
普段の製品・ソリューション紹介だけでは聞き出せない情報を「実際のところはどうなんだろう?」という素人視点で、専門家に聞いてみるシリーズです。
題して「実際どうでしょう」。。。どうぞ、ご覧ください。
<聞いてみて良かった(*´ω`*) メリひろ担当がエキスパートにインタビュー>

個人のPCでも普及しているSSD、従来のハードディスクより凄く早いですよね。フラッシュ・ストレージ、半導体デバイスがサーバー利用になるとどのようなインパクトがあるのかをその道のスペシャリストである日本IBMの伊藤さんにお伺いしました。(インタビュアー:重山)
日本アイ・ビー・エム株式会社、ストレージ事業部、製品企画・営業推進、パートナー開発・アライアンス・OEM担当
1997年から国内独立系ストレージベンダでソリューションセールス・OEMセールスとしてストレージ業界に参画。
通信事業者向け大規模クラウドストレージインフラのほか、2009年、電機メーカーの大容量のフラッシュストレージ・HDDストレージのプロジェクトにも参画。
2011年から外資系エンタープライズフラッシュストレージベンダーの事業開発経て2013年から現職。
※2013年9月時点のプロフィールです。
— 先日のセミナーはありがとうございました。時間が足りなかったですね、もっとお伺いしたかったのでインタビューさせて頂きました。よろしくお願いします。(重山)
伊藤:こちらこそ、よろしくお願いします。
容量単位で国内一番の導入実績
— フラッシュ・ストレージの話に入る前に、伊藤さんのプロフィールをお聞かせください。IBMに入られたのは結構最近なのですね。
伊藤:はい。2013年2月からなので半年が経過したところです。
— 社会人のスタートは老舗の印刷会社に就職され、デジタル事業の立ちあげなどの新規事業にも参加され、そこからローエンドストレージ専業のストレージメーカーに転職、そこで更なる経験を積み、外資系フラッシュ・ストレージメーカーの事業開発を経て現在に至るということですね。
伊藤:そうです。入り口は印刷会社でしたが、子供の頃からコンピュータが好きでした。まだPCがない時代でしたが、小学校の頃の作文を読み返したら将来はコンピュータの仕事につきたいと書いていました。ローエンドストレージ専業会社の時代では、2009年~2010年当時で日本国内でかなり大容量のフラッシュ・ストレージをお客様に導入していたと思っています。新規開拓、ビジネス開発は好きな領域です。
— それだけ専門にやられていて、外からIBMやフラッシュ・ストレージを見ていらっしゃった伊藤さんが日本IBMに入られて、実際いかがですか?
伊藤:Texas Memory Systems社を買収した頃から、投資の意気込みを感じていました。IBMは、フラッシュ・ストレージ分野に関して、1,000億円の研究開発費を投じると発表しています。フラッシュストレージベンダー専業の他社は「年商」が300~400億円クラスと考えると、いかに巨額な投資かおわかりいただけると思います。
個人的にはIBMがミッドレンジの製品を自社開発のStorwizeシリーズで強化したことは新鮮な驚きでした。ハイエンドストレージのイメージが強かったためです。これによって製品ポートフォリオのバランスも取れ、お客様のビジネスの支援は万全です。
現在(2013年9月時点)、私はストレージ事業部に所属していますが、7月1日付けで、ストレージ事業部内にIBM FlashSystemの専任チームが設立され、活動しています。組織を見ても、それだけ力を入れている事がよくわかります。
HDDは40年前から大きく変化してないストレージ技術なのです
— なるほど、IBMが力を入れているのは分かりましたが、市場性から見たらどうでしょうか。
伊藤:現在のコンピュータのアーキテクチャとしては、性能面でストレージだけが進化から取り残されていました。ハードディスクが誕生したのが1970年です。そこから、「磁気に記録する」という観点では大きな仕組みは変わっていません。
こちらの図のとおり、この30年でCPUパフォーマンスは年率で60%向上しているにも関わらず、ディスクは同5%です。
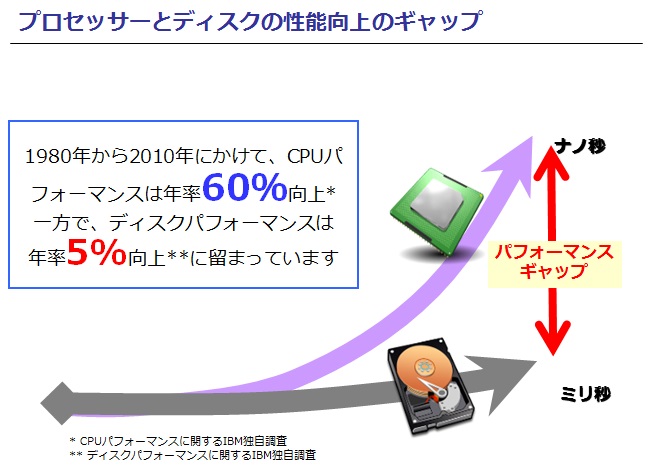
— 年率60%という数値も凄いですが、比較するとそれほど差があったのですね。
10時間が1時間へ、まさに桁違いのパフォーマンス
伊藤:システム導入案件においても、そもそもストレージがボトルネック(改善ポイント)だと認識されていない場合もあるぐらいです。
— コンシューマPCにSSDが利用されている現在、半導体ストレージは認知されてきていると思いますが、はやりサーバー製品でフラッシュを使うとなるとお値段が・・・・・
伊藤:そうですね、フラッシュの場合従来のディスクストレージとくらべても容量単価が15倍〜20倍高いのは事実です。今後、普及と共にもっと下がるとは思いますが、価格を比較するとフラッシュ・ストレージの方が高いのは変わらないと思います。
— 私も、このインタビューを続けてきて、少しわかったことがあります。高価格の製品は希少価値で高いのではなく、その投資に見合うだけの効果が期待できるからだと思います。
伊藤:先にそう言っていただけると、話しやすいです。(笑)実際の話ですが、例えば半導体回路の設計で現在はシュミレーションに10時間かかっているのが1時間になる場合の対費用効果は明らかですよね。工程が短くなる、品質があがって収益性が高くなる、競争優位になるという競争優位性の教科書のような効果が出ます。
— それにしても、1/10の時間短縮は劇的な効果ですね。
伊藤:そうなのです。SSDも速いのですが、3倍から5倍の性能しか出せない事が実情で、その理由はSASインターフェース等、ハードディスクをエミュレーションしていることによるオーバーヘッドがあります。オールフラッシュ・ストレージであるIBM FlashSystemなら、フラッシュメモリーチップの性能を最大限発揮する専用のハードウェア設計となっている事から、桁違いの性能を得られる場面が出てくるのです。
「10時間が8時間に短縮されます」だと、「現状のままでいいか」と思われるお客様でも、1/10の1時間に改善されるならば、お客様の事業課題も大きく変化します。そういったご提案が出来るのも、この製品の強みです。
また、システムの一部であるストレージのコストが高いのではなく、システム全体の投資コストはむしろ下がる事が多いのです。

2012年頃からマーケットが動いている
— エンタープライズ領域においても、フラッシュは最新テクノロジーではなく、導入検討が当たり前の年になっているのですね。
伊藤:そうですね、これは個人的な印象ですが、2012年くらいからマーケットにおけるフラッシュ・ストレージの許容性が変わってきたと感じています。3年ほどで大きな普及期がくると思います。
例えば企業における仮想化のテクノロジー、つまりHyper-V,VMwareは現在では日本でも当たり前ですが、米国やアーリーアダプターと呼ばれる先行着手ユーザから3年遅れで、やっと日本で大きく普及しました。
— こういった飛躍的な進化はIT業界にいてワクワクする要素の一つですね。どんどん進化していくのが楽しみです。
伊藤:逆説的な話で恐縮ですが、テクノロジーという意味では、実はNANDフラッシュメモリは、微細化の限界が近づいていまして、いまのままでは3年ほどで限界がやってくると言われています。
— NANDフラッシュメモリーの半導体技術の限界として、それ以上微細化できないということでしょうか?
伊藤:はい。この20年で13世代もの進化の結果、線幅はマイクロメートル(μm:0.001mm)からナノメートル(nm:0.001μm)へ進化し、チップあたりの容量は4,000〜8,000倍に増えました。詳細は割愛しますが、書き換え寿命は微細化と反比例しますので、現在主流の32nm、24nmの先の1xnmに到達した以降の次世代NANDフラッシュ技術では製品化が難しいと言われています。
そうは言っても、構造を3次元化するなどの次の技術が開発されてきていますので、何かしらの方法で進化はしていくと思います。
フラッシュ・ストレージの導入検討は経営効果からのアプローチが鍵
— なるほど、それは知りませんでした。 次ですが、IBMのALLフラッシュ・ストレージのロードマップの強みなどは先日のセミナーでも勉強させていただいたのですが、最後の方のいわゆる導入検討の段階がお時間が少なくて省略されてしまいましたが、改めてお聞かせ下さい。
伊藤:先ほどの投資コストの話の延長になりますが、「フラッシュ・ストレージの導入検討は経営効果から入り、必ずしもハード売りではない」と思っています。お客様は大きく分けると3つのタイプに分かれます。
ひとつは、投資効果が明確なケース。例えば統合ストレージ基盤を刷新した通販事業者様のように注文受付システムの応答速度が早くないとお客様を獲得できないのが明確な場合はすぐに導入が決まります。
2つ目は、システム部門が多忙というのもあるとは思いますが、投資効果を算出できていないケースです。例えばOracle等のDBサーバーのI/Oがボトルネックだと現状把握しているが、そのままIBM FlashSystemに載せ替え移植した場合に、データ処理性能の劇的な改善がどの程度なのかを把握していないため、導入検討が進まないケースです。
3つ目は、ディスクストレージのI/Oボトルネックに気がついていない等のケースで、認知して頂くために、効果的なご提案が必要です。
— 認知・啓蒙活動には「MERITひろば」でも貢献させていただきます!(笑)
伊藤:是非ご協力ください。私もセールスだけでなく、経営課題を解決するという視点で活動していきます。
— 今後のIBMのロードマップも注目しています。またアップデートがありましたら教えて下さい。本日はありがとうございました。
伊藤:こちらこそ、ありがとうございました。
導入効果予測「Oracle DB アセスメントサービス」実施中
パフォーマンス課題で悩まれているOracle DBユーザ様へ
“現状のOracleDB処理時間のレポート”と“FlashSystem導入後の効果予測”を無償でご提供するサービスを実施しています。
「バッチ処理が時間内に終わらない」
「チューニングも限界」
「クライアント集中で遅くなる」
上記インタビューのとおり、これらの課題はディスクI/Oが原因かも知れません。Oracle DBユーザー様に、DB,アプリははそのままで、FlashSytemを導入した場合、何がどのように早くなるのかのレポートサービスを無償で実施しています。
お客様には、標準で稼働しているOracle AWRというツールのデータを送っていただくだけの簡単な作業です。
伊藤さんは2009年の時点で、大手放送局の動画管理プロジェクトを担当し、約23テラバイトのSSD(半導体ディスク)ストレージも納入したそうです。
この分野では国内ではトップセールスだそうです。だからといって、イケイケな雰囲気ではなく、物静かに、しかし情熱的で知的で・・・と素敵な方でした。私も専門性を持ちながら幅広い知識をもったビジネスパーソンになりたいです。 (重山)