
座談会:画像認識だけじゃない!ディープラーニングの「使いどころ」とは?
AI、ディープラーニングが注目を集めているが、AI のビジネス活用は、「何ができるのか」から、具体的に「何をするか」という実践のフェーズに入ってきた。とはいえ、多くの企業は必要性は感じつつも、「使いどころ」が明確にイメージできていないのが現状だろう。
そこで今回は「ディープラーニング」にフォーカスし、日本IBM の ITスペシャリストの藤岡 英典 氏、頼 伊汝(らい・いる)氏とエヌアイシー・パートナーズの久田 修央 氏に、ビジネスのユースケースや活用のポイントについて聞いてみた。
 |
| 右から日本アイ・ビー・エム システムズ・ハードウェア事業本部 先進テクノロジー・センター 頼 伊汝氏、藤岡 英典氏、 エヌアイシー・パートナーズ 企画本部 企画推進部 久田 修央氏、ビジネス+IT編集部 松尾 慎司氏 |
ディープラーニングは「人間の認識レベル」を超えている
まず、AI の現状について、企業における認識の変化などで感じることを教えてください。
藤岡氏:我々がお客さま先に訪問して感じるのは、「AI で何ができるのか」「何に使えるのか」がまだ明確になっていないケースです。AI は注目されているものの、自社の業務にすぐに活用できるというイメージを持っている企業はまだまだ多くないと感じます。
久田氏:AI という言葉が社会に浸透してきて、企業は取り組む必要性を感じています。一方で、高かった期待値の反動というか、「自分たちに今できることは何か」を冷静に見極めようと考える企業が多いように感じます。
では、AI で何ができるのかについて、改めて現状を整理してください。
頼氏:人工知能は「汎用型人工知能」と「特化型人工知能」に分かれます。汎用型は、人と同じような知能を備えた人工知能で、残念ながらこれはまだ実現できていません。 一方、特化型は、ある特定の領域、分野において人間より優れた知能を持ったテクノロジーのことです。コンピューター囲碁や将棋、自動運転、画像認識といった先端事例を目にする方も多いでしょう。 ルールが決まっている、プログラミングできる特定の領域で、大量のデータを学習することで、人間よりも高いパフォーマンスで正解を導き出そうというテクノロジーといえます。
AI というと、テクノロジーの変化が早く、また、マーケットにはさまざまな用語が飛び交い、そこが混乱を招いている側面もあります。そのあたりを整理していただけますか。
頼氏:人工知能は、1960 年代に提唱され、人間の知能を再現するためのソフトウェアや、ロボティクスなども含む幅広い学問の分野です。その中の 1 つのテクノロジーが機械学習。これは大量のデータからパターンをみつけて、未来を予測していくものです。そして、機械学習の 1 つの手法がディープラーニングで「IBM Watson」(Watson)は、機械学習とディープラーニングの双方にまたがっています。
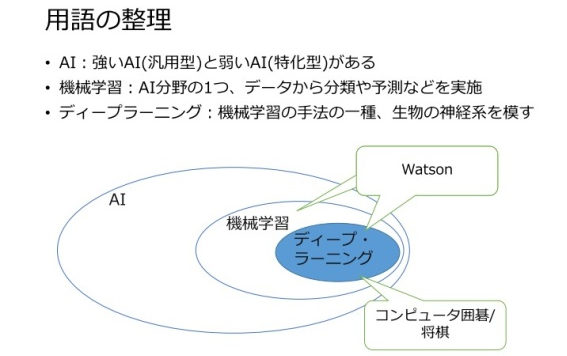 |
Watson は PaaS としての「IBM Bluemix」上で動作し、自然言語処理、画像認識などの技術を用いて、様々な機能を API として提供しています。ディープラーニングは Watson の基礎技術の 1 つです。
ディープラーニングについて、もう少し詳しく教えてください。
藤岡氏:次の写真を見て欲しいのですが、この中で、写っているのが「唐揚げ」でないのはどれだか分かりますか?
 |
ぱっと見たところでは難しいですね。どれも唐揚げに見えます。
藤岡氏:実は、唐揚げでないのは【2】なのです。写っているのは犬(トイプードル)ですが、このように人が誤認識してしまうかもしれない画像を、正しく認識できることが期待されています。
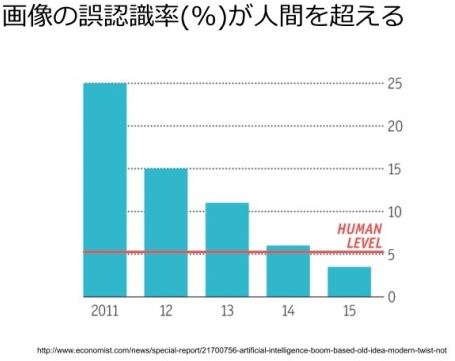
最先端の画像認識技術を競う世界的なコンテストがありますが、2011 年までは、画像認識のアルゴリズムは機械学習のロジックを用いるのが主流で、誤認識率は 25 % あたりが限界値だと思われていました。
これが、2012 年のコンテストでディープラーニングが登場し、一気に 15 % くらいまで、誤認識率が 10 % ほど改善したのです。その後、さらにテクノロジーが洗練され、2015 年の段階で、誤認識率は 5 % 未満に達しました。
人間の誤認識率は平均で 5 % といわれます。すでにディープラーニングは人間の認識レベルを超えるところまで進化しているのです。
 |
すでに製造業の工場や、サービス業などでディープラーニングの活用事例が出てきた
では、実際に、ディープラーニングで何ができるのか、もう少し詳しく教えてください。
藤岡氏:AI のゴールは「人間の知能の代わりになること」にあり、特に、知覚、ビジュアルに関する領域でユースケースが広がってきています。たとえば、画像や映像の中に何が映っているかを検出し、それをカテゴリー分けする技術などがあります。
人が物体を見て「何か」を認識、判断するプロセスは、それまで経験してきた膨大なデータ(記憶)から照らし合わせて判断しています。これが 1 つの学習です。AI も同じで、膨大な画像データから、ものの色や大きさ、形状などさまざまな要素を照合し、「これが リンゴ である」と区別しています。
また、画像の一部が欠損している場合に、人間は頭の中で「そこに何が写っているか」を補うことができますが、機械も同じようなことができます。
そうしたことが実現できると、どんなメリットがあるのですか。
藤岡氏:これまでの機械学習は、たとえば、「目が 2 つあって鼻と口があるのは人間ですよ」というように、正解(特徴)を人間が定義する必要がありました。正解を人が機械に教える必要があるという意味で、これを「教師あり学習」といいます。ディープラーニングはそれをしないで、人工知能自身が記憶を洗練させていくことができる特徴があります。
頼氏:これまでの機械学習とディープラーニングの大きな違いは、扱えるデータ量です。従来の機械学習な得意な領域は数値データ。たとえば、小売店でこういう商品が売れた、その傾向から、このお客さまにはこの商品も売れるのではないか、と予測することです。
過去のデータから予測するので、入力する特徴量がシンプルなのです。
一方、ディープラーニングは、画像や音声、テキストといった非構造化データを扱うことが得意です。たとえば、画像は同じ犬の写真でも、複雑で、1 つとして同じ画像がありません。そうしたデータから正解を予測するのは難しく、上述した通り、これまでは誤認識率が高かったのです。
ディープラーニングにより、煩雑なデータに対しても、高い正解率が期待できるようになりました。
では、実際の事例について教えてください。
頼氏:画像認識については、ディープラーニングを用い、半導体などの製造ラインで、傷やゴミ、汚れなどを判別し、不良品を検出する事例や、工場に限らず、高層ビルやダムなど、人が立ち入りにくい場所にある構造物のひび割れなども、ドローンなどと組み合わせることで、より高精度で効率よく検出できるような事例が出てきています。
実際に、国内企業でディープラーニングの取り組みは進んでいるのですか?
藤岡氏:国内でも徐々に事例が出てきました。ある損保企業では、自動車保険を乗り換える顧客が保有するさまざまな保険証、車検証などを画像データでもらい、色んな会社の書式をディープラーニングで学習することで、契約時の手入力を省力化する業務効率化のツールとして活用しています。
別の会社では、人の視覚を肩代わりして、熟練したエンジニアの作業を代わりに行うとか、熟練エンジニアの作業を学んで、スキル移転のツールに使うといった事例もあります。
企業にディープラーニング活用を提案する立場として感じることはありますか?
久田氏:ディープラーニングには大きな可能性を感じます。今は代表的な分野として画像認識に注目が集まっていますが、ビッグデータの時代に、データの組み合わせで色々な発想、可能性が広がってくるでしょう。
ユーザー企業に提案する立場としては、お客さまのビジネスに今、何が求められているかを考えることが、AI のユースケースを広げていくことにつながると考えます。
導入には「正しい教師データ」が不可欠。ハードウェアの整備とあわせて進めたい。
では、企業がAI活用をうまく進めていくためのポイントはどこにありますか?
頼氏:正しい教師データがあるかどうかがポイントです。一般的な数値データであれば、既存の機械学習の手法で、いいスコアが出ることが期待できます。しかし、ディープラーニングは、先のクイズの”唐揚げ”のような画像や動画といったこれまで分析対象ではなかった非構造化データが必要です。
教師データを整備するには、大量の非構造化データをどう溜め、整理するかという課題もあります。
頼氏:分析の精度に関わるのはデータ量で、画像であれば枚数が多ければ多いほどよいです。
久田氏:そう考えると、データを溜める「器」が重要で、サーバやストレージといったデータセンターの整備が欠かせません。
ディープラーニングを取り入れるに際して、導入ステップというか、環境作りをどう進めるかを教えてください。
頼氏:サーバやストレージの他にはポイントは 3 つ あります。 1 つ は「GPU マシン」で、ビッグデータ解析が可能なコンピューティングパワーが必要です。
2 つ目は「フレームワーク」。ここでいう「フレームワーク」とは、ディープラーニングの分析モデルをパーツ化したもので、これを組み合わせる知識が必要です。そして、3 つ目はそのための「プログラミング」スキルです。
最近は、サービス化されたフレームワークも出てきており、分析モデルを指定してデータを投入すれば、学習結果を出力してくれるサービスが出てきています。その意味で、昔に比べると非常に環境構築はやりやすくなりました。
とはいえ、導入のハードルはかなり高いように感じます。
藤岡氏:IBM では、上述したフレームワークを使いこなせるスキルがなくても、画像を入れれば学習結果を返してくれるサービスを開発しています。これが、ノンプログラミングで、既成の学習パターンで学習してくれるサービス「AI Vision」です。これは「データの準備」「モデルの作成」「モデルの学習」「モデルの利用」の 4 ステップで活用できます。
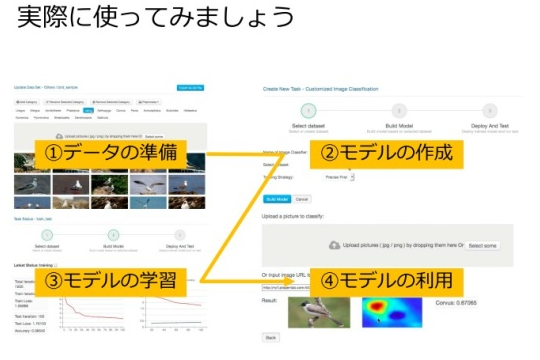 |
画像をアップロードして、学習モデル(例えば、鳥の画像を分類するというような「タスク内容」)を作成すれば、学習結果が得られ、さらにそれを API として利用できるようになるものです。 API は Web で広く使われているREST API に対応しており、例えば、モバイルアプリと連携することも可能です。
ハードウェアのコスト感はどの程度でしょうか?
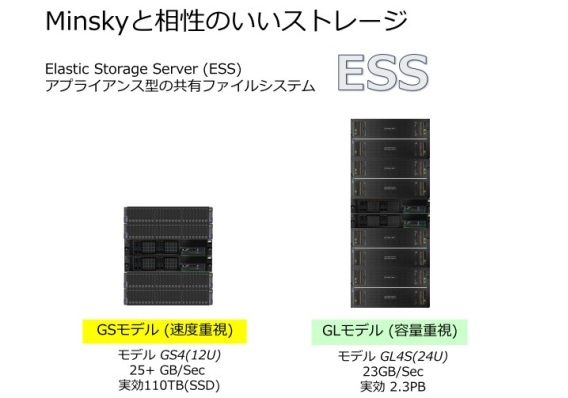
藤岡氏:IBM では、GPU を積んだディープラーニング専用のハードウェアを推奨しており、ディープラーニング用のサーバとして「Minsky」を用意しています。
 |
GPU を搭載し、画像等のデータを大量に処理する場合に、GPU と RAM の通信を高速化する「NVLink」に対応しています。提供価格 400 万円からで、Minsky と相性のいいストレージ」「ESS (Elastic Storage Server)」を組み合わせれば、並列に分散処理を行う環境を構築することもできます。
 |
最後に、今後、AIやディープラーニングはどう進化していくと思いますか?
藤岡氏:画像以外の領域としては、IoT のセンサーデータから機器のメンテナンスタイミングを予測する予兆分析などにディープラーニングが活用されるようになるでしょう。
あるいは、音声データから文章を要約、テキストを自動生成することや、広告のキャッチコピーを学習して、コピー文案を考えるといった領域での活用が期待されます。
頼氏:これまではロボティクスと AI を結びつけるのは難しいことでした。今後は、例えばディープラーニングの画像認識でモノを認識し、そのモノにあったつかみ方を判断することで、ロボットアームが最適なピッキングをする、というように、AI が現実世界に対してインタラクションするケースが増えてくるでしょう。
久田氏:こうした先端事例が増えていく中で、まずは「AI Vision」のように、お客さまにはディープラーニングに実際に触れる体験をしていただき、弊社でも新しい技術、製品に習熟していくことで、パートナーと一緒に、お客さまのビジネスに最適な提案、ユースケースを考えていきたいです。
本日は、貴重なお話をありがとうございました。
当セミナーの”動画”は、以下にて公開中です。あわせてご視聴ください。
[ダイジェスト動画公開] 7月13日【NI+C P主催】Webセミナー「Watson の基礎技術 今のビジネスに活かせる AI / ディープラーニング とは?」 ~ 繰り返しますが”今”です ~
[動画・資料公開]7月13日【NI+C P主催】「Watson の基礎技術 今のビジネスに活かせる AI / ディープラーニングとは?」~ 繰り返しますが”今”です ~(MERITひろば)
※ビジネスパートナー専用サイト(MERITひろば)のコンテンツです。ログイン or 新規会員登録が必要となります。
ご参考情報
◆製品発表情報
【新製品発表】 HPC 用 Linux モデルIBM Power System S822LC (8335-GTB)
◆技術情報
“Minsky” POWER8 NVLink Server (日本情報通信株式会社サイト)