
こんにちは。
てくさぽBLOGメンバーの宮里です。
今回はAzure Stack HCIの検証をしてみたので3回シリーズで検証で得られた知見をお伝えします。
検証の目的は、Azure Stack HCIの構築・管理・クラウドとの連携をどのような手順でおこなうのか、使いやすいのか、を実機を使って体感してみることです。
今回は3回シリーズの1回目で、Windows Server 2019の2台をAzure Stack HCIとして構築した手順をご紹介します。
Azure Stack HCIを導入してみた Vol.1 -Azure Stack HCI構築編- *本編
Azure Stack HCIを導入してみた Vol.2 -管理機能編-
Azure Stack HCIを導入してみた Vol.3 -Azureと連携編-
Index
はじめに
まず、Azure Stack HCIについて簡単に説明します。現在のAzure Stack HCIは2種類あります。1つはクラウドのAzureがサブスクリプションで提供する専用OSを利用するタイプ、もう1つはWindows Serverで提供される機能を利用するタイプです。今回は後者で検証します。
Windows Server が持つ仮想化機能のHyper-VとSDS(Software defined Storage)機能のS2D(ストレージスペースダイレクト)で、外部ストレージを使用しない仮想基盤であるHCI(ハイパーコンバージドインフラ)を実現します。
私は実機を使った検証や構築は初めての経験になります。そのため、うまくできるのか不安な気持ちと楽しみの気持ちの半々で挑みました。
検証機につきましては、レノボ・エンタープライズ・ソリューションズ様から実機をお借りして行いました。
レノボ・エンタープライズ・ソリューションズ様、ありがとうございます!
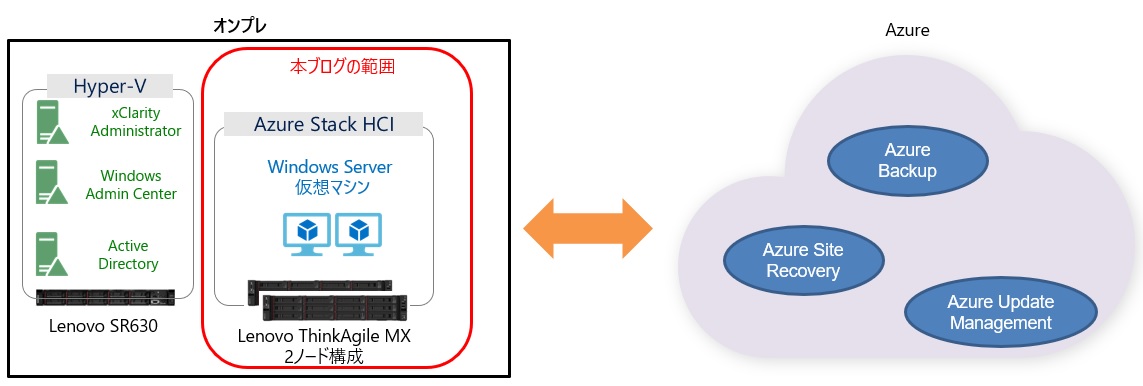
今回の検証環境の概要図はこちらになります。お借りしたAzure Stack HCIのハードウェアはLenovo ThinkAgile MXの2ノード(以下、MXサーバー)になります。もう1台、周辺サーバー用にSR630(以下、Hyper-Vサーバー)もあります。オンプレ側はこれら物理サーバー3台を使用して検証を行いました。
1. 事前準備
MXサーバーでの構築検証の前に以下を実施しておきます。物理サーバーへのWindows Server 2019インストールには、XClarity Controllerの仮想ファイル(ISOイメージ)のマッピング機能を利用したのでインストール用メディアを用意する必要はありませんでした。
- Hyper-VサーバーにWindows Server 2019 構築。周辺サーバーを仮想マシンで構築するためHyper-Vを有効にします。
- MXサーバーの2台にWindows Server 2019 構築。ADドメインにメンバーサーバーとして参加しておきます。
- 以下の2台の周辺サーバーをSR630のHyper-Vサーバー上に仮想マシンで構築します。
- 周辺サーバー1:Active Directory ドメインコントローラ(以下、ADサーバー)
- 周辺サーバー2:Windows Admin Centerサーバー(以下、WACサーバー)*Azure Stack HCIの管理をWACサーバーから行います。WACサーバー自体の構築手順は第2回のブログでお伝えします。
2. MXサーバー環境構築
2-1. 必要なコンポーネントの追加
WACサーバーにて、ドメインのadministratorアカウントでMXサーバーに接続します。
「役割と機能」にて”Hyper-V”、”データ重複排除”、”Data Center Bridging”、”フェールオーバークラスタリング”の4つの役割と機能を選択してインストールします(2台とも)。
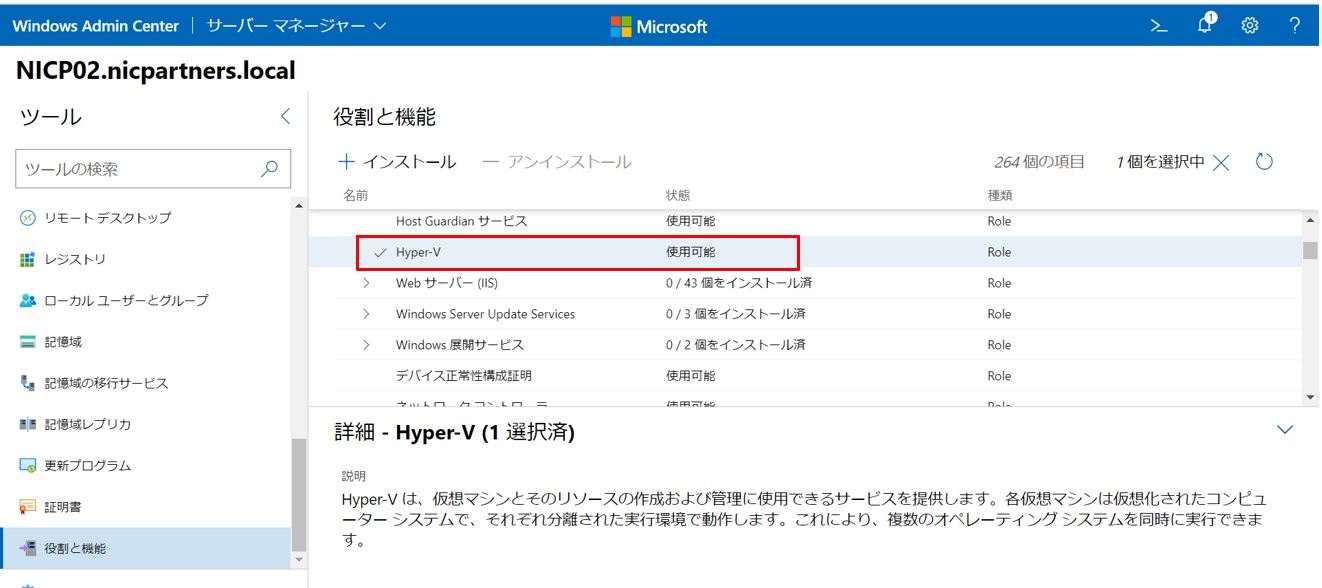
4つの役割と機能を選択すると関連する必要なコンポーネントもまとめてインストールされます。
2-2. ネットワークの設定
今回設定したAzure Stack HCIのネットワーク構成は以下になります。2台のノード間は直接接続し、外部ネットワーク用の物理スイッチとの接続は各ノードとも1ポートです。
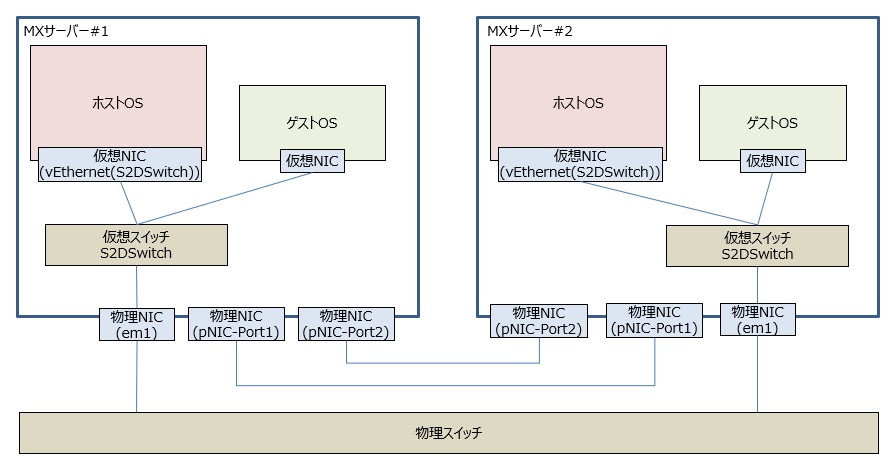
今回のネットワーク設定は「Microsoft Storage Spaces Direct (S2D) Deployment Guide」(以下、デプロイメントガイド)という資料を参考にしました。英語資料ですが接続構成毎に詳細に解説してありますので、ぜひMXサーバー構築の際には一読されることをおすすめします。今回はデプロイメントガイド43ページからの「RoCE: 2-3 nodes, direct-connected」という箇所を参考にしました。
MXサーバーにリモートデスクトップ接続して以下の設定作業を行います。2台ありますのでそれぞれで設定します。
以下はホストOSが認識しているネットワークアダプターです。この後、PowerShellで設定していくので、コマンドの入力をしやすくするために「Slot4 ポート1」「Slot4 ポート2」と言う名前になっているMellanoxアダプターの名前を変更します。
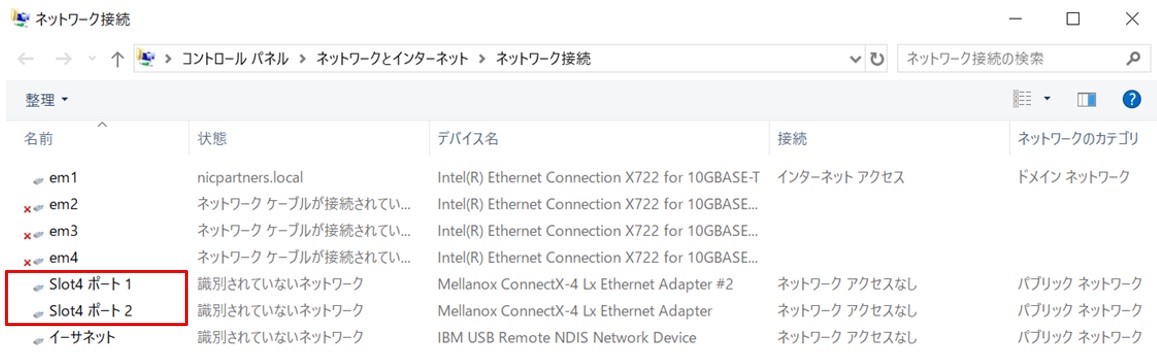
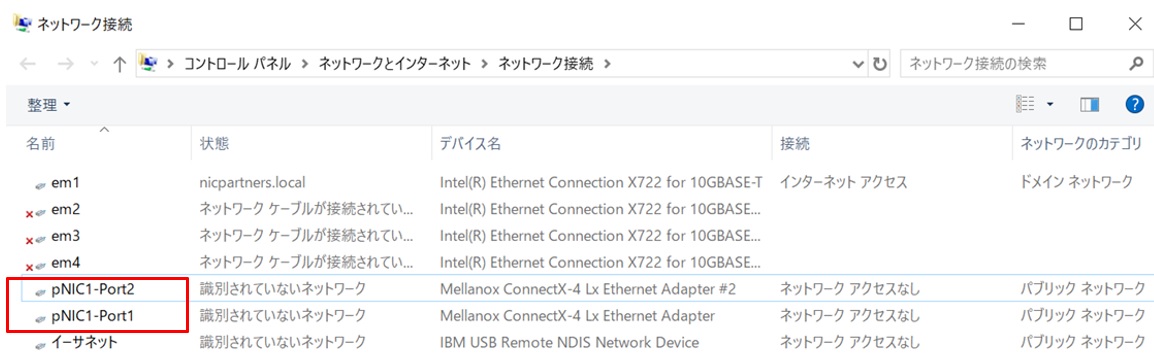
”pNIC1-Port1”、”pNIC1-Port2”とそれぞれ変更しました。
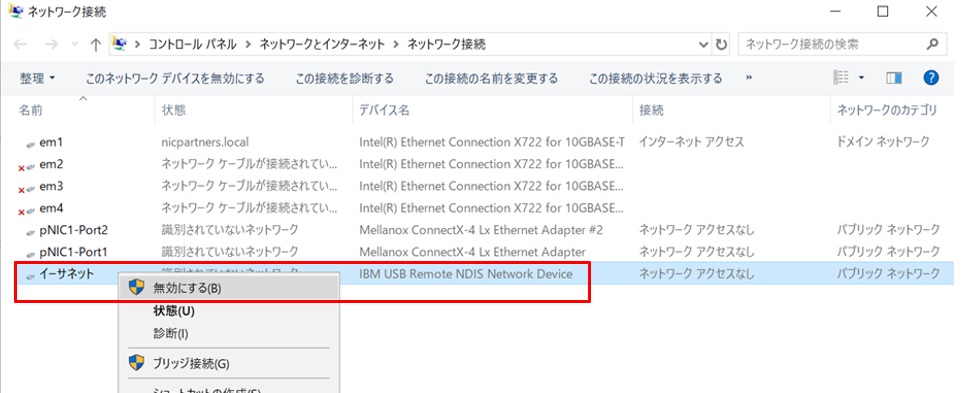
続いて”IBM USB Remote NDIS Network Device”を無効にします。これが有効のままだとこの後のフェールオーバークラスタの設定ウィザードでエラーになるためです。
ここからPowerShellで設定します。デプロイメントガイド49ページに沿って実行していきます。以下の設定を行いました。
- DCBXプロトコルのブロック(Set-NetQosDcbxSettingコマンド)Set-NetQosDcbxSetting
- 帯域制御(QoS)の設定(New-NetQosPolicyコマンド)
- SMB-Directのフローコントロールの有効化(Enable-NetQosFlowControlコマンド)
- その他通信のフローコントロールの無効化(Disable-NetQosFlowControlコマンド)
- 通信制御をノード間通信用に適用(Enable-NetAdapterQosコマンド)
- 最低帯域の設定 – SMB-Directは50%、Cluster-HBは1%(New-NetQosTrafficClassコマンド)
- Mellanoxアダプターのフロー制御を無効にする(Set-NetAdapterAdvancedPropertyコマンド)
| PS C:\Users\Administrator> Set-NetQosDcbxSetting -InterfaceAlias “pNIC1-Port1” -Willing $False
確認 この操作を実行しますか? Set-NetQosDcbxSetting -Willing $false -InterfaceAlias “pNIC1-Port1” [Y] はい(Y) [A] すべて続行(A) [N] いいえ(N) [L] すべて無視(L) [S] 中断(S) [?] ヘルプ (既定値は “Y”): y PS C:\Users\Administrator> Set-NetQosDcbxSetting -InterfaceAlias “pNIC1-Port2” -Willing $False 確認 この操作を実行しますか? Set-NetQosDcbxSetting -Willing $false -InterfaceAlias “pNIC1-Port2” [Y] はい(Y) [A] すべて続行(A) [N] いいえ(N) [L] すべて無視(L) [S] 中断(S) [?] ヘルプ (既定値は “Y”): y PS C:\Users\Administrator> New-NetQosPolicy -Name “SMB” -NetDirectPortMatchCondition 445 -PriorityValue8021Action 3 Name : SMB PS C:\Users\Administrator> New-NetQosPolicy -Name “Cluster-HB” -Cluster -PriorityValue8021Action 7 Name : Cluster-HB PS C:\Users\Administrator> New-NetQosPolicy -Name “Default” -Default -PriorityValue8021Action 0 Name : Default PS C:\Users\Administrator> Enable-NetQosFlowControl -Priority 3 PS C:\Users\Administrator> Disable-NetQosFlowControl -Priority 0,1,2,4,5,6,7 PS C:\Users\Administrator> Enable-NetAdapterQos -Name “pNIC1-Port1” PS C:\Users\Administrator> Enable-NetAdapterQos -Name “pNIC1-Port2” PS C:\Users\Administrator> New-NetQosTrafficClass “SMB” -Priority 3 -BandwidthPercentage 50 -Algorithm ETS Name Algorithm Bandwidth(%) Priority PolicySet IfIndex IfAlias —- ——— ———— ——– ——— ——- ——- PS C:\Users\Administrator> New-NetQosTrafficClass “Cluster-HB” -Priority 7 -BandwidthPercentage 1 -Algorithm ETS Name Algorithm Bandwidth(%) Priority PolicySet IfIndex IfAlias —- ——— ———— ——– ——— ——- ——- Cluster-HB ETS 1 7 Global PS C:\Users\Administrator> Set-NetAdapterAdvancedProperty -Name “pNIC1-Port1” -RegistryKeyword “*FlowControl” -RegistryValue 0 PS C:\Users\Administrator> Set-NetAdapterAdvancedProperty -Name “pNIC1-Port2” -RegistryKeyword “*FlowControl” -RegistryValue 0 PS C:\Users\Administrator> |
次にHyper-Vマネージャーで仮想スイッチを作成します。Hyper-Vマネージャーは[スタート] ボタン-[管理ツール] -[Hyper-V マネージャー] で実行します。
右ペインの[操作] メニューから”仮想スイッチマネージャー”を開き、”新しい仮想ネットワークスイッチ”を選択して、仮想スイッチの種類として”外部”を選択します。
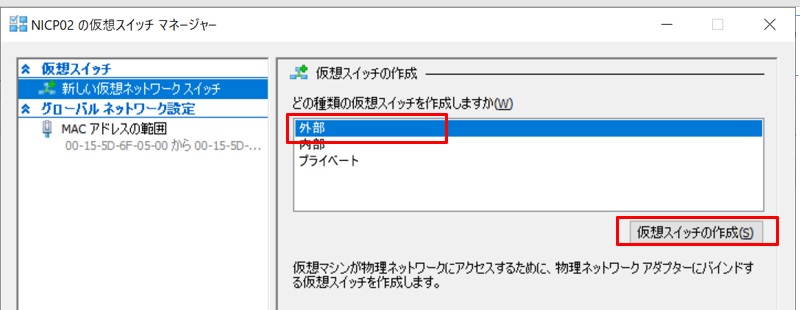
仮想スイッチを以下のように設定して作成します。
- 仮想スイッチの名前:S2DSwitch
- 仮想スイッチの種類:”外部ネットワーク”、物理スイッチに接続している物理NICを選択
- ”管理オペレーティングシステムにこのネットワークアダプターの共有を許可する”にチェック
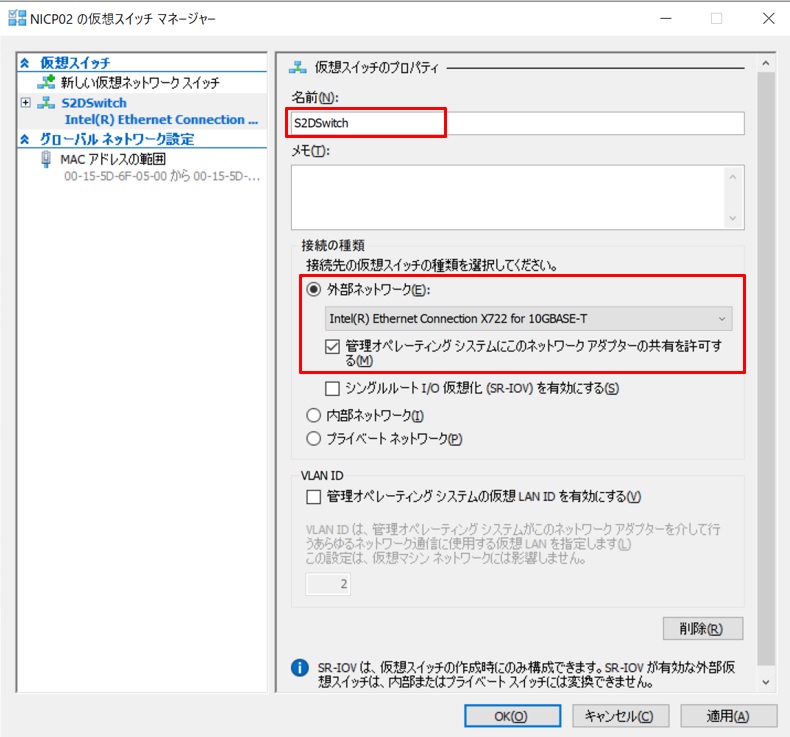
すると、”vEthernet(S2DSwitch)”という名前のHyper-v Virtual Ethernet Adapterが作成されました。これがホストOSが利用するネットワークアダプターになります。
次に再びPowerShellで設定を行います。デプロイメントガイド50ページに沿って実行していきます。以下の設定を行いました。
- MellanoxアダプターへのRDMA有効化(Enable-NetAdapterRDMAコマンド)
- Intelアダプター(em1)へのRDMA無効化(Disable-NetAdapterRDMAコマンド)
| PS C:\Users\Administrator> Enable-NetAdapterRDMA -Name “pNIC1-Port1”
PS C:\Users\Administrator> Enable-NetAdapterRDMA -Name “pNIC1-Port2” PS C:\Users\Administrator> Disable-NetAdapterRDMA -Name “em1” |
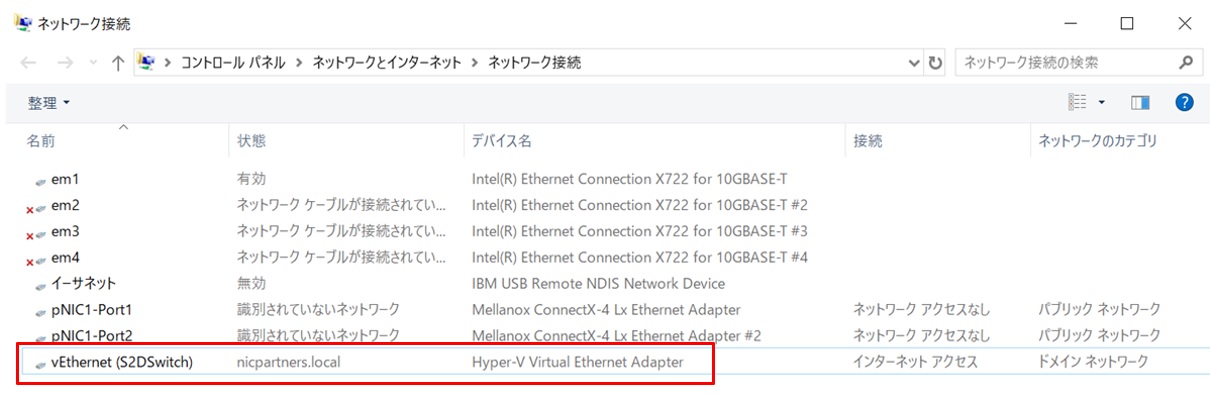
続いてこの”vEthernet(S2DSwitch)”にホストOS用の固定IPを設定します。
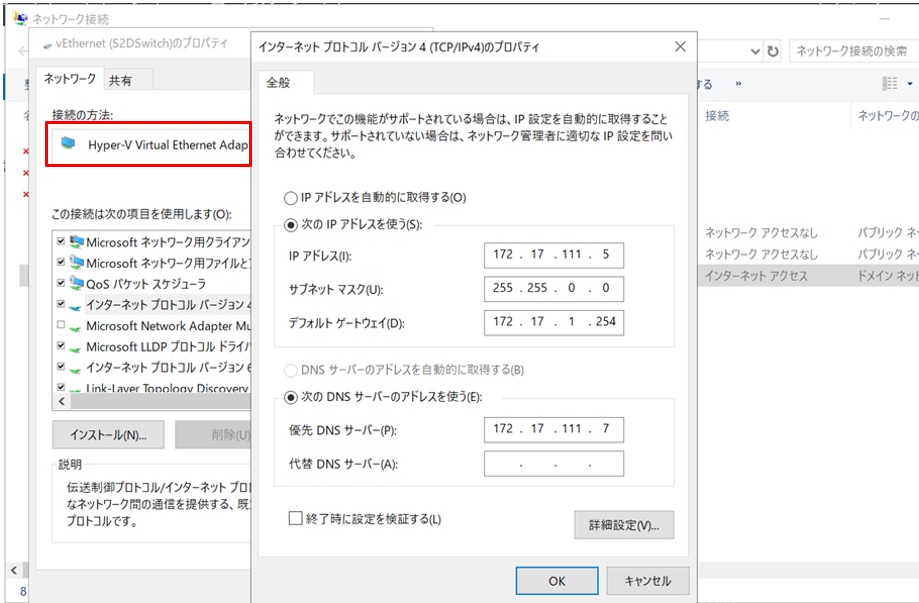
