマイニングなどのナレッジが活かされています。サービスインまでに Watson にある程度覚えさせる行程とリリース後に覚えさせる行程がありますが、コグニティブの世界ではこのコーパスを作るところは泥臭い作業で、特にリリース後のユーザの参加は必須ですね。
企画担当:データ分析の領域において、近年は「データサイエンティスト」という分析担当者に注目されていましたね。
Jさん:最近、IBM は「データサイエンティストのようなスーパーマンはそんなに多くはいない」と言い始めています。確かに私も個人的に存在を一人も知りません(笑)。DSX(Data Science Experience)というプラットフォームを IBM は用意しています。一人のスーパーマンではなく、データの準備、整備、プログラム開発、分析など行程をわけてチームワークでデータサイエンスを始めるためのプラットフォーム。こういうのが出てくるのは Knowledge Studio と同様に市場がコグニティブの導入検討ではなく、実際の導入の際に生産性に影響しているプロセスの改善ニーズがあるのだと思います。Watson も「何に使えるのか」から「どうやって効率的に使うか」のフェーズに入ってきたのですね。
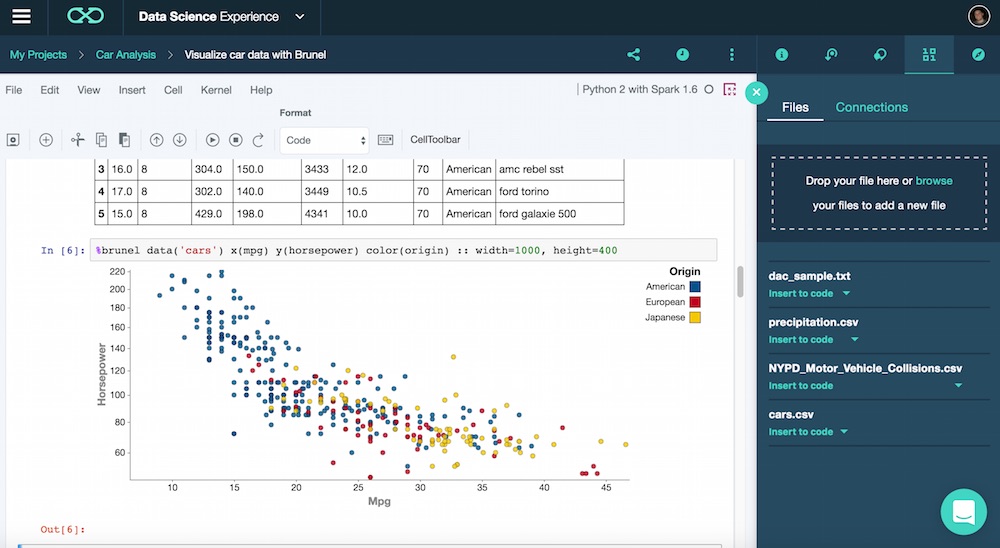
Data Science Experienceの画面
企画担当:全体のメッセージは先行事例から次のフェーズに来ているということですね。先行投資できる企業は良いですが、研究や開発に大きな投資ができない企業はどうすれば良いでしょうか。
Jさん:IBM はインダストリー別に「”学習済み” Watson」をリリースしていくとこのイベントでも発信しています。例えば「Watson automobile」は自動車業界向けというように業界別にパッケージし、金融、製薬など現在 80 種類ほどの学習済 Watson をリリースしていくとのこと。
企画担当:企業が持つ「データレイク」やナレッジを知識ベースとして提供し、学習済みの Watson が用意されていく、オープンスタンダードな思想をもとに Watson を利用したサービスが増えていく・・・こんな近未来が見えてきますね。
Jさん:気象データや医療文献情報などもそのうちの一つですね。IBM 自体も The Weather Company を買収して、気象データを提供する側になっています。
今後のビジネス展開 – API 化
企画担当:こういった環境において、ビジネス面で考えるとシステムインテグレーターやソリューションプロバイダーはどのような戦術が必要になるのでしょうか。
Aさん:私の理解ですが、Watson は API のことを示していると思います。そして知識ベースは個別のインダストリーで用意する。この知識ベースを構築する行程はシステムインテグレータなどのベンダーがユーザをリードし、一緒に構築していく領域だと思います。
Kさん:テキスト分析、データマイニングの経験が豊富なベンダーは優位ですね。また、Web アプリ、API 開発が得意なベンダーにもチャンスだと思います。IBM は「IBM マーケットプレイス」をラウンチしていますが、日本国内はまだ立ち上がったばかりです。
このマーケットプレイスで開発ベンダーは開発した API、ソリューションをカタログ化して掲載できるのです。
企画担当:なるほど、開発力はあるが営業力が弱いといったベンチャー型の会社や部門は参入のチャンスですね。
Jさん:そうですね、「今後は API 化してほしい」というのが IBM のメッセージです。ユーザ、パートナー企業を含めた「API エコノミーの推進」とも言えます。
企画担当:ありがとうございます。初歩的な質問をしますが、一般企業が API 化することの利点ってどんなことがありますか?
Jさん:例えば、フライト情報を検索、表示する旅行会社のアプリがあって、コンシューマーがフライト情報にアクセスする度に航空会社の Web を参照するアプリの仕様だと提供側の航空会社の Web サーバの負荷は高くなります。いわゆる Web スクレイピング、Web クローリングという技術ですね。これを API アクセスすることで Web サーバーの負荷が減ります。情報開示側が API 化しておくことで、開発ベンダーは様々な API を組合せてより良いサービスやアプリケーションを作っていけるのです。
Aさん:API 化しておけば、「Lift&Shift」の際に、クラウド or オンプレ という移行もスムーズになりそうです。
Jさん:API 化はマイクロサービス化と言い換えてもいいだろうと思います。
企画担当:開発会社、エンジニアから見て、API 実装自体は新しいことではないと思いますが、マーケットプレイスにパッケージしてカタログ化していくことも最初から意識するという点でベンダーにとっては新しいビジネスモデルになりそうですね。
IBM マーケットプレイスなどのエコシステムについてはディストリビューターの弊社としても要ウォッチですね。 今後もエヌアイシー・パートナーズの取引先の皆様には専用Web サイト「MERITひろば」でより詳しい情報を掲載していきたいと思います。
本日はありがとうございました。
【関連リンク】


