
こんにちは。てくさぽBLOGメンバー佐野です。
前回のPart1 では、Flexera One の概要と検証環境についての説明をしました。
今回のPart2では実際に導入検証した内容を共有します。
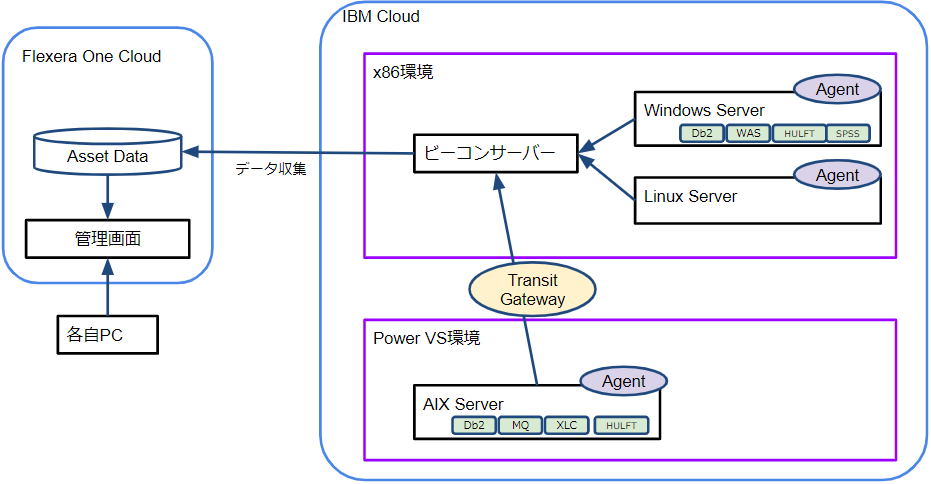
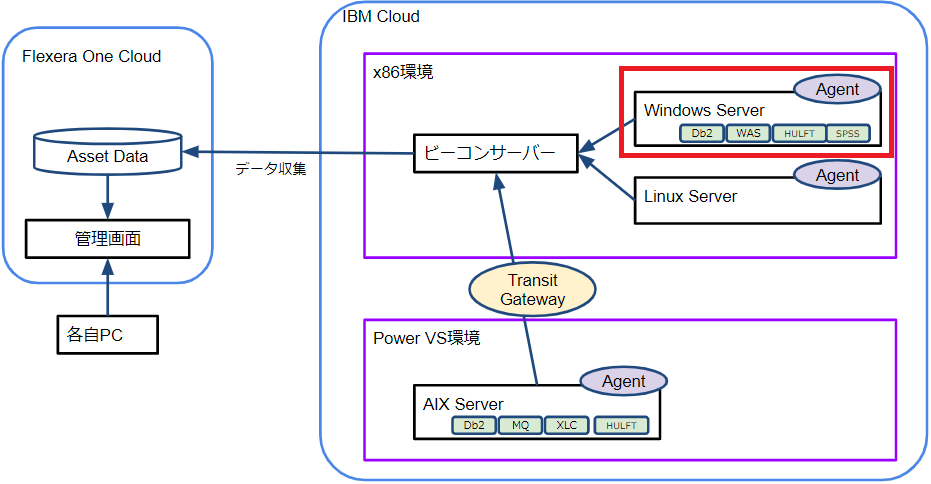
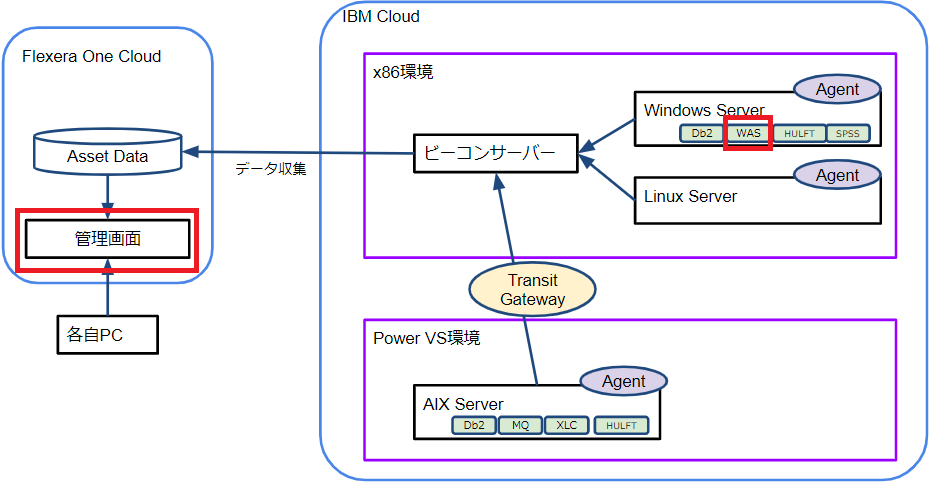
前回のおさらいとして、検証環境の構成を再掲します。
今回の検証手順の紹介において、Flexera OneはSaaSですので、SaaSの契約およびプロビジョニングまで完了していることが前提となります。
また、初回ログインのための最初のユーザー登録は済んでいる状態と想定しております。ログインが求められる場合にはこのユーザーで実施下さい。
導入手順の検証
Flexera One を検証するにあたって、以下の手順で構築を進めました。
今回はエージェント導入先として Windowsサーバーへの導入検証結果・手順を共有します。
※エージェント導入対象サーバーの構築手順については省略します
1.ビーコンサーバーの構築
まず初めにビーコンサーバーを構築します。
![]()
システム要件に書いてある通り、OS は Windows Server 2012 から 2022、Windows 8,10,11 がサポート対象です。
ソフトウェアの要件として Power Shell 3.0以上と IIS7.0 with ASP.NET 4.5.2以上(ただし.NET v 4.6.2以上推奨)が必要です。
本検証環境では Windows Server 2022 を利用しています。
※英語版で構築したため画面ショットが全て英語となっていることご了承ください。
ビーコンサーバーを構築するためには以下のステップが必要となります。それぞれについて操作を進めていきます。
1-1.事前設定(信頼済みサイトの設定、IIS導入、.NET導入、TLS設定)
1-2.ビーコンサーバープログラムのダウンロードおよびインストール
1-3.ビーコンサーバー設定
1-1.事前設定(信頼済みサイトの設定、IIS導入、.NET導入、TLS設定)
IBM Cloud上にデプロイされている Windows Server 2022 ではシステム要件に必要な IIS、.NET などは導入済みでしたので省略します。TLS も要件にある 1.1/1.2 が設定されていました。
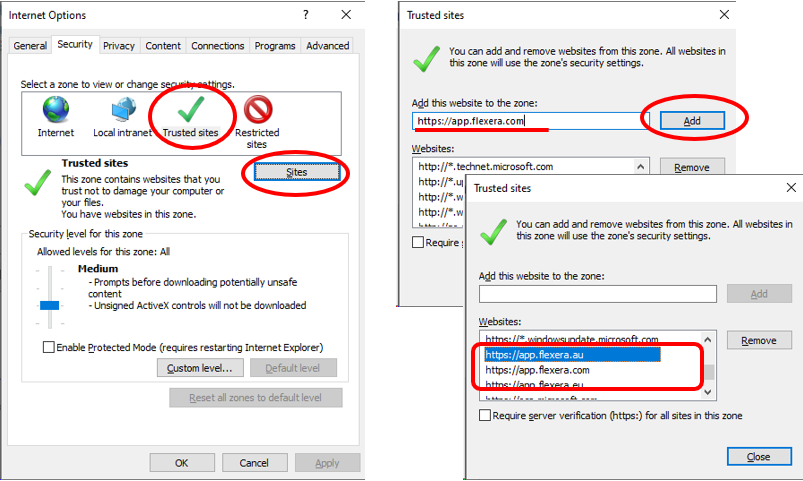
個別に設定が必要なものは「信頼済みサイトの設定」のみでした。
IEのインターネットオプションから「Trusted Site」で指定されたドメインを信頼済みサイトとして登録します。
検証時点ではSaaSの管理サーバーとして選択できるロケーションがヨーロッパと北米であったため、距離が近い北米で契約・デプロイしました。そのため、「https://app.flexera.com」を設定しています。
※2023年3月時点ではアジアも選択できるようになっています
これで事前の設定は終了です。次にビーコンサーバーのプログラムを導入していきます。
1-2.ビーコンサーバープログラムのダウンロードおよびインストール
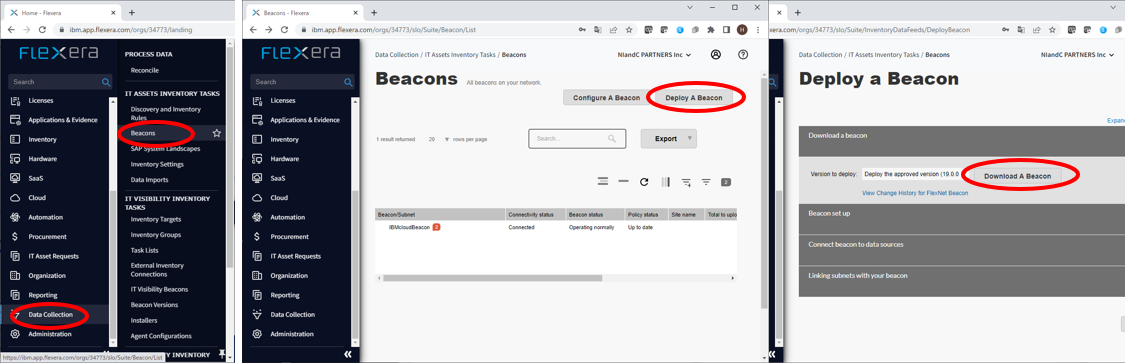
Flexera One の管理画面にログインし、プログラムをダウンロードします。
- 左側のペインにある「Data Collection」から「IT ASSETS INVENTORY TASKS」内の「Beacons」を選択します。
- 画面右上に表示されている「Deploy A Beacon」ボタンを押します。
- 「Download a beacon」内にある「Download A Beacon」ボタンを押します。もしバージョンを変更したい場合には「Version to Deploy」欄に表示されているバージョンから変更ください。
ビーコンサーバー上以外でダウンロードを実行した場合にはダウンロードした実行ファイルをビーコンサーバーへコピーします。
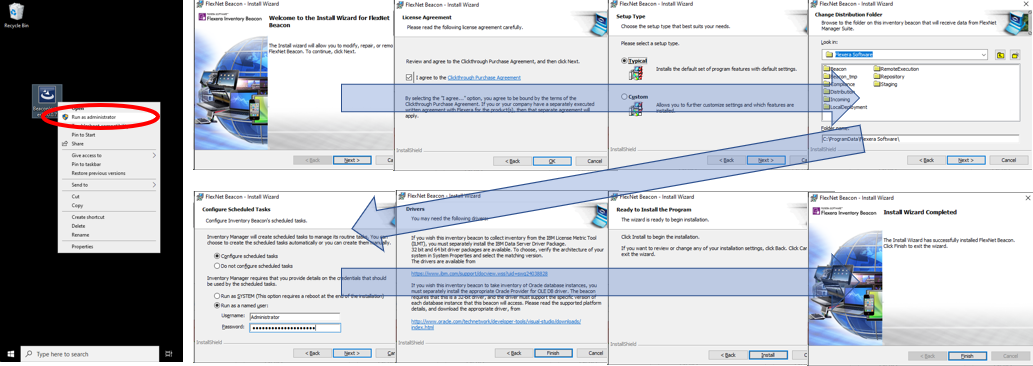
- 実行ファイルを右クリックし「管理者として実行」を選択し実行します。
- 「Next」を押し、操作を進めます。特に何かを変更する必要はありません。
「Configure Scheduled Tasks」では「Run as a named user」が選択されているのでそのまま、管理者権限を持つユーザー名とパスワードを入力します。 - “Install Wizard Completed”が表示されればインストール終了です。
1-3.ビーコンサーバー設定
次にビーコンサーバーからインベントリ情報をFlexera One環境へアップロードするための設定をします。
- インストールした「FlexNet Beacon」を右クリックし「管理者として実行」を選択し実行します。
- Parent Connectionを有効化するため「Enable parenet connection」にチェックを入れます。
- 「Configure inventory beacon connection」内の「Configure and import configuration file」をチェックし「Download Configuration」ボタンを押します。
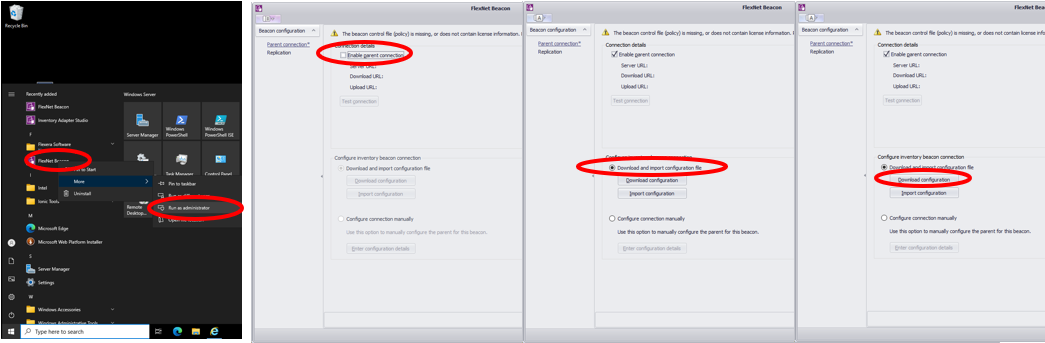
- ブラウザが自動的に起動し、Flexera Oneの画面が表示されますのでログインします。
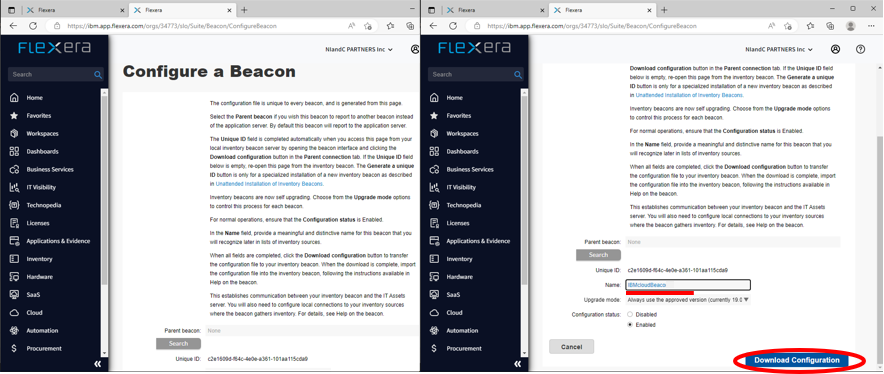
- 「Configure Beacon」ページが表示されるので、Name欄にビーコンサーバーの名前を入れます。今回はビーコンサーバーのホスト名である「IBMcloudBeaco」と入れます。他の項目は変更しません。
- 「Download Configuration」ボタンを押します。拡張子が「flxconfig」となっているファイルをダウンロードし保存します。
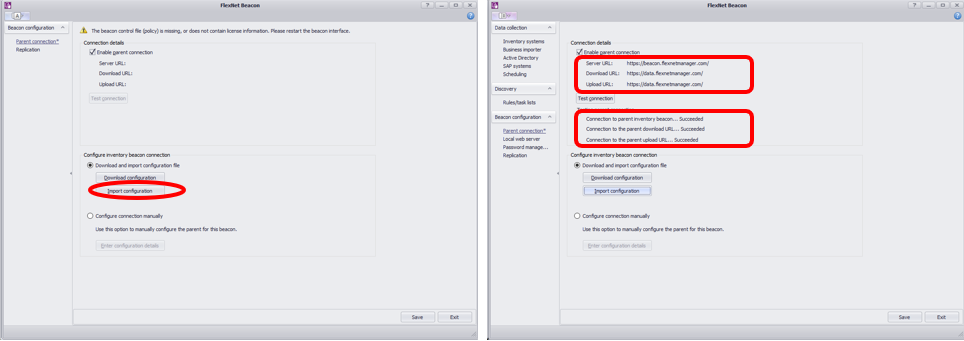
- (FlexNet Beaconが起動していない場合)ビーコンサーバーの「FlexNet Beacon」を右クリックし「管理者として実行」を選択し実行します。
- ウィンドウの真ん中にある「Download and import configuration file」を選択し「Import configuration」ボタンを押します。
- 先ほどダウンロードした設定ファイルをインポートし「Connection details」欄にServer URLやDownload URL、Upload URLなどが表示されることを確認します。
- その後、Testing parent connectio…欄の結果が “Succeeded” になることを確認します。
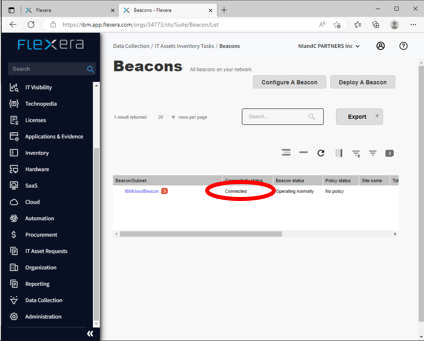
- Flexera One画面の左側のペインにある「Data Collection」から「IT ASSETS INVENTORY TASKS」内の「Beacons」に登録したビーコンサーバーが表示され、「Connectivity status」が “Connected” になっていることを確認します。
ここまででビーコンサーバーの設定は終了です。
次に管理対象サーバーにエージェントを導入します。
2.エージェントの導入
管理対象サーバーにエージェントを導入します。
今回は Windowsサーバーへエージェントを導入する手順を紹介します。
AIX や Linux は設定ファイルの書き方や実行方法が異なりますので詳細はエージェント導入のドキュメントをご参照下さい。
また、導入先のシステム要件は必ず事前に確認するようにして下さい。
エージェントの導入は以下ステップで実施します。
2-1.エージェントをダウンロードする
2-2.エージェント導入前の設定ファイルを作成する
2-3.エージェントを導入する
2-1.エージェントをダウンロードする
Flexera Oneエージェントを管理画面からダウンロードします。
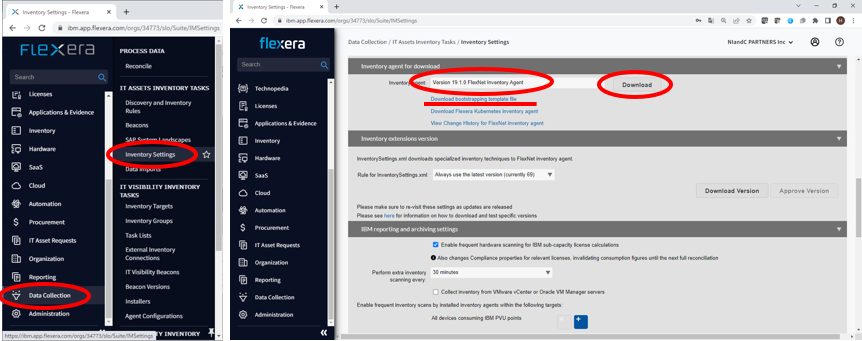
- 左側のメニュー「Data Collection」から「IT ASSETS INVENTORY TASKS」内の「Inventory Settings」を選択します。
- Inventory agent for download欄にある”Inventory agent:”からバージョンと導入先プラットフォームに適切な組み合わせを選びます。今回はWindowsなので”Version 19.1.0 FlexNet Inventory Agent”を選択し「Download」ボタンを押します。
- また、この後設定に使う設定ファイルも”Download bootstrapping template file”リンクからダウンロードします。
- ダウンロードしたエージェントのプログラム(ZIP)を解凍し設定ファイルを「FlexNet Inventory Agent.msi」と同じディレクトリ内に配置します。
2-2.エージェント導入前の設定ファイルを作成する
こちらを参考にしてエージェント導入前に設定ファイルを作成します。
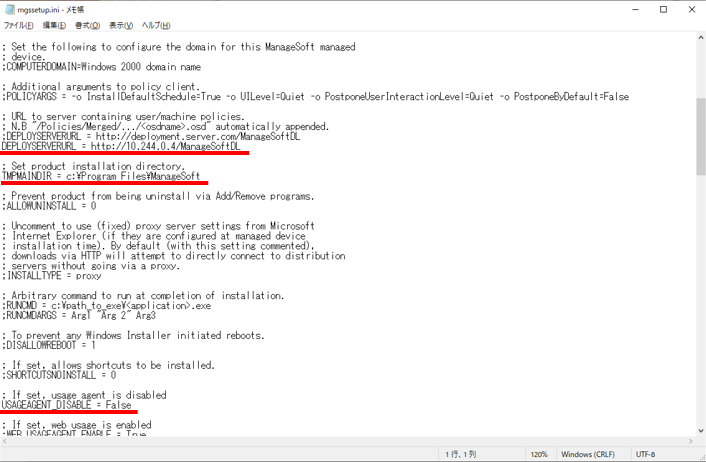
- ダウンロードした設定ファイルから3点変更します。
- URLを変更
DEPLOYSERVERURL = http://10.244.0.4/ManageSoftDL
※”10.244.0.4″はビーコンサーバーのIPアドレスを指定します。 - 以下2行の冒頭にあるコメント(;)を外す
TMPMAINDIR = c:\Program Files\ManageSoft
USAGEAGENT_DISABLE = False
- URLを変更
2-3.エージェントを導入する
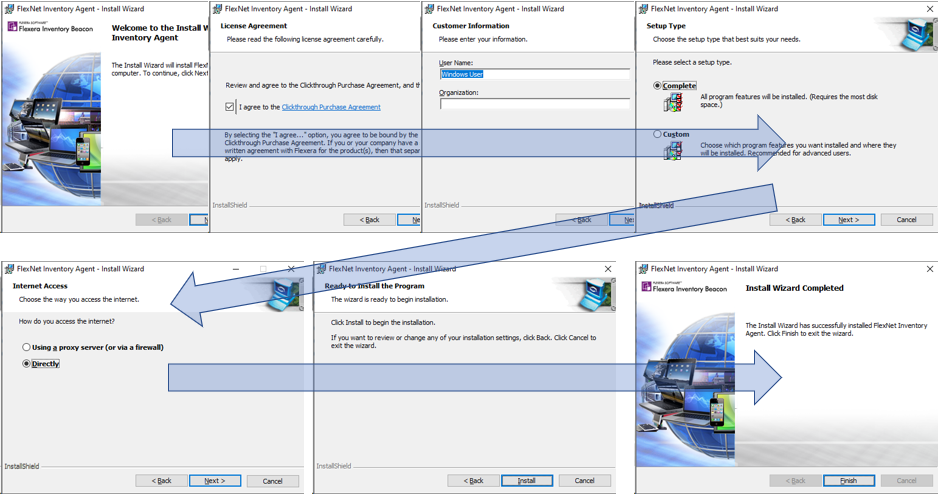
- 「FlexNet Inventory Agent.msi」を実行します。
基本、デフォルトの選択のままで進めればOKです。
エラーが発生せずに”Install Wizard Completed”と表示が出ればインストール完了です。
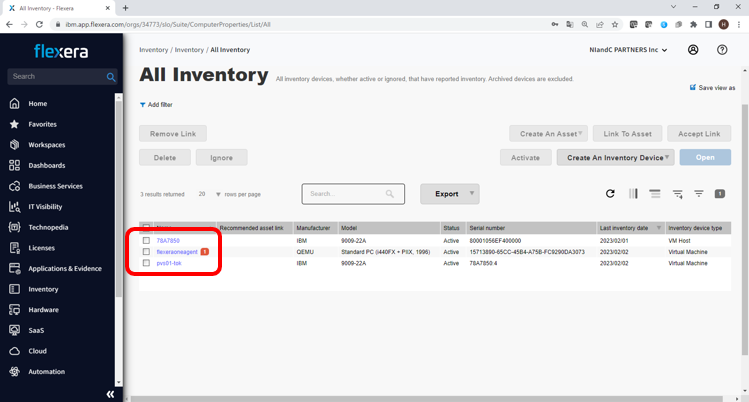
- エージェント導入後にしばらく待つと、Flexera One管理画面の左側のペインにある「Inventory」から「INVENTORY」内「All Inventory」ページにエージェントを導入したホスト名が表示されます。
ホスト名が表示されたらエージェントから収集したデータがビーコンサーバー経由でFlexara One環境にアップロードされたため、正常にセットアップできたことが確認できました。
※図はWindowsだけでなくPower Virtual Serverもエージェントを導入した後となります
3.レポートの出力
ソフトウェアの導入状況と数量のレポートを出力します。
エージェント導入サーバーに管理対象となるソフトウェアを導入し、Flexera One の管理画面でライセンスの登録およびレポート出力を実行します。
今回はIBMソフトウェアをサブキャパシティとして利用していることのレポートを出力します。
対象ソフトウェアは WebSphere Application Server 9.0 Base(以下 WAS)となります。
レポート出力は以下のステップで実施します。
3-0. エージェント導入サーバーへWASの導入
3-1. ライセンスの登録
3-2. ライセンス数量入力
3-3. レポート出力
3-0. エージェント導入サーバーへWASの導入
エージェント導入サーバーへ WAS を導入します。
この手順はエージェント導入前に実施しても問題ありません。
※本ブログはFlexera Oneの導入ブログであるため、WAS の導入手順は省略します
3-1. ライセンスの登録
レポートを出力するためには、ご自身が所有しているライセンスを登録し、そのライセンスを Flexera One が検出したソフトウェアと紐づける必要があります。
そのため、まずは利用しているソフトウェアのライセンスを登録します。
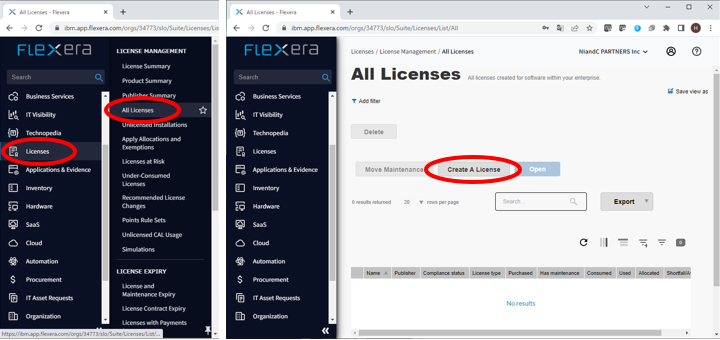
- Flexera One管理画面の左側のペインにある「License」から「LICENSE MANAGEMETNT」内「All Licenses」を選択します。
- 画面中央付近にある「Create A License」ボタンを押します。
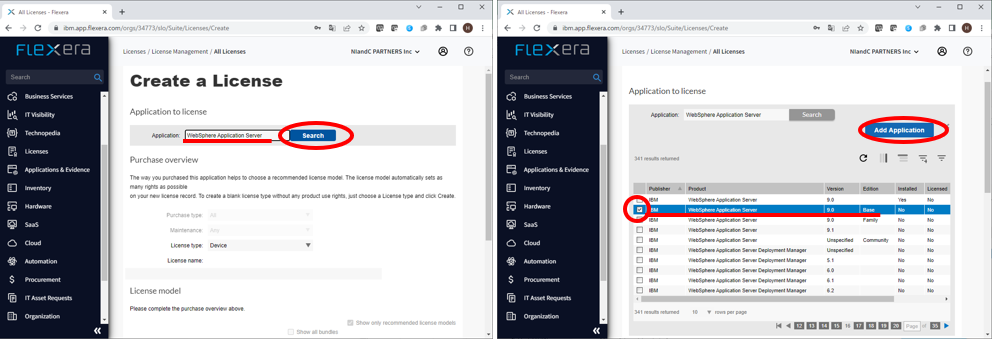
- 「Application:」欄に”WebSphere Application Server”を入力し「Search」ボタンを押します。
- 検索結果に表示されたProductから導入している製品(WebSphere Application Server 9.0 Base)を選択します。
- 「Add Application」ボタンを押します。
- 「License Type」で「IBM PVU」を選択します。
- 「Create」ボタンを押します。
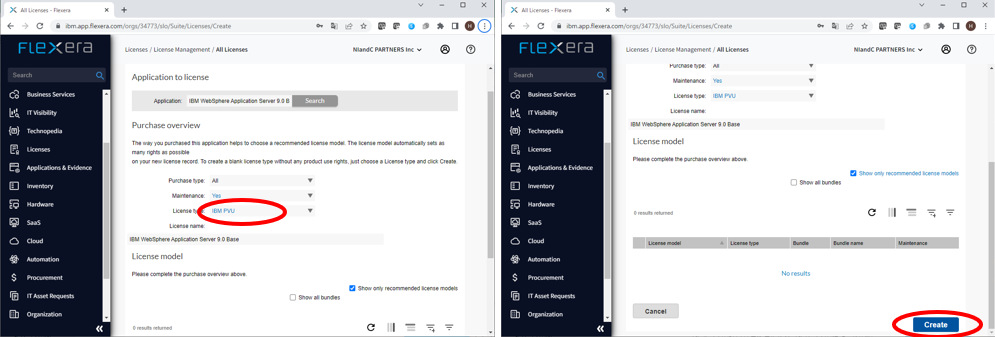
これで WebSphere Application Server のライセンスが登録できました。
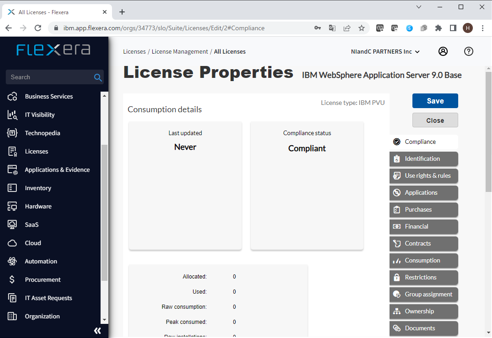
この後に保有しているライセンス数量を入力します。
3-2. ライセンス数量入力
保有している WAS のライセンス数量を入力します。
- 右側にある「Compliance」を選択し、中央ペインの下段に「Entitlements and consumption」項目にライセンス数量を入力します。
- 「Extra entitlements」項目の「+」の右側に保有しているライセンス数量を入力します。
今回は400PVU分と入力し、ページ右上にある「Save」ボタンを押します。
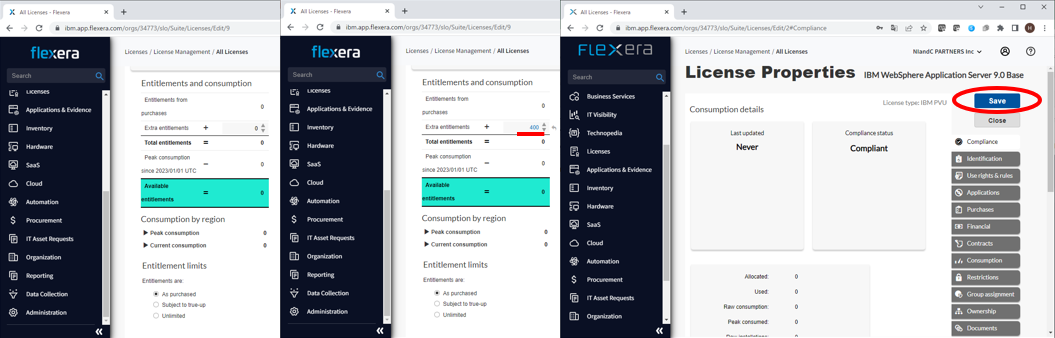
これでライセンス数量の入力まで終わりました。
3-3. レポート出力
最後にレポートを出力します。
今回は IBMソフトウェアをサブキャパシティとして利用していることのレポートとなるので、IBM の Auditレポートになります。
※WAS は PVU課金の製品であるため、PVU課金のレポート画面から内容を確認した上で Auditレポートを出力します
- Flexera One管理画面の左側のペインにある「Reporting」から「LICENSE REPORTS」内「IBM PVU License Consumption」を選択します。
- 「Run Report」ボタンを押します。
少し待つと、画面下段の表に「License Name」が「IBM WebSphere Application Server 9.0」となっている項目が出てきます。
※画像では他のソフトウェアも表示されています表内で「License Consumption」列に現在WASが稼働しているサーバーのスペックにあわせたPVU数が表示されていることを確認します。
※反映までに時間がかかることがあるので、もし出てこない場合には翌日再確認してみてください
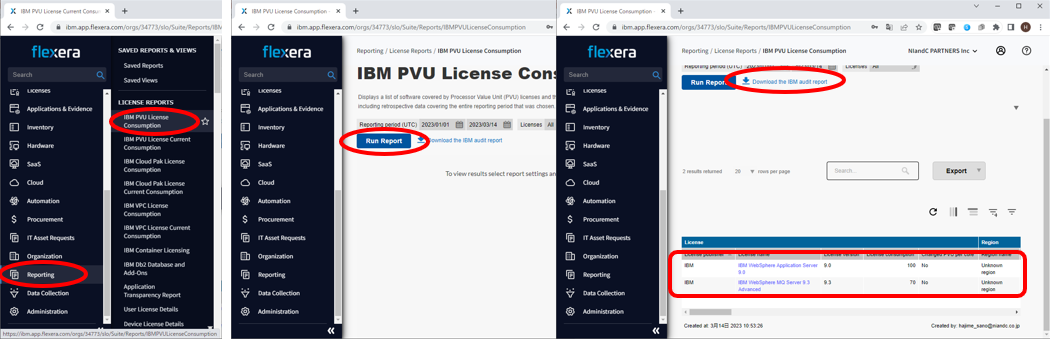
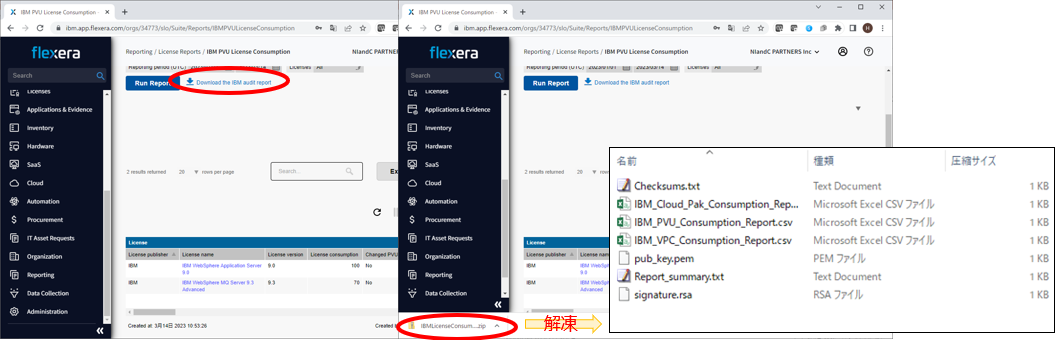
- 正しく内容が反映されている場合には「Run Report」ボタンの右側にある「Download the IBM audit report」リンクをクリックします。
- これにより、ZIPファイルに圧縮されたIBM Audit Reportをダウンロードできます。
IBMへはこちらのZIPファイルをご提出ください。 - ZIPファイルの中身を見ると、環境内にあるPVU・VPC課金、Cloud Pakライセンスのインベントリ情報、使用数量などのデータが入っているCSVファイルが存在することが分かります。
(各CSVファイルの中身を確認し、保有数量と消費している数量に乖離が無いかを念のためご確認頂くのがよいでしょう)
おわりに
Flexera One を使った IBMソフトウェアのライセンスの監査レポートの出力までの手順を追って説明いたしました。
今回は Windowsサーバーを対象にした手順をご紹介しましたが、AIX や Linux の場合に異なるのはエージェントの導入方法のみで管理画面の操作方法は同じです。
管理対象のプラットフォームが違っていても一つの画面でソフトウェアの導入状況が分かり、監査レポートとして提出できるのは非常に良い点だと感じました。
また、Flexera One を利用する際に RDBMS をはじめとした他の製品が不要なので、問題の切り分け対応が楽です。
今回は検証していませんが、SaaS や IaaS のコスト管理・最適化機能もありますので、ソフトウェアを管理するだけでなくSaaS含めたコストの最適化ができ、応用範囲が広い製品です。
ご興味ある方は是非使ってみて下さい。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp