
こんにちは。
てくさぽBLOGメンバーの 高村です。
2021年に IBM Power Virtual Server(以下 PowerVS)のプロビジョニング、バックアップ、x86環境との接続をトライしたやってみたBLOG「IBM Power Virtual Server でAIX環境を作ってみた」を公開しました。
今回は PowerVS から IBM COS へバックアップ取得を想定し、AIX環境から Proxyサーバ経由で IBM COS へファイル転送を行う手順をご紹介します。
IBM COS については以前のブログ「【早わかり】IBM Cloud Object Storageを見積してみよう」でご紹介しているのでご覧ください。
それでは早速構築手順をご紹介いたします。
| セクション |
|---|
1)接続イメージのご説明
図の赤い線が今回検証したプライベートネットワーク経由の PowerVS から IBM COS の接続です。青い線はパブリックネットワーク経由で端末から各サービスに接続する経路になります。
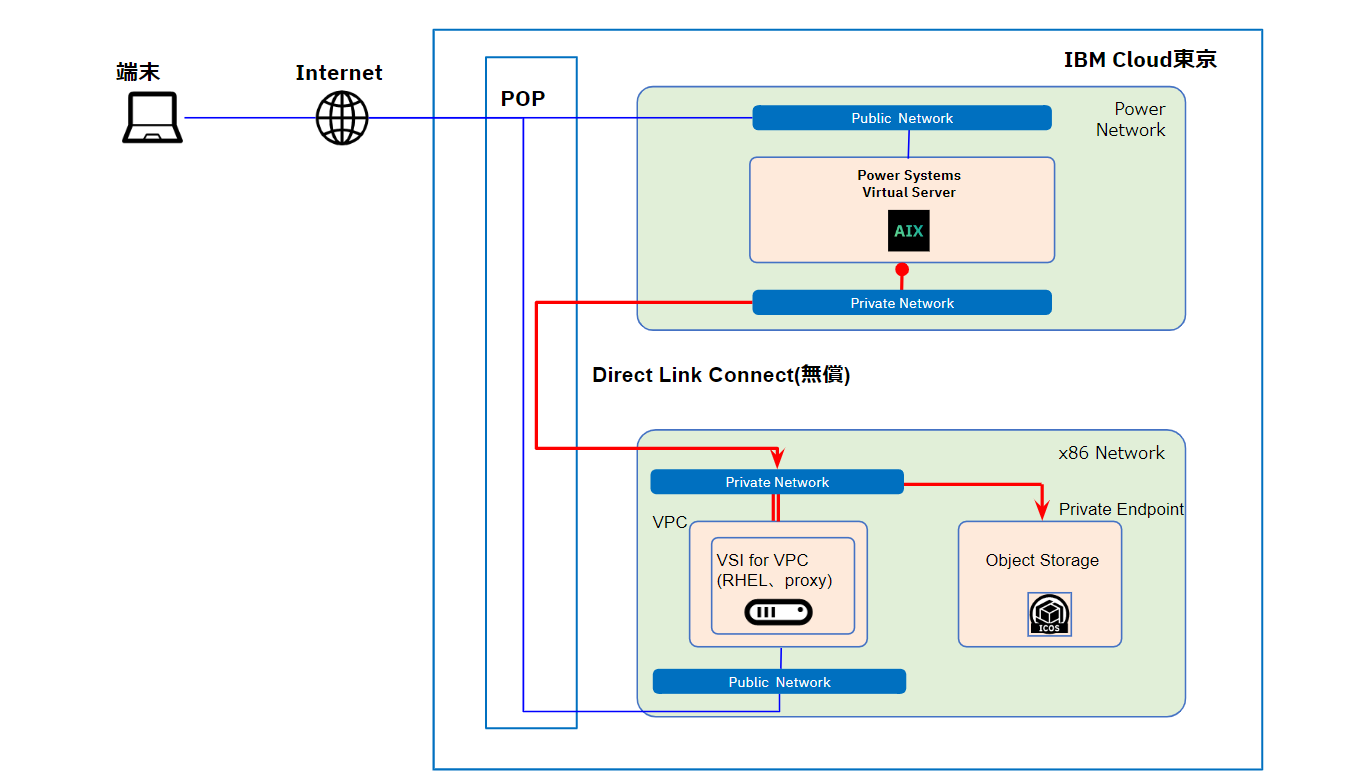
まず PowerVS と IBM Cloud(x86環境)接続ですが、両者はネットワークが独立に管理されているため直接通信はできません。そのため、Direct Link Connect を作成して接続します。
次に IBM COS と PowerVS の接続ですが、パブリックネットワーク経由で IBM COS のパブリックエンドポイントへアクセス可能ですが、プライベートネットワーク経由から IBM COS のプライベートエンドポイントへは直接アクセスすることは出来ません(2023年2月現在)。
プライベートネットワークから接続する場合は IBM Cloud の x86環境を経由して IBM COS に接続する必要があります。
今回は IBM Cloud の x86環境に Proxyサーバを立て Proxyサーバ経由で接続する方法を試してみたいと思います。
なお、構築手順は Qiita の BLOG「Power Virtual ServerからICOSにファイルをアップロードする」を参考にさせて頂きました。
2)IBM Power Virtual Serverの作成
・PowerVSの作成はこちらのBLOG「IBM Power Virtual Server でAIX環境を作ってみた」でご紹介しましたが、プロビジョニング画面がアップデートされました。
IBM Cloud にログインし、カタログから「Workspace for Power Virtual Server」をクリックします。
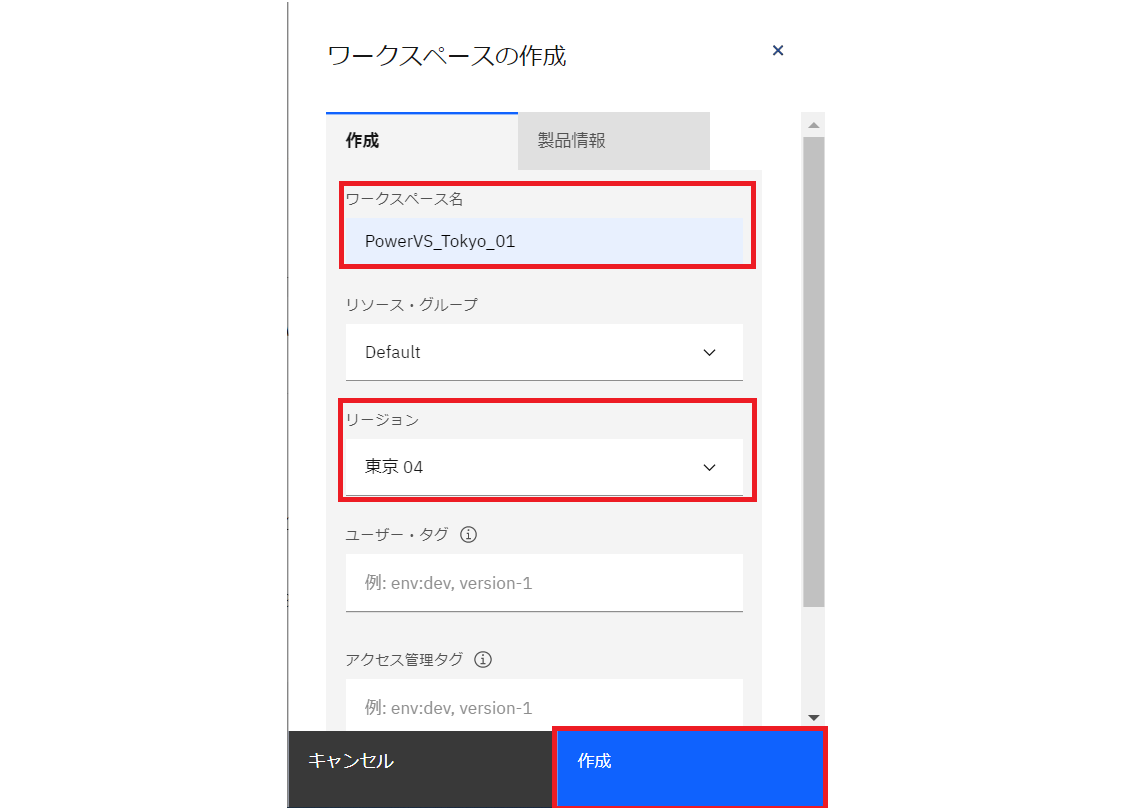
・ワークスペースを作成します。
ワークスペースは、PowerVSのデプロイする場所をゾーン毎に作成できる無償の作業環境です。任意のワークスペース名を入力し、リージョンは “東京04” を選択して作成します。
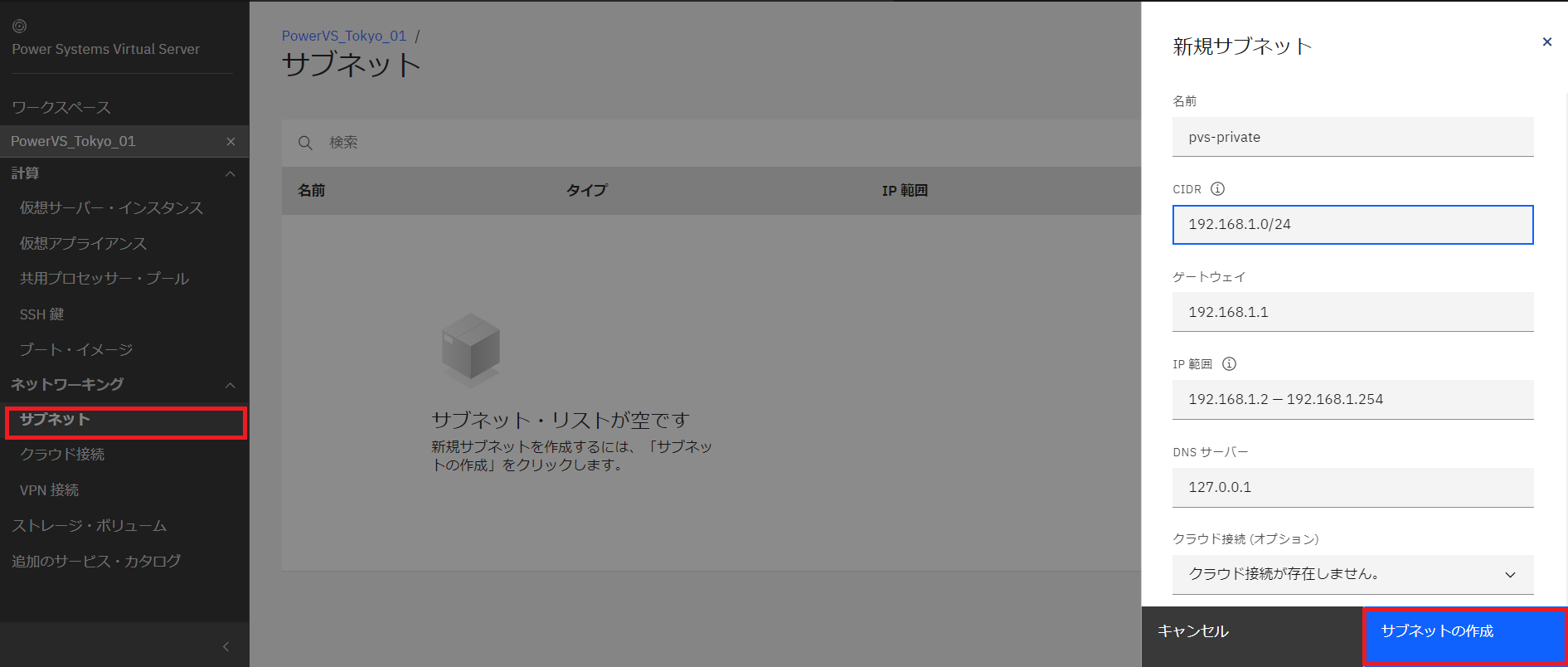
・PowerVS を作成した後にプライベートネットワークを作成するとうまくネットワークが認識されなかったので、先にプライベートネットワークを作成します。
左側メニューから「サブネット」をクリックします。プライベートネットワーク用に192.168.1.0/24のサブネットを作成します。
・次に「仮想サーバ・インスタンス」を選択しインスタンスを作成します。
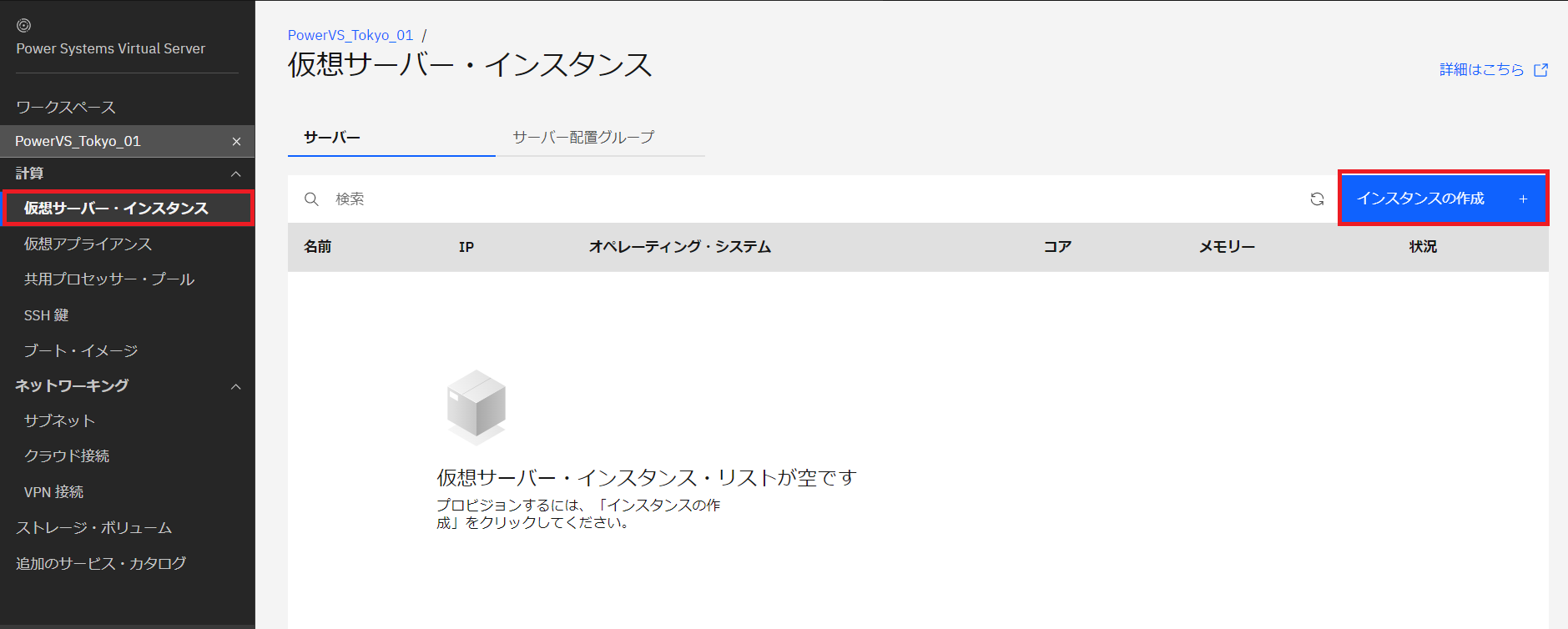
・今回は以下の構成でインスタンスを作成します。
- インスタンス名:任意の名前
- CPU:0.25
- CPUタイプ:上限なし共有プロセッサー
- メモリ:4GB
- ストレージボリューム:Tier3(SSD)30GB
- OS:AIX7.3 TL1
- プライベートネットワーク:192.168.1.0/24
右側の月額費用を確認し「作成」をクリックします。
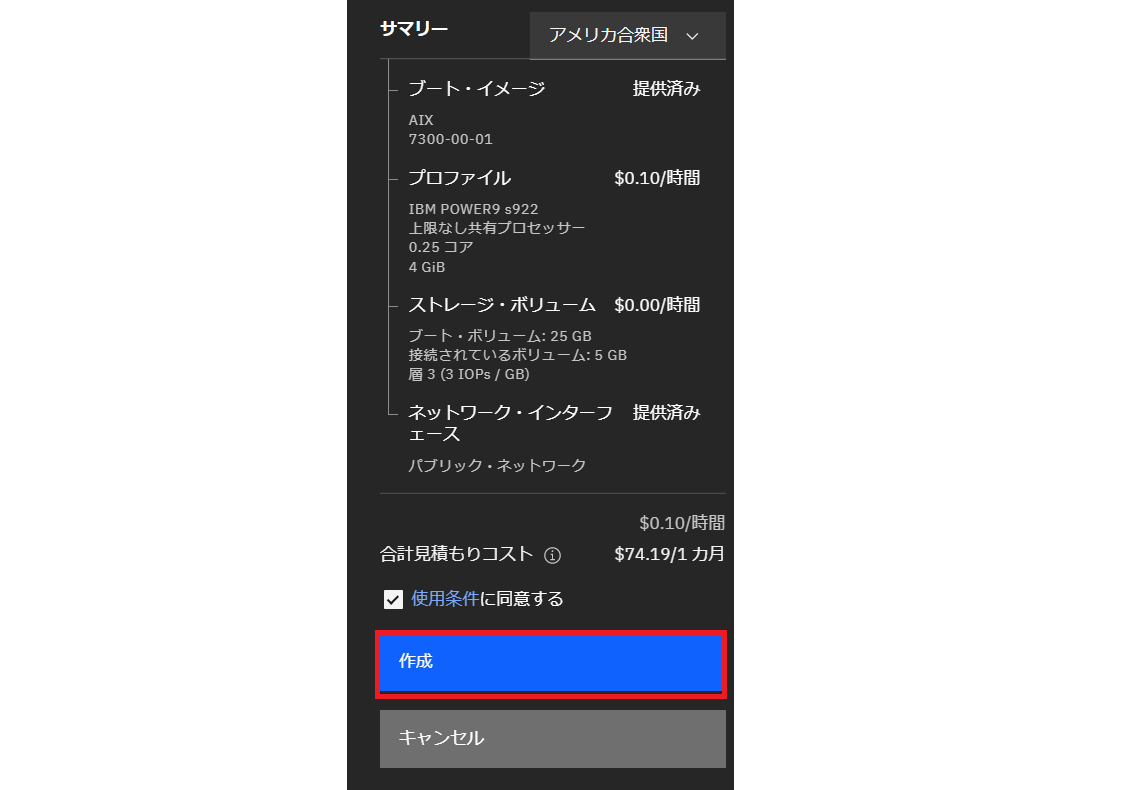
・仮想サーバインスタンスの画面に戻り、しばらくするとプロビジョニングが完了しました。
ここまでは特に問題無く進みほっとします。
3)VSI for VPCの作成
・次にProxy Serverを作成します。今回はVSI for VPCにProxy Serverをたてます。
「ナビゲーションメニュー」から「VPCインフラストラクチャー」を選択します。
左のメニューから「VPC」を選択し、「作成」をクリックします。
VPC は以下のパラメータで作成しました。
- 地域:アジア太平洋
- リージョン:東京
- 名前:任意の名前
- リソースグループ:Default
- ssh許可
- ping許可
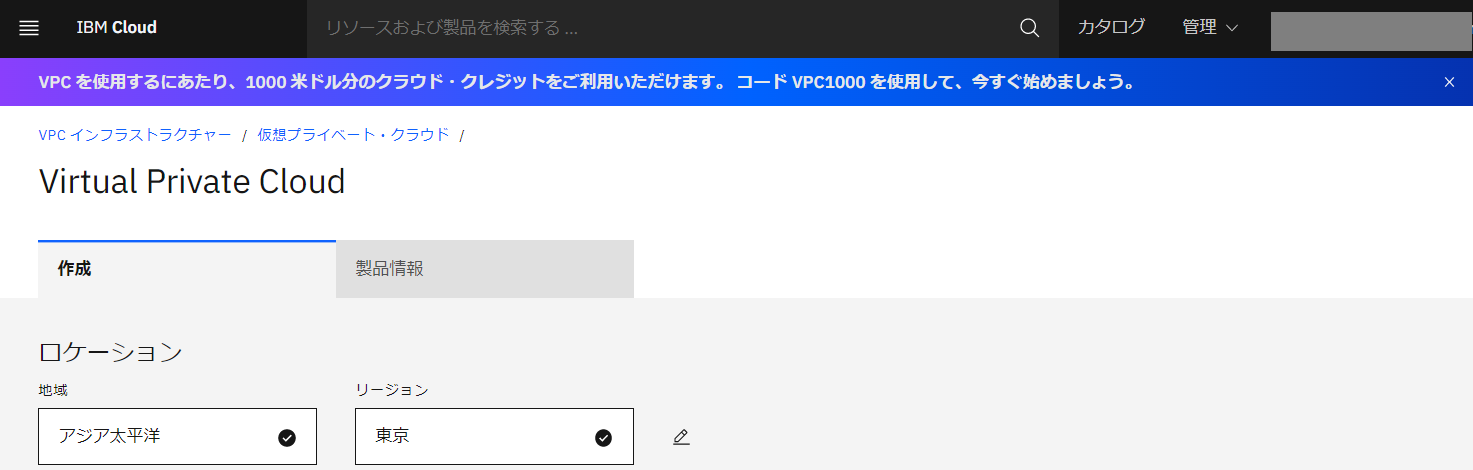
・サブネットの追加をクリックしてサブネットを追加します。
以下のパラメータで作成しました。
- 名前:sn-20230214-01(デフォルト値)
- ゾーン:東京1(東京1-3を選択可)
- リソースグループ:Default
- アドレス接頭部:10.244.0.0/18
- アドレスの数:256
- IP範囲:10.244.0.0/24
- パブリックゲートウェイ:接続無し
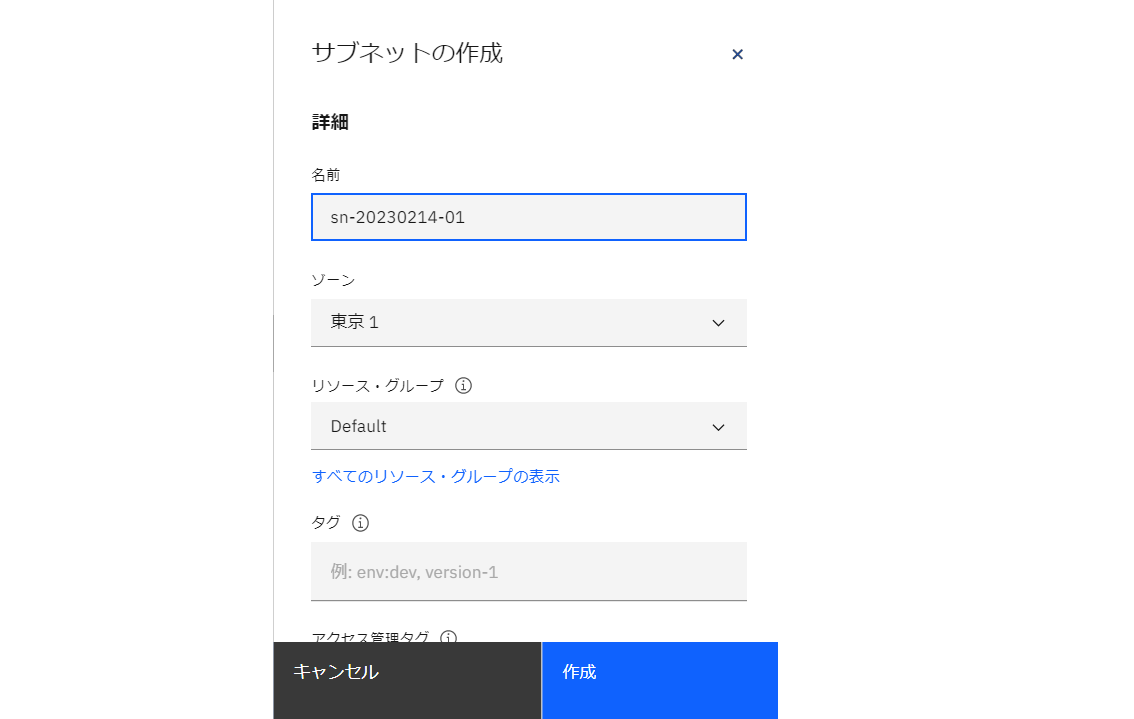
・最後に「仮想プライベート・クラウドの作成」をクリックします。
VPCのプロビジョニングが完了しました。
・次に作成した VPC に VSI を作成します。
左側のメニューから「仮想サーバ・インスタンス」を選択し「作成」をクリックします。
VSI は以下のパラメーターで作成しました。
- インスタンス名:任意の名前
- アーキテクチャー:Intel x86アーキテクチャー
- ホスティングタイプ:パブリック(マルチテナント)
- 地域:アジア太平洋
- リージョン:東京
- ゾーン:東京2
- 名前:proxy-test(任意の名前)
- リソースグループ:Default
- オペレーティングシステム:RedHatEnterprise Linux
- バージョン:ibm-redhat-9-0-minimal-amd64-1
- プロファイル:2vCPU, メモリ4GB
- 配置グループ:デフォルト値
- ブート・ボリューム:デフォルト値
- データ・ボリューム:デフォルト値
- ネットワーキング:tok-vpc-01(先ほど作成したVPCを選択)
- アドレス接頭部:10.244.64.0/18
- IP範囲:10.244.64.0/24
・パラメーターを入力したら右側画面の金額を確認し「仮想サーバの作成」をクリックします。
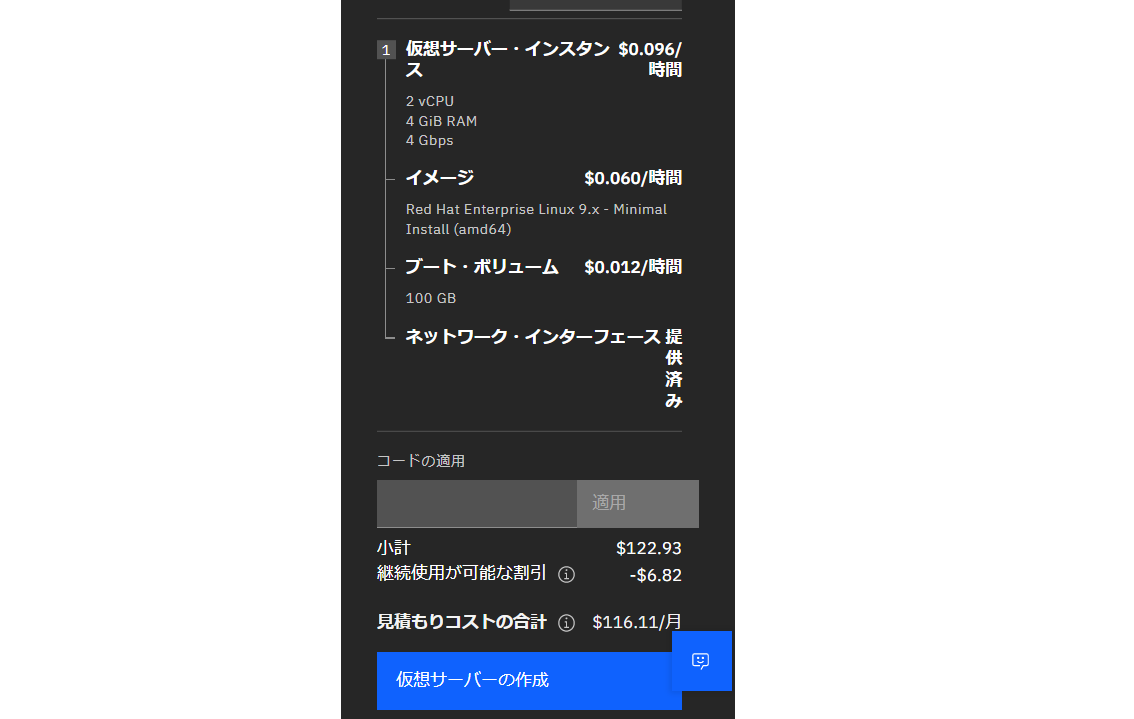
プロビジョニングが完了しました。PowerVS よりもプロビジョニングは速かったです。

・作成したVSI(RHEL)に Tera term を使用し SSH でログインします。
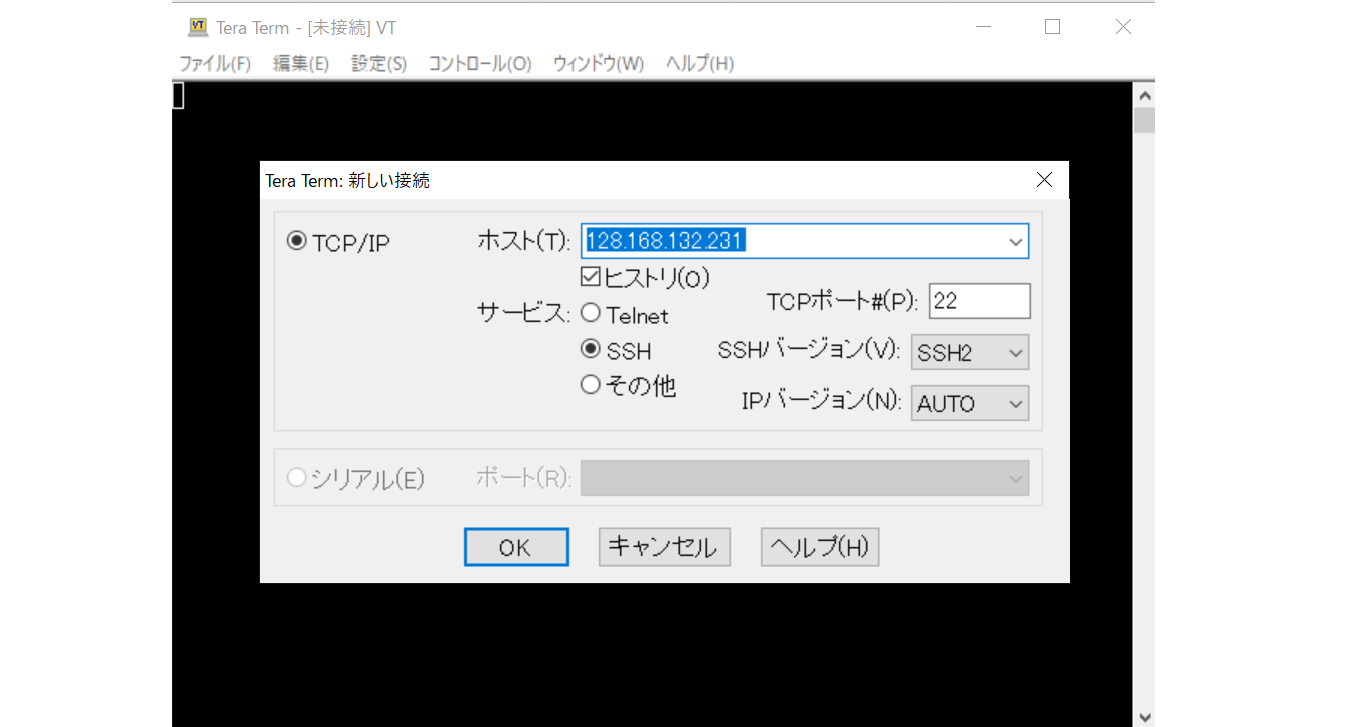
ログインしようと試みましたが、rootユーザのデフォルトパスワードでログインが出来ません。
調べたところレスキューモードで初期パスワードの再設定が必要であることがわかりました!
今更ですが、私は現場から離れかれこれ10数年、Linux のレスキューモードは初めてです。いきなりハードルが高くなりました…
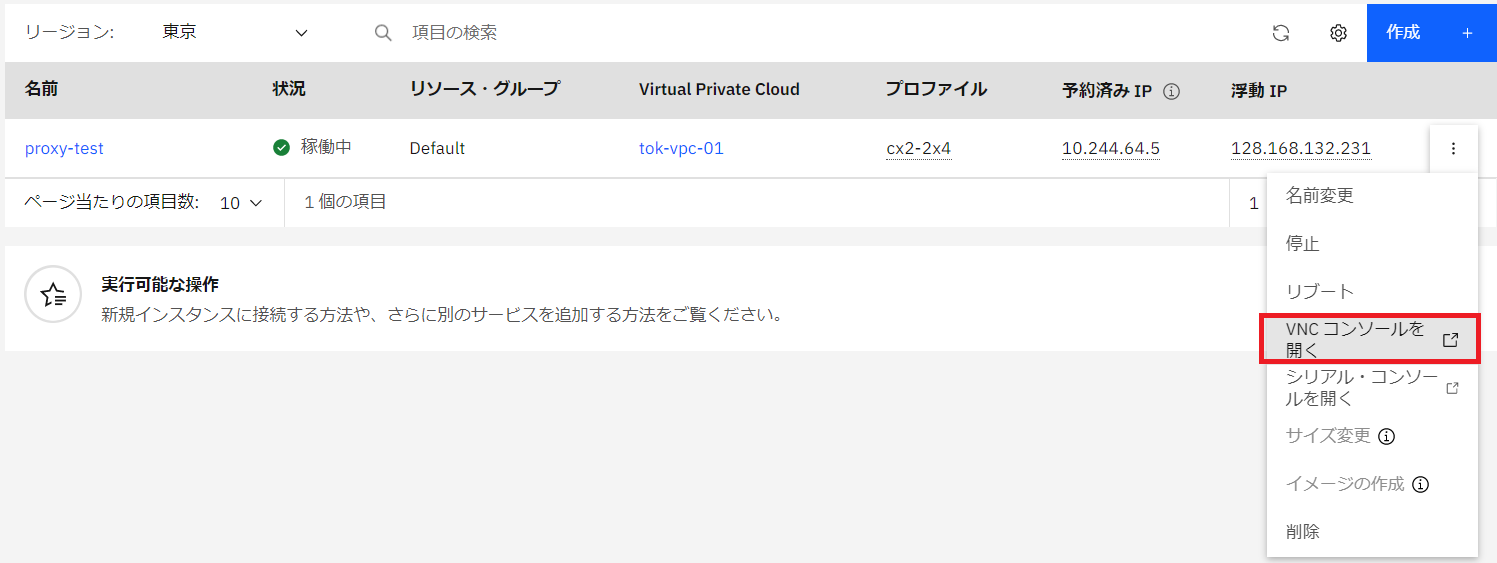
そしていざレスキューモード!と思い、VNCコンソール画面を開こうと思ったら…今度は VNCコンソールがグレーアウトされ開けません。
今回検証で使用するユーザは所有者ユーザではないため、こちら(IBMサイト)の説明にある通りVNC/シリアルコンソールの使用には権限の付与が必要であることがわかりました。更に回り道です。お付き合いください😢
・IBM Cloudサービスへのアクセス権限はアクセス管理システム “IBM Cloud Identity and Access Management(以下 IAM)” で設定することができます。
IBM Cloud画面の「管理」⇒「アクセス(IAM)」⇒「ユーザー」をクリックします。
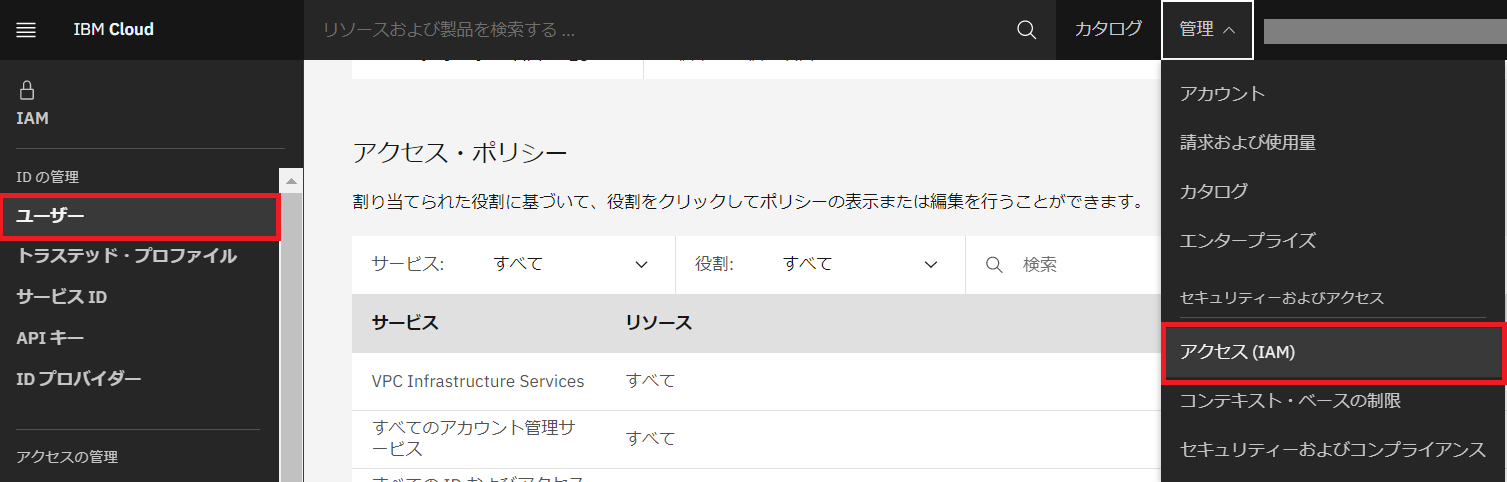
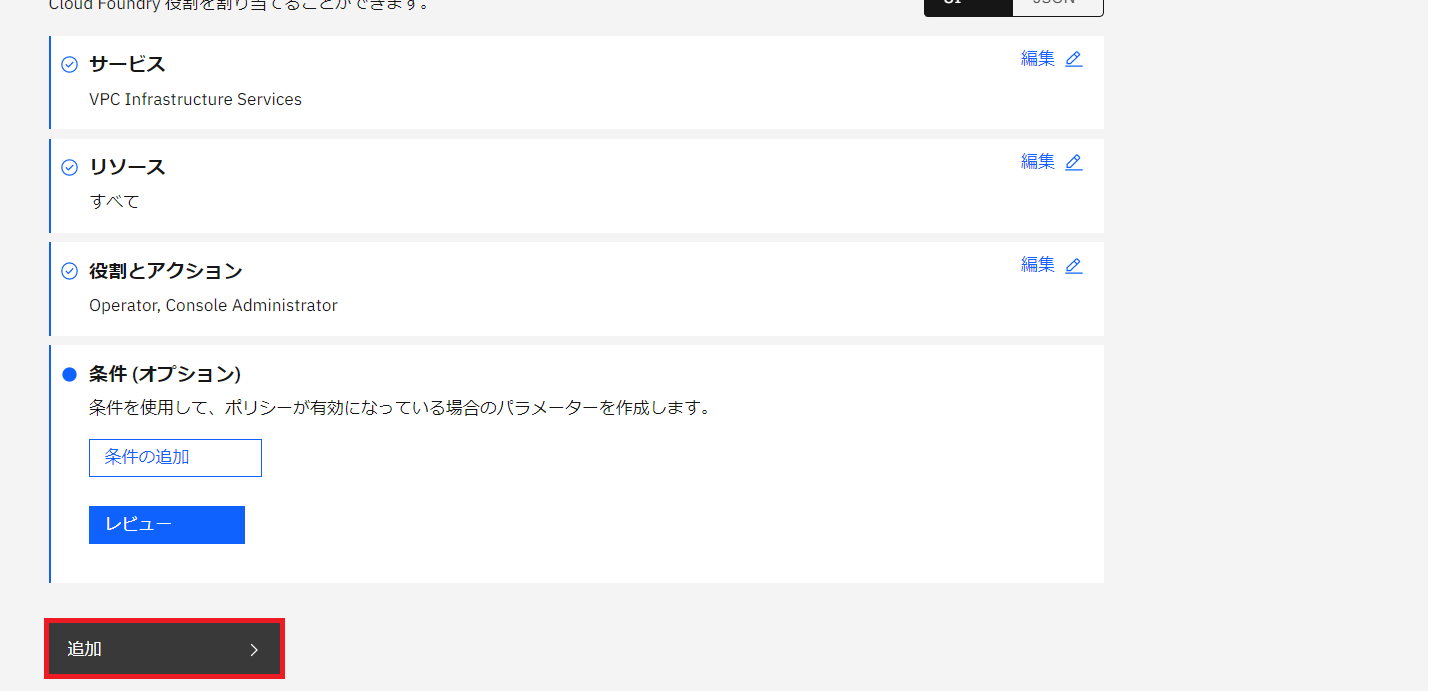
・「アクセス権限の割り当て+」をクリックします。

・「ポリシーの作成」でサービスから「VPC Infrastructure Services」を選択します。
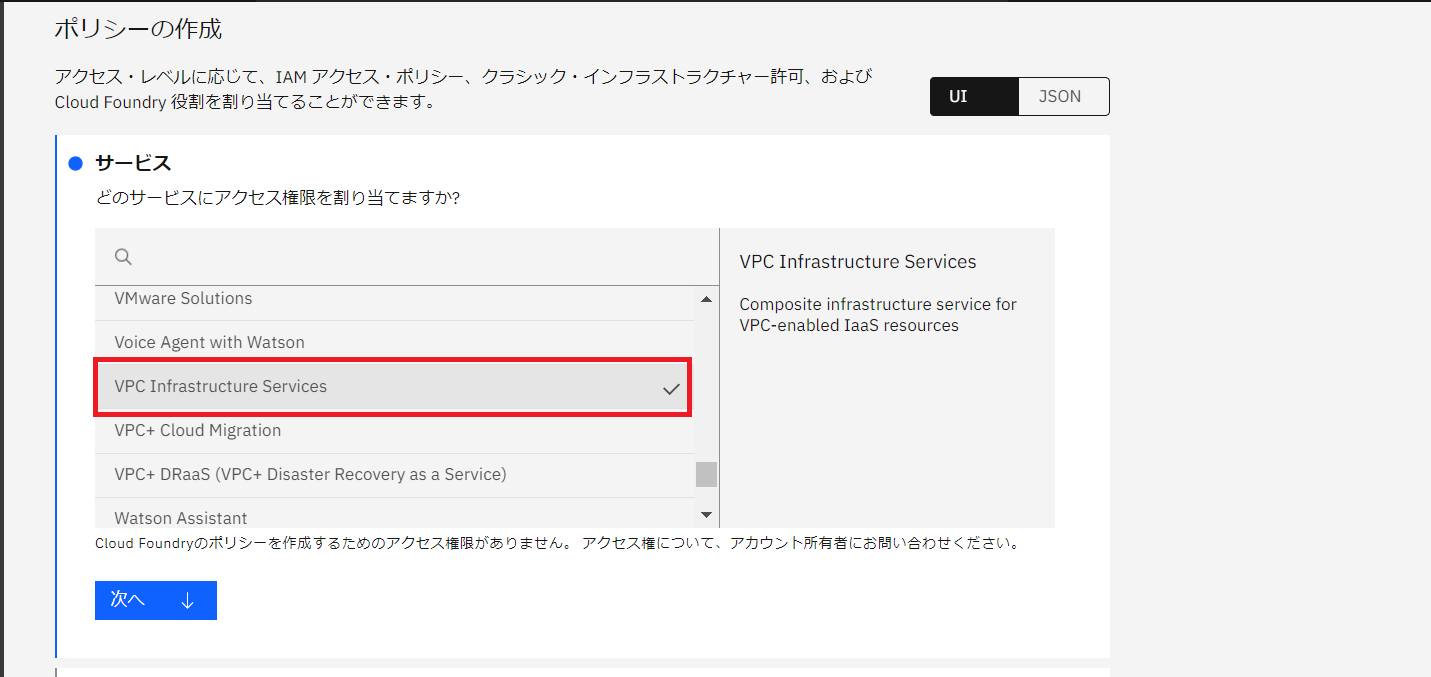
・「リソース」は「すべて」、「役割とアクション」はサービス・アクセスで「Console Administrator」、「プラットフォーム・アクセス」は「Operator」以上を選択し、最後に追加をクリックして完了です。
・VNCコンソールが開けるようになりました!
・やっとレスキューモードの準備が整いました。
レスキューモードは RHEL の Customer Portal「23.3. 起動時のrootパスワードのリセット」の手順を参考に行いました。ここでは手順は記載しませんが、Customer Portal の手順で問題なくパスワード設定ができます。システム再起動からすばやく [e]キーを押して起動プロセスを中断しなければいけないので目を凝らして行いました!
(ご参考に下の画面は起動プロセス中断直後の画面です。)

・VNCコンソールから rootログインをしてみたところ、無事ログインできました!
今回の検証では検証用のユーザを作成してsuして作業したいと思います。

・Teraterm から検証用ユーザで SSHログインし、root にスイッチします。
無事ログインできました。

4)Direct Link Connectの作成
前述した通り、PowerVS と VPC を接続するため Direct Link Connect を作成します。
・作成した PowerVS のワークスペース(PowerVS_Tokyo_01)に入り、左側メニューの「クラウド接続」をクリック、「作成」をクリックします。
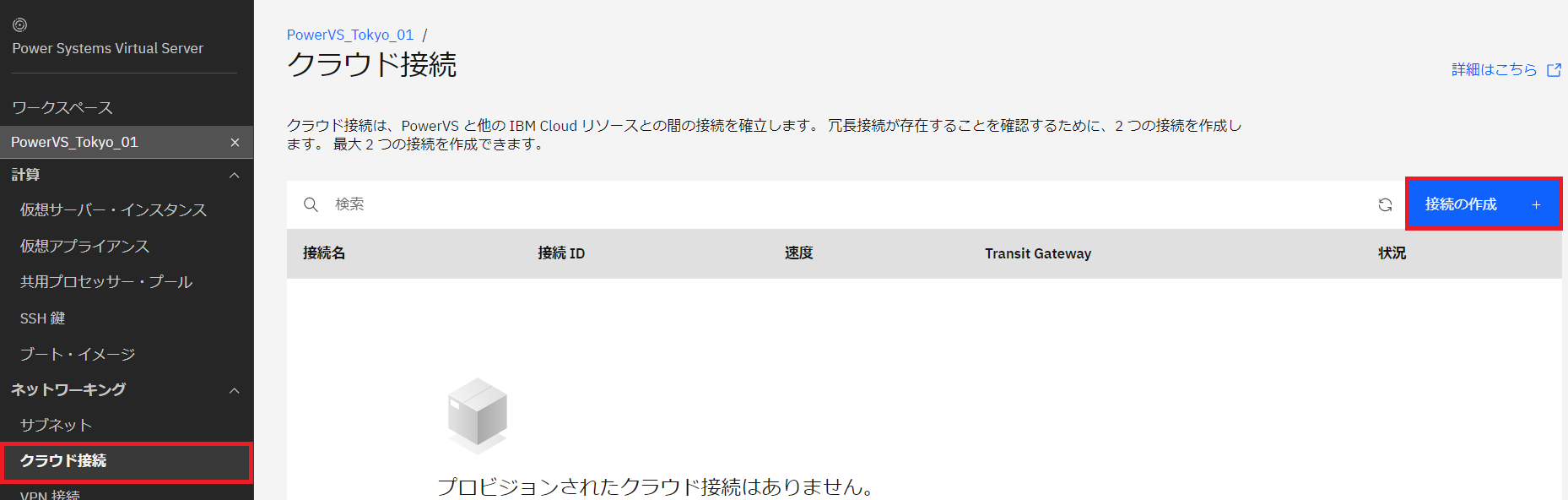
以下のパラメーターで作成しました。
- 名前:任意の名前
- 速度:1Gbps(50Mbpsから選択可)
- グローバルルーティング:選択無し
- Enable IBM Cloud Transit Gateway:選択無し(Transit Gatewayを使用する場合はチェックします)
- 宛先の構成:VPC
- VPC名:tok-vpc-01(作成済みのVPC)
- サブネット:PowerVSで作成したプライベートサブネット
・作成をクリックします。
しばらくすると Direct Link Connect の状況が “確立済み” になりました。以前は Case起票をしてプロビジョニングを行う必要がありましたが、ユーザーの操作からできるようになり使いやすくなりましたね。

5)AIXで静的ルーティングの設定
・PowerVS から VPC への静的ルートを設定します。
AIX なので smit を使用します。
![]()
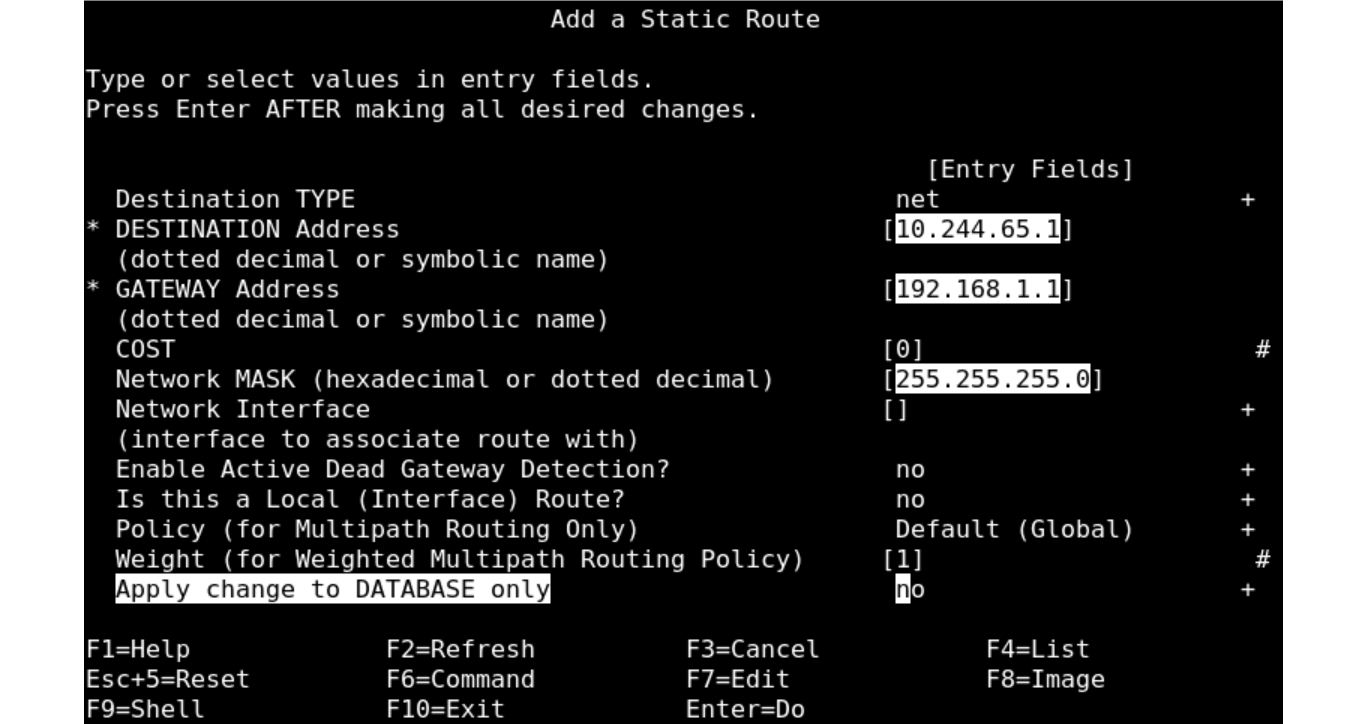
・netstatコマンドで静的ルーティングが設定されたことを確認します。
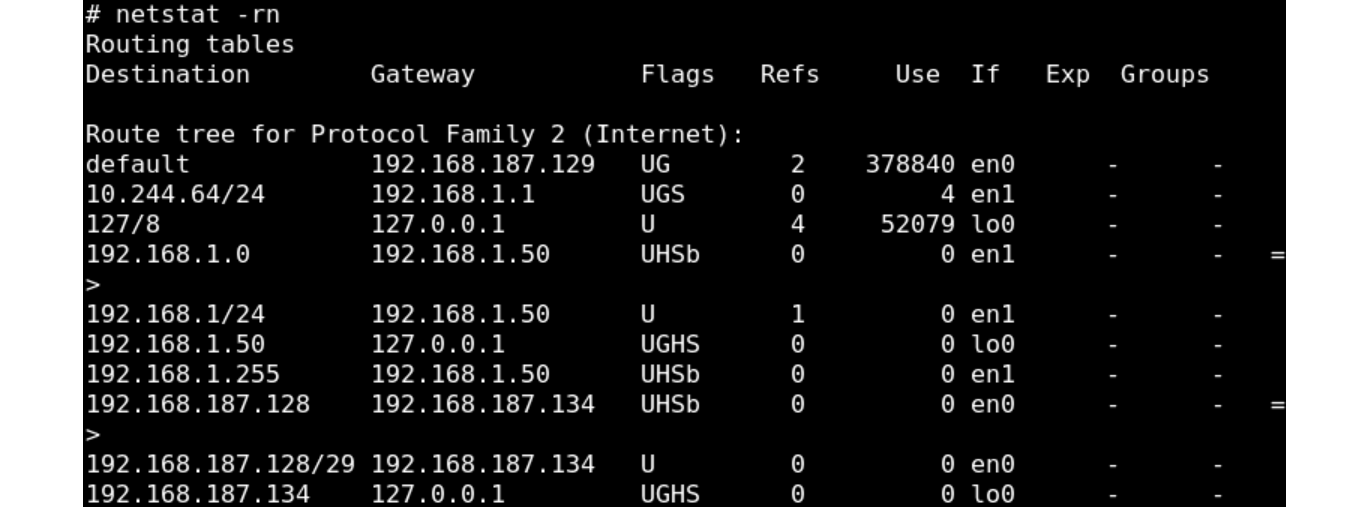
・pingコマンドで疎通を確認します。

これで PowerVS から VSI に接続ができるようになりました。
PowerVS、VSI のプロビジョニングはスムーズでしたが慣れない RHEL の操作と IAM の仕組みの理解に時間がかかりました。IAM の仕組みについては今後整理してご紹介したいと思います。
6)IBM COSの設定
・IBM COS にバケットを作成します。
今回は以前作成した Liteプランのストレージインスタンスにバケットを追加します。
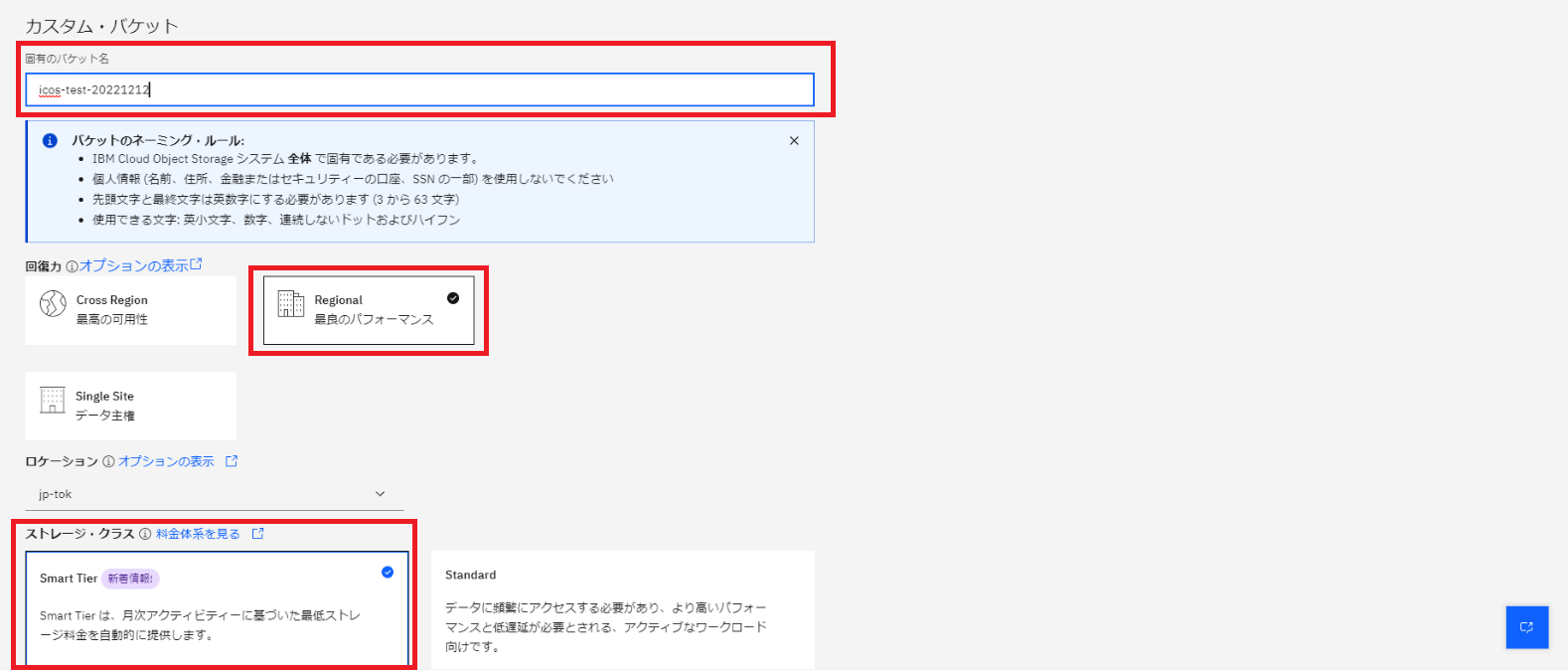
以下のパラメータで作成しました。
- バケット名:任意の名前
- 回復力:Regional
- ストレージクラス:Smart Tier
・バケットが作成されました。
こちらのバケットにファイルを転送します。(バケット自体に課金は発生しません)

これでサービスのプロビジョニングができました。
あらかじめ準備していた手順通りには進みませんでした…が全体の半分まで完了です!!
さいごに
IBM Cloud も初めて、慣れない Linux の構築、VNCコンソールが開けないトラブルなど…多々問題にあたり苦戦しましたがなんとか全体の半分まで完了しました。
10数年ぶりの構築作業でしたがデリバリSEの感覚が残っていてよかったです。
次回は AIX の設定、RHEL の Proxy の設定、ファイル転送試験です。
実際作業してみてわかった点をご紹介予定ですので是非ご覧ください。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp