
カモシーこと、日本IBM 鴨志田です。
IBM Watson が支援する「働き方改革」の第3弾にあたる今回を最終回として、お届けします。最終回は、資料の準備にかかる時間を減らすことをテーマをメインに進めていきます。
これまでの以下の記事もぜひご覧ください。
【特集ブログ】IBM Watsonが支援する「働き方改革」
第1弾:会議編 / 第2弾:メール編
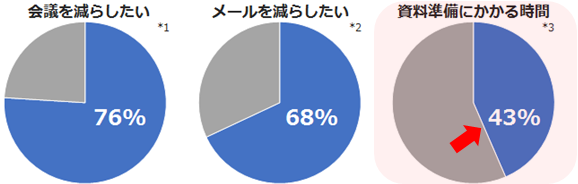
※出典:*1,2 ガートナージャパン 2016年 *3 IBM調べ資料検索や準備にかかる割合
IBM では、毎年 営業メンバーからある特定の1日をサンプリングして、その日の活動時間を項目ごとにどれだけかかっているか調査しています。その結果、半分近くの 43% を資料の検索や準備に費やしていることが判明いたしました。次のような項目から成り立っています。
| 営業プラン作成/訪問準備/資料検索/提案書作成/条件調整/提案レビュー/質問回答準備/営業管理報告/営業プラン更新/管理業務 |
資料といえば、Box?
資料といえば、ファイル、ファイルと言えばクラウド型コンテンツ管理プラットフォームである Box が有名です。しかしここでは、短絡的に「Box を使いましょう」と言いたいのではなく、Box というプラットフォームやファイル、データをいかに効率良く、効果的に活用するかが「働き方改革」を支援することにつながっていくかについて考えていきたいと思います。
Box とは
あらためて Box とは何かについてご紹介してまいります。大きく特長は 3点 です。
1. 容量無制限
|
|

1. 容量無制限であること
ファイルサーバーですと、毎年のようにストレージ容量を追加していかないといけない、現場の各部門にヒアリングして必要容量を計算して予算を確保および、そのバックアップも考えなければいけない、そのようにコスト試算が面倒ですし毎年どんどんコストが膨らんでいく傾向にあります。しかし、Box であれば、一定の使用料を確保しておくことで毎年の予算が定常化され、運用していくことができます。また、最近は動画や音声ファイルも電子化されていってますので、容量無制限は非常に魅力的です。
2. セキュリティ
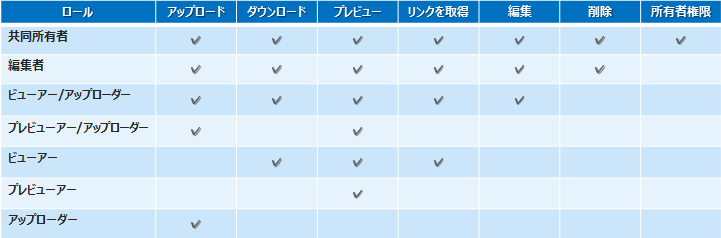
クラウドというと「セキュリティは大丈夫か?」という議論が必ず発生いたします。Box は、データの暗号化、通信の暗号化はもちろんのこと、その特長として細かいアクセス権管理があります。例えば、プレビューアーという役割では、ファイルのプレビューはできるけれど、ダウンロードはできないという権限です。「外部のお客様とファイルの共有をして見てもらいたいけど、ファイルをそのまま渡してしまうのは好ましくない」ような場合に使えます。反対にアップローダーという役割では、ファイルのアップロードはできるが、その他のファイルを見ることはできないという役割です。例えば関連業者様や企画会社にファイルをアップロードしてもらう場合や学校のゼミなどで生徒が課題を提出する場合にアップローダー権限を付与し、先生方は編集者として提出されたものを添削、コメントしていくことができます。
3. 連携
Box は様々なソリューションとの連携も大きな特長の1つです。例えば前回ご紹介したような電子メールとの連携があげられます。Box は通常、ブラウザやスマートデバイス上の Box アプリから利用しますが、BoxDrive のモジュールを設定することで、ファイル・エクスプローラー(Mac でいう Finder)や各種オフィスなどのアプリケーションから直接 Box にアクセスしてファイルの読み書き・更新ができます。一方で、そのように直接 Box を利用していくのではなく、デジタル複合機と連携し、契約書などの紙媒体をスキャンする際に複合機の操作パネルから直接 Box のフォルダを選択し、直接 Box に格納して電子的に管理していくことでデジタル複合機を入り口としてアクセスしていくことも可能です。また、IBM Notes/Domino や IBM Connections Cloud およびサイボウズ kintone などのアプリケーションのファイル格納先として Box を利用していくこともできるようになっています。利用者は Box の存在や Box との連携を意識することなく、利用しているアプリケーションから自然と Box にセキュアに情報を格納していくことができるのです。
IBM Watson との連携例
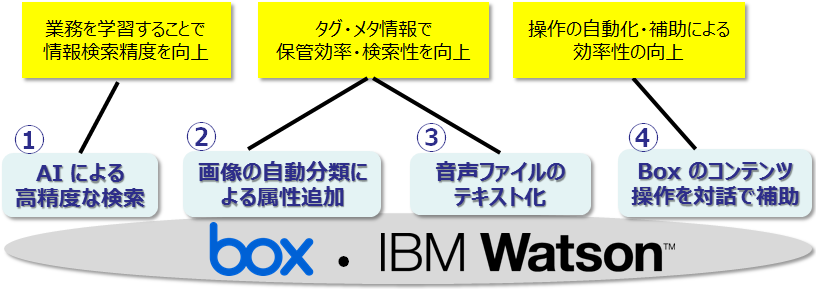
では、次に IBM Watson と組み合わせるとどのようなことができるかご紹介していきましょう。Box でのコンテンツ管理と IBM Watson の各種サービスを組み合わせることで次のようなことが実現できます。
① AI による高精度な検索
|
以下、Youtube の動画ファイルがありますので、是非ご参照ください。
▼AI 時代の box + IBM Waston ナレッジ活用ソリューション (Youtube より)
AI による高度な検索
ご紹介の YouTube でご覧いただきましたように、1 つ目の例にある「AI による高度な検索」だけでも大きく「働き方改革」や今回のテーマである「資料の準備にかかる時間を減らす」ことに寄与することがわかると思います。Box のみならず、IBM Notes など様々なアプリケーションでそれぞれ検索機能は搭載されていますが、必要な情報がなかなか見つからないということも多いと思います。そこへ IBM Watson が加わることによって、役立つ資料かどうかの判別ができたり、自らその評価のフィードバックをすることができたりしますので、有益な情報の見える化またその資料探しの短時間化に繋がります。
| 画面左が IBM Watson によって学習した後の検索結果、右は IBM Watson とは連携しない時の結果です。結果が異なることがわかります。 |  |
 |
|
IBM Watson およびサイボウズ kintone との連携例
次に、サイボウズ kintone と連携していくとどのようなことができるでしょうか?例えば、IBM Watson と サイボウズ kintone そして Box の組み合わせでは、農業改革につながっていったという事例があります。
| 右のような画像があります。よく見ると白い斑点がありますが、このような写真を含めて、kintone 上のアプリで報告書などのレポートをまとめたり、統計管理をしたりしていきます。 写真は kintone から自動的に Box に格納され、さらにそれが IBM Watson の Visual Recognition というサービスと連携することで、この白い斑点の問題の判定と対応策の提示を行ってくれるのです。 数十年農家に専従している熟練者でなくても、迅速に問題解決を図ることができます。高齢化、後継者対策や専門的な判断の補助など農業に必要な知識の習得期間の短縮に寄与しています。 |
 |
Box Capture でスマートに働き方改革
先の例のような画像・写真と Box および IBM Watson との連携をよりシンプルに行っていくことができます。それを支援するのが Box Capture (キャプチャー)です。AppStore からアプリをスマートデバイスに無料でダウンロードして利用することができます。
| Box Capture は、カメラや録音アプリです。 Box Capture を利用すると、iPhone などのアプリに保存することなく、直接 Box の指定したフォルダに写真や音声をアップすることができます。Box に入った後は、先の Visual Recognition で画像判別をしたり、タグ付けをしたりしていくことができます。 |
また、IBM Watson と連携をしなくても、リアルタイムに現場での写真を本部の方や遠隔地の方と共有することができますので、例えば建設現場や保守メンテナンスの現場写真を本部の方がレポートにまとめたり、技術の方が見て適切なアドバイスを即座にもしくは、並行作業で行ったりすることができます。個人だけでなく、チームでの働き方改革に寄与できるのではないでしょうか。
「働き方改革」成功のポイント
さて、これまで 3回の連載に渡って IBM Watson やコラボレーションツールおよびそれらの組み合わせによって「働き方改革」の事例や解決策の例をご案内してまいりましたが、最後に働き方改革成功のポイントを IBM での経験を元にご案内したいと思います。結論から申しますと、成功のポイントはツールの有効活用だけではありません。
以下の図にあるように領域 0 から 4 までの 5つの点を考え、対応する必要があります。
IT ツールやそれを利用する環境、スマートデバイスのような端末や外出先や自宅からアクセス、共有できるインフラ環境は、領域 1.2. ハード面としています。ここでは、領域3.4. のソフト面および領域 0 の組織風土・意識を整備する方法や IBM での例をご紹介いたします。
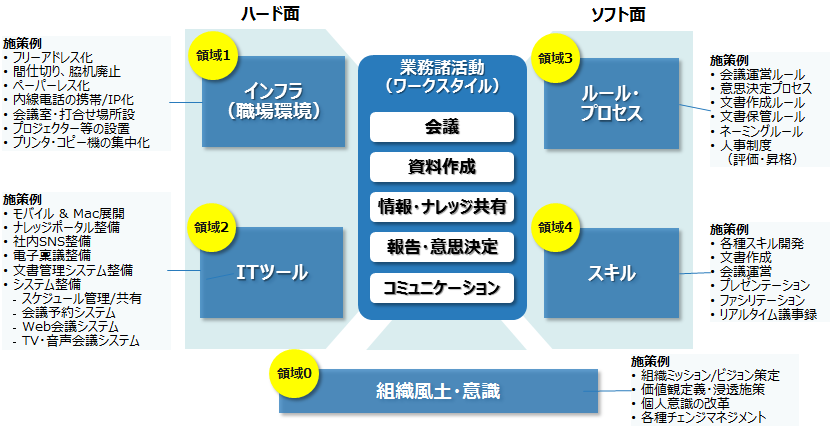
領域0. 組織風土・意識
「組織風土・意識」を整備するのはもしかすると最も難しいかもしれません。IBM Watsonを活用するにしても働き方改革を実践するにしても、情報・データ・ファイルなどこれらがナレッジとして活用されていく情報の元ネタが必要になります。まずこれらの情報がないと話になりません。「俺のものは俺のもの」としてみなさま各人の頭の中やPCの中にしまわれていては困ってしまいます。組織内に共有されてそれが活用の土台にあがっていくかが重要です。
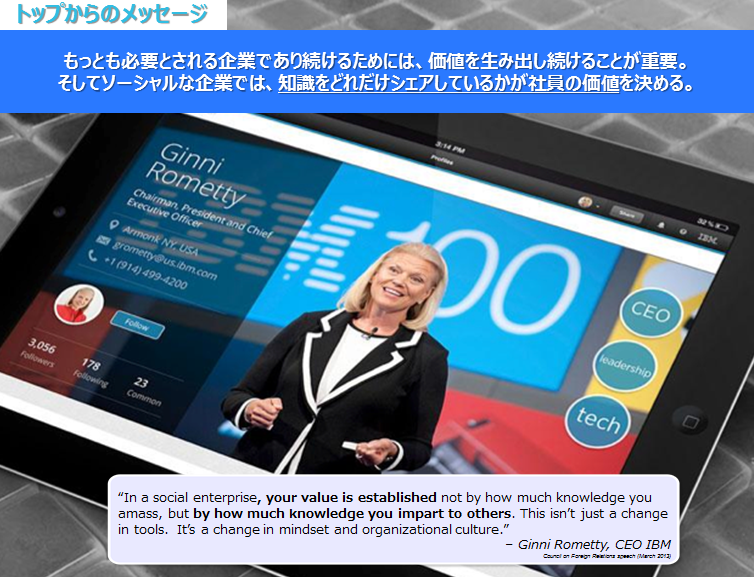
IBMでの例としては、トップ自らが情報の重要性を訴えています。具体的には次のようなことを従業員に訴求しています。
「知識をどれだけシェアしているかが社員の勝ちを決める」
こんなふうに訴えかけられたら「俺のものは俺のもの」なんて言ってられませんよね。
トップ自らが情報の重要性を訴える、トップ自らが情報発信をするなどの行動が必要かつわかりやすい訴求方法ではないかと思います。
領域3.4. ソフト面
「知識をどれだけシェアしているかが社員の価値を決める」と言われてもお客様情報や個人情報など何でも共有できるものでもありません。その辺りのルール整備も必要です。従業員が迷った時の指針となるものがあると安心して行動ができると思います。これも IBM を例に取りますが、IBM では BCG (ビジネス・コンダクト・ガイドライン=行動基準)を定めています。
内容は非常にシンプルでごくアタリマエのことが記述されていますが、IBM 従業員としての基本的な行動基準ですので、行動の拠り所として利用することができ、このようなものが有るというだけでも安心感があります。IBM 従業員は毎年この内容を学習して(クイズなどにも答えます(苦笑))同意し、サインをして働いています。こちらの BCG は外向けにも公開されていますので、参考にしてもらえればと思います。
→ 『IBMビジネス・コンダクト・ガイドライン』(IBM企業行動基準)
最後に・・・
以上、IBM Watson が支援する「働き方改革」と題して身近な「働き方改革」をどのように実現できるかを例を交えて連載してまいりましたが何かヒントになるものはありましたでしょうか? 身近な「働き方改革」で最も重要なことは行動を起こすことかもしれません。みなさまのまわりでできることを何か少しでも実践してみませんか?