
皆様こんにちは。てくさぽBLOG メンバーの佐野です。
今回のブログは、10/5(水)にヒルトンお台場で開催されたNVIDIA主催のカンファレンス「GTC Japan 2016」に参加してきましたので、簡単にフィードバックします。
1.GTC Japan 2016とは?
GPUを製造している会社であるNVIDIAが主催のカンファレンスです。GTC=GPU Technology Conferenceの略称です。
GPUを用いた最先端のソリューションや、NVIDIAの最新製品、パートナー企業がブースに出展し各社のソリューションを展示していました。
イベント全般的な感想としては、「ディープラーニング」や「IoT」といった言葉がキーワードとなっていたように感じました。特にディープラーニングについてはセッションも多く、GPUとの相性も抜群なのでキラーソリューションの1つであると思います。
2.基調講演
基調講演は立ち見も出るほどの盛況で、私が数える限りでは約800~1000人程度の参加者がいました。
基調講演にはNVIDIAのCEOのジェン・スン・ファン氏が登壇し基本的には1人で説明をしていました。
内容をまとめると、大きく以下の2点をアピールしていました。
・ディープラーニング
・自動運転
GPUによるディープラーニングは新しいコンピューティングモデルであるという説明をし、GPUディープラーニングの開発者が25倍に増加しているという事実を公表しました。

GPUディープラーニングはIoTデバイスなどからの情報を分析・学習し、推論した結果を各デバイスにフィードバックするというサイクルでできているということを説明しました。
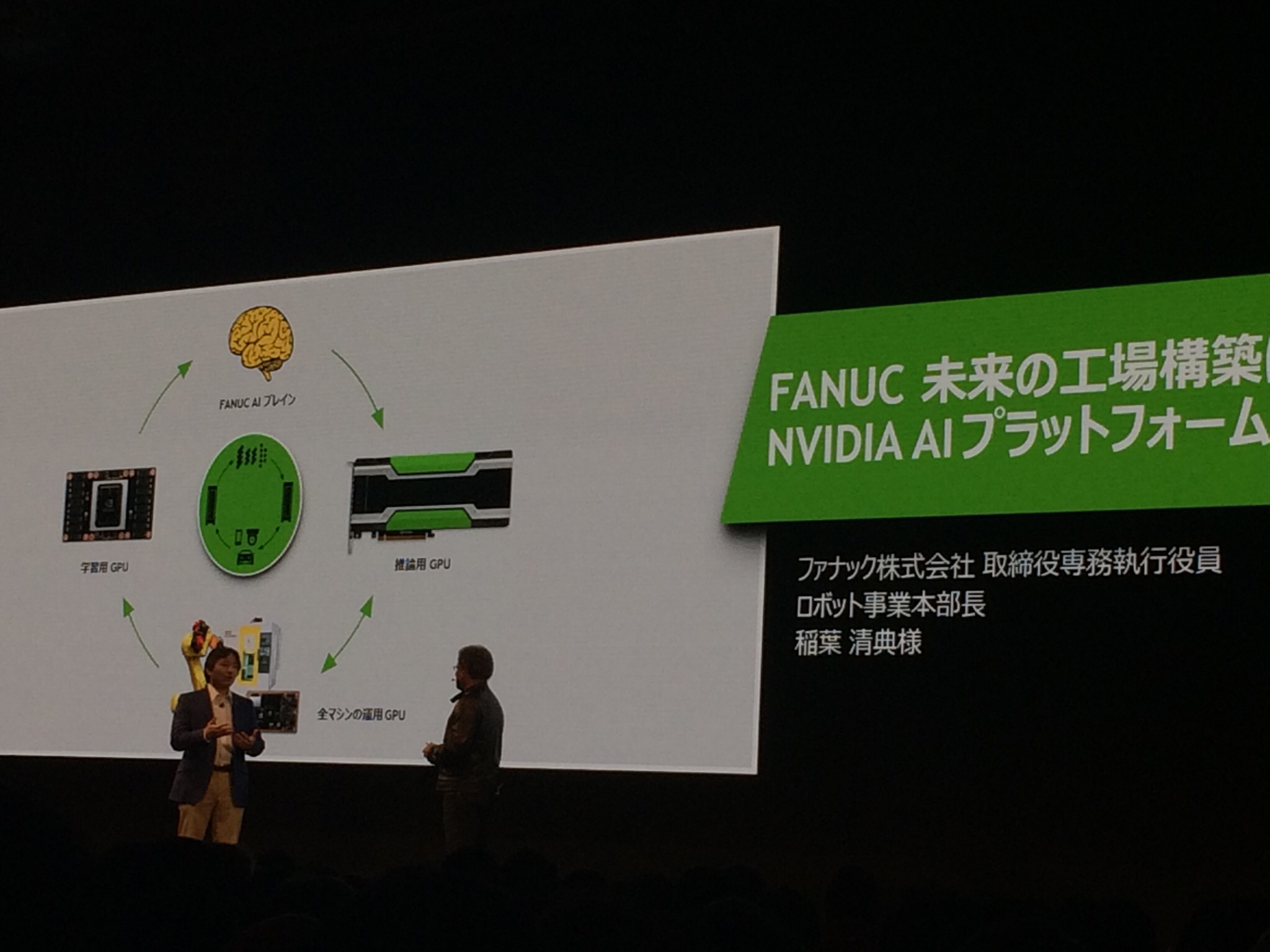
これを実現している企業として、企業向けロボットの製造会社であるファナック様が登壇して実際の仕組みについてを説明していました。(流ちょうな英語で・・・)
ロボットにAIを搭載し、学習することで作業効率性を上げるということを実現しているそうです。
続いてジェン・スン・ファン氏は、IoT機器に搭載することを目的とした小型のGPU搭載マシン「Jetson TX1」を紹介しました。この機器は乾電池と同じ大きさで、動作にはわずか10Wという低消費電力で1Tflopsもの処理能力をもつことが売りです。Jetsonを使えば、各IoT機器が自己学習し動作することが可能となります。

自動運転に関しては「Driveworks Alpha」という自動運転用のオペレーティングシステムを発表しています。

このOSを使うことで、位置情報や周囲の車両・レーンの情報などを把握し、運転をサポートする機能を利用できます。
最後に、今までのソフトウェアを書くだけでは解決できなかった問題を解決するために、ディープラーニングやAIを利用することが重要だということを述べて締めくくりました。
3.セッション
全部のセッションの内容は書ききれないので、IBMセッションの内容について書きます。
IBMセッションは、最近発表した「Power System S822LC」に関するセッションでした。
このモデルは、2つのPOWER8 CPUと4枚のGPU(NVIDIA Tesla P100)を搭載しており、CPUとGPU間はNVLinkで接続されているのが特徴です。
NVLinkを利用するメリットは、x86サーバーでGPUを接続するとPCIe x16での接続となるので帯域は16GB/sにとどまりますが、NVLinkでは2.5倍の40GB/sとなり、高帯域幅を利用することが可能となります。(GPU間もNVLinkでの接続)
トポロジー概要は以下になります。

CPU-Memory間でも115GB/sという転送速度ですので、CPUからGPUにデータを渡すところが全体のパフォーマンスのボトルネックとなることが見て取れると思います。
電気通信大学の森下亨様から、この実機を使ったいくつかのシミュレーションを実施し、システムのパフォーマンスがどのようになるのかの検証結果を発表していました。
簡単にいうと、実施したシミュレーションは、大きな行列で表された物質の状態に、状態変化のための係数(行列)を掛け合わせるものです。この掛け算を繰り返すことで、物質の状態がどのように変わるのかをシミュレーションします。
行列の大きさはシミュレーション内容によって変わります。
1つ目のシミュレーションでは、行列の大きさが16GB以内に収まるようなシミュレーションです。
CPUのみで計算した時には約11.51Gflopsでしたが、GPUを利用すると107.10Gflopsと10倍近くのパフォーマンスが得られました。
この場合には、トポロジー図にも記載したように、GraphicsMemory内に全てが格納できてしまいますので、計算を開始してからCPUからGPUにデータが送られるのは1回だけです。
そのため、GPUのパフォーマンスがフルに発揮できたといえます。
2つ目のシミュレーションでは、20GB以上のメモリを利用するようなシミュレーションです。
この結果が興味深いもので、CPUのみで計算した時には約23.86Gflopsでしたが、GPUを利用すると14.84Gflopsと2/3程度に落ち込んでいます。
このシミュレーションでは行列が大きいことでCPUからGPUへの転送が500回発生しており、NVLinkの帯域がCPU-メモリ間の帯域よりも狭いことでパフォーマンスが落ちているようです。
3つ目のシミュレーションでは、物質の状態を表す行列を大きくした場合です。CPUからGPUへのデータ転送は2つ目のシミュレーション同様に500回発生していますが、パフォーマンス結果は異なっています。
CPUのみでは234.71Gflopsでしたが、GPUを利用する場合には483.90Gflopsとなっており、GPUを利用した方が2倍近くの性能を出しています。
これは、計算量が多くなったことでNVLinkの帯域幅が小さいことよりもGPUの処理能力が高いことによるメリットが大きくなったということを示しています。
森下様によると、このシミュレーションにはまだ改善の余地があるということですが、数値が結果として出ているので見ている方としてはイメージがしやすく、メリットもよく分かりました。x86サーバーとは帯域幅が違うので、これだけのパフォーマンスが出るのはPower Systemsだから、というのもありそうです。
このように、GPUが有効に活用できるような計算処理があると、GPUを搭載できるモデルは計算速度に圧倒的なメリットがでてきます。
4.その他
各社の展示では、GPUは関係なさそうな展示もありました。
例えば、こんなのや、

こんなの

です。
前者は歩行機械の右に見える画面で歩くときの重心位置をポインティングしていました。(ピンクの丸です)
後者はパワードスーツのようなもので、GPUとの関連性がいまいち分からず・・・
最後に、休憩時間になると展示ブースは常に人がいっぱいで、本当に盛況なイベントだったと感じました。
<関連情報>
・Power System S822LCのお披露目動画
———-
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp