
悪質化・巧妙化する一方のサイバー攻撃を始め、システムリスクは企業が直面し続けている「今そこにある危機」です。
ビジネスの中断を招かないためには、何かが起きたとしても重要な情報資産であるデータを迅速に復旧できる能力やデータ・レジリエンスが強く求められています。
しかしその一方で、予算も人的リソースも有限であり、セキュリティコストや運用工数をむやみに増加することはできません。
そうした中、IBM ではデータ・レジリエンスに特化した包括ソリューション IBM Storage Defender で、データの保護、識別、検知、対応、復旧をエンド・ツー・エンドで実現していこうと提唱しています。
本コラムでは IBM Storage Defender の構成要素や、それぞれの構成要素を企業がどう採り入れていくことで堅牢な守りを形にできるのか、を見ていきます。
また、セキュリティコストや運用工数という観点からも IBM Storage Defender の差別化ポイントを探ります。
| 目次 |
|---|
悪化の一途をたどるサイバー攻撃被害、求められているのはデータ・レジリエンス
依然としてサイバー攻撃が猛威を振るい続けています。
IBM のサイバーセキュリティの専門家と対策担当者からなる IBM Security X-Force の「X-Force 脅威インテリジェンス・インデックス 2023」によると、サイバー攻撃による被害は悪化の一途をたどっており、ランサムウェアによるデータ侵害への対応にかかる平均コストは5億9千万円に上っています。
また、データ侵害の特定と封じ込めに要した平均日数として287日にかかっており、その間、多くのシステムは停止を余儀なくされました。
さらに、Windows だけではなく Linuxシステムへのランサムウェア攻撃も増加しており、最近では VMware ESXi のサーバーまでも標的になっているといいます。
今やどんな規模の企業であっても「まさか当社のシステムが狙われることはないだろう」などと甘く考えることはできません。
ここではサイバー攻撃を例に挙げましたが、システムへのリスクは他にも自然災害やハードウェア/ソフトウェア障害、人為的ミスなどさまざま存在します。
すべてを起きないように防ぐのはもはや不可能といえます。
現代の企業には、何かが起きたとしても重要な情報資産であるデータを迅速に復旧できる能力、つまり、データ・レジリエンスというものを身につけることが強く求められています。
また、データに対しては世界的にコンプライアンス準拠への圧力が高まっており、企業はこれにも対応しなければなりません。
しかし持てるリソースは有限であり、セキュリティ強化だからといって湯水のように予算が湧くことはなく、恒常的な人材不足に悩む中、むやみに運用工数を上げることはできません。
多くの企業はこの点に大きなジレンマを抱えています。
IBM Storage Defenderはエンド・ツー・エンドでストレージを守る包括ソリューション
そうした中 IBM は2023年、IBM Storage Defender というソリューションを発表しました。
IBM Storage Defender は、ストレージ基盤全体にわたってデータの保護や改ざん防止、検知、対応、復旧、自動化を行える機能を有し、企業のデータ損失リスクを軽減することができます。
セキュリティ・ダッシュボードを備えていることも大きな特長で、データ保護とサイバー・レジリアンスのステータスをシンプルに統合して表示することができます。

図1. データ・レジリエンスを実現するIBM Storage Defender
IBM Storage Defender は、具体的に以下の8つのソフトウェアから構成されています。
IBM Storage Virtualize
ストレージリソースの一元化やデータサービスの拡張を可能にするストレージ仮想化ソリューションです。
IBM製ストレージと他社製ストレージの管理を統合でき、ストレージリソース管理の簡素化と使用率を向上します。
IBM Copy Service Manager(CSM)
ストレージ環境におけるコピー・サービスを制御する製品です。
ストレージ環境全体のレプリケーションを一元的に管理することができ、アプリケーションに対して災害復旧と高可用性を提供します。
IBM Storage Data Protect
仮想環境やクラウド環境のバックアップ・復旧を司るソフトウェアです。
SaaSポータルで問題の監視・警告・予測を行うとともに、異常検知しレポートします。
VMware のエンタープライズ保護機能を有しているという点も大きな特長です。
IBM Storage Sentinel
ランサムウェア攻撃のソースを検知/診断/特定し、主要なアプリケーションに対して自動復旧オーケストレーション機能を提供するソフトウェアです。
IBM Storage Archive
物理的なエアギャップ保護と直感的なグラフィカルアクセスの機能でデータ・アーカイブを作成します。
1次ディスクのアクセスパフォーマンスが不要なデータのストレージ・コストを削減できます。
IBM Data Management Service(DMS)
IBM Storage Defenderサービスに対するユーザーのランディングページで、包括的なデータ・レジリエンスを実現するダッシュボードです。
具体的には、Storage Protect、IBM FlashSystemセーフ・ガード・コピー、IBM Storage Data Protect と接続しデータ保護ステータスの統合的ビューとともに、ロギングやレポーティング、シミュレーションなどの機能を統合して提供します。
IBM Storage Protect for Container
Storage Protect はシンプルな構成で物理、仮想、アプリケーション、NAS と、さまざまなバックアップ対象の保護および保管方法を提供しますが、IBM Storage Protect for Container はその中でもバックアップ対象のコンテナ環境に特化しています。
IBM Storage Protect Suite
上記以外の要件のバックアップと復旧に関しては、この IBM Storage Protect Suite に含まれる多彩なソフトウェアで実現可能です。
災害復旧管理やノード複製、Network Data Management Protocol(NDMP)バックアップ、大規模テープ・ライブラリーをサポートする IBM Storage Protect Extended Edition、Oracle および Microsoft SQL Server と連携する IBM Storage Protect for Database などがあります。
必要な機能を導入しながら段階的にデータ・レジリエンスを高めることが可能
IBM製品を利用のお客様であれば、IBM Storage Defender の導入でサードパーティソリューションに頼らずエンド・ツー・エンドのデータ保護を IBM環境で統一することができます。
また IBM Storage Defender は、その時点で必要な構成を採り入れながら段階的にデータ・レジリエンスを高めていくことができます。
たとえば、IBM FlashSystem 5200アップの製品をお使いのお客様には IBM Storage Virtualize が搭載されており、このソフトウェアのみでランサムウェア攻撃によるデータ暗号化に備えるセーフ・ガード・コピーが実現できるようになっています。
ここに IBM Copy Service Manager をプラスすれば、リアルタイムに近い感覚でデータコピーを取得したり適用業務に合わせてデータの世代保存を管理するといったことも可能になります。
上記がフェーズ1だとすると、フェーズ2ではデータ・アーカイブやデータを分類するのはいかがでしょうか。
IBM Storage Archive を導入すると、法令や会社で定めた保存期間を過ぎたデータをより安価なストレージへ移すといったことが容易にできます。
これにより、メインストレージの実容量を常に気にかける必要もなくなります。
続くフェーズ3では、ランサムウェア対策をさらに強化することにしましょう。
その目的にかなうのが IBM Storage Sentinel です。
このソフトウェアを用いれば、200以上のコンテンツ・ベースの分析と機械学習技術でスナップショット・データを分析、高度なランサムウェア検知を行い、影響を受けたファイルを特定するレポートを自動的に生成します。
これにより、マルウェアがどのように広がったかやマルウェアから復旧するための最善の方法が理解できるとともに、すべてのサーバーの復旧を自動化することができます。
さらに、IBM Storage Data Protect を加えれば、バックアップデータのバックアップというセカンダリーデータ保護も可能です。
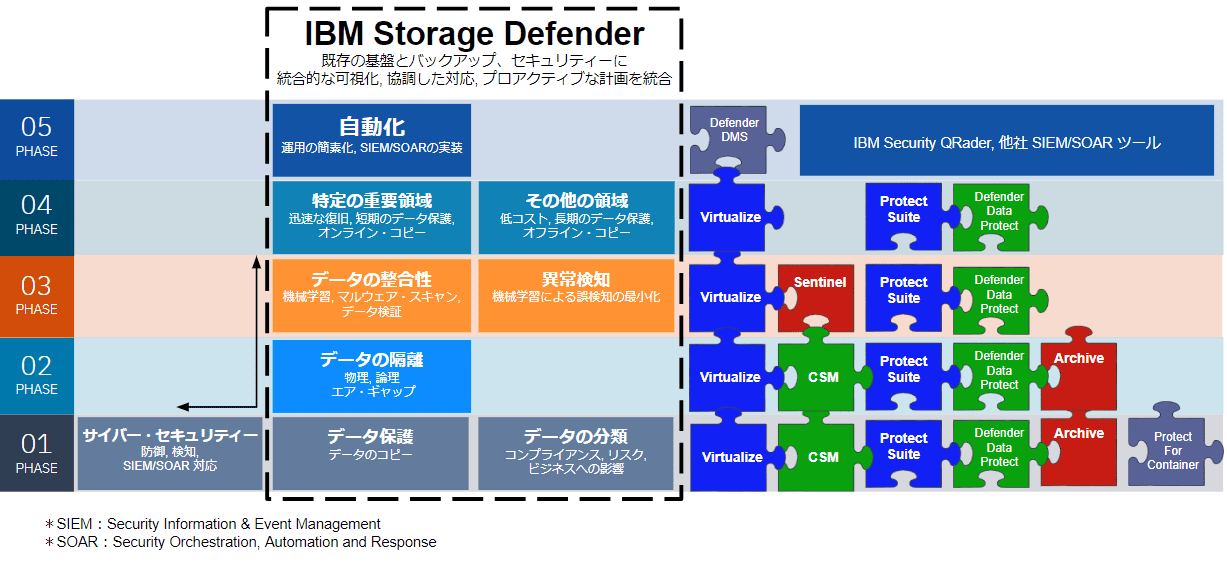
図2. IBM Storage Defenderの全体像
コスト抑制に効くライセンスモデル、運用を簡素化できる利点も特長
IBM Storage Defender は導入するソフトウェアを増やしたからといって、コストがリニアに上昇するというわけではありません。
その理由はライセンスモデルにあります。
費用は月額固定の SaaS利用料+従量課金のサブスクリプション利用料で構成され、従量課金はストレージボリューム1TiB当たりの RU やリソースユニットがソフトウェアによって重みづけされており、それを何TiB分必要かで算出されます。
計算方法は図*にあるとおりです。

図3. IBM Storage Defender ライセンス形態
ここで最も特長的なのは、購入した RU についてはその配分を選択/調整できることです。
10RU を購入し、フェーズ1ではこれをすべて IBM Storage Virtualize と IBM Copy Service Manager で使用していたけれど、フェーズ2ではランサムウェア対策を強化のため RU を IBM Copy Service Manager から IBM Storage Sentinel へ切り替えたい、といった変更も可能です。
必要な機能を必要な容量だけ、それが IBM Storage Defender です。
ちなみに、IBM では RU計算ツールを提供しています。IBMid が必要ですが、ざっとシミュレーションしてみたいというお客様はアクセスしてみてください。
(https://app.ibmsalesconfigurator.com/#/)
IBM Storage Defenderの特長まとめ
- メインストレージからバックアプストレージまでデータを保護
- オンプレミス/仮想環境/パブリック・クラウドへ対応
- データ保護、改ざん防止、検知、復旧などの機能を包括的に提供
- 様々なデータ保護機能の中からニーズに合わせて必要な機能だけを選択可能
- サブスクリプション型のライセンスにより、必要な期間だけの契約(年単位)
- 単一ライセンス形態により、ライセンスの管理を簡素化
- Data Management Service(DMS)によるシングルコントロール
IBM Storage Defender は、ストレージのセキュリティ機能強化やバックアップおよびリカバリーの強化をはじめ、データ管理の最適化、コンプライアンスと法的要件の遵守といった領域においても有用なソリューションと言えます。
バックアップ検討の際は、IBM Storage Defender を検討してみてはいかがでしょうか。
構成提案はエヌアイシー・パートナーズにお任せください
エヌアイシー・パートナーズでは IBM Storage Defender の導入に関して、正確にお客様のストレージ環境を把握した上で、RU計算ツールなども用い最適な構成立案を支援いたします。
取り扱い製品が多いため、ストレージのみならずシステム全体の最適化をめざした包括的な提案支援も可能です。
企業の情報資産を格納する重要なストレージ基盤やその保護に関してお客様が直面している課題を、当社はパートナーのリセラー企業とともに解決していきます。
お問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いいたします。