
2017年5月に世界的に大流行し、その後鎮静化していたランサムウェアの脅威が再び増大しています。
IPA(独立行政法人 情報処理推進機構)が毎年発表する「情報セキュリティ10大脅威」の組織部門においても、ここ数年、不動の第1位に君臨する「標的型攻撃による被害」の陰で「ランサムウェアによる被害」が2017年以降5位以内をキープ。
最近では多額の身代金が獲れそうな企業にターゲットを定め、データを暗号化するだけではなく機密データを窃取し、それを公開すると脅して身代金を要求するなど、標的型化の事例も報告され、高度化・巧妙化が進んでいます。
本記事では、こうした最新動向や被害の状況に触れつつランサムウェア感染からのシステム復旧を考える上で欠かせないバックアップについて、対策のポイントとそれを踏まえたお勧めのソリューションとして「IBM Spectrum Protect」を紹介します。
Index
- 企業を狙った標的型ランサムウェアの被害が増加中
- サイバーセキュリティ+サイバーレジリエンスで、ランサムウェアに多層的に対応
- まずはデータバックアップ、さらには感染を迅速に検知する仕組みを
- ランサムウェアの感染を “ふるまい検知” して通知。確実な復旧を実現する「IBM Spectrum Protect」
- 効率的なバックアップ・アーカイブ・階層管理を実現
- この記事に関するお問い合わせ
- 関連情報
企業を狙った標的型ランサムウェアの被害が増加中
2017年に登場し猛威を振るった「WannaCry」などのランサムウェアでは、無差別に送られる「ばらまき型」メールによって感染し、端末がロックされたユーザに対してロック解除のための身代金を要求するケースが一般的でした。
しかし、高額な身代金を支払える個人は少なく、攻撃者にとってあまりに非効率でした。
そこで攻撃者は対象を企業や団体に移し、特定のターゲットに対し下調べをしたうえで攻撃を仕掛けるようになりました。
2020年6月には、某国内大手自動車メーカーがサイバー攻撃を受け、マルウェアに感染。9つの工場で操業に影響が出ただけなく、コロナ禍でテレワーク中の従業員が社内システムにアクセス不能になるなど、深刻な事態に陥りました。
この事案では、ネットワーク偵察や感染経路の確保など入念な事前調査が行われていた可能性が指摘されており、まさに標的型ランサムウェアともいうべきものです。
結局4日をかけて工場の操業を再開したものの、その間工場の出荷が停止するなど、同社のビジネスにグローバルで大きなダメージを与えました。
サイバーセキュリティ+サイバーレジリエンスで、
ランサムウェアに多層的に対応
ランサムウェア感染の結果、製造業では前段で紹介した事例のように、工場の操業が止まることで利益損失に直結するほか、医療機関や社会インフラサービスなどが狙われると人命が危険にさらされたり、人々の生活に困難をきたすことも。
問題は、標的型攻撃の場合、マルウェアがひそかに侵入し時間をかけて機密情報の搾取を試みる間も業務継続が可能なのに対し、ランサムウェアに感染した場合、感染後にデータが暗号化されてしまうとデータの利用ができなくなり、一気に業務停止に至ることです。
このためランサムウェア対策では、インシデント発生を未然に防ぐ “サイバーセキュリティ” の対策だけでなく、発生したインシデントをいかに早く沈静化して本来の状態に戻すか、という “サイバーレジリエンス(セキュリティレジリエンス)※” のアプローチも必要です。
様々なセキュリティ対策で侵入を防ぎつつ、万が一侵入を許してデータが暗号化されてしまった場合に、その状態から迅速に復旧するための手段を備える “多層的な対策” が求められます。
まずはデータバックアップ、さらには感染を迅速に検知する
仕組みを
ランサムウェアの被害に対するサイバーレジリエンスを高める上で欠かせないのが、バックアップです。
ランサムウェアに感染しデータが暗号化されてしまうと、データ利用は不可能で、もしデータバックアップがされていなければ、もはや打つ手はありません。逆に言うと、バックアップさえあれば時間や工数はかかっても、システムを初期化するなどした上で感染前のデータに戻すことができます。
では、バックアップさえとっていればOKか?というと、必ずしもそうとは言い切れません。
ランサムウェアの感染を早いタイミングで検知できなければ、復旧に用いるバックアップデータが古い世代にものになってしまい、一定期間分のデータロストが発生するためです。
ランサムウェア対策を考えると、まずは高頻度でバックアップをとること(オフラインでバックアップデータを保管するのが望ましい)を基本とし、感染したことを早期に検知して、できるだけ新しいデータで復旧する仕組みがあるのが理想的です。
ランサムウェアの感染を “ふるまい検知” して通知。
確実な復旧を実現する「IBM Spectrum Protect」
ここからは、サイバーレジリエンスまで考慮した有望なランサムウェア対策の1つとして、データ保護ソリューション「IBM Spectrum Protect」を紹介します。
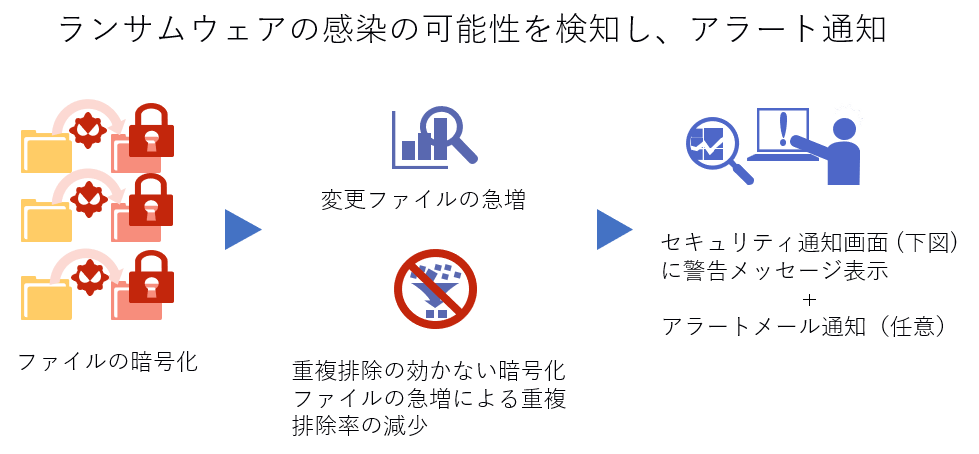
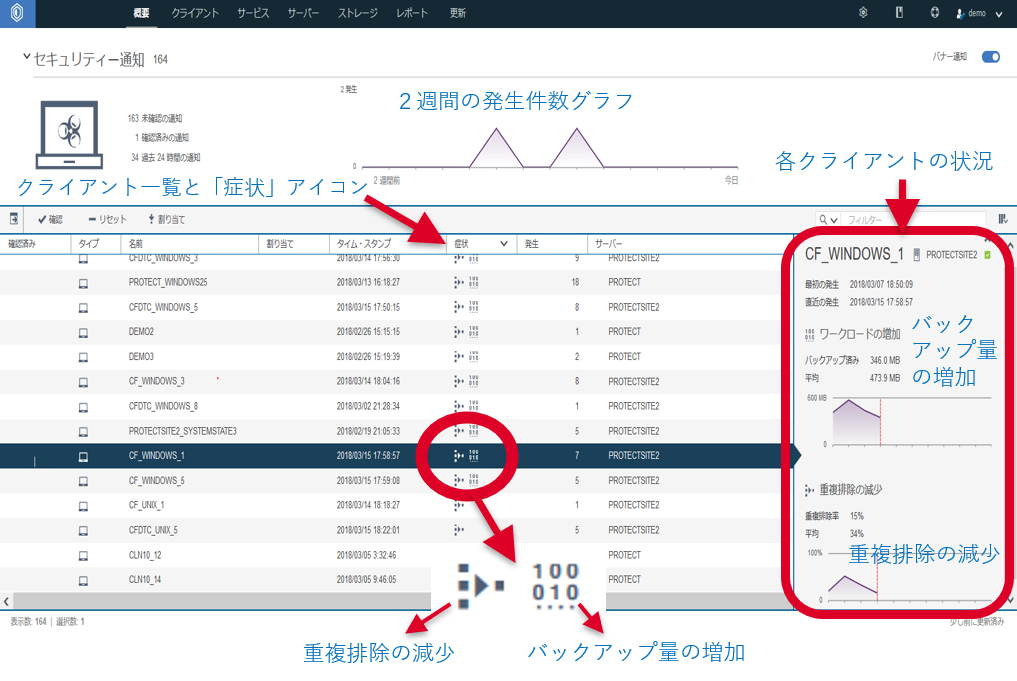
この製品(ソフトウェア)がすぐれているのは、ランサムウェアに感染したことを検知し管理者にメール通知してくれる点です。
ランサムウェアに感染すると、ファイル数やデータ量が急増する一方本来増えるはずの重複排除率が逆に減少する、といった、通常では考えられない現象が見られます。
IBM Spectrum Protect では、バックアップ対象データを統計的に分析することで、こうした平常時と異なる “ふるまい” を検知。即座に管理者へメール通知します。これによって、感染後できるだけ早期のデータ復旧が可能になります。
また、ランサムウェアによってはバックアップからの復旧を不可能にするため、バックアップデータの破壊を試みるものもありますが、IBM Spectrum Protect では、サーバーからアクセス不能な保護領域を確保し、最大500世代の増分バックアップを実現(セーフガード・コピー)。生命線ともいうべき感染前のクリーンなバックアップデータをしっかり保護し、確実なデータ復旧へと導きます。
効率的なバックアップ・アーカイブ・階層管理を実現
バックアップの対象となるクライアントと管理サーバーで構成される「IBM Spectrum Protect」は、以下のような優れた機能により、効率的なバックアップ・アーカイブ・階層管理を実現します。
1.真の永久増分バックアップで、バックアップウィンドウを最小化
定期的なバックアップデータの合成で、フルバックアップを更新する他社の永久増分バックアップと異なり、「IBM Spectrum Protect」の永久増分バックアップはフルバックアップの取得は初回のみで、その後は増加した分のバックアップだけで OK。
バックアップの合成にともなう時間とシステムリソースの消費を回避できます。さらに、複数のバックアップサーバーに存在する同一データをブロックレベルで 1つにまとめ(重複排除)、ストレージ容量の削減に貢献します。
2.高速転送機能で、低品質WAN環境でも安定的なデータ転送を実現
永久増分バックアップと重複排除により遠隔地バックアップの時間短縮を実現する「IBM Spectrum Protect」ですが、標準搭載の高速転送機能(Aspera Fast Adaptive Secure Protocol)は、海外など脆弱なWAN環境においても安定した高速転送を実現します。
3.オンプレミスだけでなく、クラウド環境も含めた統合バックアップ
オンプレミス環境(物理・仮想)はもちろん、クラウド環境も含めて統合的にバックアップを管理できます。
しかも、上りのデータ転送料が無料というメリットを活かし、長期保存のデータをクラウドにバックアップ(アーカイブ)したり、オンプレミス←→クラウド間のレプリケーションで DR環境を構築する、といった活用シナリオに対応します。
このほか「IBM Spectrum Protect」は、バックアップ対象の複数サーバーを単一ダッシュボードから統合管理できるオペレーションズ・センターを提供。
管理者は場所を問わず、必要な時にブラウザ上で各種バックアップの実行や健全性の確認などが可能。「コロナ禍で、バックアップのために出社するのは避けたい」「リモートでバックアップ状況を把握・管理したい」といったニーズにも対応します。
ランサムウェアの対策として、またニューノーマル対応のデータ保全・バックアップ対策として、この機会に「IBM Spectrum Protect」を検討してみてはいかがでしょう。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- DRで考えるべきITシステム復旧の3つの指標と、実現方法を解説。BCPとの違いは?効率的な対策は? (コラム)
– 近年、大規模な自然災害が増加していることから DR の重要性が高まっています。今、改めて押さえておきたい DR の基本・指標と、実現するための方法とは? - データを守るということについて (ブログ)
– 様々な脅威からどうやってデータを守るか、という内容でお届けします。