また、物理スイッチに接続した物理NIC(em1)のプロパティを表示し、”インターネットプロトコル バージョン4(TCP/IP V4)”のチェックボックスがオフでIPアドレスが設定できないことを確認します。
続いてノード間通信用に直接接続しているMellanoxの物理NICに固定IPを設定します。外部ネットワークと接続しないのでデフォルトゲートウェイは指定しません。
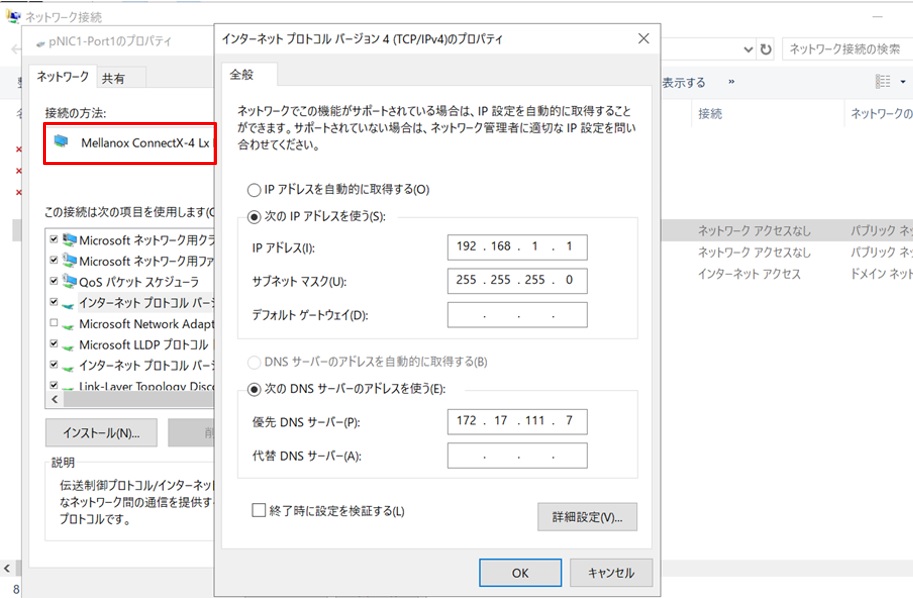
最後に、設定した固定IPにpingコマンドが正常に実行されればOKです。
以上で本章の最初に示したネットワーク構成になりました。
2-3. フェールオーバークラスタの構成
引き続きMXサーバーにリモートデスクトップ接続して設定を進めます。フェールオーバークラスターマネージャーは[スタート] ボタン-[管理ツール] -[フェールオーバークラスターマネージャー] で実行します。起動したら、右ペインの[操作] メニューから”構成の検証”をクリックします。
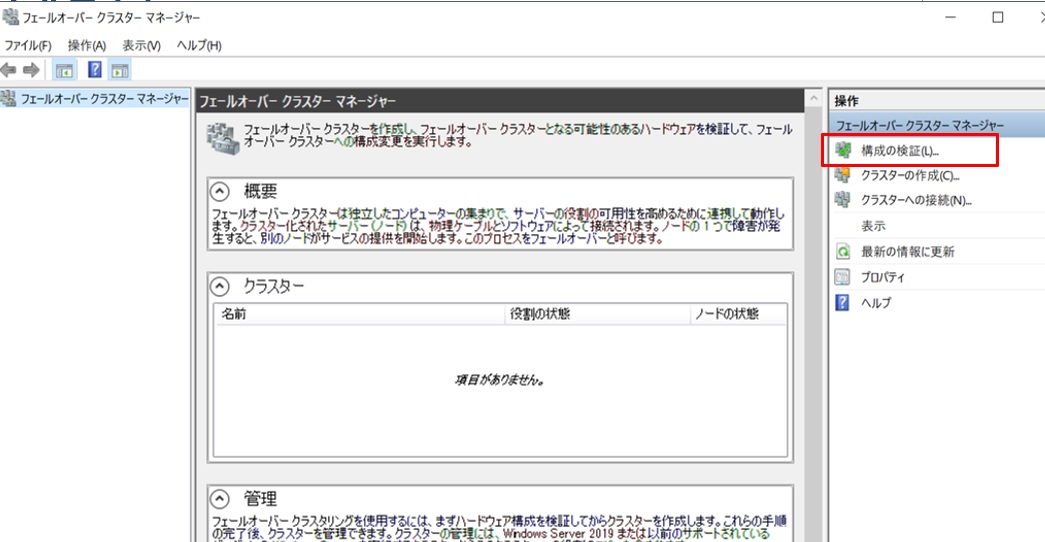
「構成の検証ウィザード」が起動します。MXサーバー2台が選択されていることを確認して「次へ」をクリックします。
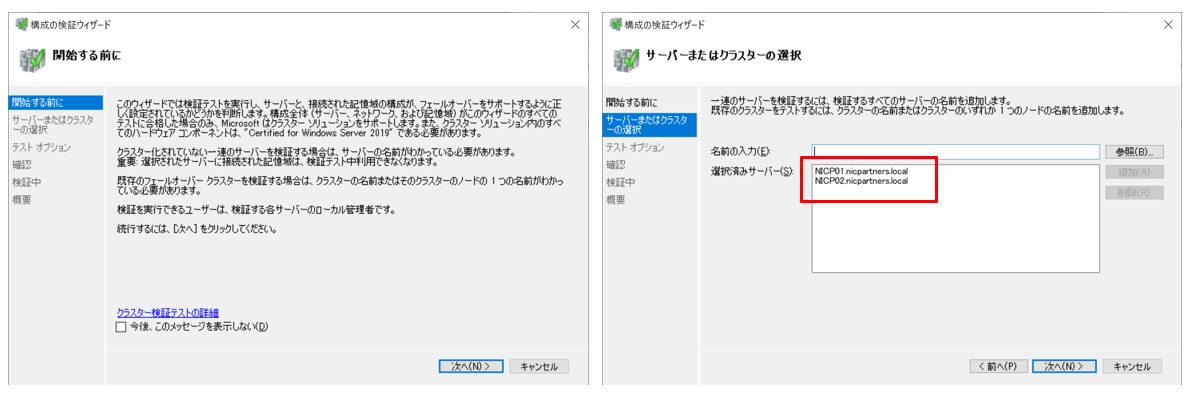
テストオプション画面で「すべてのテストを実行する」を選択し、次の確認画面を進みます。
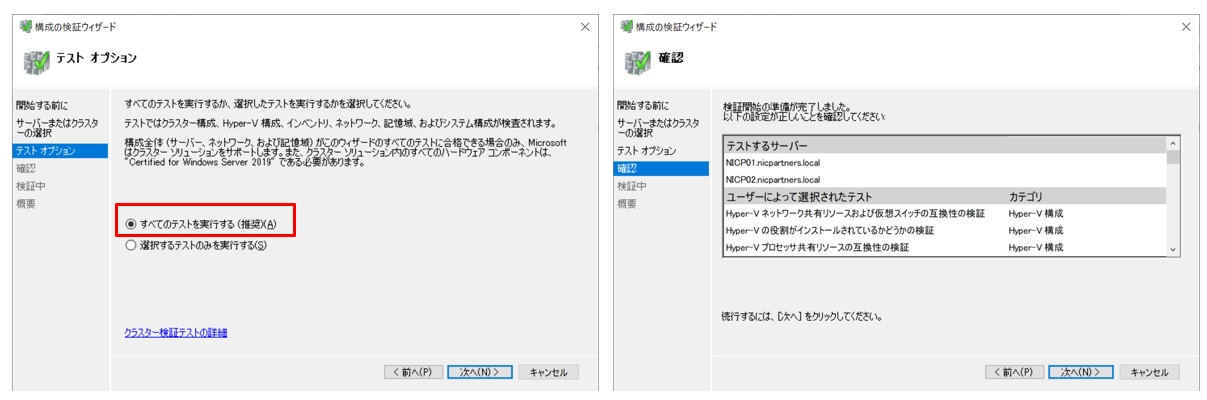
下図のように”検証済み”、”成功”と表示されればテストは完了です。「検証されたノードを使用してクラスターを今すぐ作成する」にチェックを入れて完了します。続けてクラスターの作成ウィザードが始まります。
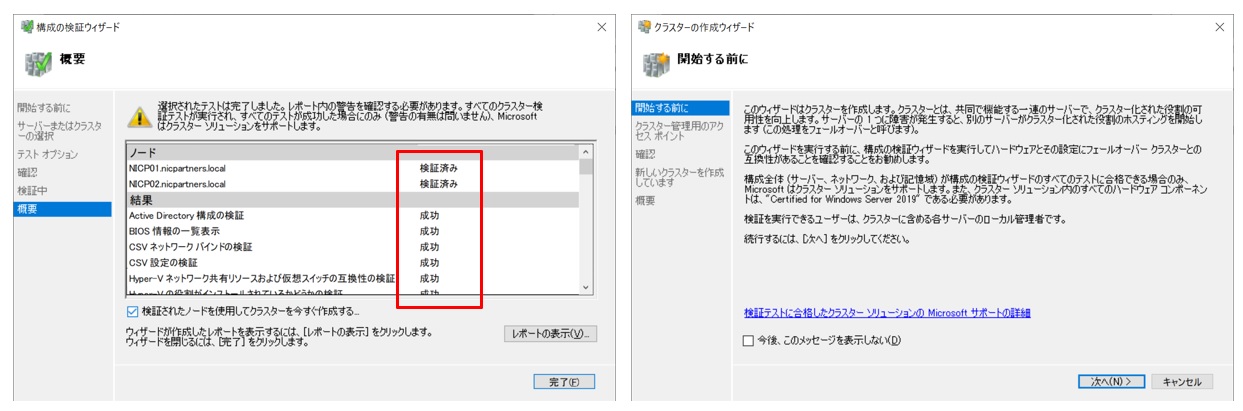
「クラスタ名」と「クラスタ用IPアドレス」を入力し、次の画面で確認します。
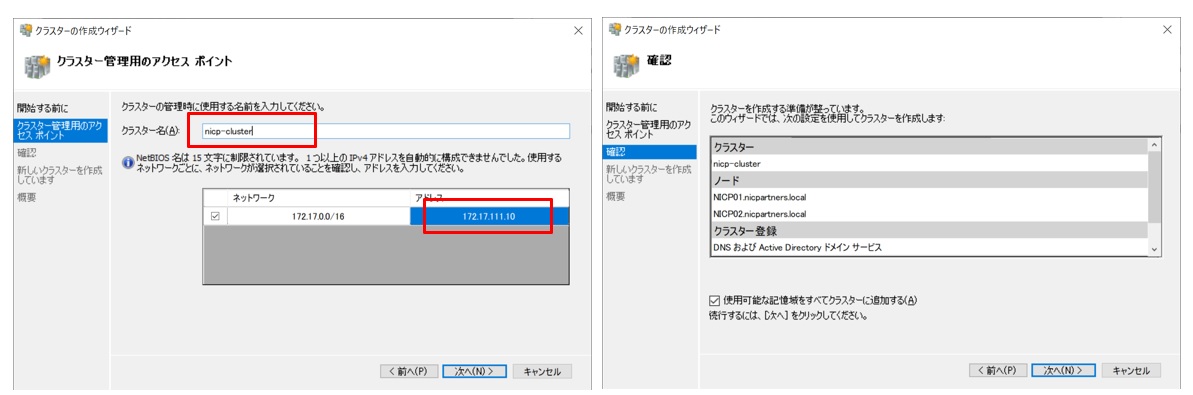
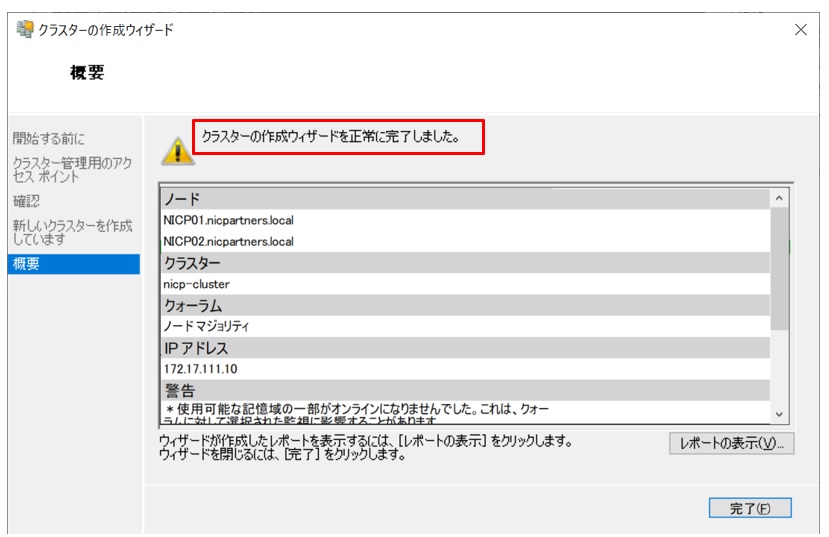
クラスタの作成ウィザードが正常に完了したことを確認します。
続いて、作成したクラスタ名を右クリックし、”クラスタークォーラム設定の構成”を選択します。
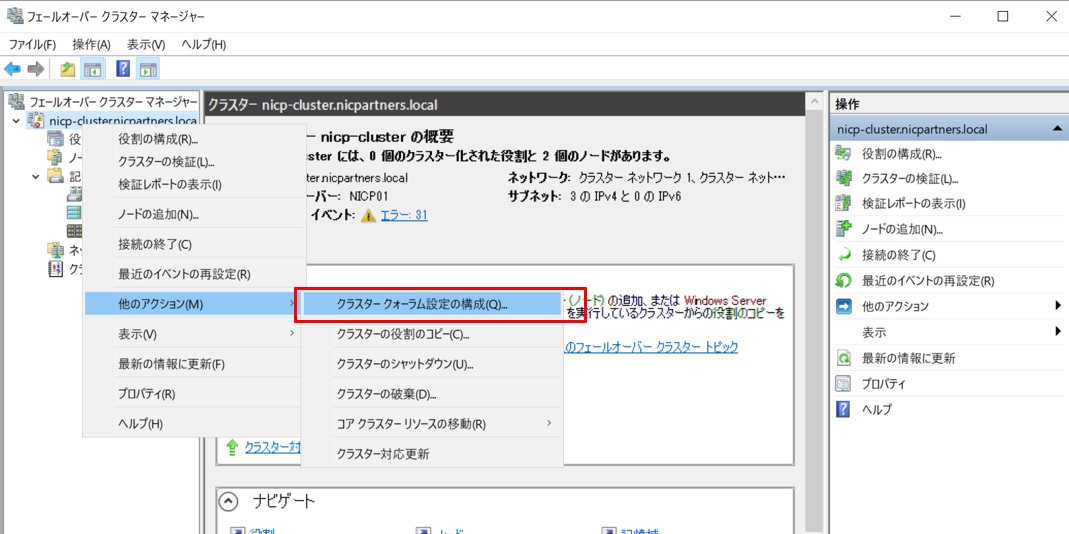
クラスタクォーラム構成ウィザードを実行します。構成オプション選択画面では”クォーラム監視を選択する”を選択します。
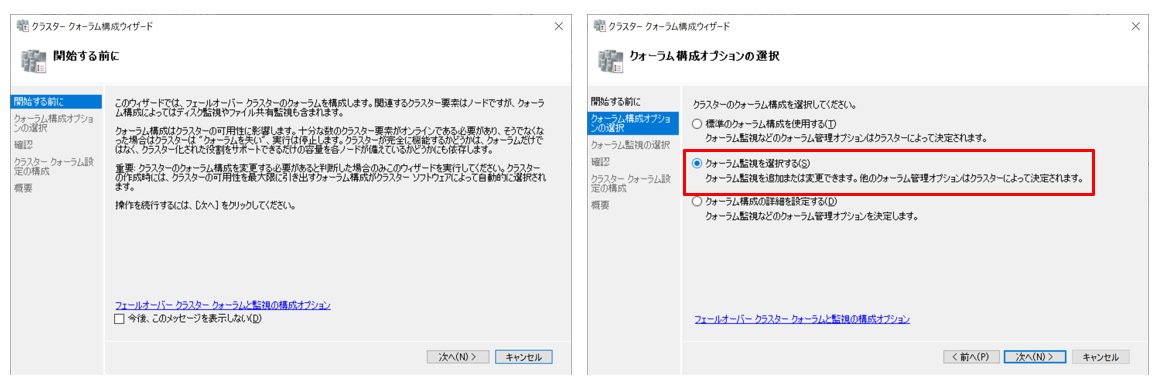
続いて監視の選択画面では”ファイル共有監視を構成する”を選択します。そして次の画面で利用する共有フォルダのぱすを入力します。今回は事前構築したADサーバー(サーバー名:AD01)上に作成した共有フォルダ(¥¥AD01¥quorum)を指定します。
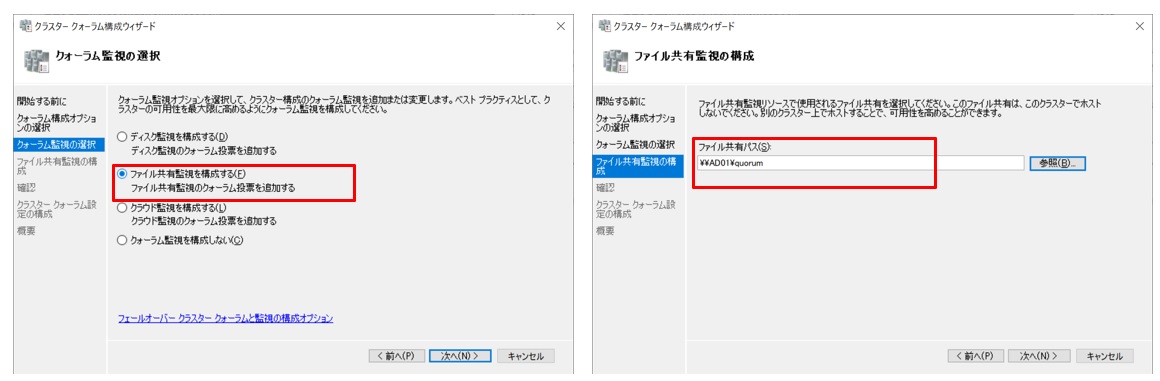
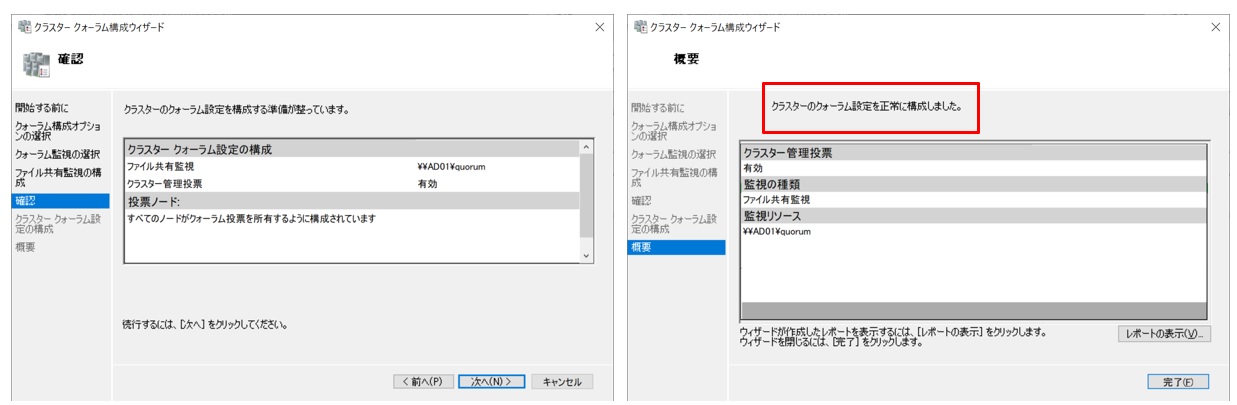
指定した項目を確認して設定を進めます。正常に構成されたことが確認できました。
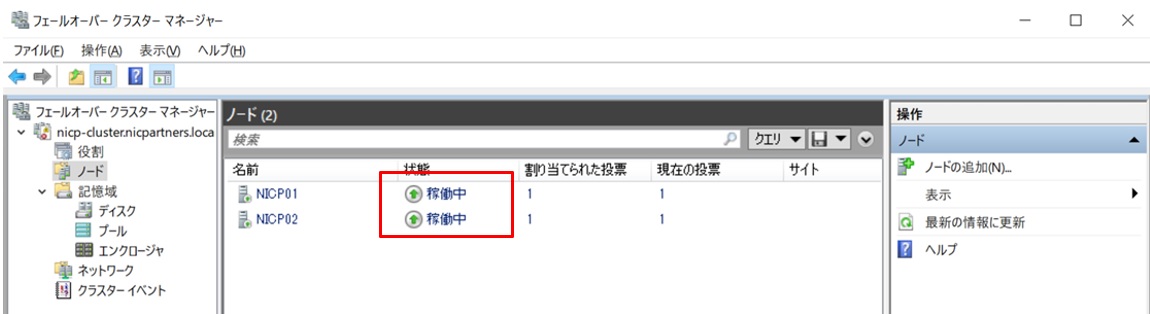
フェールオーバークラスタマネージャーにて、両方のノードが稼働中であることを確認したらここまでは完了です。
躓きポイント:
この”クラスタークォーラム設定の構成”の設定で1点躓いたのでご紹介します。
最初に実行した際にウィザードの最後で以下のようなエラーとなりました。
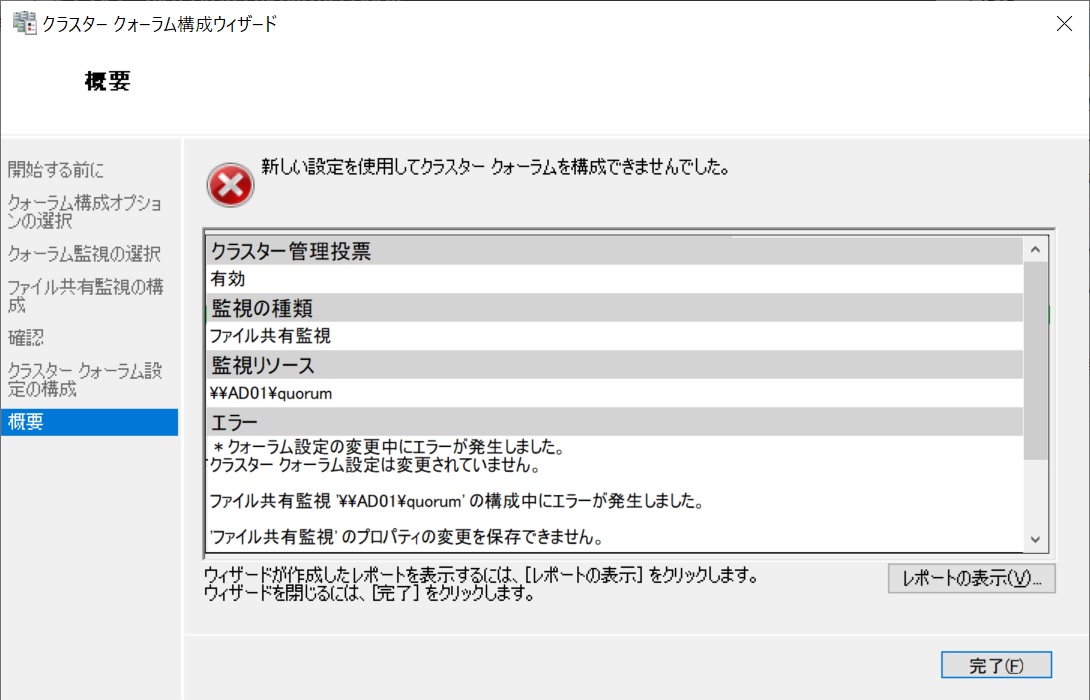
調べると共有フォルダのアクセス権が不足していました。作成した共有フォルダのプロパティ画面の「セキュリティ」タブで2台のコンピュータ名とクラスタ名の3つをコンピュータアカウントとしてアクセス権を”フルコントロール”にして追加します。
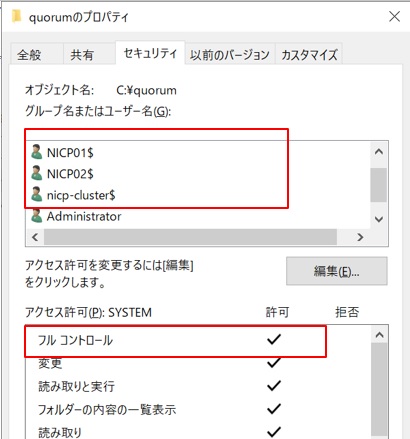
この後にクラスタクォーラム構成ウィザードを再度実行したら正常に構成されました。
2-4. ディスクの構成(S2Dの有効化)
リモートデスクトップ接続したまま、引き続きS2D(記憶域スペースダイレクト)を有効にしてディスクの構成を行います。まず「ディスクの管理」ツールで各ディスクが以下のように”未割り当て”となっていることを確認します。
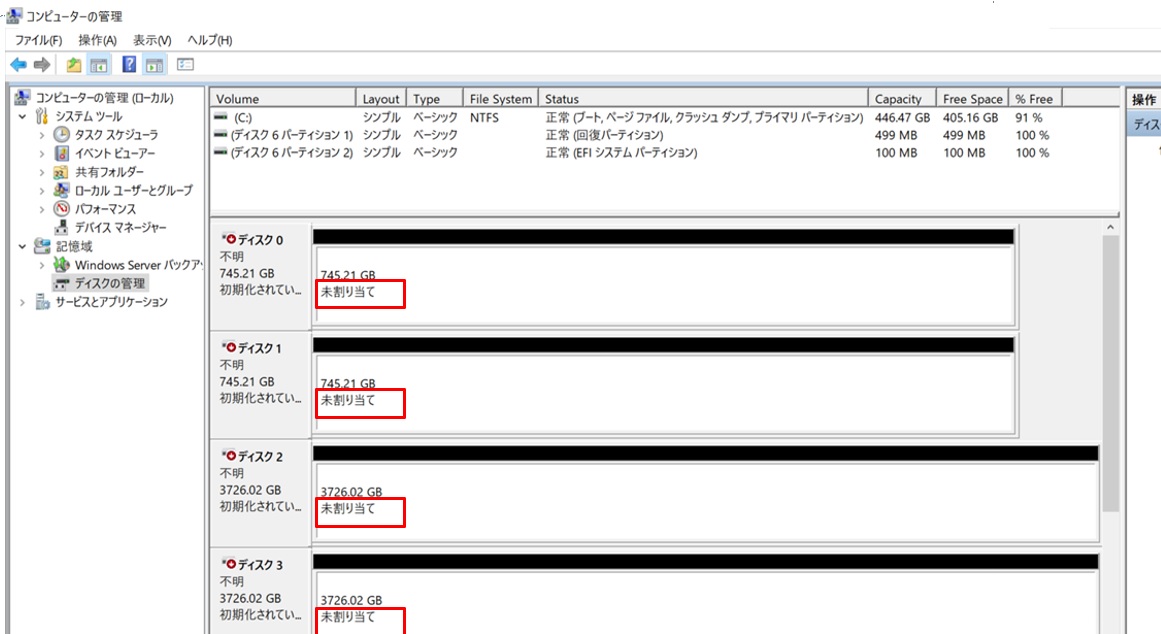
PowerShellでS2Dを有効にします。”Enable-ClusterStorageSpacesDirect”コマンドを実行します。
| PS C:\Users\Administrator> Enable-ClusterStorageSpacesDirect 確認この操作を実行しますか?ターゲット ’クラスターの記憶域スペース ダイレクトを有効にします’ で操作’nicp-cluster’を実行しています。[Y] はい(Y) [A] すべて続行(A) [N] いいえ(N) [L] すべて無視(L) [S] 中断(S) [?] ヘルプ (既定値は “Y”): yNode EnableReportName ——- ———————— NICP01 C:\WIndows\Cluster\Reports\EnableClusterS2D on 2021.11.11-14.55.16.htmPS C:\Users\Administrator> |
フェールオーバークラスターマネージャーにて、新しくプールとクラスター仮想ディスク(ClusterPerformanceHistory)が作成されて、どちらもステータスがオンラインであることを確認します。
2-5. ボリューム作成
ここからWACサーバーで設定していきます。
WACサーバーにてクラスタを登録してから、クラスタに接続して作成します。
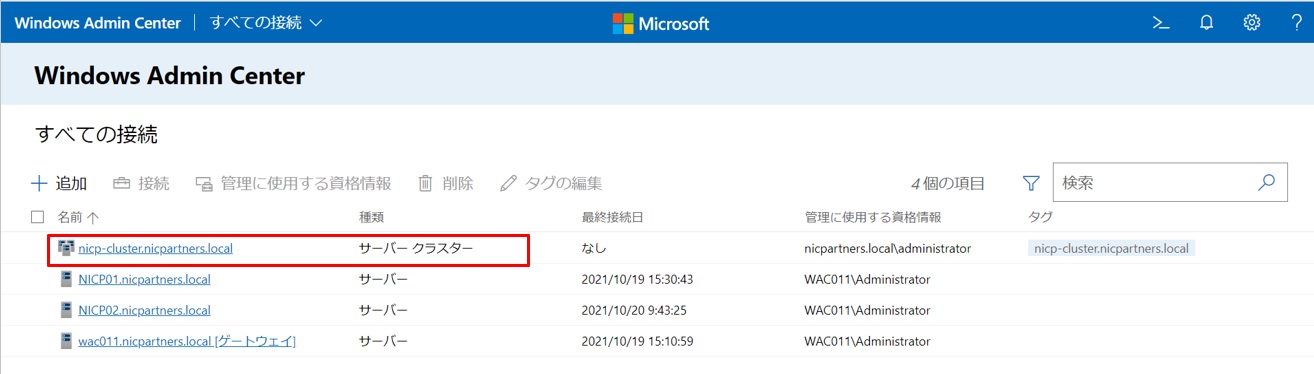
ボリューム画面から「作成」をクリックし、名前とサイズを入力します。今回はtest-vol01という200GBのボリュームを作成しました。
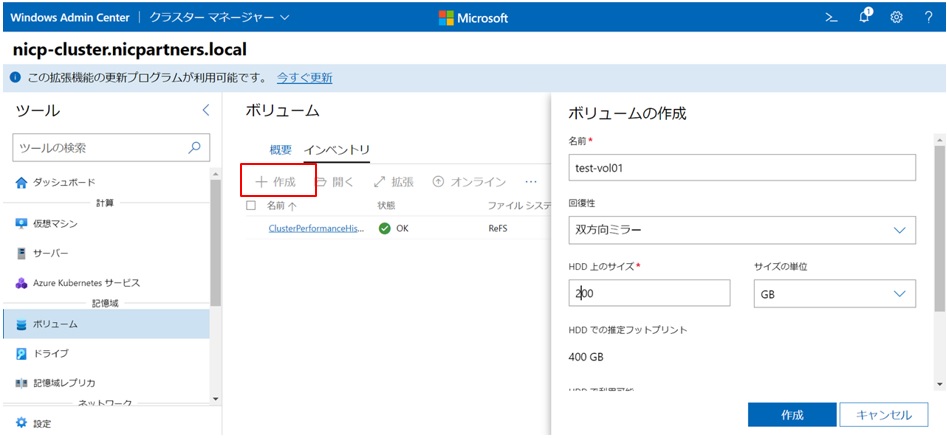
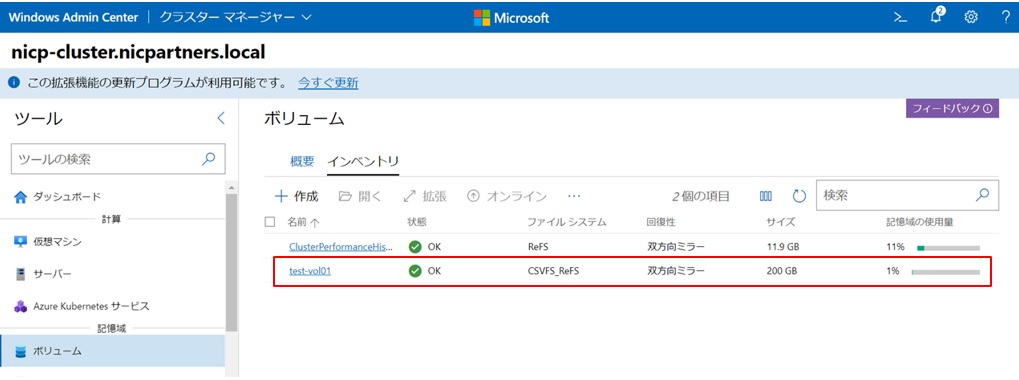
しばらくするとボリュームが作成されます。状態がOKになっていれば利用できます。
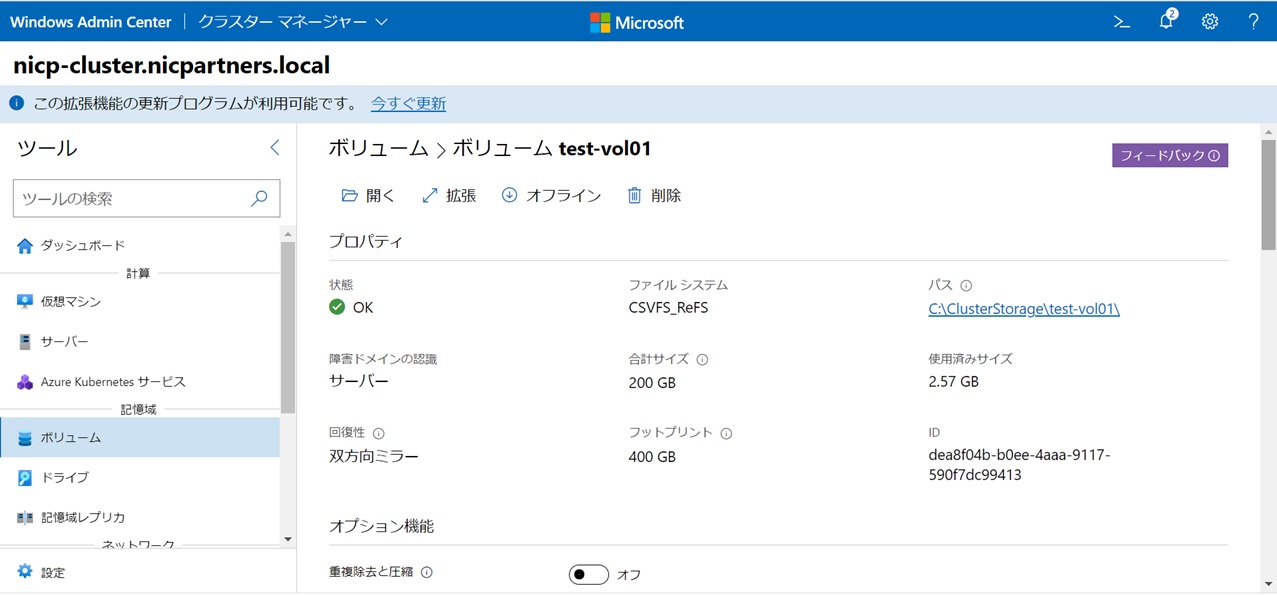
プロパティを確認します。作成直後はこのような状態になります。
フェールオーバークラスターマネージャーからも確認してみます。このようにクラスタの共有ボリュームとして作成されていることが確認できました。
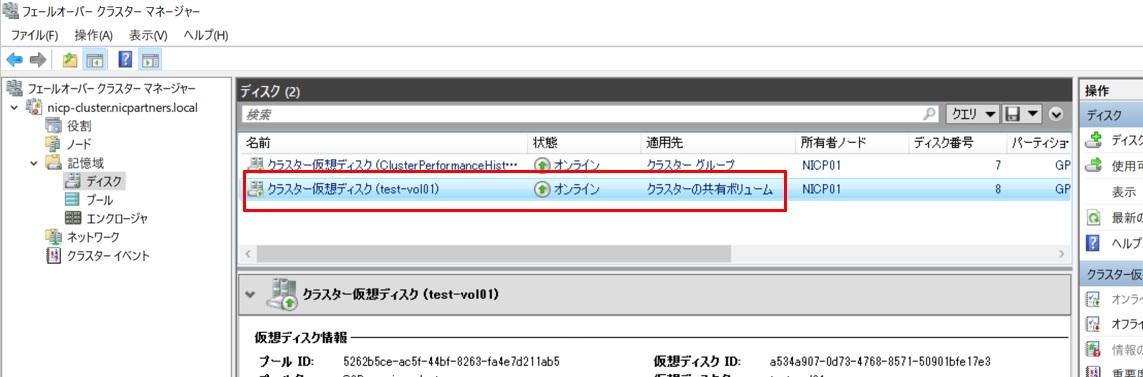
以上で共有ストレージを持たない2ノードのクラスタ構成で共有ディスクが作成できました。
これで仮想マシンを作成できるようになりました。
仮想マシンの作成やMXサーバーでの管理機能について検証してみた内容は第2回のブログでお伝えします。
さいごに
実機での検証は所々うまく動作せず、調べたり聞いたりと試しながらでしたが6時間ほどで検証は成功しました!
実際にXClarity Controllerを使ってみると操作性も良く、Enterpriseへアップグレードすることによる仮想ドライブのマッピングも便利でした。
Windows Admin Centerではインターフェースが分かりやすかったので、まだまだ触り始めの私でも十分理解出来ました。
個人的にはネットワークの設定辺りで躓くことが多かったです。参考にした手順書を見習いながら設定を進めましたがうまくいかないこともあり、一つ一つ調べながらの作業となりました。
もう少しネットワークの勉強が必要ですね。
構築編は以上になります。
如何でしたでしょうか、次は管理機能編になりますので是非ご覧ください。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp