
皆さま、こんにちは。てくさぽBLOGメンバーの佐藤です。
前回「【てくさぽBLOG】超簡単データ分析!H2O Driverless AIを使ってみた」にて、H2O Driverless AI(以下 Driverless AI)のご紹介をしました。
今回は、Driverless AI の第二弾として競馬の予測(回帰分析)に挑戦しました。
*連載の続きはこちら(2020年7月13日公開)
「【てくさぽBLOG】H2O Driverless AIをIBM Power System AC922で動かして予想する(その2)」
背景
AIは社会的に非常に注目されています。
AIを利用するためにはデータを元に学習させて、学習モデルを元に予測精度がどの程度なのかをテストすることになります。
サンプルデータはGit等たくさんあるので、学習と”予測できた”という結果は確認できます。
予測結果が実用性があるレベルなのか?何か具体的なデータで予測と実際の結果と照らし合わせて検証してみたいと考えました。
尚、弊社ではDriverless AI PoC環境として、IBM Power System AC922 がありますので今回はこちらの環境を利用して、テストしてみたいと思います。
こちらのブログを読んでぜひ試してみたいという方は以下リンク先よりお申込みください。(要会員登録)
IBM AIソリューション PoC環境ご利用ガイド
今回の目的
回帰分析(データに基づいた予測)の機能を備えるDriverless AIを使って、予測が有用かどうか検証します。
何を予測するか
予測に適したデータは何か?を探したところ競馬についてはかなりしっかりしたデータが公開されておりかつ実際に順位という結果が出るため、テスト対象に向いていることがわかりました。
AIの検証ネタとしても複数の方が挑戦されていますし、過去に競馬AIコンテストも開かれたようです。
データを探す
まず、予測に用いるための競馬データについて調査しました。
競馬のデータについて配信を行っているのは主に3つあります。
1.JRA-VAN DataLab.
JRA公式のデータ
30年分のデータがある為、データ量は一番豊富
2.netkeiba.com
競馬ファンのための情報サイト
人が使うためのコンテンツが多く、動画配信等も充実
まとまったデータでの配布はない模様で、今回の用途には向いていない。
3.JRDB
基本的に競馬に関するデータを提供しているサイト
調教データ等、データの種類は一番豊富
詳細は割愛しますが、JRA-VANはデータの変換に手間がかかるため、JRDBを使用することにしました。
手順
Driverless AIで回帰分析をするには5つのSTEPがあります。
十分な結果が得られれば1回で終わりますし、もう少し精度が必要の場合は再び1に戻ります。
順を追って説明します。
1.データの準備
2.回帰分析
3.予測
4.検証
5.考察(考察結果をもとに必要であれば1へ)
1.データの準備
Driverless AIが受付られるデータはテキストデータになります。
データの受け渡しについてはクラウド連携が可能です。
Driverless AIとして受付られるテキストファイルは複数ありますが、今回はCSVファイルを準備することにします。
アップロードについても一番簡単なローカルからのドラッグアンドドロップで行います。
JRDBはlzhファイル形式で配布されていますが、T#というツールを使うとCSVに吐き出してくれますのでこちらを利用します。
T#は日付毎にCSVファイル出力されますので連結して解析するデータを作成します。
CSVの連結についてはコマンドプロンプトでtypeコマンドを利用しました。
今回は2010年1月5 日~2020年1月5日までのデータを連結して分析元のデータとします。
抽出するデータの項目ですが、私自身競馬に詳しくないこともあり項目については何が有効なデータか不明ですので集められるだけ集めました。
データとしては99列、50万行の規模です。
CSVファイルで340MB程あります。
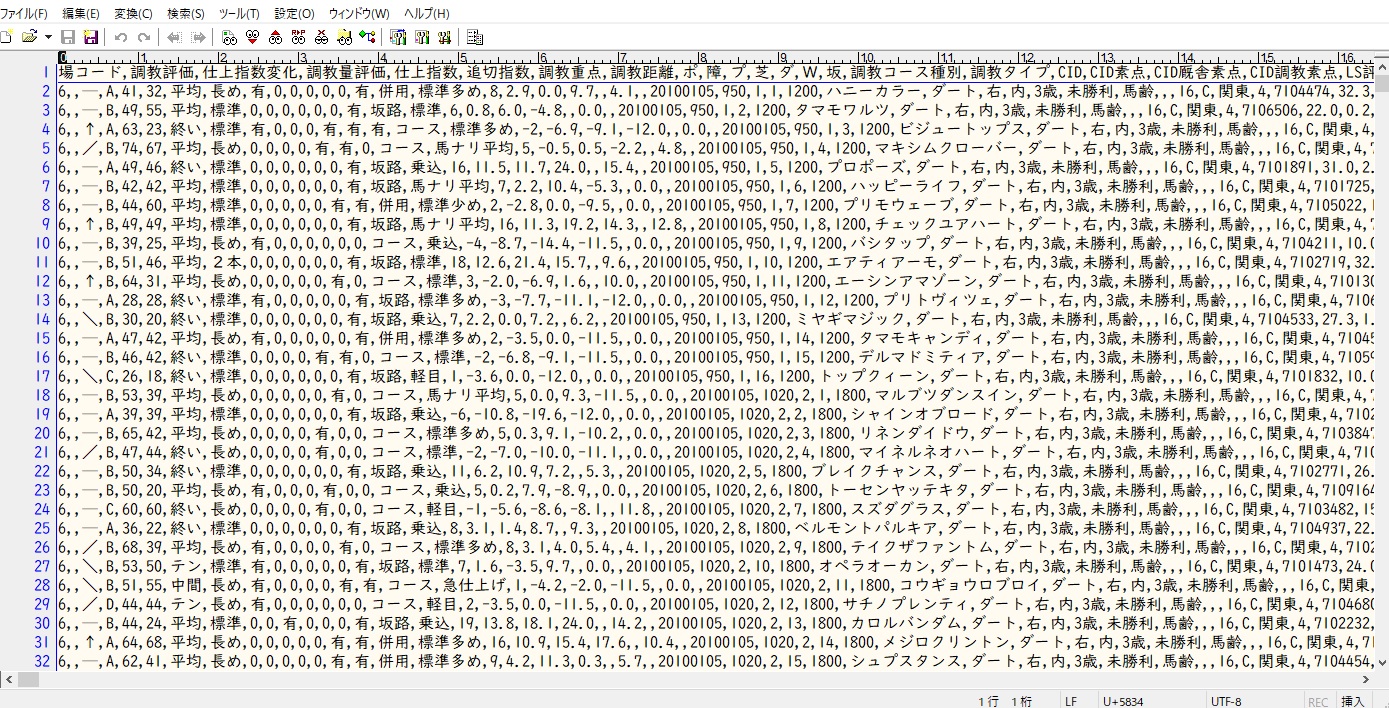
データ自体はこのような感じです。
Driverless AIのメリット
回帰分析するデータについてDriverless AIのメリットを挙げておきます。
関係ないデータを回帰分析にかけても大丈夫
予測したいデータに関係ないデータは自動的に解析の対象から外します。
Driverless AIの場合、予測に有用なデータかそうでないかを選別する必要はありません。
とにかくよくわからなくても入れておけば大丈夫です。
データに歯抜けがあっても大丈夫
Driverless AIはデータがすべてそろってなくても実行することができます。
ただし歯抜けがあまりにも多いと自動的に除外されます。
自動で判断してくれますので手作業は不要です。
データの型を指定しなくて大丈夫
一般的にデータを読み込ませるという事をする場合は文字列なのか、整数なのか、日付なのか、データの型を指定する作業が必要になるケースが多いです。
Driverless AIはデータの型を自動判別してくれますので、型指定する必要はありません。
また、手動での指定も対応しています。
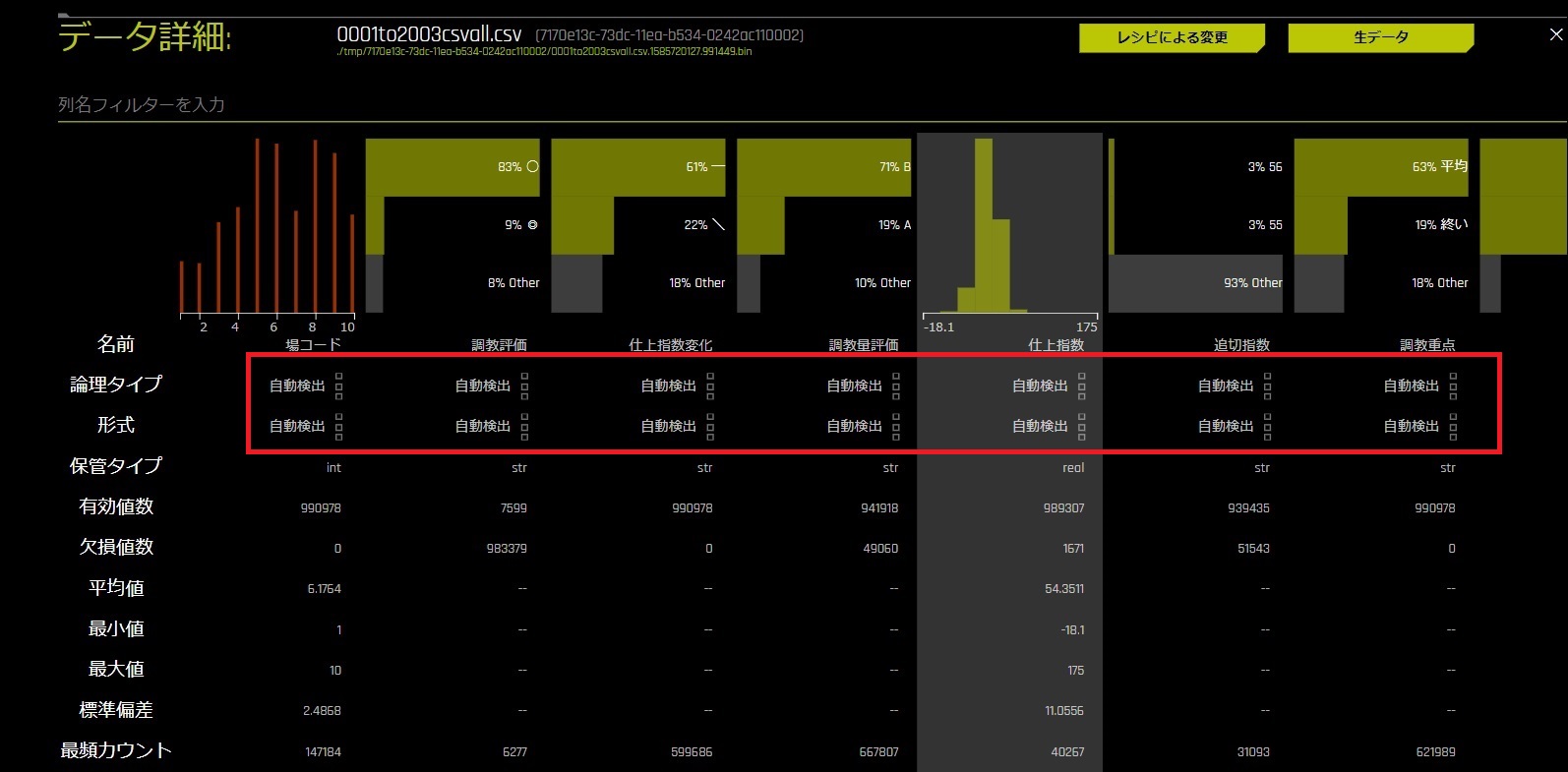
項目が自動認識となっています。
データの注意点
解析元データの注意点を上げます。
予測は1項目のみ
Driverless AIの予測は一度に1列、1項目のみとなります。
複数項目を同時に予測はできません。
予測以外のデータは埋まっている必要がある
予測をする場合は予測項目以外の列は基本的に埋まっている必要があります。
今回のケースの場合、分析元データにレースをしないとわからないデータ、レース走行タイム系は含めることができません。
レース前に判明する調教時のタイムは使うことができます。
文字コードはUTF-8のみ
Driverless AIは文字コードがUTF-8でないと文字化けします。
JRDBの配布データはS-JISのため、テキストエディタやエクセルを使用してUTF-8で保存しなおす必要があります。
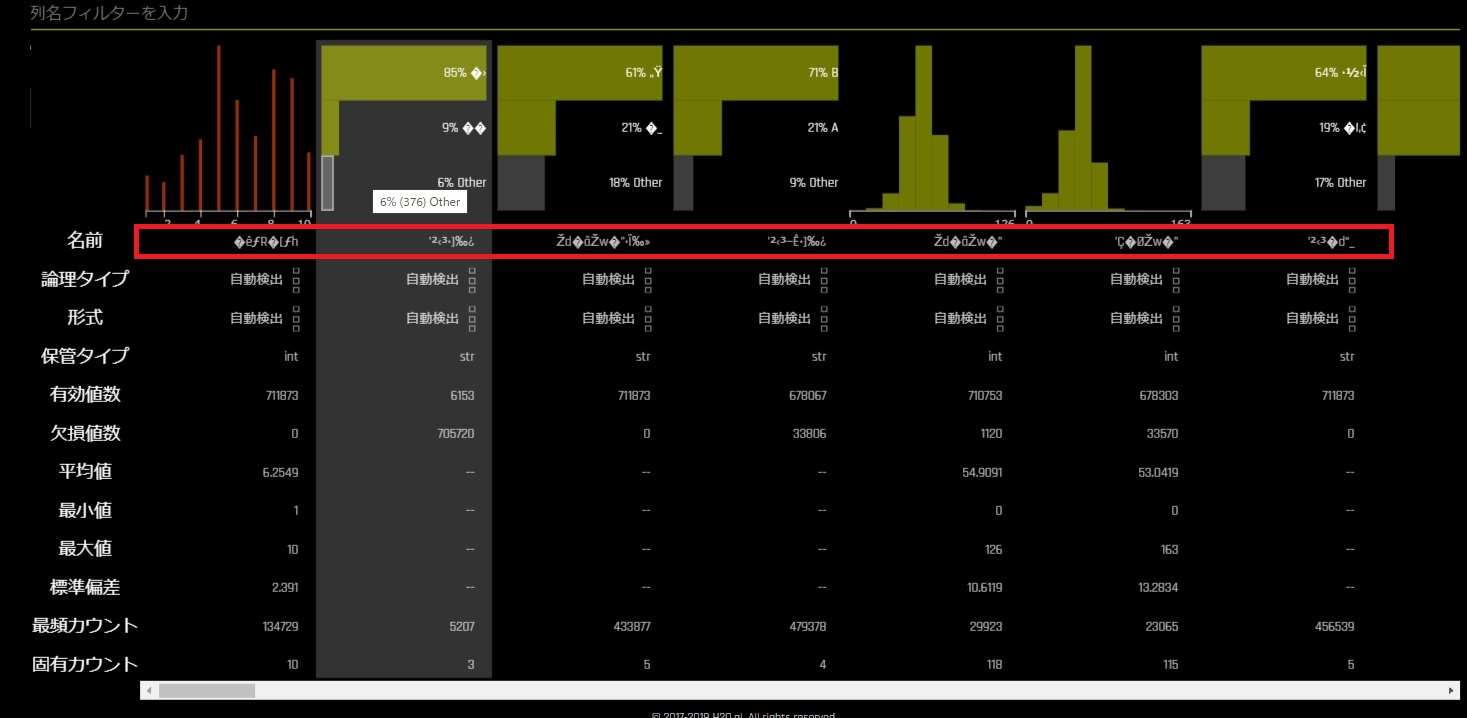
S-JISだとこのように文字化けしてしまいます。
2.回帰分析
Driverless AIにログインし、データのアップロードが済んだら、回帰分析をします。
Driverless AIのパラメーターですが、自動的にスコアラーがRMSE選択されますが今回はMAEに変更します。
スコアラーは評価指標と呼ばれるもので、どういう指標で回帰分析してほしいか?で選択をします。
例としてRMSEとMAEの違いを挙げます。
数式や細かい説明については、いろいろなサイトで詳細な解説があるので、今回はかなり簡単に説明します。
MAE
MAEは単純な当たりはずれ精度になります。
比較的精度がでます。
一方はずれ度合いについては評価しないため、当たりはずれの落差が激しい傾向が出ます。
RMSE
RMSEは当たり、外れの差分をできる限り減らす評価となります。
単純な当たりはずれの精度だけでなく、外れた場合の外れ度合いも評価します。
例えば売り上げ予測といった数値予測の場合、精度が80%であっても、売り上げが100と予測したのに実際は1だった
という大きな外れが発生しては困るといった場合に利用します。
当たりはずれの幅が少ない評価となります。
傾向としてMAEより精度が落ちます。
RMSEは データと結果の相関が強いデータでないと精度が出ないため、今回は予測する値がよりはっきりしやすいMAEに設定します。
どちらが正解という事もないため、このブログを参考に試される方は両方試して比較されるのもよいかと思います。
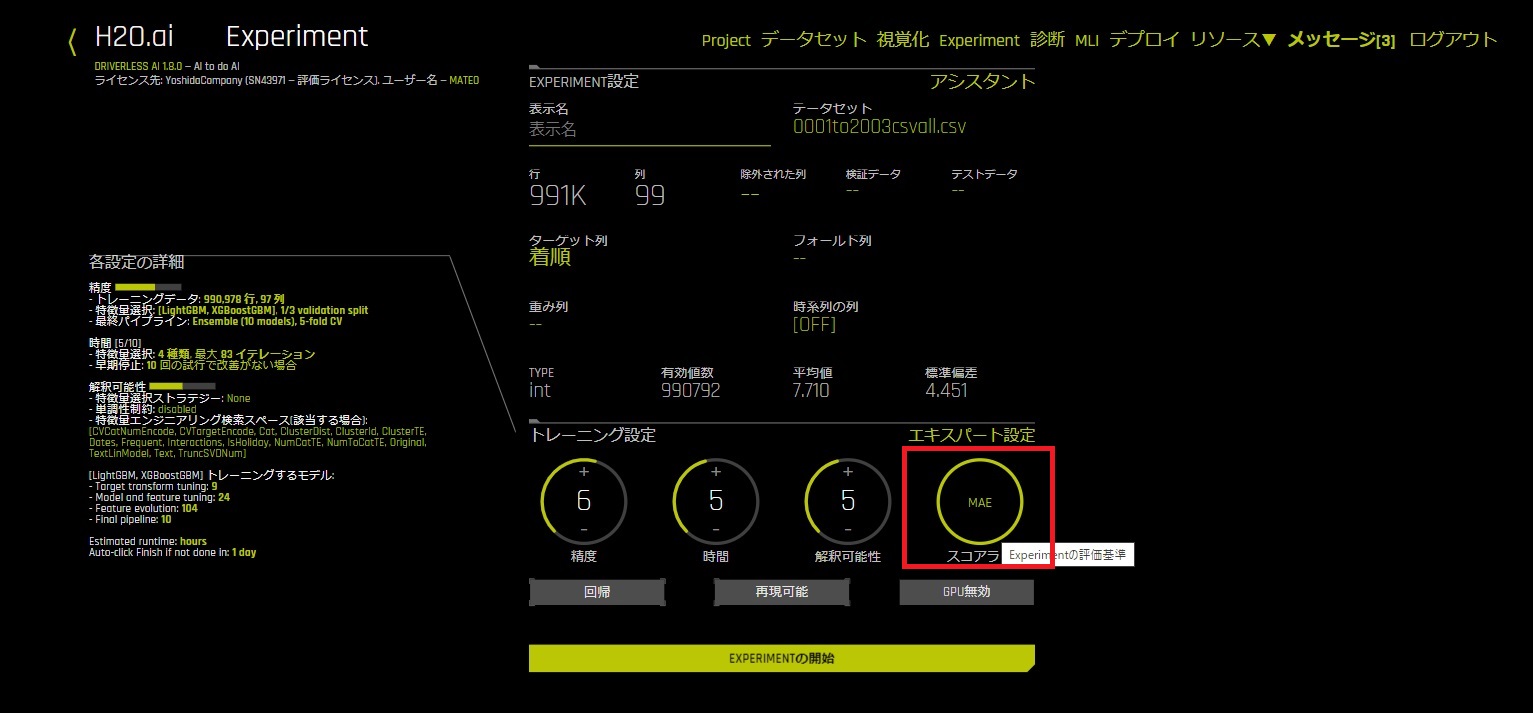
MAEを選択した状態
回帰分析をしてみてDiriverlessAIについて印象的なポイントをあげます。
全自動
とにかく全自動で解析してくれることです。
何もしなくてもとりあえずとにかくやってくれるというのが非常にメリットです。
傾向分析
傾向分析なんてエクセルでもできるじゃないかと思われる方もいらっしゃると思います。
Driverless AIのなにがすごいか?
99列の中から相関関係がある列を自動的に抽出し、相関のないデータは除外します。
次に、x列がy%の影響度があるという、具体的な数値で相関を出してくれます。
さらには、x列のデータのうち、外れ値を除く数値の範囲だけ相関があるといった一部だけ抜き出して有用といったものも判断してくれたり、それら複数を組み合わせたりして予測したい値に対する相関を様々な組み合わせやアプローチで試してしてくれます。
同じことをエクセルでやってみることを想像してみてください。
負荷が高い
自動で処理してくれるかわりに、非常にCPU負荷が高いです。
データ量にもよりますが、高い負荷が長時間続きます。
負荷状況を見ますと、Driverless AIはGPUも利用しますが、基本はCPUでの処理となりますので、優先度としてはまずはとにかく高速なCPU、次にGPUとなります。
今回、PCやクラウド環境とも比較しましたが結果はどの環境でも出ますが、処理能力が少ないと完了までの時間がとてもかかりますので、やはり運用するのであれば専用機が1台欲しいところです。
今回テストする環境のスペック
8335-GTH
Power9 40Core 2.4GHz~3.0GHz 160スレッド
メモリ1024GB
NVIDIA V100 16GB ×2
960GB SSD ×2(RAID1)
というシステム構成となっております。
x86CPU(Intel/AMD)は1Coreあたり2スレッドになりますが
IBM Powerの優れたポイントとして、1Core当たりのスレッド数が”4”となります。
やみくもに増やしているわけではなく、1Coreあたりのパフォーマンスが高いため実現しているテクノロジーとなります。
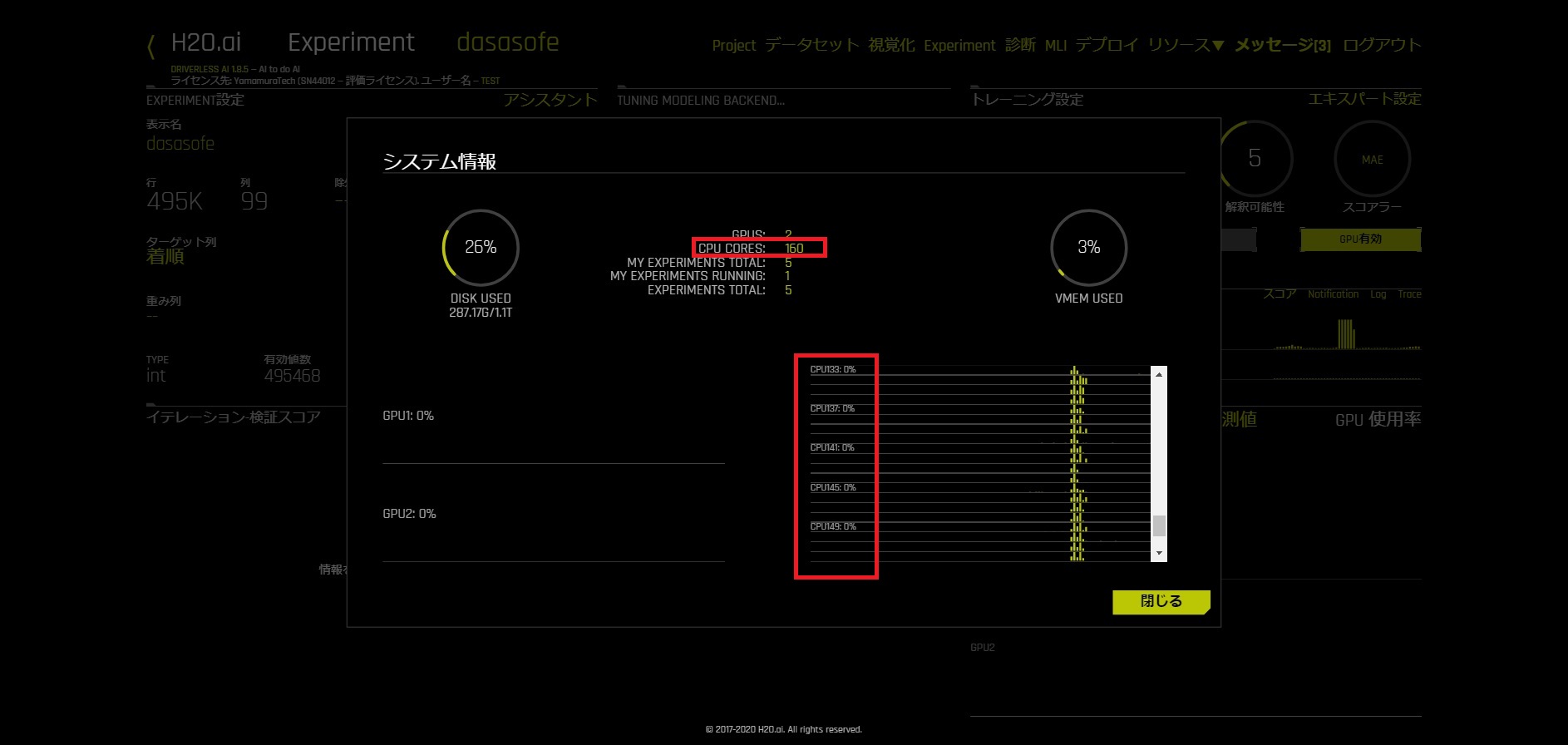
160Core(!)の画面ショット(Driverless AIはスレッド数=Core数と認識)
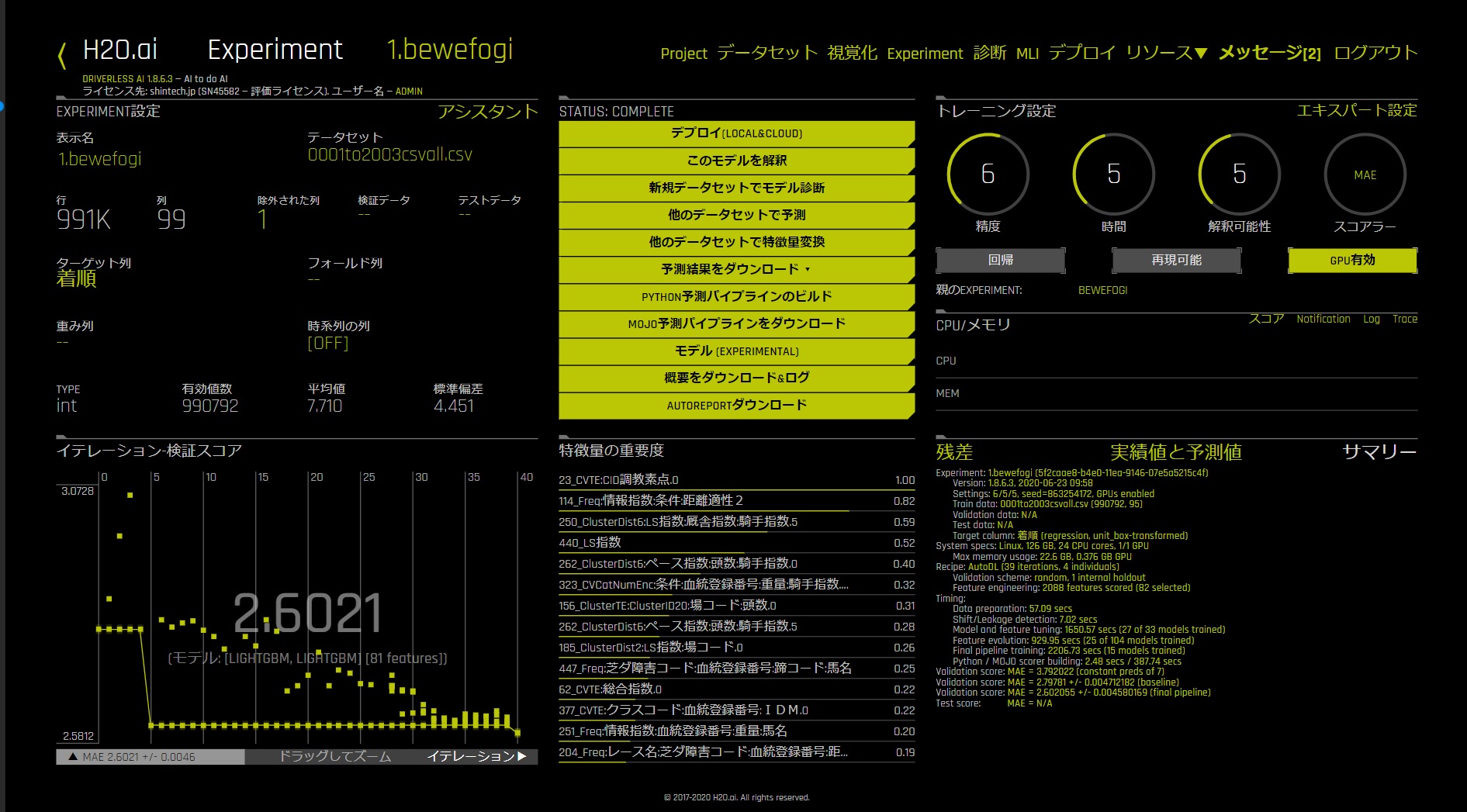
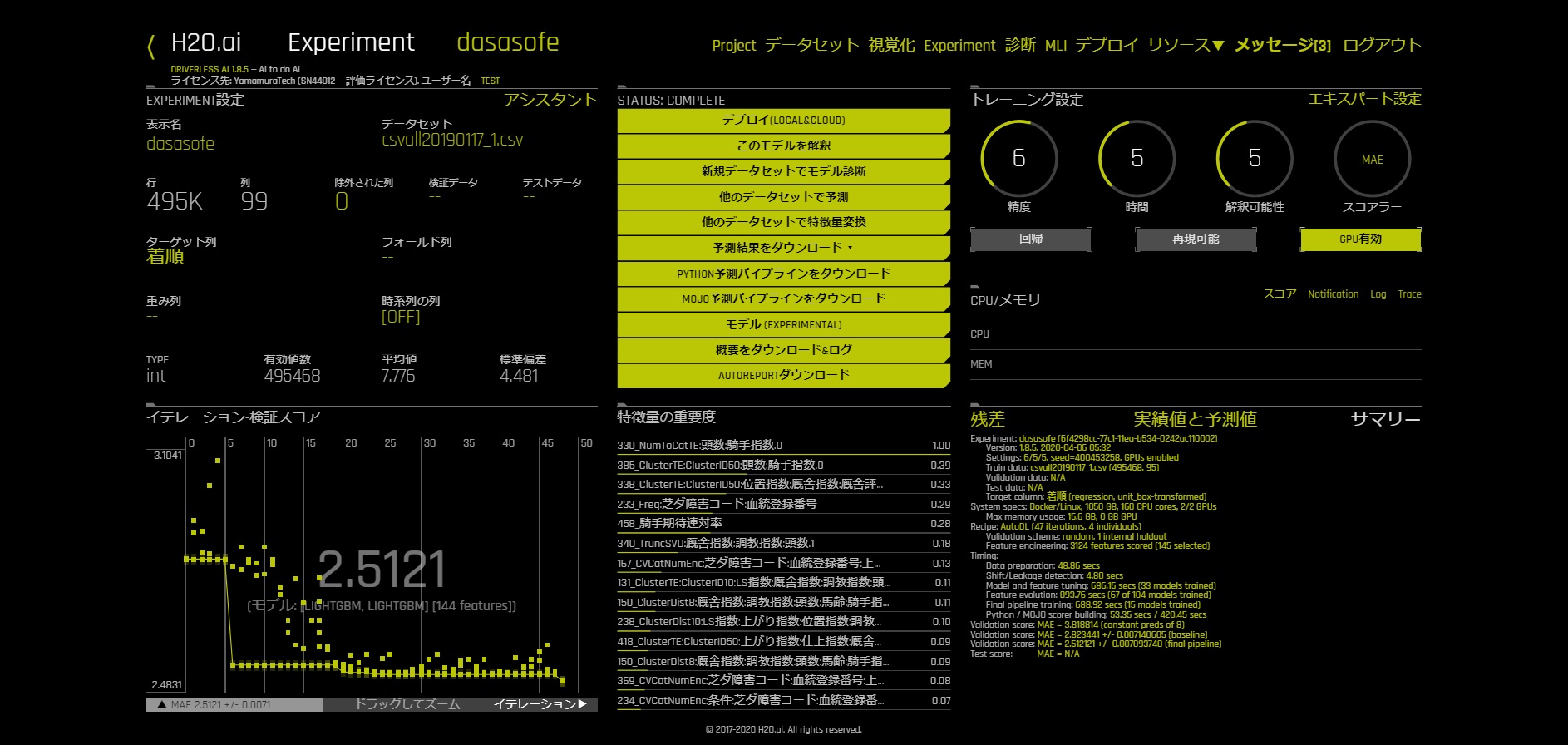
今回のデータの場合、テスト環境ではパラメーターをデフォルト設定で約50分で終了します。
完了するとこのような画面になります。
これで予測の準備が整いました。
{kind=link}
長くなりましたので、次回、予測をして内容について検証します。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp