
カモシーこと、日本IBM 鴨志田です。
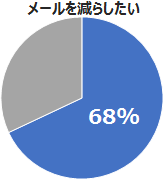
前回(IBM Watsonが支援する「働き方改革」第1弾:”会議編”)は、身近な「働き方改革」として、会議の効率化に焦点を当ててご紹介いたしました。今回は、「電子メール や コミュニケーション手段」にメスを入れてみたいと思います。と言いますのも、前回も引用いたしましたが、2/3 を超える方から「電子メールの数をもっと減らすべき」という声があがっていますので、この多くの方の声にお応えしない訳にはいかないと思っております。
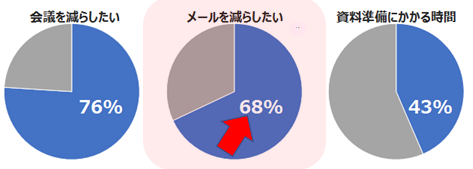
出典:ガートナー ジャパン「日本における社内コミュニケーションに関する調査」
{kind=link}
そこで、電子メールの問題点は何かを改めて考えてみました。下表をご参照ください。
| 項番 | 電子メールの問題点 | 良い点としてとらえると |
| 1. | すぐに読んでもらえるかわからない 返事がいつくるかわからない |
やり取りの証拠として残る |
| 2. | 宛先に入れた人にしか伝わらない | 必要な人に一度に伝達できる |
| 3. | 各人が情報ややるべきことを管理する必要がある | 後からでも確認ができる |
| 4. | 転送されてしまう危険性がある | 手軽に転送できる |
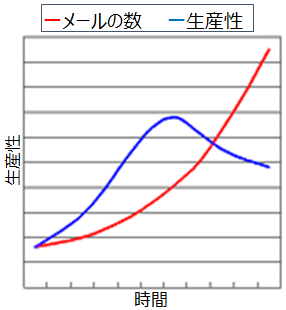
これらは「電子メールのパラドックス」と言われます。パラドックスとは、逆説や矛盾という意味です。本来、生産性を向上させるツールであったものが、反対に生産性を損ねる要因になってしまうことを表しています。生産性とメールの量の関係をグラフにすると以下のようになり、メールの量が膨大になると生産性が落ち込むことが読み取れます。
ではその「電子メールのパラドックスにならない方法」をご案内していきましょう。
1. 「返事がいつくるかわからない」への対応
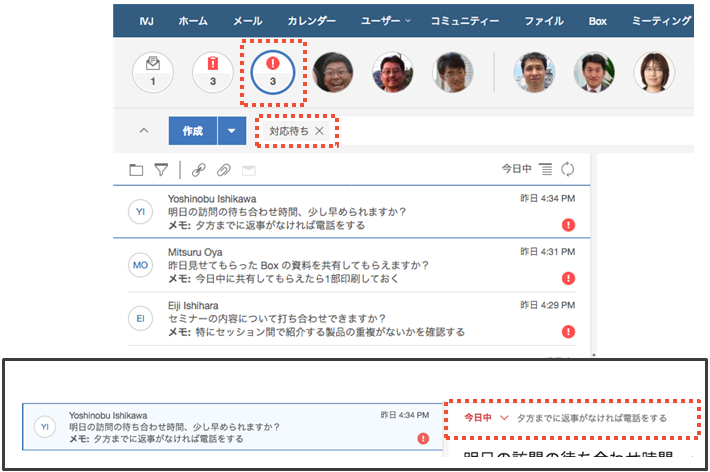
「相手に読んでもらいたい」「返事が欲しい」というメールもそうでないメールもあると思います。本当にすぐにでも返事が欲しいような用件は、電子メールではなく、対面や電話で確認したほうが良いかもしれません。しかし、相手が捕まらない場合はひとまずメールを送っておくという手段はコミュニケーションを取る上での一手になります。そのような場合はこうしませんか? IBM の電子メール「IBM Verse」では、送信したメールにメモを付けたり、フォローするタイミングを設定したりすることができます。下図のように、メール送信の際に 1 クリックし日時設定とメモを書き込みます。すると「対応待ち」に格納されます。これによりこの用件は一旦忘れることができるのです。頭のなかで「これをやらなければ! あれを対処しなければ!」と考えていると作業や仕事に集中できず生産性を落としかねません。頭を空っぽにして別の仕事に集中していきましょう。
2.「レレレメール」にならないための対応
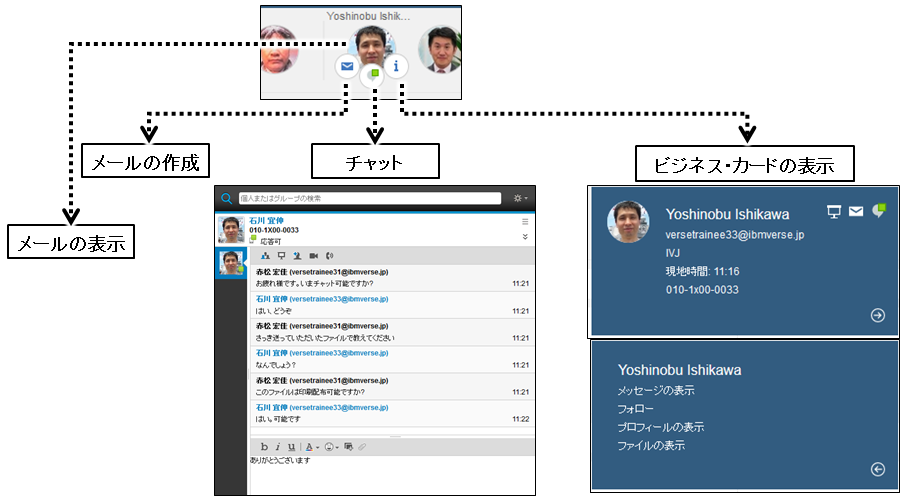
今度は送信側ではなく、受信側での場合を考えてみましょう。受信したメールに返信を出すことはよくあります。さらにその返信を待つということもあるでしょう。メールソフトによりますが、送受信が続くと「Re:Re:Re:」といつまでも Reply の Re: がつながっていく「レレレメール」になっていくことがあります。また、ちょっとした用件のメールに何分も何時間も掛けてやり取りした経験はありませんか? このような場合は、「在席確認とチャット機能」が役に立ちます。IBM Verse には在席確認とチャット機能が利用できるようになっています。
人を選んで在席状況を確認してチャットをすることもできますし、受信したメールに在席マークが表示されますので、そこからチャットで話しかけてサッと用件を済ましてしまうことも可能です。これにより、例えば 5 時間かかっていたやり取りが 50 秒で終わる、そして次の仕事に取り掛かるということもできるのです。
3.「情報の管理」への対応
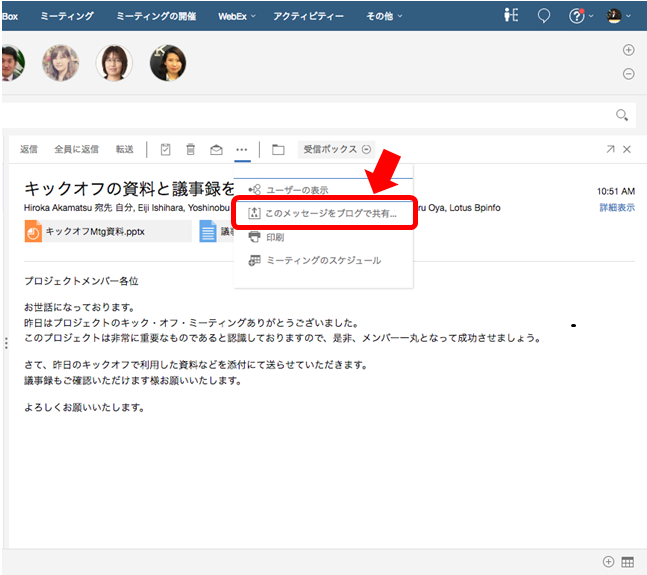
「宛先に入れた人にしか伝わらない」「私その情報もらっていない」・・・とならないように、とりあえずcc に全員入れておく。このようなことありますよね。結果、不要なメールが増えてしまう、また反対にメールを受け取った人はその情報をフォルダ分けなどで整理しておく必要がある。いかにも非効率です。情報は共有しましょう、そして共有しておく場所を決めておき、必要なメンバーが把握/参加でき、経緯や最新情報/結果をいつでも見ることができるようにしておきましょう。これによって、類似情報が社内に点在したり、並行して複数の人が同じ作業をしたりする無駄を省くことができます。そして、最初の情報発信源がメールだった場合、IBM Verse では 1 クリックで情報共有の場に導いてくれるようになっています。
4.「転送の危険性」への対応
「送ったメールが誰かに転送されてしまう」これは致し方ないかもしれません。ですが少なくともメールに添付したファイルを勝手に転送されてしまわないように、場合によっては、ダウンロードすらできないように対処したいという利用シーンもあると思います。ファイルにパスワードを付ければ良いのでしょうか? もしくは、添付ファイルがある場合は自動的にファイルを暗号化できれば良いのでしょうか? 残念ながらそれでは不十分です。結局、受信者はファイルをダウンロードして、パスワードで復号できてしまいます。そんな信用ならない人にはファイルを送らなければ良い、ごもっともですが、すぐに共有したいということもあるでしょう。
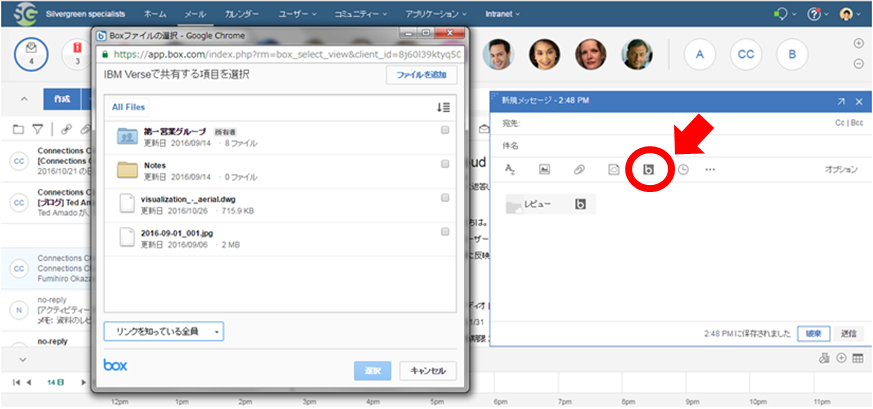
このような場合は、「IBM Verse と Box」 を組み合わせて利用することをお勧めいたします。
IBM Verse でのメール作成時にファイル添付を示すクリップのアイコンがありますが、隣接して Box の “b” アイコンが表示されます。これをクリックすると、クラウド型コンテンツ(ファイル)管理である Box にアクセスします。Box からファイルを選択するとファイルを添付するのではなく、リンク情報だけを付けるようになります。これにより、万が一このメールが転送されてもファイル格納元の Box へのアクセス権がなければアクセスできませんし、Box のアクセス権限で、「プレビューアー」を設定しておくと、ファイルをプレビューすることはできますが、手元にダウンロードすることはできないようになります。手軽にセキュリティ高く、迅速・円滑な情報共有ができることと思います。
最後に・・・
このように電子メールの数そのものを減らすことは難しいかもしれませんが、電子メールの良いところは活かしながら、問題点をそれぞれの方法で対処していく、これにより、個人やチームの生産性を向上していくというのはいかがでしょうか?
ご紹介しました IBM のソリューション(IBM Verse と Box)は、きっと皆様のメール処理の生産性向上のお役に立てるでしょう。是非ご検討なさってください。
★予告★ 次回は、”もう少し Box に触れながら「資料の検索、共有や準備」にメスを入れます。ご期待ください!