
皆様こんにちは。てくさぽBLOGメンバーの瓜谷です。
今回はLenovo社製のSystem xサーバーについてご紹介します。
また、2016年4月19日付けにて発表されております
x3550 M5/x3650 M5の新サーバーについて少し掘り下げてご紹介させていただきます。
1.Lenovoサーバーラインナップ
早速ですが、「Lenovo System x サーバーラインナップ」を見てください。
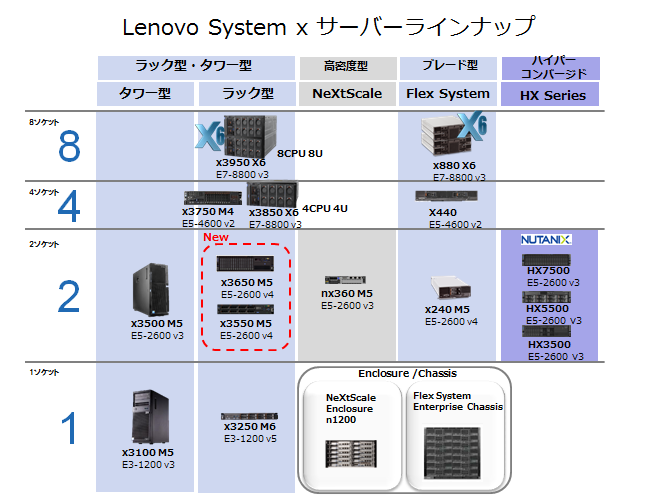
Lenovo System x 製品のサーバーは、大きく分けて下記の4つの種類に分けることが出来ます。
(背景色の同じ所は、同じ種類のサーバーとなります。)
①.タワー型・ラック型
②.高密度型
③.ブレード型
④.ハイパー・コンバージド
これだけではよくわかりませんね。
種類別にどんな特徴があるのか?どんな場合に使用されるのか?種類毎に少し見ていきましょう。
①.タワー型・ラック型
サーバーといえば、タワー型・ラック型のサーバーをイメージされると思いますが
”その通りです!” 4つの種類で一番販売されている売れ筋の製品です。
そのため少し詳しく見ていきます。
タワー型・ラック型のサーバーをさらに細かく分類すると
1ソケット搭載可能なモデルは、エントリーモデル
2ソケット搭載可能なモデルは、ミッドレンジモデル
4ソケット以上搭載可能なモデルは、ハイエンドモデルとなります。
ネーミングで想像の通りですが、エントリーモデル→ミッドレンジモデル→ハイエンドモデルの順に、 性能がアップしていきます。
それでは、エントリーモデル・ミッドレンジモデル・ハイエンドモデル別にもう少し、掘り下げて比較してみましょう。
「タワー型・ラック型サーバーの各モデル比較」を参照してください。
<< タワー型・ラック型サーバーの各モデル比較 >>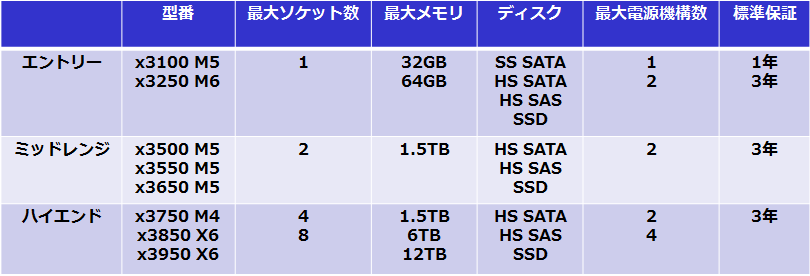
エントリーモデル:
SS SATA ディスク(※1)対応や冗長電源なしや標準保証1年のモデルがあります。
そのため、信頼性より低価格重視で、開発や検証環境等、短期間・低負荷のシステムの場合に使用されることが多いです。
ミッドレンジモデル:
エントリー・ミッドレンジ・ハイエンドモデルの中で、 一番販売されているサーバーです。
ハイエンドモデルほど、高性能な処理は必要ないが、信頼性やメモリの拡張性が必要な場合にこのモデルを選定します。
ハイエンドモデル:
CPUを4ソケット以上搭載したい場合や、大容量のメモリが必要な高性能なシステムの場合にこのモデルを選定します。
※1.ディスクの種類
SS SATA:サーバー電源をオフにしないと交換できないディスク
HS SATA:大容量/低価格/低負荷のディスク
HS SAS:高性能/高信頼性のディスク
SSD:高速読み込み性能に優れているドライブ
②.高密度型
NeXtScale System といわれるこのモデルは、6Uのエンクロージャーに最大12サーバー搭載可能なモデルです。
電源機構だけをエンクロージャー内のサーバーが共有します。
大量のx86サーバーを必要とするシステムに使用されることが多いです。
③.ブレード型
Blade Center(当時IBMから販売)として登場したのは2002年で意外と歴史は浅いのですが、
タワー型・ラック型の次に一番販売されているサーバーです。
現在 Lenovo社製では、Flex System としてシリーズとして販売されております。
このモデルは、11Uのシャーシに最大14サーバー搭載可能なモデルです。
NeXtScale Systemとの最大の違いは、シャーシ内に、ネットワークスイッチとSANスイッチを搭載することが可能で、シャーシ内のサーバーは、このスイッチを共有することが出来ます。
④.ハイパー・コンバージド
サーバー・ストレージ・ネットワーク・仮想化ソフトや管理ツールがパッケージ化されたサーバーです。
ハイパー・コンバージドに関しては、
4月てくさぽBLOGに掲載した記事に詳しく記載してます。下記URLを参照してみてください。
2.x3550 M5/x3650 M5 旧サーバーと新サーバーの違い
x3550 M5/x3650 M5の新サーバーが、2016年4月19日に発表されました。
「Lenovo System x サーバーラインナップ」の赤の点線枠の部分です。
これは、Intel社が2016年4月1日に発表した、コードネーム:「Broadwell-EP」といわれる「 Xeon Processor E5-2600 v4 」のCPUを搭載した新しいサーバーです。
旧x3550 M5/x3650 M5のサーバーは、コードネーム:「 Haswell- EP 」といわれる「 Xeon Processor E5-2600 v3 」のCPUを搭載してます。
そして一番気になるのが性能はどのくらいアップしたのか?ですよね。
Intel社が実施した「 Xeon Processor E5-2600 v3 」と「 Xeon Processor E5-2600 v4 」のCPUの ベンチマークによると平均1.27倍といわれてます。
それでは、「 Xeon Processor E5-2600 v3 」のCPUを搭載したサーバーと
「 Xeon Processor E5-2600 v4 」のCPUを搭載したサーバーに関して少し違いを見ていきましょう。
x3550 M5/x3650 M5の「 Xeon Processor E5-2600 v3 」と「 Xeon Processor E5-2600 v4 」のサーバーの違いを表にまとめてみました。
①~⑥の番号順に詳しく見ていきましょう。
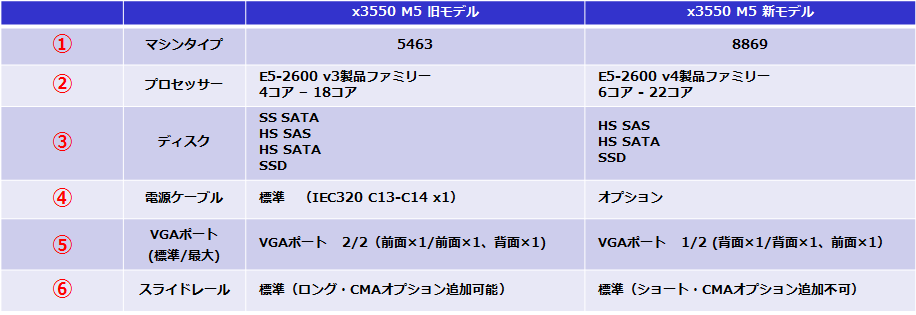
<< 新旧x3550 M5モデルとの違い >>
<< 新旧x3650 M5モデルとの違い >>
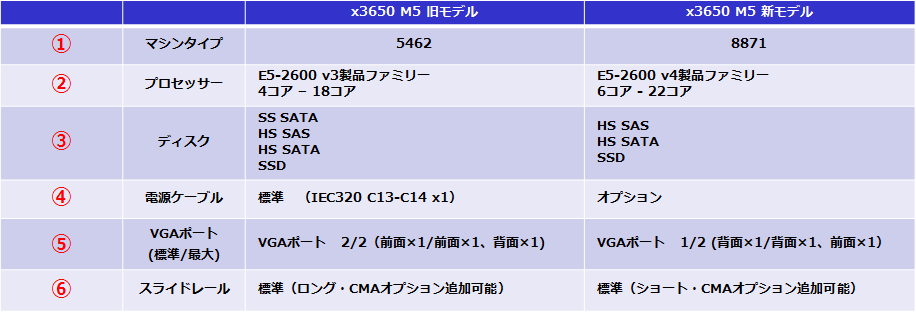
①. 「 Xeon Processor E5-2600 v3 」と「 Xeon Processor E5-2600 v4 」の搭載しているサーバーのモデルでは、製品の型番が異なります。
x3550 M5/x3650 M5の既存のモデルは、それぞれ、上4桁が「5463」 /「5462」 。
そして、新モデルの上4桁は、それぞれ「8869」/「8871」となります。
新サーバーと旧サーバーの見分け方は、型番でできますね。
②.CPUのコア数が、「4コア-18コア」→「6コア-22コア」になります。
新サーバーには、4コアのサーバー製品がなくなります。
ソフトウェアのコア数課金のため、どうしても4コアのサーバーが必要な場合には、旧モデルのx3550 M5/x3650 M5の製品にするかもしくは、x3250 M6の製品を選択してください。
③.ミッドレンジモデルではあまり使用されない、SS SATA ディスクの搭載サポートがなくなります。
信頼性の低いSS SATA ディスクは、x3550 M5/x3650 M5では使用されることがあまりないので、SS SATA ディスク搭載サポートがなくなるのはあまり影響はありませんね。
④.標準搭載されている電源ユニットに、電源ケーブルが付属されなくなります。
標準で同梱されている電源ケーブルが必ずしも使用されるわけではないので、
必要な電源ケーブルを選択式になりました。
電源ケーブル1本不足しているとサーバーの電源がONに出来ないことがあり、
サーバー構築等の遅延に繋がることがあります。たかが電源ケーブルと思わず、電源ケーブルは必ず確認してくださいね。
⑤.利用率の低い前面のVGAポートを標準搭載ではなく、オプション化しました。
⑥.新 x3550 M5のスライドレールは、従来ロングレールだったのに対して、標準同梱されるレールは、ショートレールになります。
ショートレールはケーブルマネジメントアームを追加することができないので、ケーブルマネジメントアームを使用したい場合には、同時にレールキットを購入します。
Lenovo System x サーバー製品に関して、少しでも理解が深まりましたでしょうか。
また、新旧サーバーですが、CPUだけでなく細かいところがいろいろと変更となっております。
そのため旧サーバーから新サーバーへの見積変更等は、細かいオプション等の選定が異なってきますのでご注意ください。
最後に、エヌアイシー・パートナーズでは、Lenovo社製 System x 製品の構成作成する
専任の部隊があり、弊社にて構成を作成しております。
構成を作成する部隊としては10年以上の歴史があり、2016年6月現在では全てのメンバーが3年以上の熟練したメンバーとなっております。
Lenovo社製 System x のお見積が必要な場合には、CPU/メモリ/HDD等を指定していただければ作成いたします。
Lenovo社製 System x 製品の見積及び発注に関しましては、エヌアイシー・パートナーズを是非ご利用ください。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp
商標帰属
すべての名称ならびに商標は、それぞれの企業の商標または登録商標です。