
普段の製品・ソリューション紹介だけでは聞き出せない情報を「実際のところはどうなんだろう?」という素人視点で、専門家に聞いてみるシリーズです。
題して「実際どうでしょう」。。。どうぞ、ご覧ください。
<聞いてみて良かった(*´ω`*) メリひろ担当がエキスパートにインタビュー>
「MERITひろば」の運営においても、Webサーバの生ログを分析したり、Google Analyticsを利用してアクセスログは見ているのですが、「ログ分析作業だけでは辛い」という担当者の心理をついた解説がわかりやすかったです。(インタビュアー:重山)
2002年早稲田大学を卒業後、国内広告代理店へ入社。
その後、Web系システム開発会社、デジタルマーケティングコンサル・Web開発会社での勤務を経て2011年1月よりIBMの戦略フォーカスである Smarter Commerce ならびに Enerprise Marketing Management (EMM)部門へ参画。
EMM各製品のプリセールスを担当。
趣味は波乗りと釣りとデジタルマーケティングの最前線で日本のWebビジネスを改革していくこと。
※2013年7月時点のプロフィールです。
製品視点ではなく、お客様の商売、立場で何を解決できるのかという視点を大切に
— いきなり素人発言で恐縮ですが、IBMが提唱しているインダストリーソリューションズ、スマーターコマース、エンタープライズ・マーケティング・マネジメント(以下EMM)の分野は沢山の製品群が存在していて、良くわかりません。一つずつの製品機能は見れば”なんとなく”わかるのですが・・・(重山)
田村:いえ、お客様もそう思われているでしょう。EMMを中心に、製品視点ではなく、ソリューション、つまりお客様のビジネスにおいて、どの領域で何を解決できるのかというシナリオ視点でご紹介差し上げます。このスライドをご覧ください。
はプラットフォーム")
田村: EMM(Enterprise Marketing Management、またはIntegrated Marketing Management)という考え方は、ガートナーが提唱しています。IBMはそのEMMを5つのマーケティング業務のプロセスとして定義しています。
デジタルマーケティングを含む企業のマーケティング業務には、収集、分析、決定、配信、管理というプロセスがあります。
分析の前にデータを集められるようにする、収集ですね。対象はお客様のお客様(消費者、エンドユーザ、個人)で、データはその人付随するプロファイル(誰、どこから、サイトの行動、取引履歴、コンタクト履歴)です。プロファイル情報を集めるのにも一苦労ですが、これらを人が見てわかるようにするのが分析ですね。
分析は「MERITひろば」でも実施していると伺っているGoogleAnalytics等のツールを使った分析ですね。IBMでは(旧称)Coremetricsという製品が該当します。ここまでの収集、分析は、ITツールを駆使して運営されている会社は増えてきました。
重要なのは、「この顧客には何をすべきか」という最良のマーケティングアクションを決める決定プロセスです。分析データから何を決定して、お客様にアウトバンド、インバンドを含めたコミュニケーション手段で配信して、その結果から何を得るか、このプロセス全体をどのように管理するかと続きます。
分析業務は次のアクションに繋がらないとわかるとつまらない作業
—- この図は全体を俯瞰できますね。私は、Web担当として、分析することに手一杯で次の決定以降の作業に繋がっていないという悩みはあります。
田村:はい。ちょっと乱暴な言い方ですが、分析はつらい作業ですし、次のアクションにつながらないとわかるとつまらない作業なのです。
— ありがたいです。実はその「分析はつまらない」という感覚にはすごく共感してしまいます。(笑)
田村:そうですね。この発言だけ取り上げられると私も立場上よろしくないのですが・・・(笑)しかし、お客様の本音だと思っています。
もちろん、分析には価値があるのですが、そこだけフォーカスして製品機能を語っても不十分です。
—- 発言内容はインタビュー記事を公開する前にチェックしてもらいますので、まずい解釈や表現は適切に編集しますから言ってください。(笑)
田村:はい。お願いします。(笑)
田村:実は先日、製造業のお客様への提案で、分析領域の説明はあえて減らしてみました。決定以降のプロセスの話を重点的にしたところ、ご担当者様も激しく同意してくださいました。
つぎに、業務担当者の領域別にソリューションを見てみましょう。
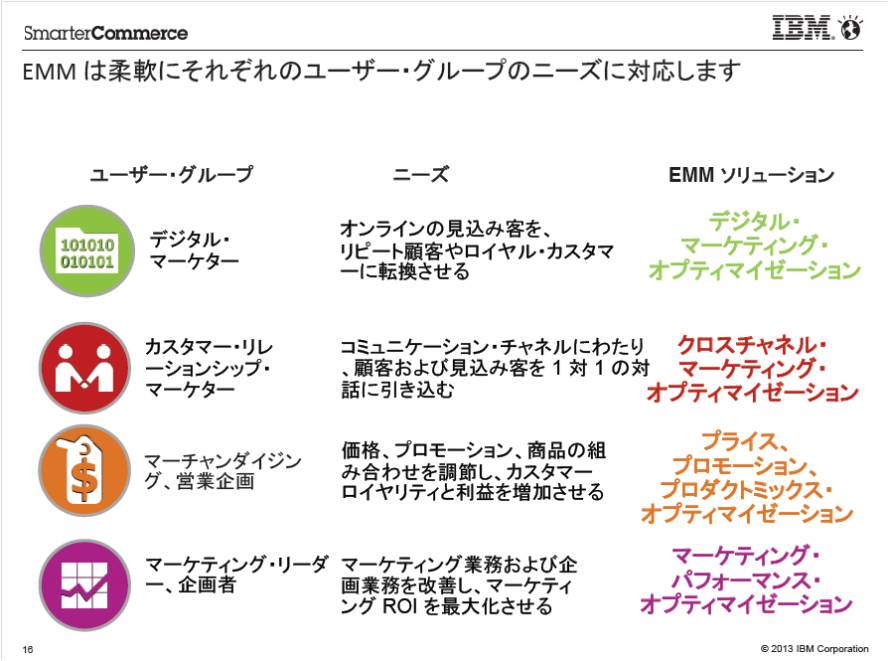
この図に製品名を大雑把に当てると以下のとおりです。
1.デジタル・マーケター向け :旧Coremetrics
2.カスタマー・リレーションシップマーケター(CRM) :旧UNICA
3.マーチャンダイジング、営業企画:DemandTec
4.マーケティング・リーダー :旧 UNICA Marketing Operation
5.コールセンター、Web担当(注:上図には記載なし) :Tealeaf
Google アナリティクスでもそれなりのことができますよね?
— この図は、どの業務のお客様に何を話すのかという整理ができていいですね。
では、ここまで聞いておきながら更に素人質問をしますが、Google Analytics(以下GA)があれば分析から決定作業につなげるレポートまで対応できているのではないかと思っていますが、いかがでしょうか。配信・管理は別だとは思いますが。GAは無料で使えますし。他の分析ツールと比較したことはないのですが、機能に遜色はないのではないかと思っています。
田村:良い質問ですね。
では、先ほどは5つのプロセスの話をしましたが、次はそのプロセスに製品を当て込んだスライドをご覧ください。
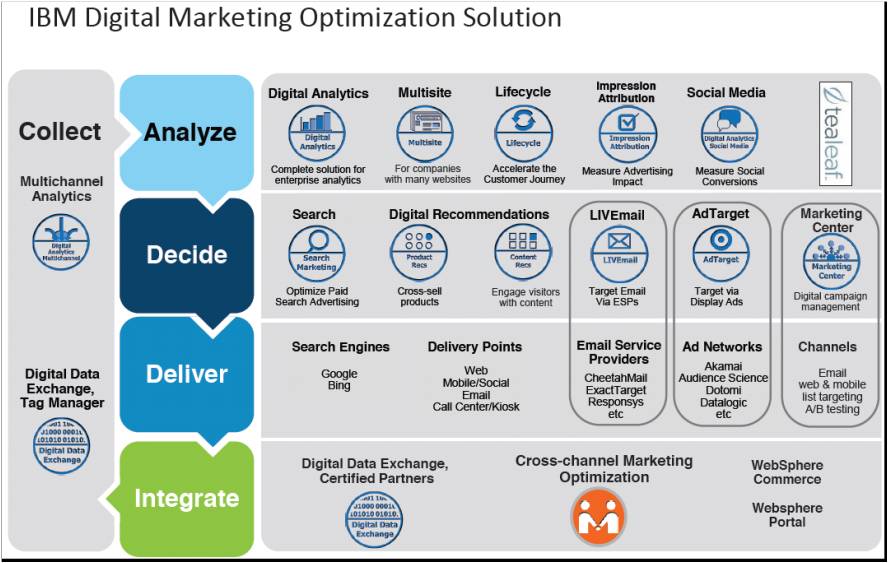
田村:英語の資料ですみません。一番左のCollectが収集、以下Analyze(分析)、Decide(決定)、Deliver(配信)、Integrate(統合、管理)のプロセスをレイヤーに分けて記述しています。丸の枠の中が各製品機能に該当します。
— あ、右上に新製品の「Tealeaf(ティーリーフ)」が入っていますね。ロゴ画像で、丸の囲みではないですが。
田村:新製品なので後から資料に足しているがバレましたね(笑)
Tealeafについては、後ほど紹介させてください。
先ほどの質問に戻りますが、分析ツールの話は、Analyzeのレイヤーの「Digital Analytics」の丸の中の話になるのです。
—- 全体から見ると本当に一部分なのですね。
特定の領域だけで製品比較に注力しているだけでは全体の課題解決には到達できない
田村:はい。この領域で、GAや他社のエンタープライズ向け製品・・という比較に注力していても全体の課題解決にはなかなか到達できません。
— なるほど、Web担当者だけの視点ではありがちな議論ですね。
おや?Analyzeのレイヤーにある丸囲みの「Impression Attribution」とは何でしょうか。
田村:ネット広告業界において、アトリビューションとは、広告効果測定のことを示し、ここ数年昔から使われている効果測定の考え方のひとつです。クリックの前の「露出(インプレッション)」が後の成果にどれだけ貢献したかを理解する為の効果測定の手法です。
—- MarketingROIの領域ですね。知ったかぶりですみません。以前、広告代理店やデジタルマーケティング会社に在籍されていた田村さんなら当たり前の領域かも知れませんが、システムインテグレーター界隈の人間には馴染みがあまりない言葉に感じました。
では、先ほど触れた「Tealeaf」について教えて下さい。
サイト訪問者の行動を後からビデオ再生のように確認できる画期的なソフトウェア
田村:TealeafはWebサイトにおいて、利用者が直面した障害や問題などを可視化するソフトウェアです。利用者のWeb上での動線を再現することができる画期的なソフトです。
例えば、先日のサッカー日本代表戦を例にすると、試合結果が1対1だったと示すのがWeb分析ソフトウェアです。一方、その90分間に何があったのか、本田が後半46分に相手のハンドを誘ってPKを決めて・・・という過程を教えてくれるのがTealeafです。
—- 分かりやすい例えです。(笑)それにしても、どうしてそのようなユーザが見たWeb行動を再生できるのでしょうか。通常のツールはブラウザのクッキー情報を取得して分析対象としているだけで、そのような個別のトレースは難しいと思うのですが・・・
田村:Tealeafはパケットをキャプチャしているのです。クッキーベースの製品とは根本的に違います。これによって、特定のサイト訪問者のWeb行動をビデオ再生しているように見て取れますので、非常に分かりやすいのです。ちょっと売込み宣伝になりますが、現時点で明確な競合製品もなく、引き合いが多い製品です。
—- でも、お高いのですよね?(笑)
田村:確かに定価で1千万円台(注:インタビュー時点での価格)ですが、PV(ページビュー)課金でご利用いただけますし、売上が発生するチャネルにおいて、Webが占める割合が高い、高くしたいお客様にとっては非常に有効なツールです。
Web分析市場は100億円、しかしビッグデータ市場で考えると3,000億円市場
—- この分野は今後も成長していくのですね。
田村:はい。少しマーケットの話をします。Web分析だけに限るとマーケットは100億円規模です。しかし、ビッグデータ市場として考えると3,000億円市場になるのです。
例えばIBM Digital Aalytics Accelerator(DAA)はWeb分析ソリューションとしてこの3,000億円マーケットに投入されています。IBMではSaaSベースでクイックに始められる製品からデータを自社内で抱えて、深く見ていく製品まで揃っているのです。

—- DAAのご紹介も先日MERITひろばの動画で解説いただきありがとうございます。マーケティング担当だけでなく、田村さんファンの方も是非ご覧いただきたいです。
田村:いえいえ、私ではなくソリューション、製品を見て下さい。(笑)
次ですが、レイヤー図一番下にある「Digital Data Exchange」とは何でしょうか。
会社の垣根を越えてデータ共有する仕組みで顧客に最適な体験を提供する
田村:はい。これは、自社Webサイトの管理外のデータとも連携していく仕組みです。広告業界では以前より、広告の枠情報を会社を超えて共有する仕組みがあります。広告在庫の需要と供給を個別のシステムを越えて共有するプラットフォームですね。
近年はさらに、DSP(デマンド・サイド・プラットフォーム)、RTB(リアルタイム・ビッディング)、DMP(データ・マネージメント・プラットフォーム)といった広告を最適な人に、適正な価格で効率よく配信するためのプラットフォームが注目されています。これらは少し専門的過ぎるので、今回は割愛します。
— 会社の垣根を越えてデータ共有する仕組みが広告、デジタルマーケティングの世界では広がっているということですね。共有するというキーワードで思い出しのですが、ライバル企業のWebサイトのアクセス数やサイト訪問者属性をこっそり調べる方法なんて存在するのでしょうか?
田村:さすがに、競合サイトの情報をとることはできませんが、データ交換プラットフォームというのは、必要に応じて自社サイトの訪問データを社内外のアプリケーションと連携して、顧客に最適な体験を提供するという試みです。
— すごい視野の広い活動ですね。ここまで話を伺って、データ分析の領域だけしか考えていなかった自分が恥ずかしいです。冒頭の5プロセスを含めて全ての領域でサービスできるのがIBMの強みなのですね。
田村:ありがとうございます。そうです、例えば件の図の左下にTag Managerと書いてありますよね。これは、ひとつのタグを自社のWebに埋め込むだけで、あらゆるプロセスのデータ取得、管理ができるようになります。もちろん、IBM製品で統一すればタグはひとつですが、提携済みテクノロジーベンダーのJavaScriptタグも統一管理できるのがTag Managerです。
DataExchangeという意味ではIBMはサービスに利用している生データを提供できるのも強みです。GAもAdobeもレポートになる前の生データは提供してくれないが、IBMなら可能です。そのデータをSalesForceにつなげる等のデータ活用する機会がお客様に提供されます。
— 確かにGAを使っていても、分析結果のレポートは提供されますが、例えばユーザのIPアドレスなどのGAが使っている元データは提供されないですよね。この視点は忘れがちですが、デジタルマーケティングを本気でやるなら必要な情報だと思います。
田村:そのとおりです。
「サイトの最適化」だけでなく「顧客体験の最適化」が重要
— 今回のプロセスの話は良く聞いていると「商い」として当たり前の視点ばかりですね。確かに製品はハイテク化、細分化していますが、お客様との会話では、このような商いの視点をもっていれば、課題の洗い出しも解決の提示もスムーズになりそうです。
では、最後になりますが、田村さんご自身のデジタルマーケティングに対する思いをIBMビジネスとつなげて一言お願いします。
田村:はい。私は、「サイトの最適化」だけでなく「顧客体験の最適化」が重要だと常々思っています。
初めてサイトに来たお客様とリピーターでは、体験も目的も違う。コンバージョンレートだけで図ることはできないのです。 分析ツールだけでお客様をハッピーにできるとは思っていません。
IBMでは本日ご紹介させていただいたように、EMM,スマーターコマースを中心に部分的なソリューションから全体最適を視野に入れた中長期の話をお客様と共有できるのが強みです。
— お忙しいところありがとうございました。私もMERITひろばを見に来てくださった方の立場でWeb運営するように意識していきたいと思います。Tealeafを導入する価値があるぐらいの立派なサイトにしていきたいです。
田村:こちらこそ、ありがとうございました。採用お待ちしております。