
皆様こんにちは。てくさぽBLOGメンバーの佐野です。
4月に書いたハイパーコンバージドの紹介記事が好評のようで、ありがたいです。
今回は皆様も興味があると思いますNutanixについて詳しく書きます。
1.Nutanixとは
Nutanixは2009年に創業した会社で、GoogleやFacebookなどをスピンアウトした人々が設立しました。
Nutanixが目指す先は「インビジブルなインフラストラクチャー」です。
インビジブルとは「見えない=意識しなくてよい存在」という意味で、ユーザーや管理者があまり意識せずに簡単に使えるインフラを目指しています。
これを実現するために、Nutanixでは専用ストレージやSANスイッチを排除したシンプルな環境であるハイパー・コンバージド製品をアプライアンスとして提供しています。
ストレージやSANスイッチが存在しないことでストレージの管理スキルが不要となり、サーバー管理者が全てを管理できるようになるため、運用管理の点でお客様にメリットが生まれます。
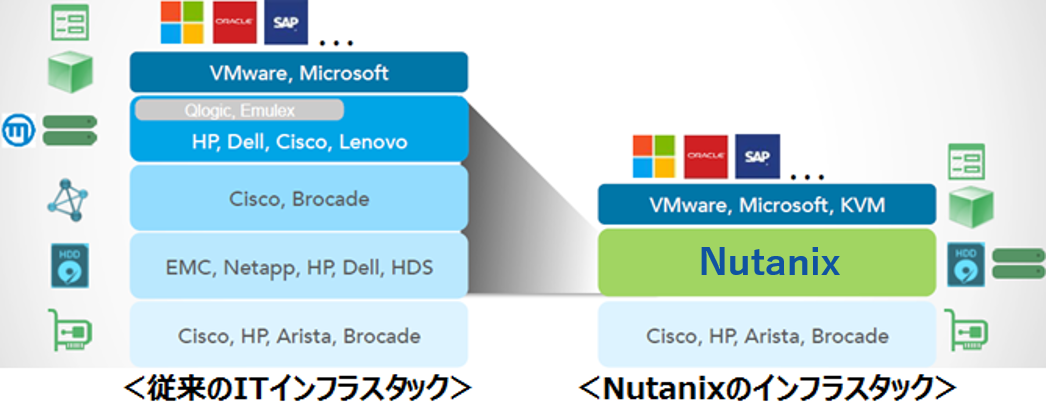
従来のITインフラスタックとNutanixのインフラスタックの簡単な構成要素の比較図は以下になります。
これを見て頂くと、インフラを構成する要素が大幅に減っていることが分かると思います。
日本ではまだ知名度はそれほど高くありませんが、米国での知名度はかなり高く、NutanixはGartnerの2015年のMagic Quadrantではリーダーの位置づけになっています。
(参考サイト)http://www.slaitconsulting.com/nutanix-leader-2015-gartner-magic-quadrant-integrated-systems/
2.Nutanixの特徴
Nutanix製品の最大の特長は、GoogleやFacebook、Amazonといった超大規模な独自のシステムのメリット(スケールやメンテナンスの効率化)を一般企業でも利用できるように分散ファイルシステムを独自で開発し、アプライアンスとして提供していることです。
Nutanixアプライアンスは最低3ノードから利用開始でき、1ノード単位で増設することができるため、リソースの利用効率を高めながら拡張していくことが可能です。
拡張の際にも、事前にハイパーバイザーが導入済みで出荷されるため、機器を搭載しネットワークを接続して電源をつなぐだけよく、数十分で利用開始することができます。
もちろん、既存環境に追加・拡張を行う際にシステム停止は必要ありません。
SANやNASがないため、前述のインフラスタックを見ても分かる通り、シンプルな構成となっており障害発生時にも問題の解決がスムーズに行えます。
システム運用開始後には、単一の管理Web画面である”Prism”を見ることで、システムのリソース状況からシステムの状況まで確認することができます。
上に添付してある画像がPrismの画面ですが、画面を縦に4分割して見ると、左から、システム概要、パフォーマンス、システムヘルス、アラートの情報となっています。
このように、日常の運用管理においても単一のWeb画面を確認すればよいため、個別に確認をしなくてはいけない従来の基盤に比べて運用負荷を格段に減らすことができます。
3.Nutanixの信頼性
Nutanixのデータ冗長化は、現在ディスクの冗長化でよく使われるRAIDは利用しておらず、ノード間での2重ミラーリングもしくは3重ミラーリング(Proエディション以上必須)での冗長化となります。
RAIDはノード内でのデータ保護となるため、ノードがダウンすると全てのデータが失われてしまいますが、他のノードにデータをコピーしていればノードダウン時にも復旧ができるのがこのNutanixが採用している方式のメリットです。
また、ノード障害が発生した後、自動的にデータの冗長化を復旧させるセルフヒーリングが発動し、特に管理者が何かの操作を実施しなくても、データの冗長性は確保されます。
副次的な効果として、RAIDのようなパリティーの再計算をしなくて済むので、復旧時間も早く済むことが多いようです。
<イレージャー・コーディング>
2重ミラーリング・3重ミラーリングでは、単純に2倍・3倍のディスク容量が必要となりますが、Nutanixではイレージャー・コーディングもサポートしています。
イレージャー・コーディングはオブジェクトストレージでよく使われるデータ冗長・容量削減の方式です。具体的にはデータを分割し、その分割後のデータに対してパリティを付与することで冗長性を担保します。
簡単にイメージ図を以下に図示しておきます。
メリットは、容量が2重コピーに比べて削減できること、2重コピーと同様に1台のノードがダウンしてもデータが復旧できることが挙げられます。
デメリットは、データの分割・パリティ計算にCPU能力を使ってしまうことです。
処理能力への影響が大きいので、イレージャー・コーディングの利用はコールドデータ(=HDDのデータ)に対してのみの適用が推奨されています。
4.Nutanixの動作
ここからはNutanixでのデータを書き込みと読み込み動作について書きます。
Nutanixでは、IO要求は全てController VM(以下CVM)が処理を行います。CVMは、各ノードに1台だけが稼働し、そのノードに接続しているSSD・HDDに対してIOの処理を行います。
・データの書き込み時の動作
データ書き込み時(2重ミラーリング)には、
1.ゲストOSからの書き込み要求が発生するとCVMが要求を受け取る
2.ノードのローカルに接続されているSSDに(容量に空きがあれば)データを書き込み
3.他のノード上のCVMへデータの書き込みを要求
4.2.と同様にローカルのSSDにデータを書き込み
5.ゲストOSに書き込み完了の通知
という流れを踏みます。この流れを見てもらえばわかる通り、データは必ず別のノードにミラーリングして書き込みがなされます。
図示すると以下のような流れとなります。
SSDからHDDへは定期的にデータが退避されるようになっていて、アクセス頻度の低いデータをSSDからHDDに移動します。このため、SSDは常に空きがある状態となるため、IOを非常に高速に実行することができます。
・データ読み込み時の動作
データの読み込み時は、書き込みしたデータがノードのローカルに必ずあるはずですので、ローカルからの読み込みになります。そのため、ノード間の通信が発生せずパフォーマンス上のメリットがあります。
仮にvMotionなどを利用した後で書き込みをしたノード上に仮想マシンが動作していないような場合には、ネットワーク越しに不足しているデータを読み込みますので、ローカルにデータがないからエラーになるというようなことはありません。この場合、読み込んだデータはローカルに保管しますので、2度目以降の読み込み発生時にはノード間の通信は発生しません。
5.ラインナップ
NutanixアプライアンスにはNXシリーズと500名以下の企業を対象としたXpressモデルの2種類があります。
現在Xpressモデルの詳細情報を入手できていないので、ここにスペックなどを書くことはできませんが、
・最大4ノードまで
・ソフトウェアの機能に一部制限あり(専用のXpressエディション)
・ご購入頂ける企業は従業員数500名以下
といった制限がある代わりに、かなり安価にご購入頂けるモデルとなっています。
NXシリーズはXpressモデルのような制限はなく、ソフトウェアも3つのエディション(Starter、Pro、Ulitamate)から選択頂けます。
最新はBroadwell CPUを搭載したG5モデルとなり、以下の4つのモデルがあります。

機器のサイジング結果次第で、どのモデルを選択するのかは変わってきますが、ほとんどの場合がNX-1000シリーズもしくはNX-3000シリーズからスタートします。
お客様環境のNutanixクラスタ内で、複数のモデルを混在させることができますので、まずはNX-1000シリーズから導入し、追加するワークロードに合わせてNX-3000を増設していくなんてこともできます。
モデル設定の際には特に2U4ノードモデルを採用することでラックスペース削減に大きく効いてきますので、是非既存の環境とTCOを比べてみてください。
6.まとめ
本記事ではNutanixに関する概要と少し詳しい解説をお届けいたしました。もっと詳しい内容も書きたかったのですが、記事スペースの関係上、ここまでが限界です。
ご要望や反響が大きければ続編も書きますのでお楽しみに!
<関連記事>
ハイパーコンバージド製品のNutanixを解説! Vol.2
ハイパーコンバージド製品のNutanixを解説! Vol.3
10分でわかる『Nutanix製品』まとめ New! (※ MERITひろば へのログインが必要です。)
———-
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp