
こんにちは、てくさぽBLOG メンバーの佐藤です。
12/12(火)、12/13(水)にヒルトンお台場で開催されたNVIDIA主催のカンファレンス「GTC Japan 2017」に参加してきました。
本ブログは12/13(水)の内容になります。
1.GTC Japan 2017とは?
GPUの雄NVIDIA主催のイベントとなります。
近年AI,ディープラーニングの市場規模が拡大していることもあり、話題のイベントとなります。
なお、昨年のレポートも参照ください。
”参加してみた” GTC Japan 2016
2.基調講演
基調講演の始まる30分程前に到着したのですが長蛇の列でした。
基調講演会場に何とか入れましたが、入れなかった方もいたようです。
おなじみの革ジャンをまとったNVIDIAのCEOジェンスン・ファン氏が登壇し今年もひとりで説明。
当初の予定を超過して1時間半強、話しっぱなしでした。
内容をまとめると、大きく以下の3点をアピールしていました。
・性能の飛躍がもたらす恩恵
・シミュレーターonシミュレーター
・自動運転
レクサスはCG?と思いきや、リアルタイムレンダリングで、中央のロボットらしきものはVRで参加している人になります。
内装も、エンジンも部品単位でデータ化されています。
未来のデザインlabという事でしたが、ここでいう”デザイン”というのは単純に見た目だけでなく
パーツの配置や組み付けの考慮という広い意味でのデザインとなります。


続いて、開発環境についての紹介です。
NVIDIAとしてはオンプレかクラウドかという選択を迫るわけではなく、クラウド環境でもオンプレ環境でも同じフレームワークで自由に使い分け、移行が出来るようにしています。

こちらの女性はディープラーニングによりAIが作り出した女性の写真です。
ほかにも男性や老人が次々と映し出されていました。
これらは3Dのモデリングで描画しているわけではなくディープラーニングによって作り出しています。
注目は左の車窓 で、こちらも自動生成された画像になります。
このデモは学習結果から学習元のサンプルデータを作り出すことができるということで、たとえば自動運転の場合は実際に車を走らせなくてもマシンパワーさえあれば仮想空間に昼も夜も、何十、何千万台でも自動運転カーを走らすことができます。
結果、自動運転のラーニングを飛躍的に加速させることができます。

サプライズということで日本では未発表だったVOLTA版Titan Vが発表。
こちらは開発用のカードで複数枚未サポートですが、安価にGPUを使うことができます。
価格は2999USD。

実績としては画像認識系のソリューションで今まで4ラックのシステムをV100によりなんと1ノードになった!とのこと。
CEOいわく、GPUは買えば買うほどお得になるとの事。

次はバーチャルゴルフコースのバーチャルロボットのデモ
実際のロボットもゴルフコースも用意しなくても、パターゴルフのディープラーニングがバーチャルで実施できます。
学習開始はよちよちな動きで、ボールにも当たらない、途中からボールにあたるようになり、最後は100発100中になりました。
現実的な問題としてはこのシミュレーターの中だけですべてのテストを終わらせるのは厳しいはずですが、ロボットアームやロボットは学習過程において自分自身を破壊してしまったり、意図せず人間を傷つける事があるため、少なくとも人間ではありえないエラーを出さない程度に仮想で事前学習してくれるのは現時点でも有用と思われます。

基調講演は最後にこれがAI革命だ!と締めくくりました。
実機を用意しなくてもディープラーニングができるというのはかなり革新的でこうなるとコストや時間といった物理的な制約から解放されて膨大な量のテストができます。
しかも学習用のサンプルデータも作り出すことができる。
これが進むと、十分にテストができるため”初期ロットは不具合が多い”といった常識は変わっていきますし今まで量が膨大になりすぎるので、無意識に切り取られていたテストから新しい発見、発明が出るかもしれません。
3.セッション
セッションはたくさんあり、どこも立ち見が出るほど大盛況でした。
1つだけ紹介したいと思います。
IBMからは、最近発表した「Power System AC922」に関する内容と、IBMが考えるプロセッサの将来についてです。
一般的に、GPUだけ高速なマシンはパフォーマンスを引き出すのにチューニングが難しい上級者向けとなります。
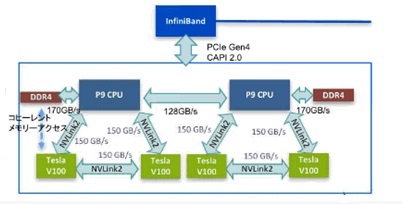
その点、AC922はCPUとGPUをNVLink2という高速なバスで接続することにより全体としてバランスの取れたマシンと言えると思います。
バスの比較ですが、一般的に使われているPCIe Gen3 x16では帯域は双方向32GB/sで、仮にPCIe Gen4になっても64GB/sにとどまります。
NVLink2ではこれが150GB/sとなり、高帯域幅を利用することが可能となります。
以下は4GPU構成の例です。
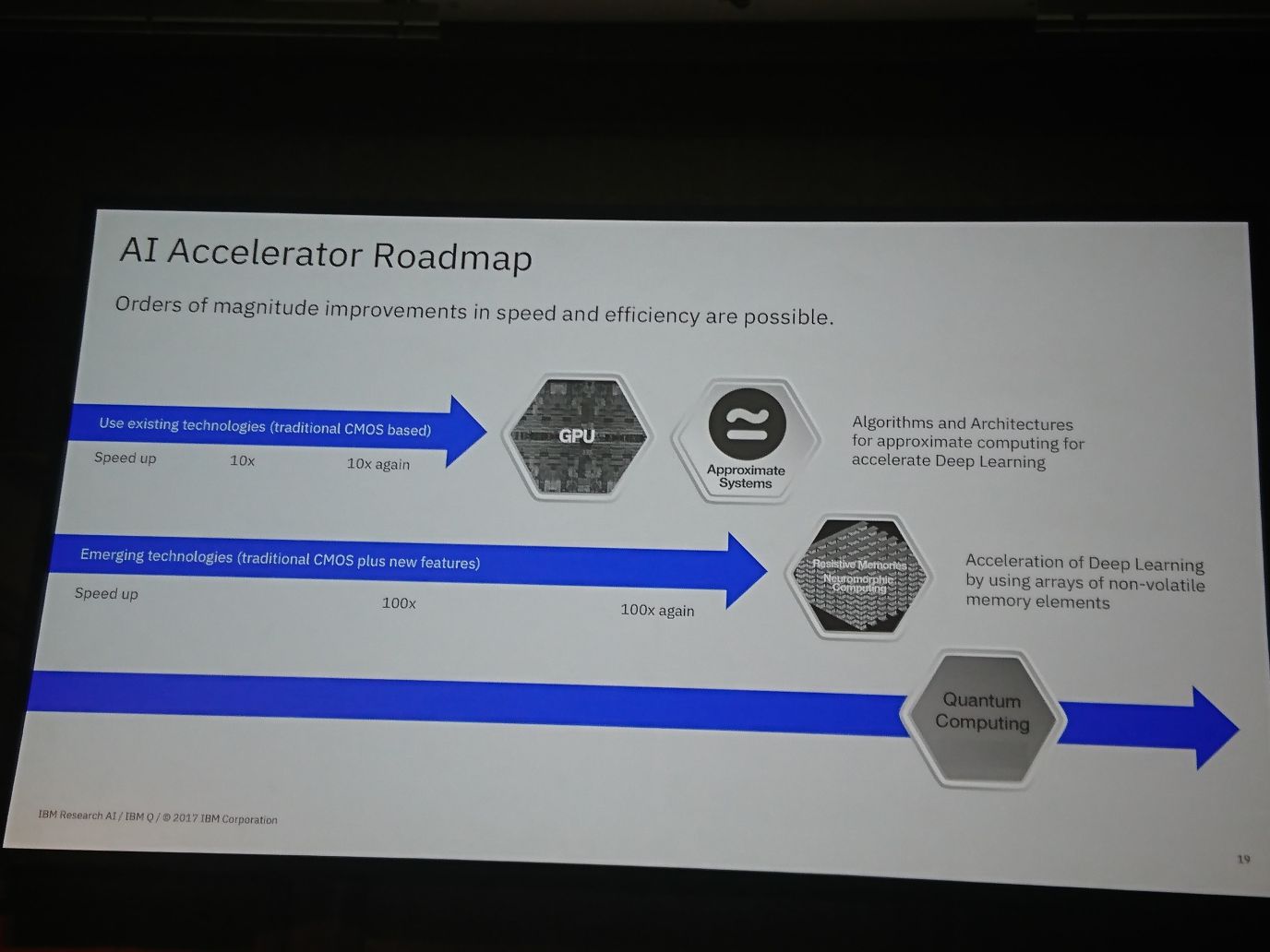
次にIBMが考える将来のAIアクセラレーターについてです。
IBMとしてはGPUは単体で将来的には今の10倍、それを並列に並べスケールすることにより、さらに10倍程度の性能が上限とみています。
次世代については、研究中の脳を模したSyNAPSEチップを用いることにより100倍以上の性能、次々世代は一部提供が開始されているIBM Q…量子コンピュータを想定しているようです。
注目が集まるIBM Qについて、先日50Qubitのプロトタイプが発表されましたが、50Qubitは量子コンピュータの一つの壁と言われています。
サービス提供がされればブレークスルーになるかもしれません。
将来が楽しみな発表でした。

4.おわりに
最後に、今年はトヨタが協業を発表したこともあって、ブースは車関係の内容が非常に多く日本における自動車業界の市場規模の大きさを体感しましたし、主催者の想定をはるかに超えた参加者だったようでした。
<関連情報>
動画・資料公開】12月20-21日【NI+C P主催】Webセミナー「遂に登場! POWER9 搭載サーバー “Newell”に迫る!」
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp