
普段の製品・ソリューション紹介だけでは聞き出せない情報を「実際のところはどうなんだろう?」という素人視点で、専門家に聞いてみるシリーズです。題して「実際どうでしょう」。。。どうぞ、ご覧ください。
<<実は私もインフラ担当、そのお気持ち良くわかります。 (*´ω`*) >
MERITひろばのE-learningコンテンツ(旧:学ぶメニュー※現在はご利用いただけません)のサービスとしても利用させていただいている株式会社システム・テクノロジー・アイのiStudyサーバ。そのインフラ担当者に、最新のクラウド環境構築の現場についてお伺いしました。
実は私もMERITひろばの運営だけでなく、社内システムの運用管理業務も兼務しており、ゲストの新保さんの苦労、やりがいのエピソードに共感すること が多くありました。(インタビュアー:重山)

PROFILE
株式会社システム・テクノロジー・アイ 新保 義幸 さん
・ 技術本部 インフラ統括部 部長
・ ヘルプデスク、製品サポート業務を経験した後、当初から希望していたインフラ担当となる
・ 29万人の学習を支える企業向けクラウドサービスの基盤も担当
MERITひろば事務局 重山 勝彦 (インタビュアー)
日本情報通信株式会社。MERITひろば事務局。入社3年目にてMERITひろばの運営、コンテンツ全般を担当。
※ 2012年12月時点のプロフィールです。
— 先週の日曜日(11月25日)に企業向け学習ソフトウェア「iStudy(アイスタディ)」のクラウドサービスをバージョンアップされたのですよね。名称は「iSudy Dynamic Cloud EE」で合っていますか? (重山)
はい。そのとおりです。 (新保)
— MERITひろばのE-Learningメニューでも利用させて頂いている「 iStudy Enterprise Server」は、「iES」と略していたのですが、今回は略称があるのですか?
・・・そう言われると略称が決まってないですね。Dynamic Cloudだけでは、弊社の製品名がなくなっちゃいますし(笑) 重山さん、何か考えて下さい。
— うーん、うーん・・・いやいや、私が質問する側ですから勘弁してください。(笑)
きっかけは、データセンター内にあるブレードサーバ環境の整理だった
— それでは、本題に入らせていただきます。 この度は、iStudy Dynamic Cloud EEはIBM PowerLinuxを採用し、その上の仮想化にPowerVM for PowerLinuxで構築され、期待以上のパフォーマンスが出たと伺っています。しかし、最初からPowerLinux/PowerVMで決めていたわけではないと思います。このプロジェクトの経緯を教えて下さい。
当初は、データセンターのコロケーション移設が目的でした。お客様向けのサービスを稼働させているデータセンター内のサーバラックの場所が点在していたのと、一部のマシンが来年で保守期間が終わるため、それらの統合 ・整理が必要だったのです。
— なるほど、ではPowerVMの話が出てきたのは、サーバ環境の統合を検討された延長上ということですね。
はい、春頃にIBMのPowerLinuxの発表を代表の松岡が見て、よしコレを使ってみようという方針が出ました。
— 松岡社長ですね、テクノロジーや業界動向に明るい方ですよね。以前の環境もIBM製品だったのですか?
そうです。保守切れになるサーバH/WはIBMのx86ブレードでした。iStudyもWebsphere上で稼働していますから。
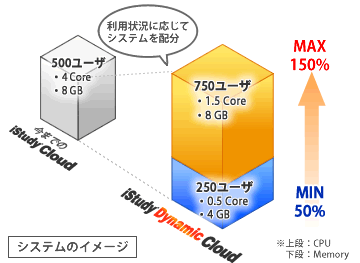
他のVM環境は利用していたのでPowerVMに期待した
— VM環境は他の選択肢もあったと思うのですが、最初からPowerVM狙いだったのですか?
通常採用決定の前に検証作業をするのですが、Linux KVMはすでに他のお客様サービスで利用しており、Oracle VMも弊社のIT研修サービスで扱っているので、パフォーマンスや使い勝手はナレッジがありました。 そこでせっかく検証するならPowerVMにしようという背景がありました。
— なるほど。技術検証も含まれたこのプロジェクトですが、どのような体制で進められたのですか?
物理的なマシンやネットワークの移設で2名、PowerVM構築で2名、iStudyのアプリケーション、サービスの開発、検証等で7、8名の体制でした。
— 完全に自社技術メンバーで進められたのですね。PowerVMの検証は具体的にはどのような作業だったのでしょうか。
Apacheのソフトウェア・ファウンデーションである「JMeter(ジェイメーター)」というクライアント・サーバシステムのパフォーマンス測定ツールを使いました。複数台のクライアントとサーバを立てて、1台のクライアントから数百のアクセス環境をつくり負荷テストを実施しました。
— ラッシュテストというやつですね。検証前の期待値と結果はいかがだったのでしょうか。
一般的なVMへの期待は「少ない資源で多くの稼働」です。始める前は、他のVMと比べても大きな差は出ないかも知れないと思っていました。
数値の読み間違い。実は、10倍のパフォーマンス性能だった
— ということは、期待以上の結果が?
はい。ただ、最初は間違えた計測をしていました。 パフォーマンス計測時のCPUのカウントの仕方が、KVMはスレッド単位だったので、PowerVMも同様に考えていたのですが、実はCPU Coreを10分割に調整できることに気が付かず、0.1が1コアだと思ってテストしていたのです。ラッシュテストを続けると、1コアでは足りなそうなので、2コアを割り当てました。
— 実際は2コアではなく、0.2コアだったのですね。
そうです。IBMの担当者にもずっと「2コア」で話していました。でもその性能でも実用化可能なレベルだったので、購入の手配まで進んでいました。(笑)
— ずっと1/10で評価していて、OKなレベルだったということは、実際は10倍の性能がでちゃったということですよね。
まさに嬉しい誤算です。 逆ではなくて良かったです。今では笑い話になっていますが。
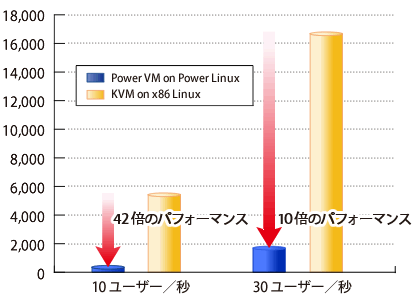
— IBM PowerLinuxが専用マシンでPower7 (CPU)の性能もありますし、IBM Java、Websphereと純正の組み合わせが功を奏したのだと思います。実際はIBMの担当者も驚いていましたが(笑)
そういえば、松岡社長も「WebSphere の起動が一瞬で驚いた」と仰っていました。あまりにも早いので、嘘なんじゃないかと(笑)
基盤は後戻りできない、アプリは後で修正できる
— では、検証が終わり、実際に構築、移設する段階に進んでいった訳ですが、移設や切り替え作業で大変だったことなどを教えて下さい。
今回は、コロケーション移設と同時にiStudyサーバアプリケーション自体もメジャーバージョンアップをしているので、基盤とアプリケーションを同時進行で作業 するのは大変でした。
— それは、チェックポイントも多いですし、緊張しますね。私も社内システムの運用管理の業務に携わっているので、お気持ちお察しします。「インフラは動いて当たり前」という認識ですからプレッシャーですよね。
はい、データセンターの作業は社長も立ち会っていたので、更なるプレッシャーでした。(笑) しかし、豊富な経験とそれに裏付けされた感があり、プレッシャー以上に安心感も大きかったです。
— さすが、現役エンジニア社長ですね。新しいテクノロジーの採用には自ら立ち会う訳ですね。
はい。話を戻しちゃいますが、とにかく同時進行は気を使いました。

本当は、基盤についてはじっくり検証、作業をして、その後にアプリやサービスの作業をしたいのです。基盤の環境構築は後戻りできないですからね、アプリは後からでも修正がしやすいですから。
— なるほど。では、今回のプロジェクトを通して、 エンジニアとして体得された事は何でしょうか?
冒頭にも申し上げたとおり、今まではKVM, Oracle VMを経験していたので、PowerVMの利用は興味深かったです。AIXの勉強にもなりました。また、今までは初期設定はベンダーに任せたり 、検証作業も部下に任せることが多かったのですが、今回は全部自分でも作業しましたので、スキルアップに繋がりました。
検証は時間をかけましたが、実際のデータセンターの切り替え作業は一晩でしたので、そういった意味ではあっと言う間でした。
インフラ担当は後手より先手が理想的
— 最後に、インフラ担当として、今後の展開、展望をお聞かせ下さい。
今回はPowerLinux/PowerVM上に柔軟性、拡張性の高い、大きな環境を作ったのですが、これからお客様を更に増やしていきたいですし、実際に増えた時に快適なリソース配分やサービスを提供できるように、もっと研究、検証を進めていこうと思っています。
— 素晴らしいですね。インフラを担当すると後手に回ってしまうことが、実際は多いと思うのですが、検証を進めて先手打つ・・・私も見習いたいです。
リソース配分で思い出したのですが、資源は1/3、パフォーマンスは10倍になった「iStudy Dynamic Cloud EE」は、利用者への利用料金も従来より安く、還元されたとのことですね。
— MERITひろばの環境も新環境に移設した場合は、利用料金安くなりますか?
そこは、担当営業に聞いて下さい(笑)
— ですよね。(笑)そうします。
本日は、移設作業直後にもかかわらず、お時間いただきありがとうございました。