
生産性向上を目指し DX に取り組んでいる企業では、ハイブリッドクラウド環境で稼働するシステムの増加に伴い運用管理ツールが増え続け、様々な環境から発生する膨大な数のインシデントチェックとその対応がこれまで以上に IT運用管理者の負担となってきています。
この複雑化したIT運用管理の課題に対して、今、注目されているのが「AIによる自動化」です。
本コラムでは、IT環境の異常に対する自己検知、診断、対応を行う過程をAIにより自動化し、IT のコントロール性、効率性、ビジネス継続性の向上を実現する「IBM Cloud Pak for AIOps」についてご紹介します。
| 目次 |
|---|
ハイブリッドクラウド化により複雑化するIT運用管理の課題
生産性向上を目指して DX を推進する企業の多くは基幹系システムがオンプレミスで稼働する一方、クラウド上で稼働するシステムも増加しています。
オンプレミスとクラウドが混在した状態で複数のシステムを運用しているためトラブル発生時の原因究明や解決のために複数の運用管理ツールを複合的に利用する必要があり、IT運用管理の現場の大きな負担となっています。
例えば、1つの環境で稼働するシステムであれば障害発生箇所とその対応方法は特定のツールを利用して情報収集し判断ができるため比較的障害箇所を把握しやすいですが、システム自体がオンプレミスとクラウド環境の両方を使っているように複数の環境でシステムが稼働していると環境ごとに異なるツールに収集される膨大なイベントやアラートに対して原因を特定するまでの工程が多く、時間もかかります。
現場では熟練した技術者が常に不足している状態でこの負担が恒常化すれば、あってはならない「見逃し」や「対処の遅れ」によるサービス停止が危惧されます。
そのため、いざ障害が発生した際に素早くトラブルシュートができないのではないか?という危機感を持っている管理者は少なくないのではないでしょうか。
先に述べた通り、オンプレミス・クラウド両方の環境で構成されたシステムのインシデントチェックとその対応には、複数のツールを利用して膨大なイベントやアラートを収集・判別し、迅速にトラブルシュートする必要があります。
また、オンプレミス・クラウド双方において情報を収集・分析し、早急な対応が必要な案件をフィルタリングして抽出しなければなりません。
そこで注目されているのが、今回ご紹介する「AIによる自動化」です。
複雑化したシステムのインシデントチェックと、その対応に自動化が有効な理由
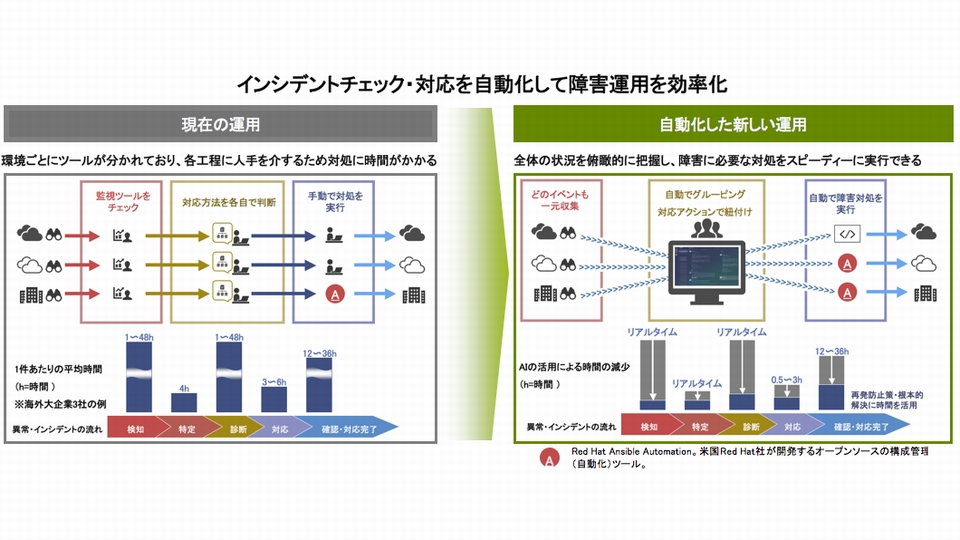
インシデントチェックとその対応は環境ごとに次のような工程に分かれており、各工程で人手を介する場合相応の時間がかかります。
- (1)イベントの検知
- (2)インシデント発生箇所の特定
- (3)インシデントの診断
- (4)インシデントへの対応
- (5)インシデント対応実施および修復完了
これを最適化・高度化するのが、AI による自動化されたフィルタリング機能です。
まず、複数のツールすべてのイベントを一元収集し自動的にグルーピングして対応アクションを紐づけることにより、(1)検知・(2)特定・(3)診断までの時間を大幅に短縮します。
AI はこれまでの管理知識や経験則を学習しているため、長年担当した熟練技術者や専任の管理者が不在であっても対応が可能です。
さらに、定型のイベントやアラートに対しては Red Hat Ansible Automation(※1)などの自動化ツールで事前に対処方法を確立しておけば、人手を使わず自動で障害対応を実行することが可能です。
そのため、(5)対応完了までの時間も大きく短縮することができます。
AI による自動化を活用すれば、膨大な数のイベントやアラートを人がすべてチェックする必要はなくなります。
早急な対処が必要な重要インシデントのみを AI がフィルタリングで絞り込んでくれるため、管理者はイベントやアラートを見逃すことなく障害が起きる前に対応することができ、システム監視と発生したイベントの解決を効率化することが可能になるのです。
※1:Red Hat Ansible Automationは、米国Red Hat社が開発するオープンソースの構成管理(自動化)ツール。サーバー構築から構成の変更、動作確認、確認作業まで一連の作業を自動化することができる。
IBM Cloud Pak for AIOpsが解決する3つのIT運用の課題
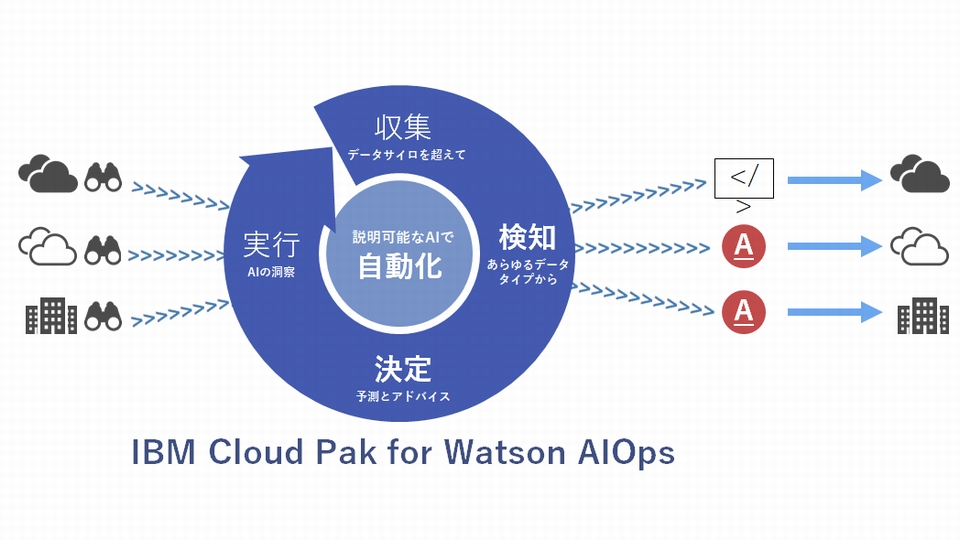
IT運用ツールチェーン全体に先進的な AI を実装することで、膨大なイベントやアラート通知をフィルタリングし重要で対処が必要な案件のみに絞り込んでシステム監視を効率化するのが、AIOpsプラットフォーム「IBM Cloud Pak for AIOps(以下 AIOps)」です。
AIOps は、IBM Research の120を超える特許と自然言語理解(NLU)、機械学習(ML)、自然言語処理(NLP)といった、最も優れた IBM Watsonテクノロジーを活用してシステム環境全体でデータを解析します。
IT環境の異常に対する自己検知、診断、対応を行う過程を自動化し、リスクと埋もれた技術資産を特定します。
これにより、基幹業務のワークロードにおけるインシデントを確実に評価、診断、解決できるようになり、IT のコントロール性、効率性、ビジネス継続性を向上させて複雑化するハイブリッド/マルチクラウド環境に対応した運用のモダナイゼーションを実現し、次の3つのメリットを実現してIT運用の課題を解決します。
1. データの一元収集と解析によるアジャイルでプロアクティブな運用管理
エンティティ・リンキング(知識ベースに結びつけ)によって構造化データと非構造化データを合わせて理解し、自然言語処理、機械学習テクノロジーを活用することで正確な診断および解決のリコメンデーションを行います。
IT環境から発生する様々なイベントやアラートを一元収集しこのテクノロジーを活用し解析することで、複雑化した複数のシステム環境における異常をリアルタイムで検知・分析することができるようになります。
AIOps を活用し IT運用の中核に AI を据えてすべてのビジネスワークフローに適用することで、アプリケーションとインフラストラクチャーの管理を集約し、問題を検知し解決する時間を短縮することが可能になります。
複数データを全体で処理することによってのみ理解できる固有の洞察を得ることも可能です。
トポロジー機能によるアプリケーションやクラスターの可視化、問題の発生個所とその影響範囲の把握、および問題解決に向けて迅速に対応が可能なため、アジャイルでプロアクティブな継続的に向上していく AI主導の運用管理を実現します。
2. インシデントチェック・対応を自動化して障害運用を効率化
AI/ML を活用したイベント分析により、関連イベントをグルーピングするとともに問題のコンテキストを把握します。
また、問題に対する Next Best Action を提示することで、イベント通知量を軽減すると同時に実行可能で効率的な障害運用を推奨することも大きな特長です。
Slack といった Chatツールへの情報連携によって、関連するイベントやトポロジーの情報、過去の類似事象、次に行うべきアクションを合わせて Chat内で提示してくれるので、早期に対応を開始することができます。
さらに、相関関係・因果関係・パターン特定により、洞察の根拠に関してステークホルダーにわかりやすい推論および説明があるので対応も迅速に実施できます。
これにより、今まで検知できなかった問題やその影響範囲を自動検知し早期に対応を開始するとともに、ホットスポットとボトルネックの可視化、財務的影響についての情報活用、早急に取り組まなければならない問題の優先順位付けなどの洞察を提供することで、次に行うべきアクションを自動的に提示し、解決時間を短縮します。
3. インシデント管理ツールチェーンによる予測保守で品質と生産性を向上
運用チームの働く場所で実行し既存のツール・プロセスワークフローを活用することで、ITデリバリーを加速し効率性を向上させます。
これらのデータはプロセスに組み込まれ運用チームに専門家のガイドを提供するため、お客様環境における傾向を把握した上で障害発生を予測することができ、事前に対応を行うことで障害発生を予防することにつながります。
また、AIOps の AI による早期の異常検知や次に行うべきアクションの提示には、運用コストの削減や ITサービスの品質向上も見込まれます。
さらに、サービスを可能な限り迅速に復元するように最適化されており、これにより最高レベルのサービス品質と可用性が維持されます。
まとめ
AIOps はマルチクラウド・ハイブリッドクラウドで利用される様々なツールによって生成されるイベントやアラートを一元収集し、収集したデータを AI で解析することで従来の手作業では発見できなかった問題を早期に明らかにしていくために有効な製品です。
また、膨大なイベントやアラート通知をフィルタリングし重要かつ対処が必要な案件のみに絞り込むことでシステム監視を効率化するとともに、対処が必要なインシデントに対してはその対処方法を提示してくれるのも、AIOps の大きな特長です。
さらに AIOps はどのようなソースからでもデータを取り込み、ローカル、ハイブリッド、マルチクラウド環境を横断して管理するだけではなく、お客様が選んだ様々なコラボレーションプラットフォームとの連携や IT運用ツールとの相互運用が可能で、様々なクラウドでも洞察を直接ワークフローにつなげることができます。
特に、
- マルチクラウド・ハイブリッドクラウドにおいてフルスタックの可観測性を提供し、環境を理解・判断して迅速にアクションを促す洞察を提供する「IBM Observability by Instana」
- AIを活用し、アプリケーションのためのリソース配置を自動的に最適化するAIOpsソリューション「Turbonomic ARM for IBM Cloud Paks」
- AIライフサイクル管理機能(継続的学習、公平性、ドリフトモニタリング、データリネージュ、など)を提供する「Cloud Pak for Data」
と連携させることによってハイブリッド・マルチクラウド環境の効率的な管理を実現し、クラウドのメリットを最大化させることができます。
エヌアイシー・パートナーズは IBM認定ディストリビューターとして、ARM(Turbonomic)や APM(Instana)製品などとともに、AIOpsソリューションの拡張提案についてご支援します。
AIOpsソリューションに関するお悩みは、ぜひエヌアイシー・パートナーズへご相談ください。
お問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いします。
関連情報