
こんにちは。
てくさぽBLOGメンバーの高村です。
今回は IBM Cloud Schematics(以下 Schematics)を利用して IBM Power Virtual Server のプロビジョニングを検証してみました。
IBM Cloud Schematics とは、Infrastructure as a Code(以下 IaC)を提供する IBM Cloud のマネージドサービスです。
IaC や Schematics などについてご存じでない方もいらっしゃると思いますので、順番にご紹介します。
IaCとは?
IaC はインフラストラクチャの設定や管理をコードで行うアプローチです。
具体的には、サーバーやネットワークなどのインフラストラクチャをコードで定義し、必要な時に実行し展開・変更することができます。
IaC を利用するメリットとしては以下が挙げられます。
- 構築・管理の効率化:
インフラストラクチャをコードとして管理することで構築・管理を自動化することができます。またコードを再利用することもできるため、複数の環境に対して同じ構成やリソース追加を効率的に構築することができます。
- 共有の容易化:
IaC は通常、ソースコード管理システム(Githubなど)を使用してコードを管理します。これにより、チームメンバーとの共有・変更の管理が容易になります。
- 人為的ミスの削減:
人為的なミスのリスクが減り、変更の管理やインフラストラクチャの状態の監視も容易になります。
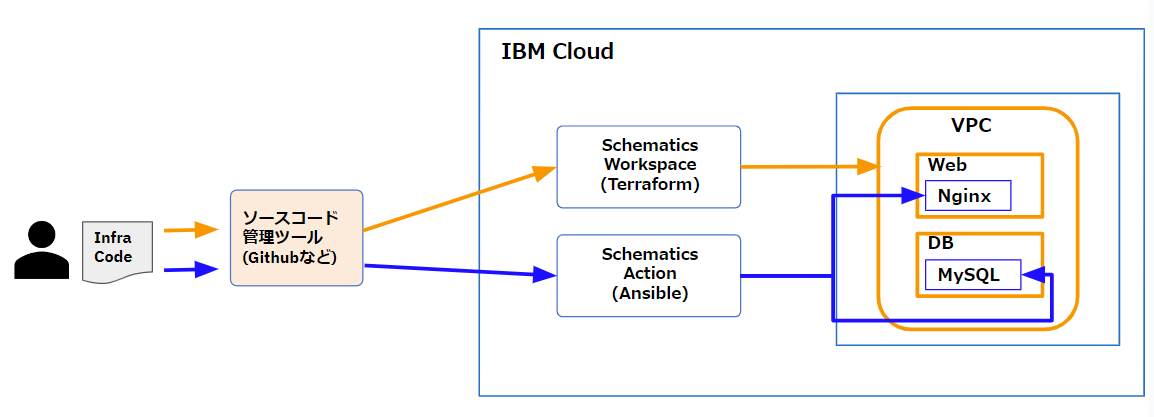
以下はコードが実行される流れを表した図です。
作業者がコードを作成し、そのコードを Gitリポジトリなどにアップロードすると構成管理ツールによってコードが実行され、自動的に環境が構築される流れになります。

IaC を実現するためには構成管理ツールを利用します。
代表的なツールとしては「Terraform」「Ansible」「chef」などがあります。
以下に簡単にご紹介します。
- Terraform:
インフラストラクチャのコードを記述することで、インフラストラクチャの作成、構成、および変更を自動化します。Terraform は主に IaaS に焦点を当てており、インフラストラクチャの構成及び状態の管理に使用されます。
- Ansible:
構成管理、アプリケーションのデプロイ、タスクのオーケストレーションなど、幅広い自動化タスクに使用されるツールです。主に構成管理とアプリケーションのデプロイに使用されます。
- Chef:
Chefサーバーとクライアントを使用して設定を管理します。主にシステム設定やソフトウェアの導入などの自動化に使用されます。
ツール毎に得意とする分野があり、使用目的や環境に応じて使い分けられています。
これからご紹介する Schematics は上記の Terraform や Ansible の機能を統合し、IBM Cloud環境での IaC を実現するマネージドサービスです。
Schematicsとは?
Schematics は IBM Cloud のサービスの一つとして提供されるマネージドサービスです。
Schematics自体は無償サービスで、プロビジョニングしたリソースに対し費用が発生します。
2023年8月時点で、Schematics自体のリソースは北アメリカやヨーロッパなど一部の地域に作成されます。
ただし IBM Cloud のリソースを作成する場合は、Schematics のロケーションに関係なくどこでも作成することができます。
Schematics は大きく分けて3つの機能を利用することができます。
- Schematicsワークスペース:
Terraform の機能を利用し、IBM Cloud環境へのリソースのプロビジョニングと構成の管理の自動化を行います。
- Schematicsアクション:
Ansible as a Service機能を利用し、構成の管理及びアプリケーションを IBM Cloud環境にデプロイします。
- Schematics Blueprints(2023年8月現在ベータ版):
定義したインフラコードをモジュールとして取り扱い、組み合わせることで大規模環境をデプロイします。
Schematicsワークスペースと Schematicsアクションの使い分けとしては、リソースのプロビジョニングは Schematicsワークスペースを利用し、ソフトウェアのデプロイや設定管理には Schematicsアクションを利用することが推奨されています。
今回の検証では、Schematicsワークスペースを利用した Power Virtual Server のプロビジョニングをご紹介いたします。
検証の概要
Schematicsワークスペースの利用シーンとしては、複数の区画をプロビジョニングしたり、構成変更や別環境へ同一構成をプロビジョニングすることなどが考えられます。
今回の検証では Power Virtual Server を東京リージョンにプロビジョニングし、メモリ容量を変更を行います。
また、大阪リージョンにも同じ区画をプロビジョニングしていきます。
なお、事前に Power Virtual Server のワークスペースを東京と大阪に作成しておきます。
ワークスペースの作成方法につきましては「【やってみた】IBM Power Virtual ServerのAIX環境とIBM Cloud Object Storageを接続してみた -Part1-」の「2) IBM Power Virtual Serverの作成」をご参照ください。
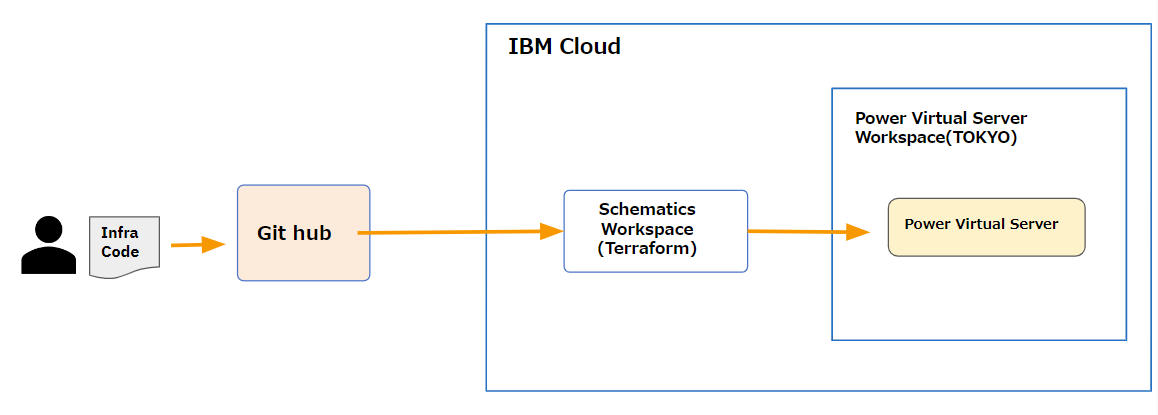
以下は検証の構成図です。
コードは Github のプライベートリポジトリに配置します。外部のソースコード管理ツールを使用したくない場合は IBM Cloud Toolchain の Gitlab を利用することも可能です。
Githubの設定
プライベートリポジトリの作成
Github の使用は初めてなので、アカウントやリポジトリ作成方法は Web で検索しました。
以下の画面は Github のトップ画面です。デザインがカッコいいですね。
アカウントを作成し、ダッシュボード画面に入ります。
コードは外部公開しない想定のため、プライベートリポジトリを使用します。
任意のリポジトリ名を入力、[Private] を選択し [Create a new repository] をクリックします。
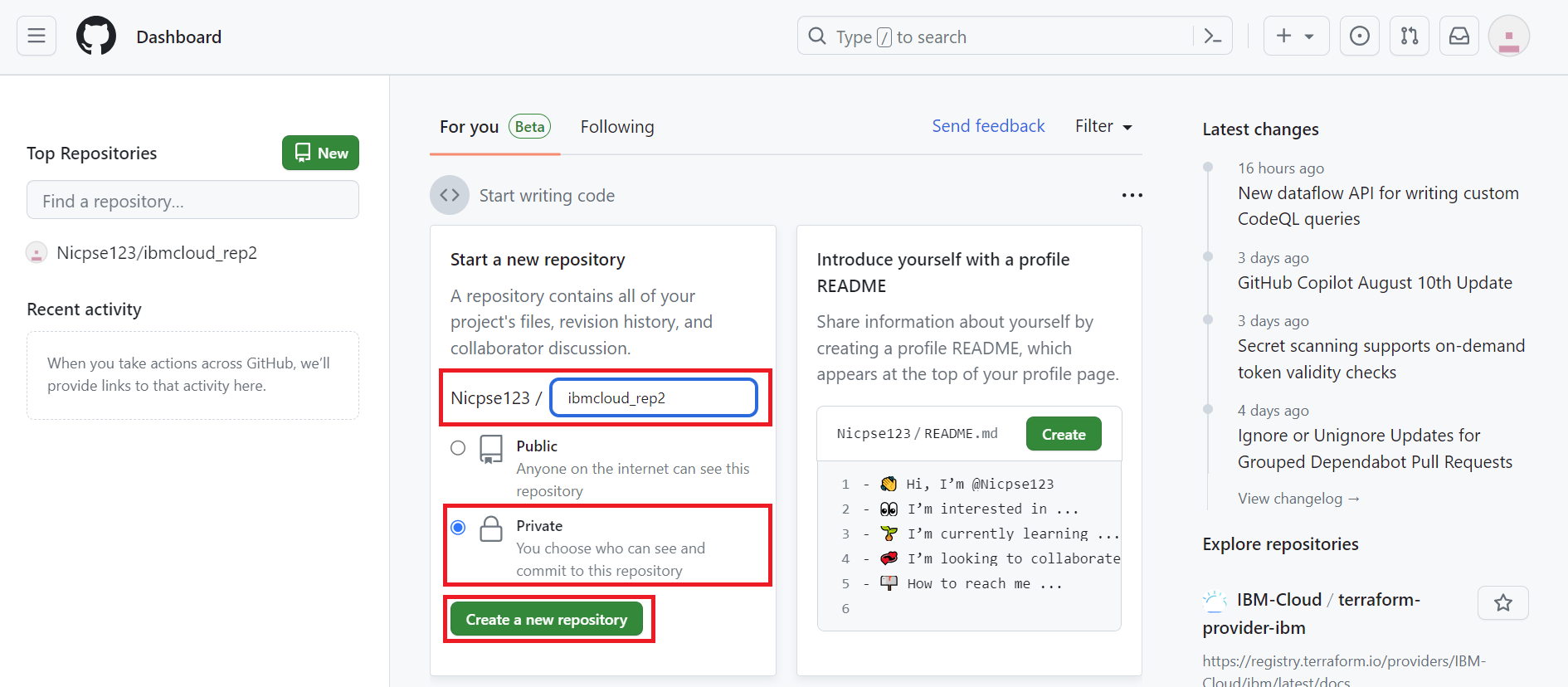
プライベートリポジトリが作成できました。
作成したリポジトリにコードを配置していきます。
コードの作成
Power Virtual Server をプロビジョニングするためのコードですが、こちらの Github に「サンプルコード」が公開されています。5つのコードファイルがありますが全て使用します。
以下各コードファイルの説明です。
- README.md:Readmeファイル
- main.tf :インフラ定義を記述するファイル
- provider.tf :対象のクラウドなどの情報を記述するファイル(リージョンなども記述)
- variable.tf :変数を記述するファイル
- versions.tf :使用するモジュールとバージョンの組み合わせを記述
プライベートリポジトリの画面に戻り、[Add file] から [Create new file] をクリックします。
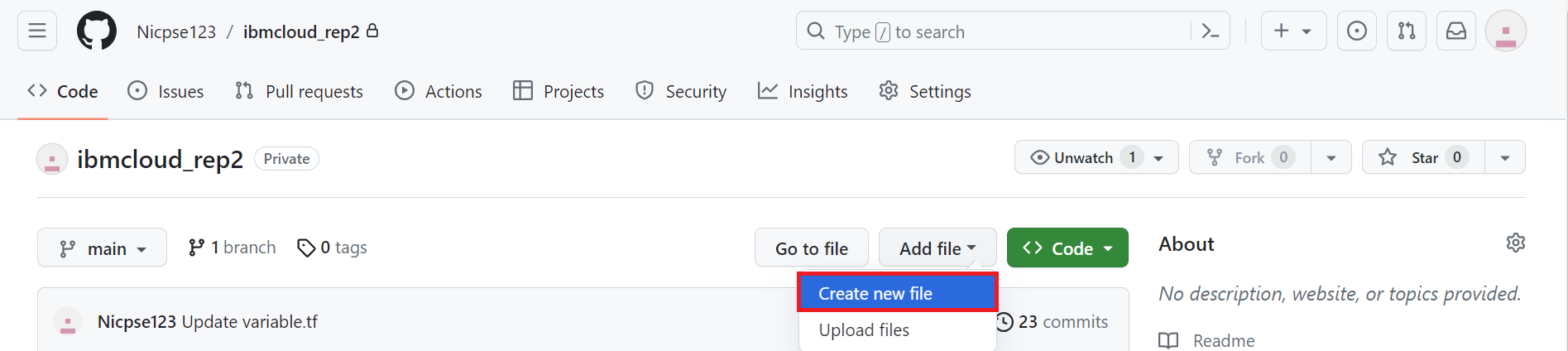
ファイル名を入力し、サンプルコードをコピー&ペーストします。最後に [Commit change] をクリックします。
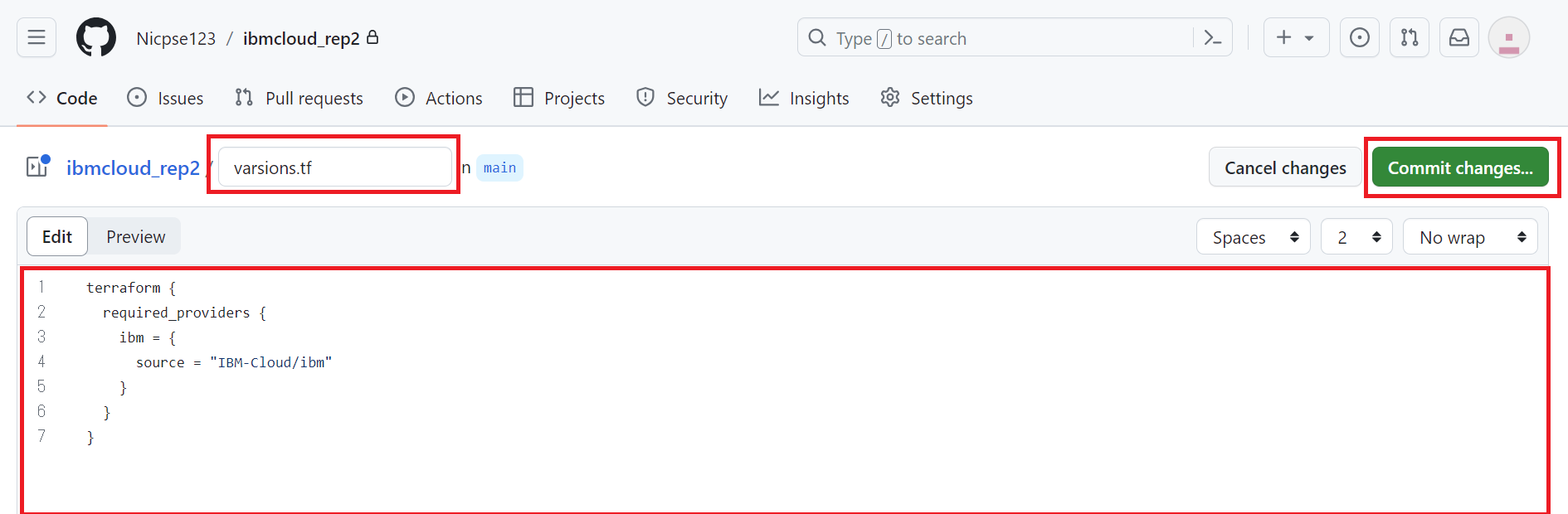
5つのコードファイルを作成しました。
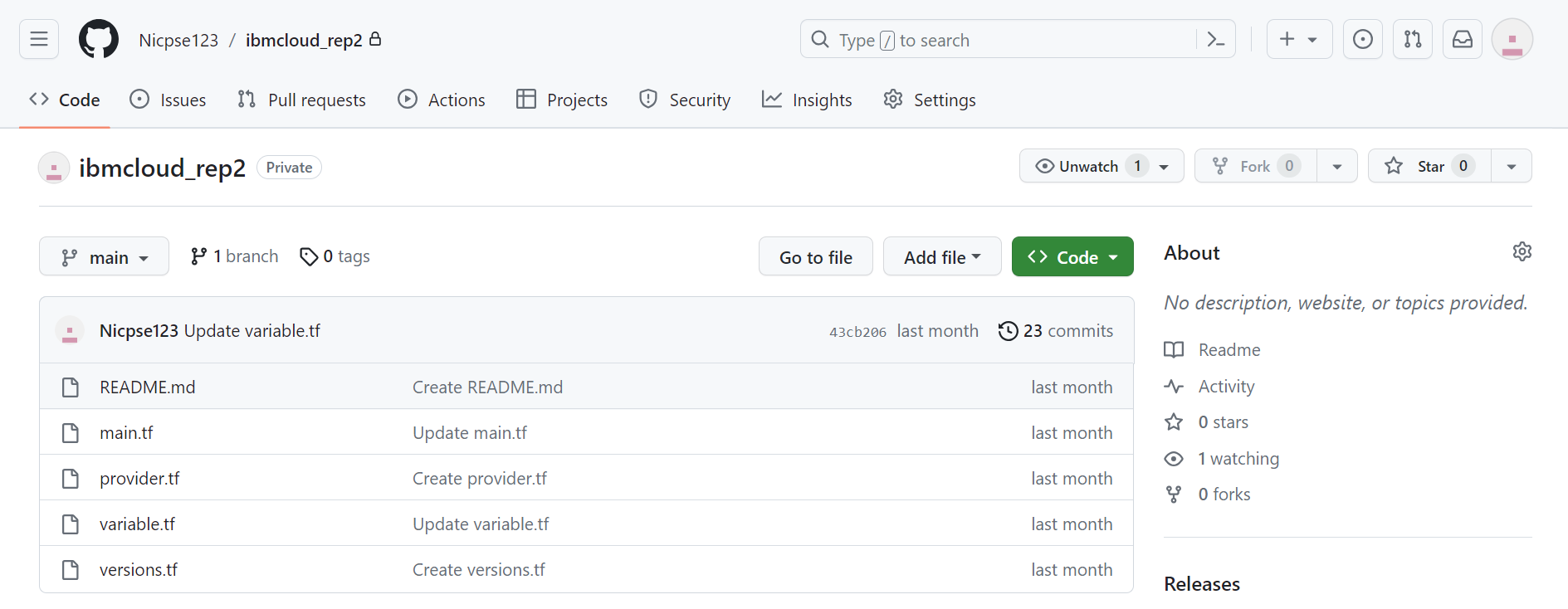
コードの編集
検証では以下構成の Power Virtual Server をプロビジョニングしていきます。
- リージョン:東京
- インスタンス名:test_AIX
- OS:AIX V7.3
- CPUタイプ:Uncapped Shared
- CPU:0.25
- メモリ:2GB
- ストレージタイプ:Tier3
- 外部ディスク名:dg
- 外部ディスクサイズ:1GB
- NW名:pvs_test_nw
サンプルコードのままでは上記の構成を作成することはできないため、変数ファイル「variable.tf」を編集する必要があります。
main.tf、provider.tf は variable.tf の値をみて動きますので特に編集は不要です。versions.tf は変更無し、README.md は適宜編集します。
以下は variable.tf の内容です。
各パラメータの説明は割愛いたしますが、ピンク字①~③の値の確認方法は下にご紹介します。
| // Service / Account variable “ibm_cloud_api_key” { description = “API Key” type = string default = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX“ }<① variable “region” { description = “Reigon of Service” type = string default = “tok“ } variable “zone” { description = “Zone of Service” type = string default = “tok04“ } variable “cloud_instance_id” { description = “Cloud Instance ID of Service” type = string default = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX“ }<②// Image variable “image_name” { description = “Name of the image to be used” type = string default = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX“ }<③// Instance variable “instance_name” { description = “Name of the instance” type = string default = “test_AIX“ } variable “memory” { description = “Instance memory” type = number default = 2 } variable “processors” { description = “Instance processors” type = number default = 0.25 } variable “proc_type” { description = “Instance ProcType” type = string default = “shared“ } variable “storage_type” { description = “The storage type to be used” type = string default = “tier3“ } variable “sys_type” { description = “Instance System Type” type = string default = “s922“ }// SSH Key variable “ssh_key_name” { description = “Name of the ssh key to be used” type = string default = “ssh_20230719“ } variable “ssh_key_rsa” { description = “Public ssh key” type = string default = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX“ }<公開鍵を入力// Network variable “network_name” { description = “Name of the network” type = string default = “pvs_test_nw“ } variable “network_type” { description = “Type of a network” type = string default = “pub-vlan” } variable “network_count” { description = “Number of networks to provision” type = number default = 1 }// Volume variable “volume_name” { description = “Name of the volume” type = string default = “dg“ } variable “volume_size” { description = “Size of a volume” type = number default = 1 } variable “volume_shareable” { description = “Is a volume shareable” type = bool default = false } variable “volume_type” { description = “Type of a volume” type = string default = “tier3“ } |
ピンク字①~③の値の確認方法は以下です。
①APIキー
APIキーの作成方法は「APIキーの作成方法」(IBMサイト)をご参照ください。
作成したAPIキーを控えます。
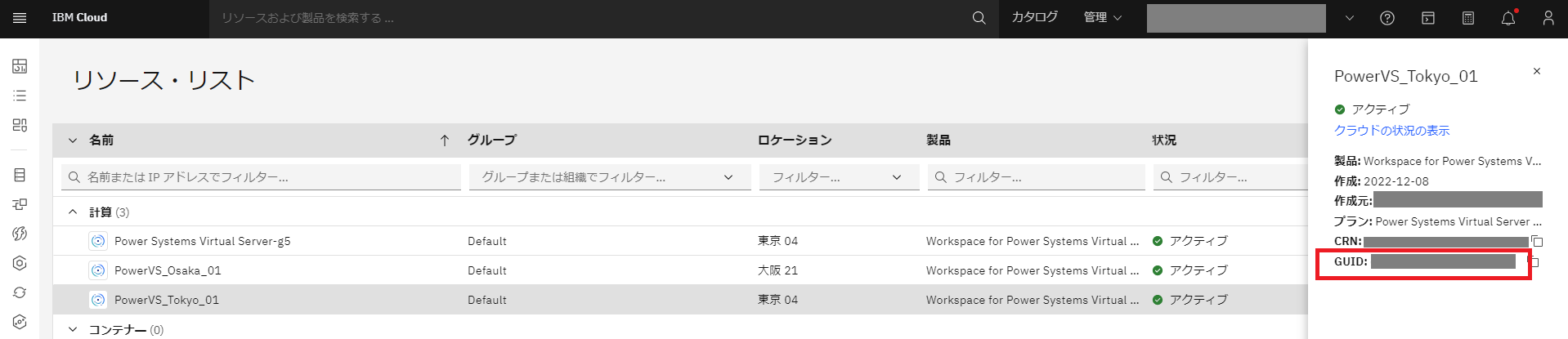
②クラウドインスタンスID
IBM Cloudリソースリストから Power Virtual Server のワークスペースを選択すると GUID が表示されるので控えます。
③イメージID
IBM Cloud Shell からコマンドを実行してブートイメージのイメージIDを取得します。
Cloud Shell は管理コンソール画面の右上のアイコンから入ります。

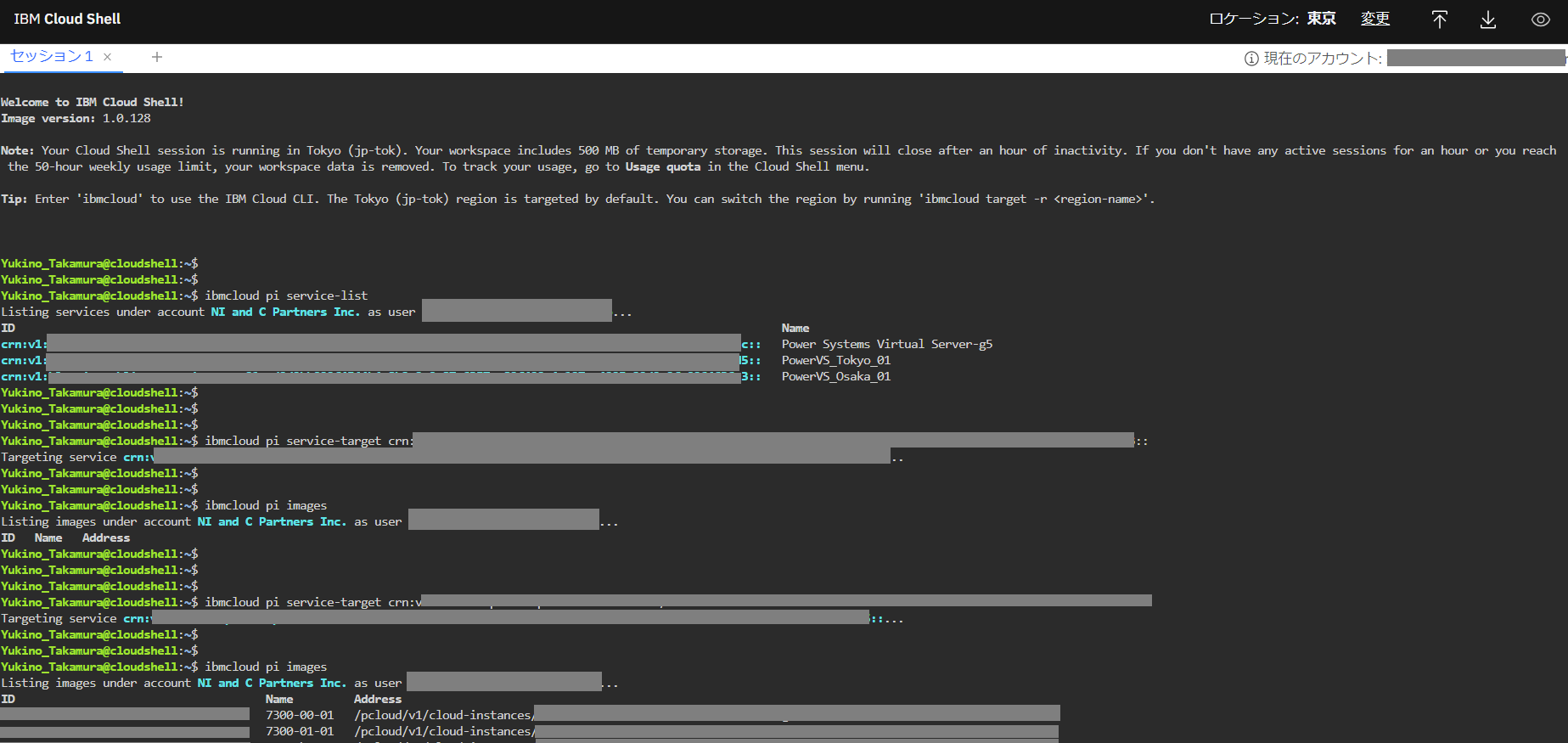
Cloud Shell で以下コマンドを実行します。
$ ibmcloud pi servicelist <ワークスペースのcrnが表示されます
$ ibmcloud pi service-target crn:XXXXXXXX <表示された対象ワークスペースのcrnを入力します
$ ibmcloud pi images <イメージIDが表示されるのでIDを控えます
以下は出力結果画面です。
マスキングが多く申し訳ございませんが、ご参考ください。
これでコードの編集が完了しました。
サンプルコードが提供されているので、variable.tf の変数を編集すれば目的のコードを作ることができますね。
トークンの取得
Schematics から Github のプライベートリポジトリにアクセスする際にパーソナルアクセストークンが必要となるため、Github からパーソナルアクセストークンを取得します。
メニューから [Settings] をクリックします。
左側メニューの [<>Developer settings] をクリックします。
[Tokens(classic)] をクリックします。
[Generate new token(classic)] をクリックします。
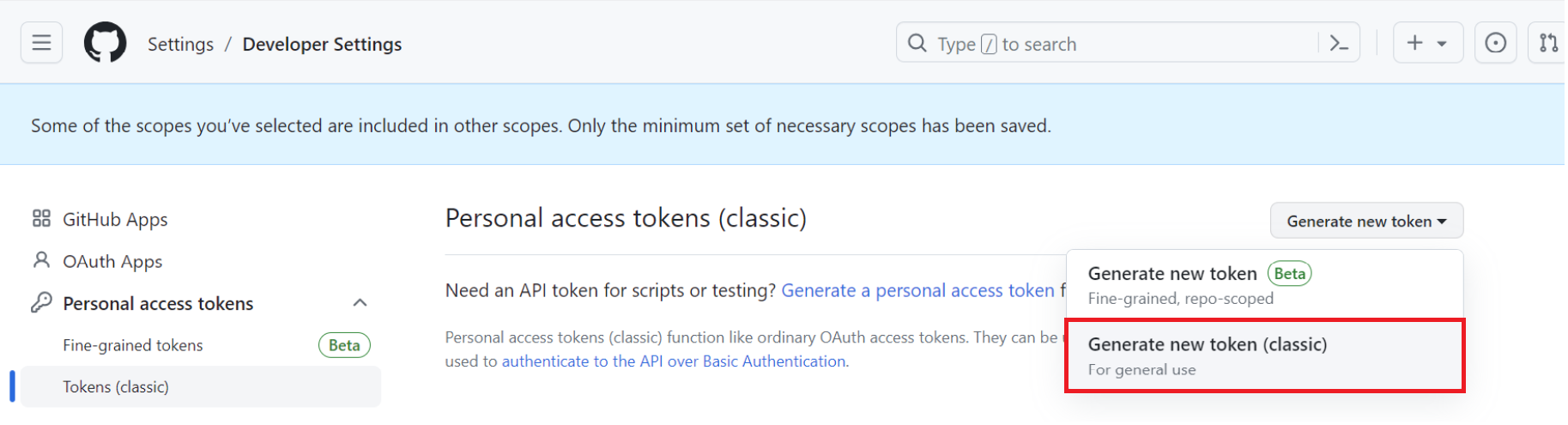
[Note] に適宜入力し、[Expiration] を30日に設定し、”Select scopes” では [repo] にチェックを入れます。画面を下にスクロールし、[Generate token] をクリックします。
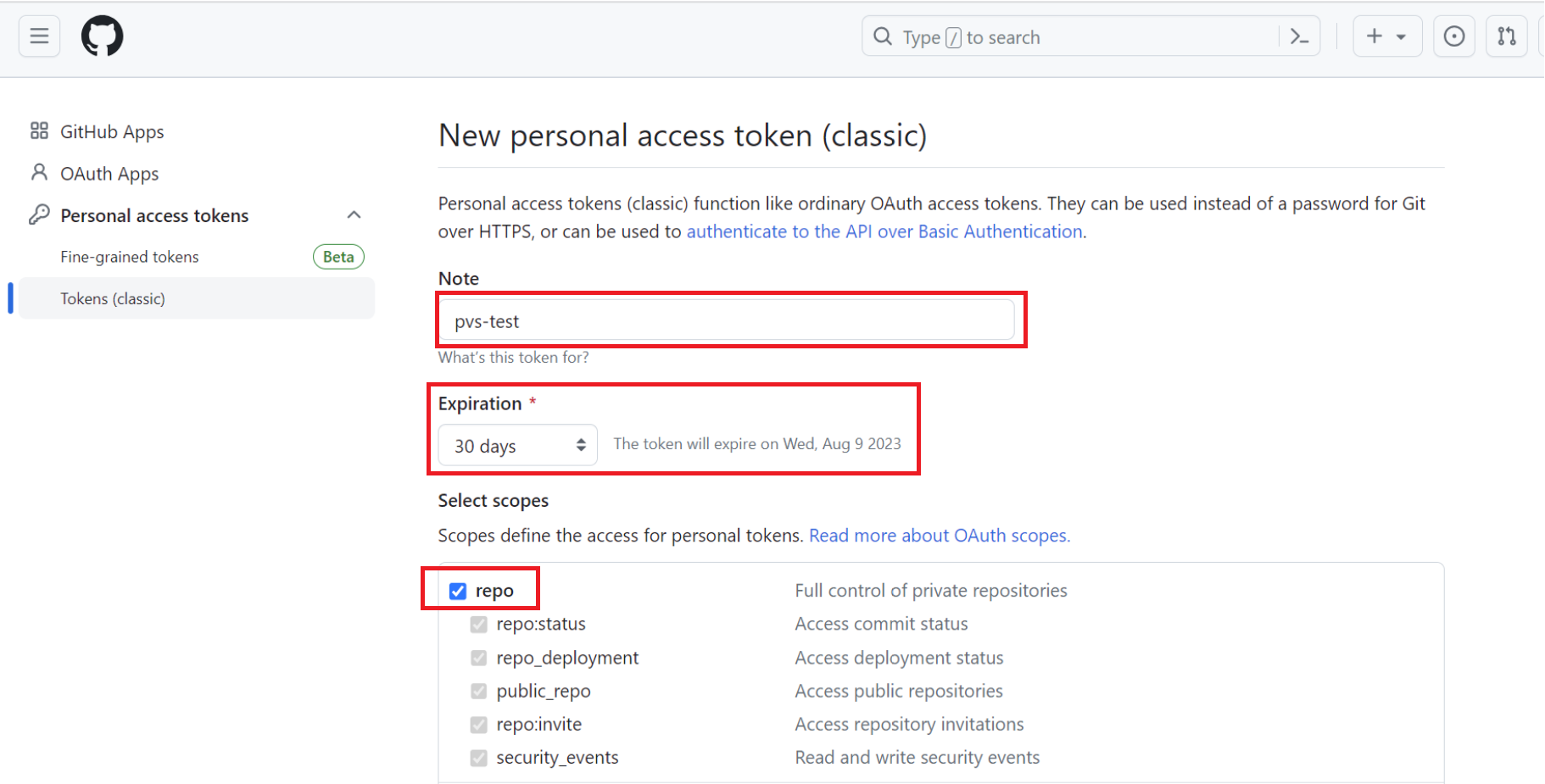
パーソナルアクセストークンが作成できました。
後程Schematicsワークスペースの作成で必要になるためメモ帳などに控えておきます。
リポジトリーのURL取得
プライベートリポジトリのURLを取得します。
リポジトリ画面に戻り [<>Code] をクリックし、[HTTPS] を選択して URL を控えておきます。
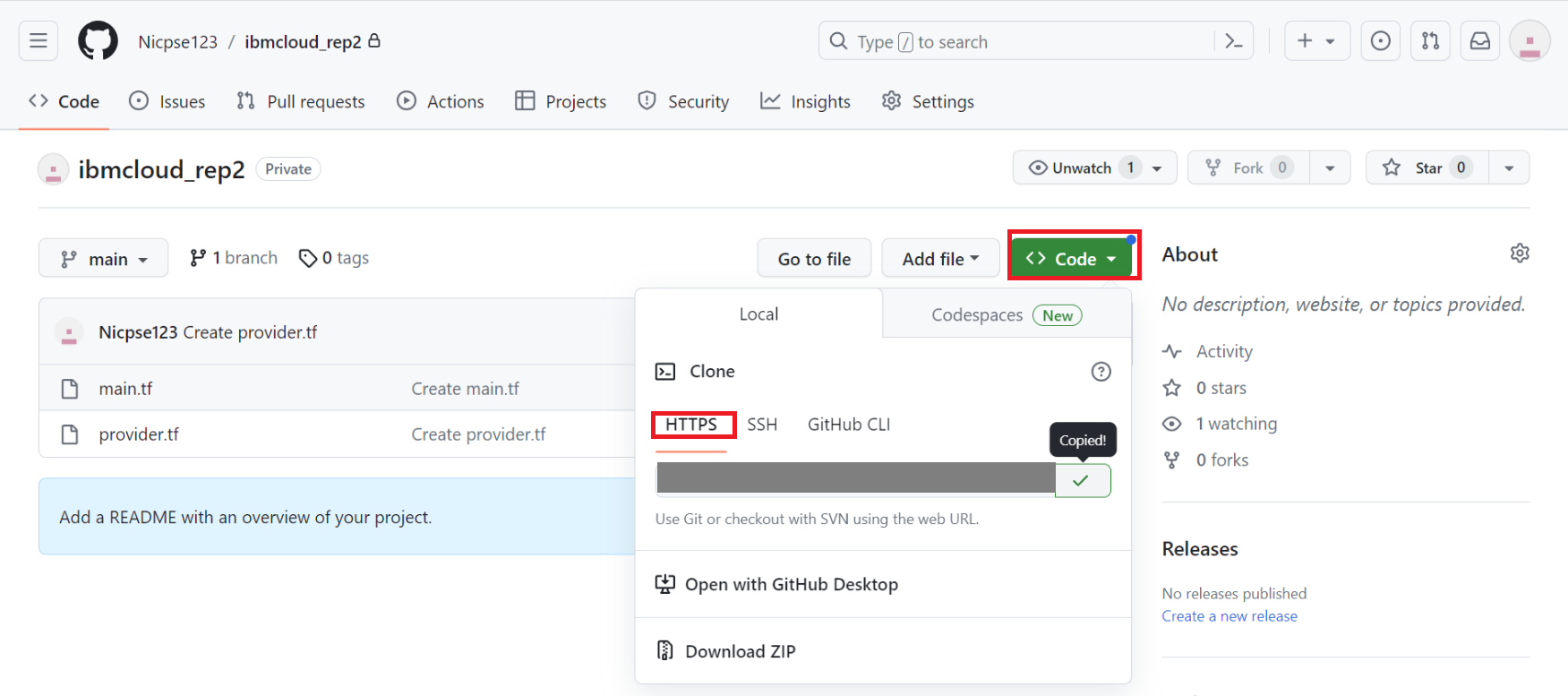
これで Github の設定は完了しました。
Schematicsワークスペースの設定・プランの実行
Schematicsワークスペースの作成
Schematicsワークスペースから Power Virtual Server をプロビジョニングにしてみましょう。
IBM Cloud のカタログから “Schematics” を選択します。
Schematics のホーム画面に入りました。
[ワークスペースの作成+] をクリックします。
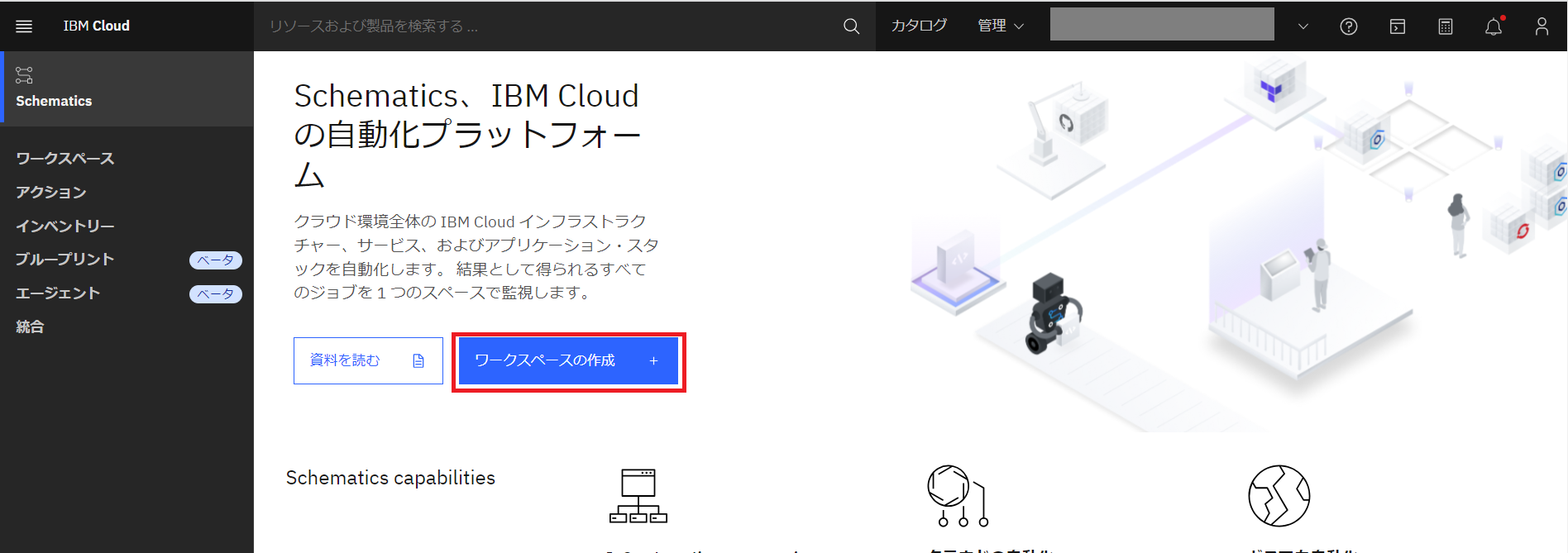
ワークスペース作成画面です。
[GithubのURL] にはプライベートリポジトリの URL、[パーソナル・アクセス・トークン] には Github で作成したトークンを入力します。[完全リポジトリーの使用] のチェックボックスはデフォルトままにします。[Terraformバージョン] は最新バージョンを指定して [次へ] をクリックします。
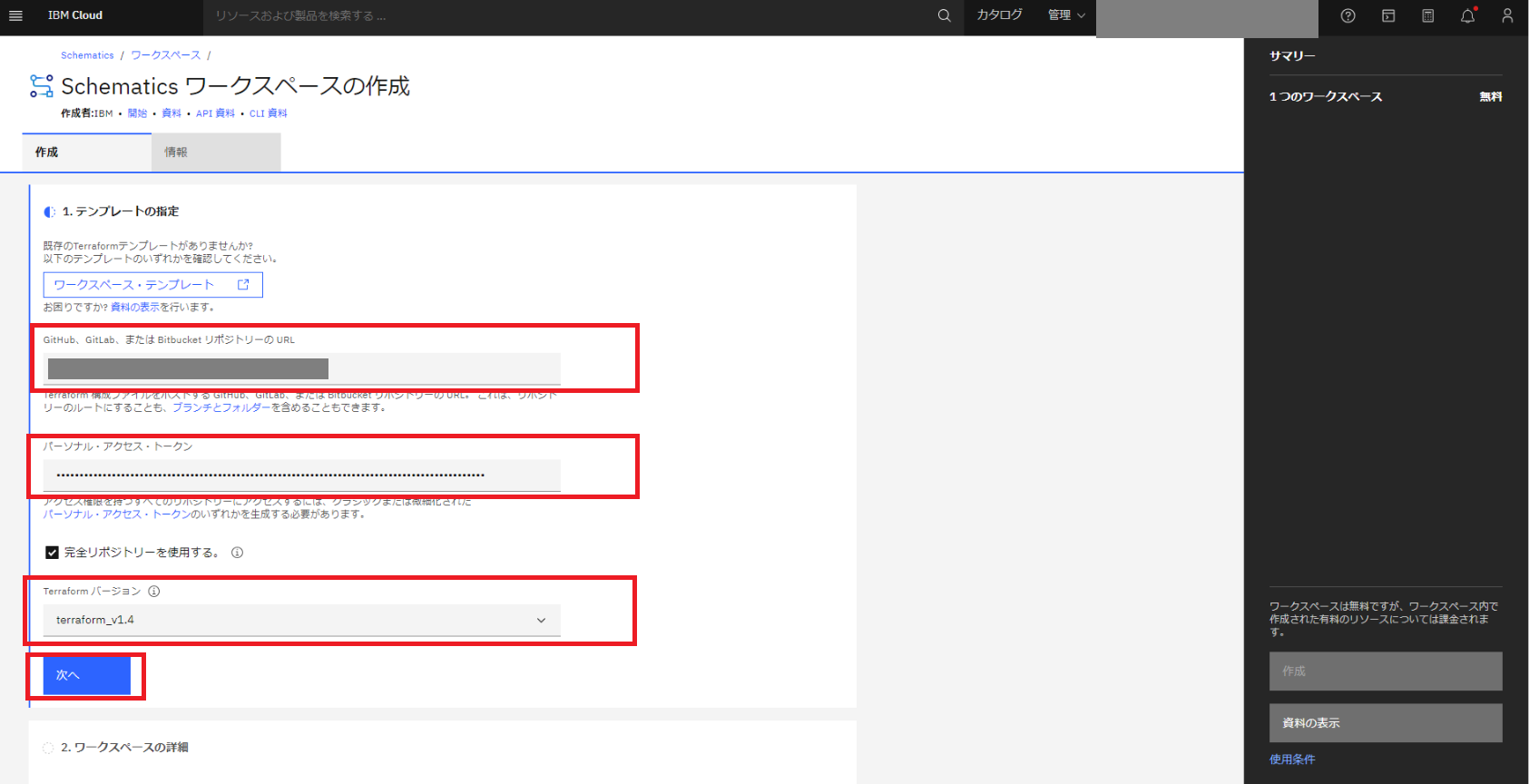
[ワークスペース名] に任意の名前を入力し、[ローケーション] を北アメリカ/ロンドン/フランクフルトの中から選択し、[次へ] をクリックします。
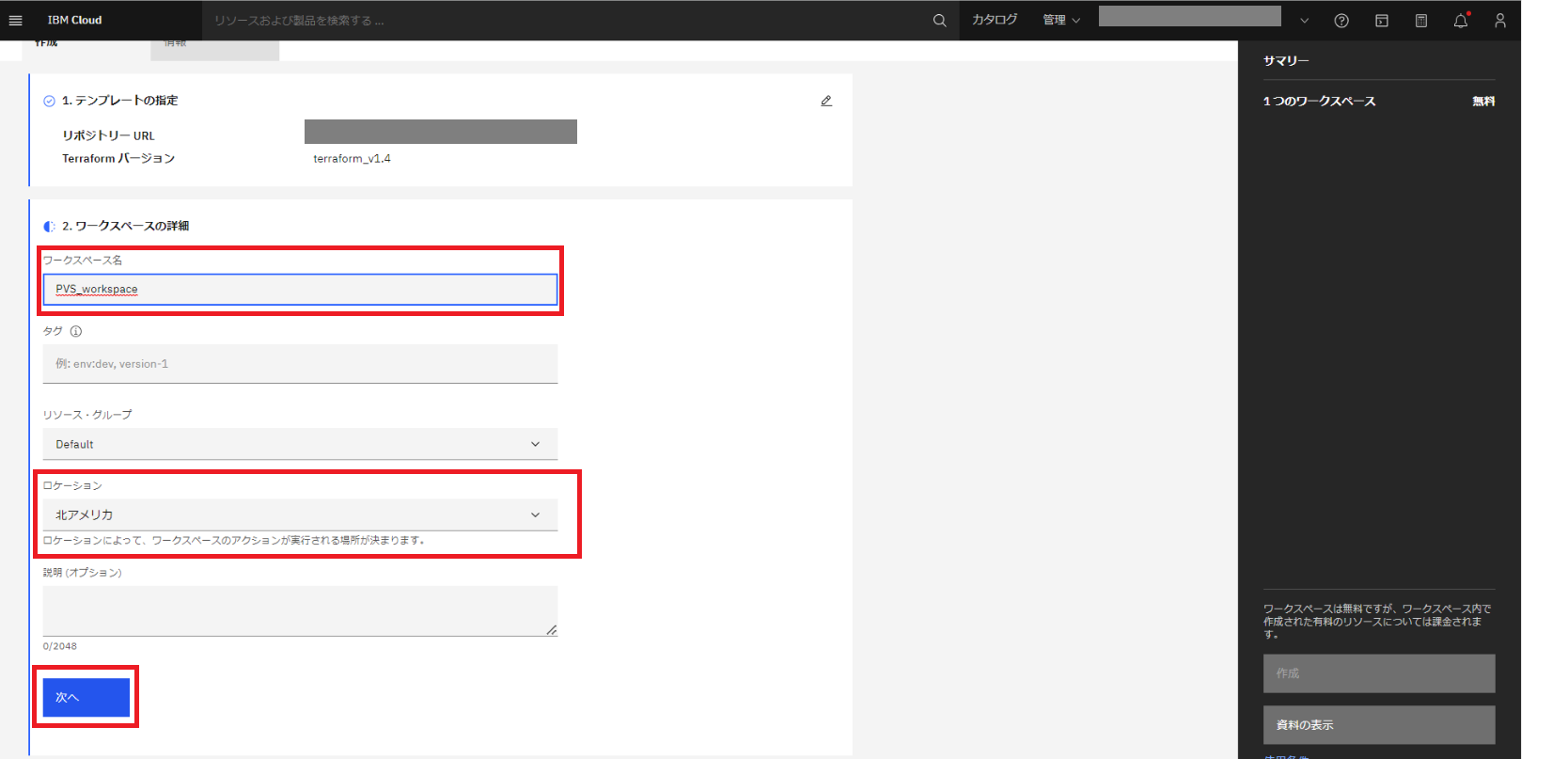
設定値が表示されるので確認し、[作成] をクリックします。
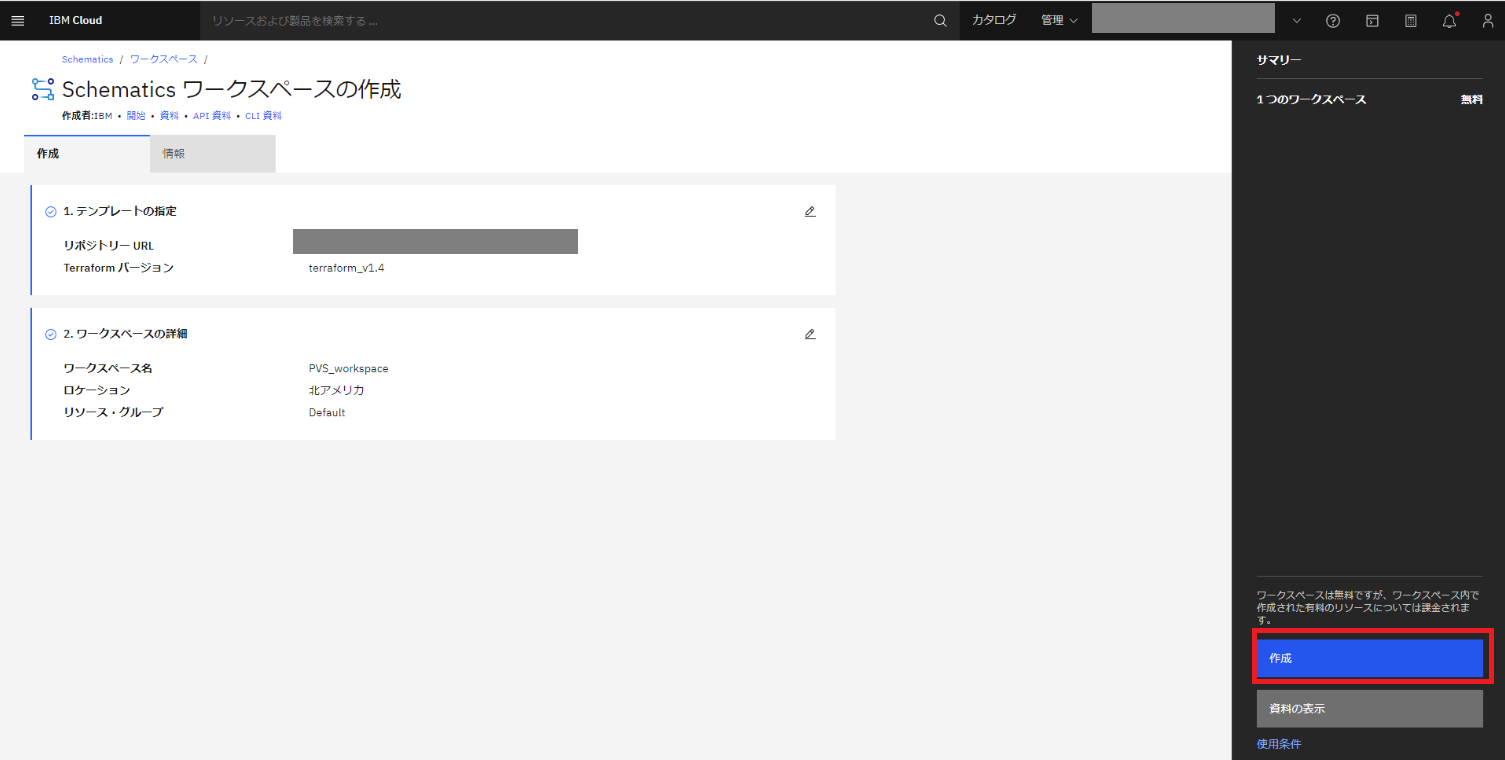
約1分程でワークスペースが作成できました。
variable.tf の変数が読み込まれ、ワークスペースの変数に表示されています。
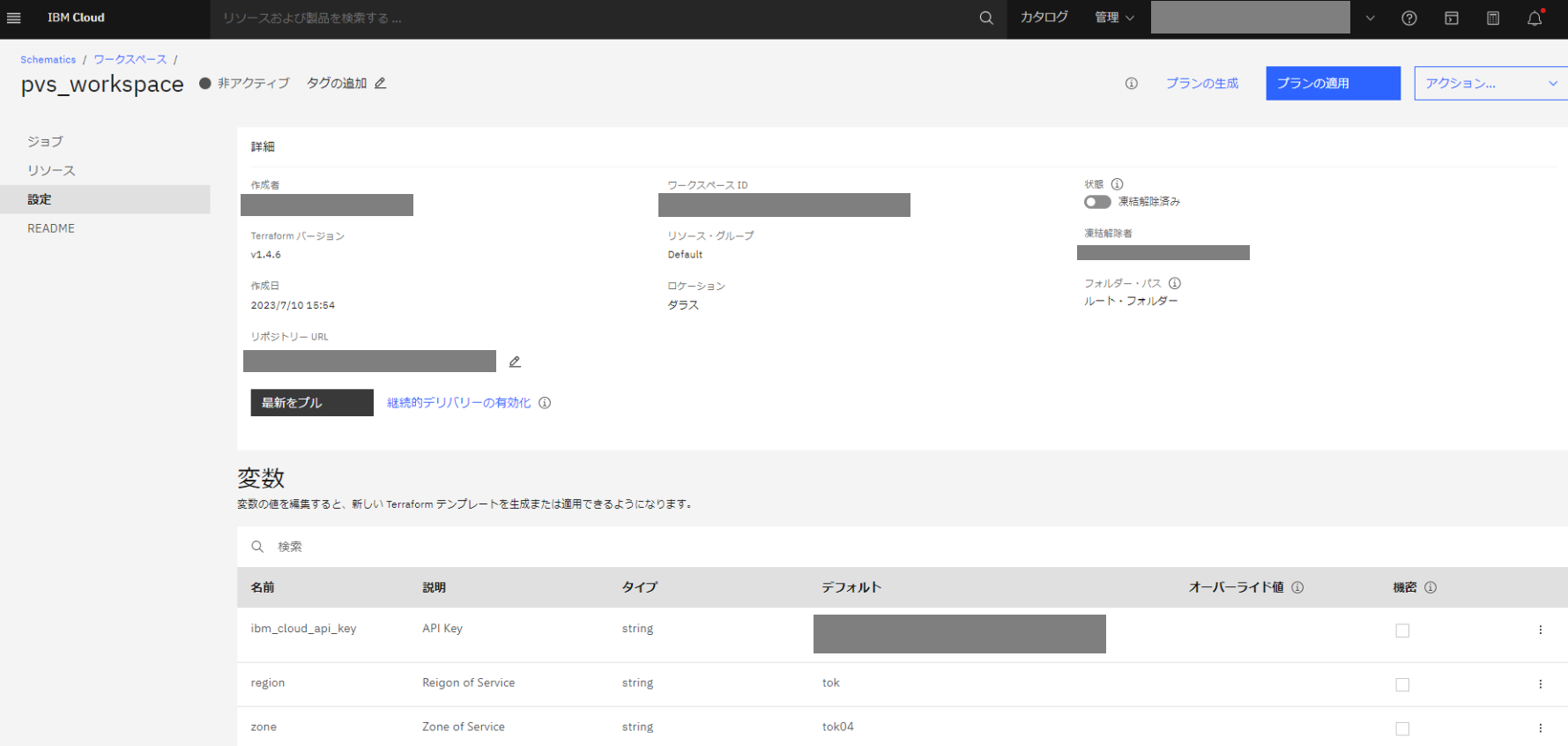
[README] を選択すると、README.md が読み込まれていることがわかります。

Power Virtual Serverのプロビジョニング
右上の [プランの生成] をクリックし、コードのチェックを行います。
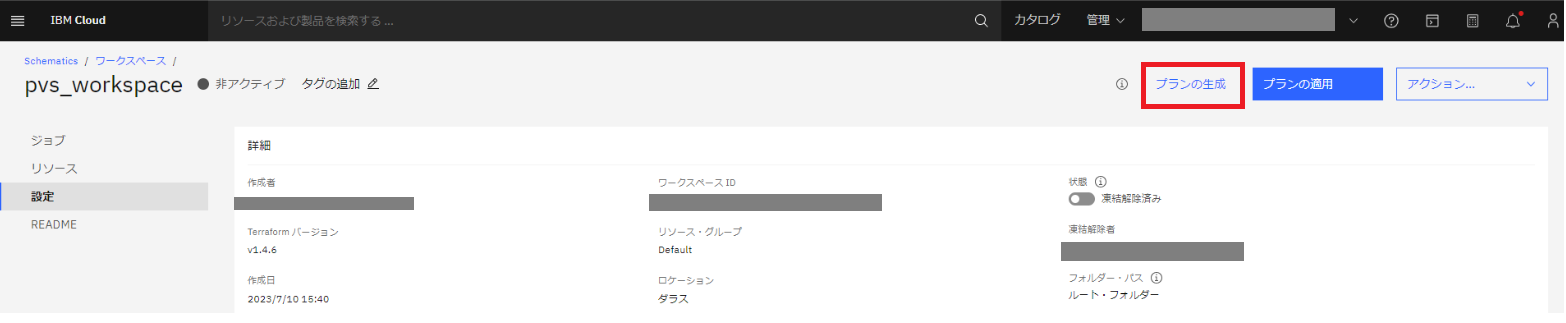
プランの生成が成功すると、[ジョブ] 画面に以下のように表示されます。

ちなみに失敗時は以下の画面が表示されます。
失敗した場合はエラーメッセージから原因を確認します。
ここでは記載しませんが、何回かプランの生成に失敗しコードを修正しました。

コードを修正した場合は、[最新をプル] をクリックすると最新の状態にすることができます。
話がそれましたが、プランを適用してプロビジョニングを実行します。
[プランの適用] をクリックします。
進行状況は [ジョブ] から確認できます。
適用が進んでいますね。
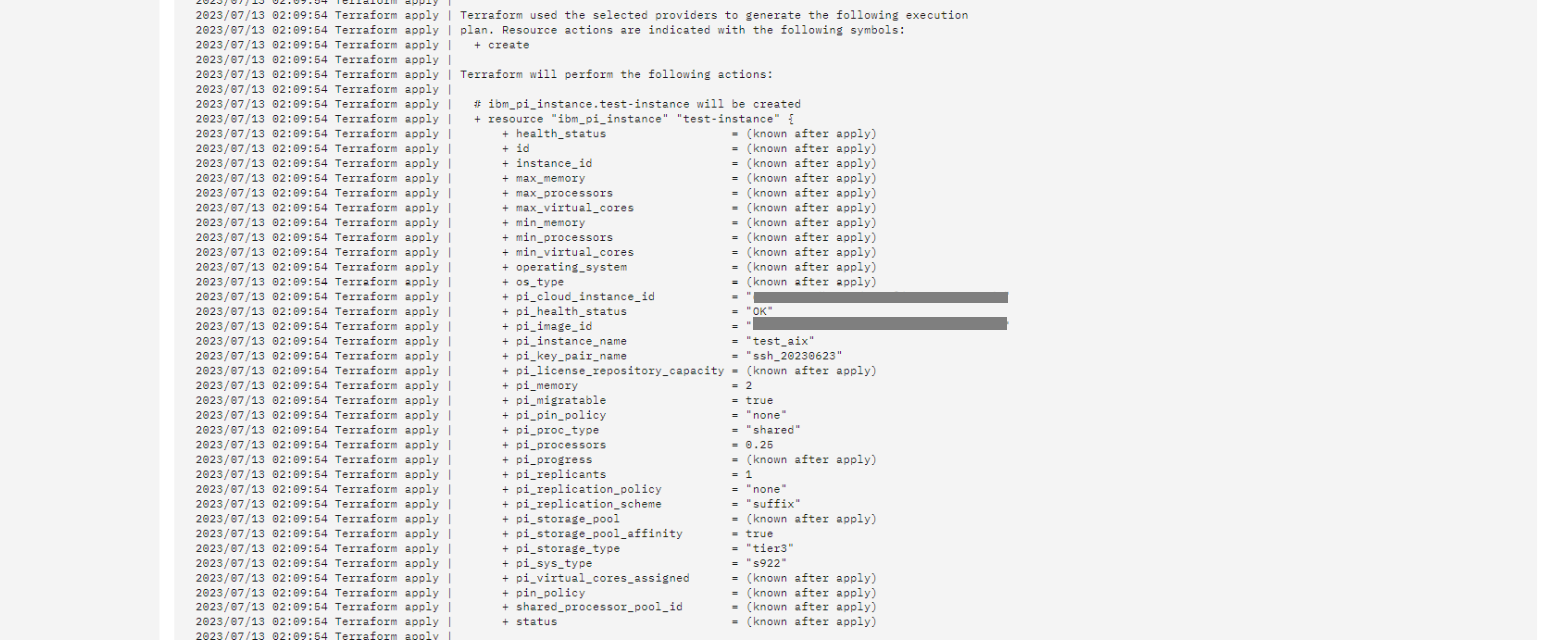
約15分程でプランの適用が完了しました。

Power Virtual Server のワークスペースを確認すると、指定通りのインスタンスが作成されていました。

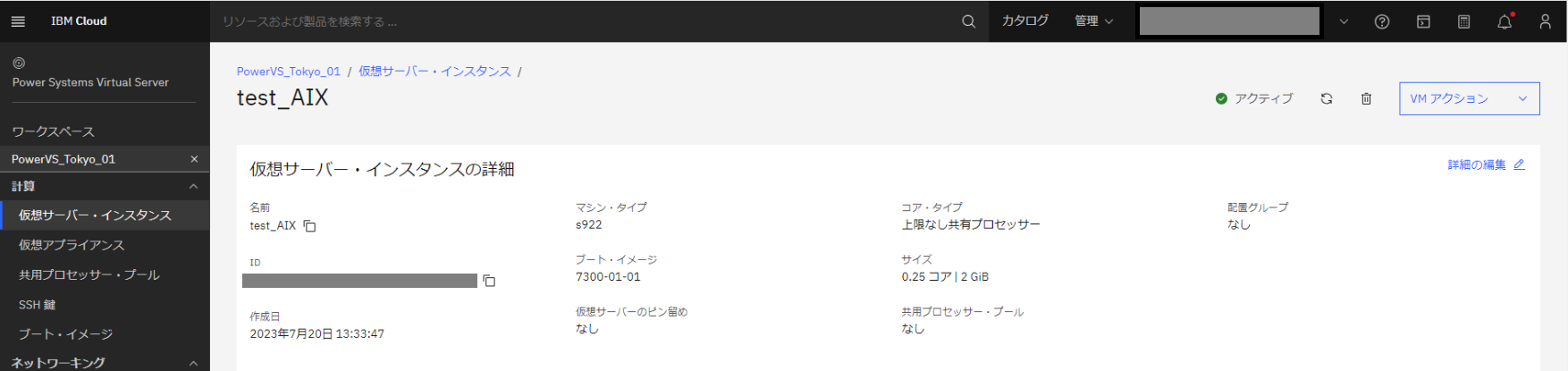
構成変更
Schematicsワークスペースにてメモリ容量を2GBから4GBへ変更します。
Github のコード編集ではなく、ワークスペースから変数を上書きすることができます。
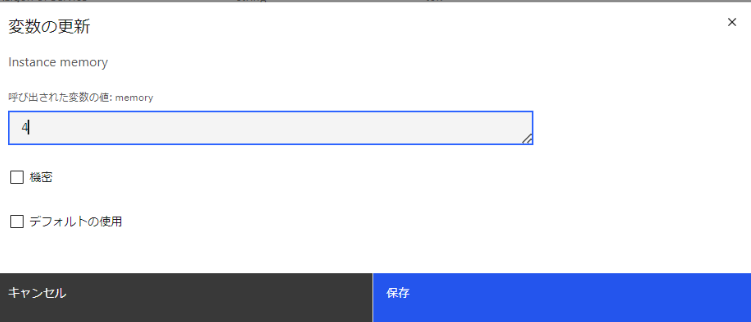
ワークスペースの変数画面から [memory] の編集アイコンをクリックします。

値を [4] にして [保存] をクリックします。
なお、デフォルト値に戻したいときは [デフォルトの使用] にチェックを入れて保存します。
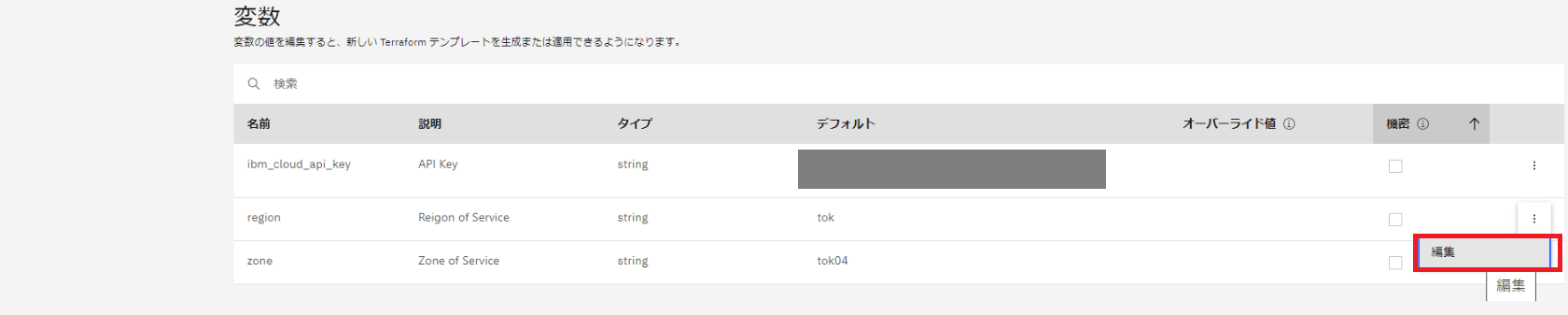
メモリの変数がデフォルトは2、オーバーライド値が4になりました。
![]()
プランの生成、適用を行い正常に行われたことを確認します。

Power Virtual Server を確認するとサイズ変更が実行されていました。

数分後、メモリが2GBから4GBに変更されたことを確認できました。

大阪リージョンへプロビジョニング
東京リージョンに作成した区画と同じ構成を大阪リージョンに作成します。
リソース変更手順と同様にワークスペースの変数を編集します。
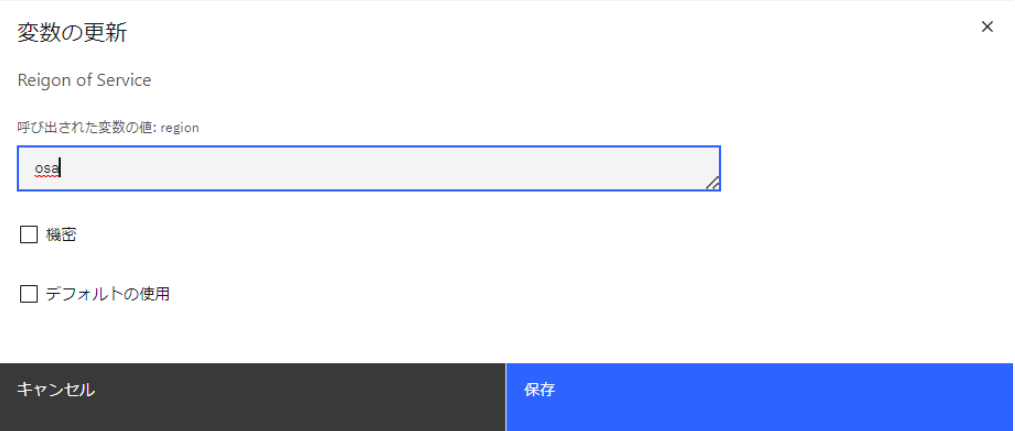
[region] を選択して [編集] をクリックします。
大阪リージョンの [osa] を入力して [保存] をクリックします。
同様に、zone, cloud_instane_id, image_name の変数を大阪リージョンの値に上書きします。
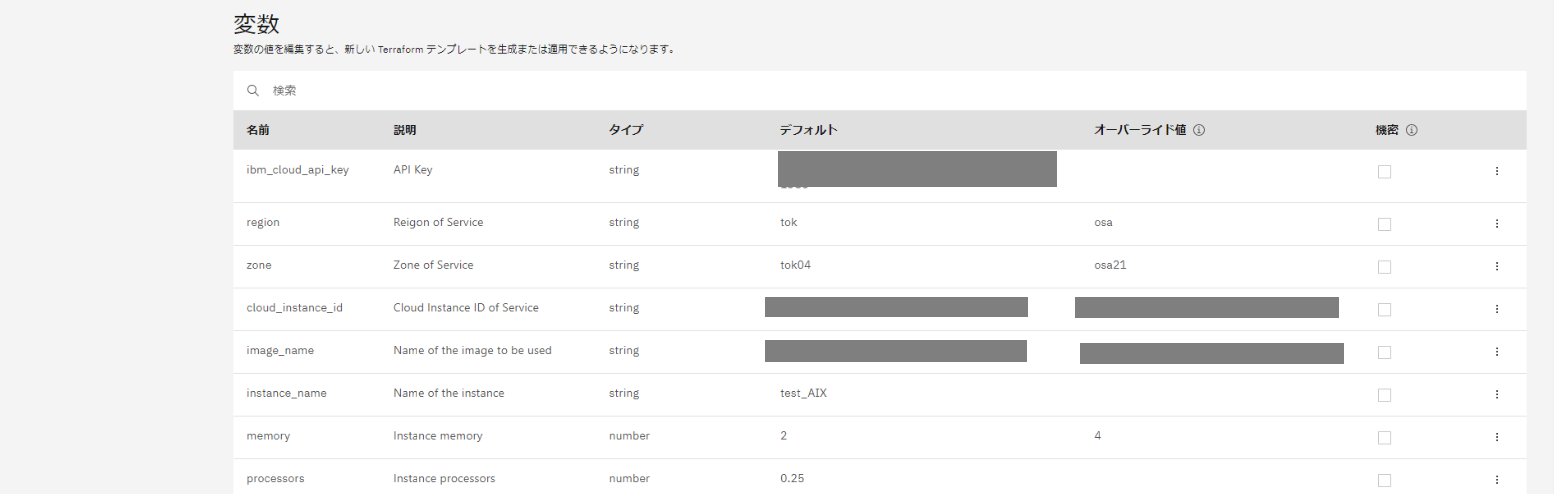
変数の上書きをした後、プランの生成を行ったところ生成が失敗してしまいました。
ログをみると、イメージを Get できない内容のエラーが出力されています。
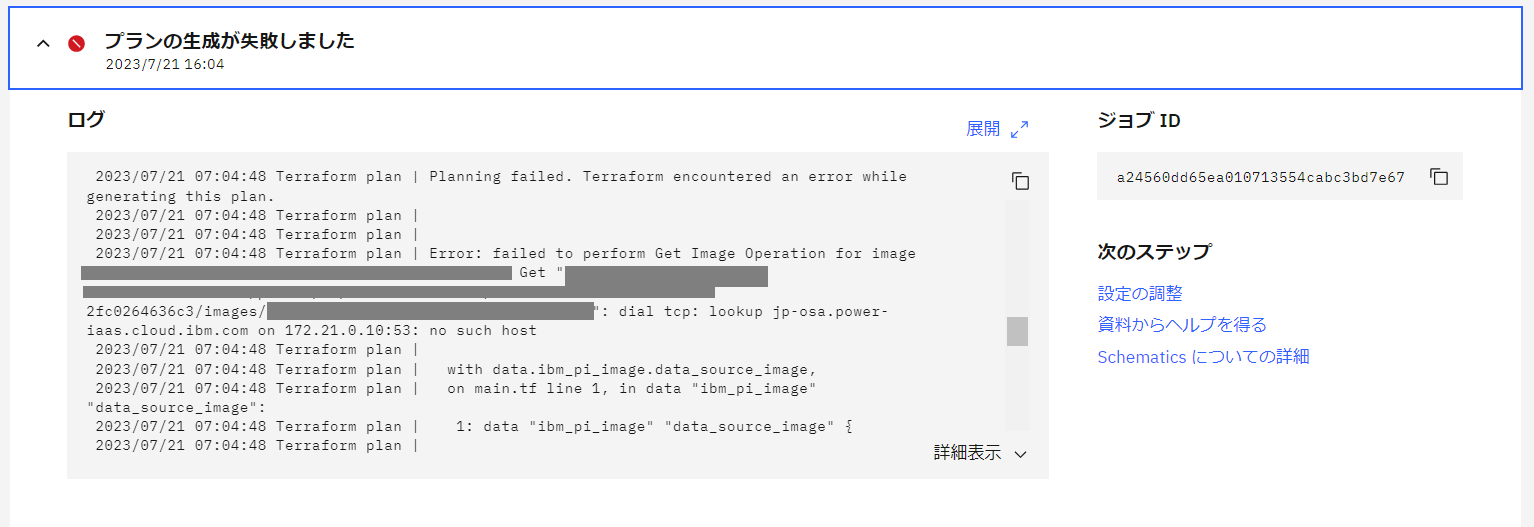
しかし、変数のオーバーライド値には大阪リージョンの値を入力しています。Github のコードを編集して Schematicsワークスペースを更新してみましたが、同様のエラーで失敗しました。
プラン適用時に環境変数が残ってしまっているのかも?と考え、新たに大阪リージョンの用の Schematicsワークスペースを作成し、変数は大阪リージョンの値を登録しました。
プランの生成・適用を行ったところ、無事成功しました。
変数の値は間違っていないようです。

大阪のワークスペースを確認すると、指定した構成で作成されていました。
Schematicsワークスペースはリージョン毎に分けた方が良いのかもしれません。

以上で検証は完了です。
コード作成の経験がない私でも、Schematicsワークスペースから Power Virtual Server をプロビジョニングすることができました。
サンプルコードはカスタマイズや修正を行えば実行できたので、作業の難易度はそこまで高くありませんでした。
さいごに
いかがでしたでしょうか。
Schematicsワークスペースを利用して Power Virtual Server のプロビジョニング、構成変更、別環境へ同一構成のプロビジョニングを行いました。
コード作成はスキルが必要と思われる方も多いかと思いますが、サンプルコードが提供されているため初心者でも取り掛かりやすいと思います。
検証では1区画のみの作成でしたが、複数区画作成する場合は GUI で作業するよりもコードを定義し Schematicsワークスペースから実行した方が工数・ミスを削減できるのではと感じます。
また、ワークスペース上で変数のデフォルト値が保持されているため、デフォルト値に戻したい場合はクリック一つで設定を戻すことができ、デフォルト値がわからなくなるといったミスを防ぐことができます。
別環境へのプロビジョニングでは変数を上書きしてもプランを適用できなかったため、別リージョン専用のワークスペースを作成しました。
明らかな原因を突き止めることができなかったのですが、環境ごとに Schematicsワークスペースを分けた方が運用面では管理がしやすいですね。
また今回は検証しませんでしたが、ベータ版の Schematics Blueprints は定義したコードをモジュールとして取り扱い・組み合わせることで大規模環境をデプロイすることができる機能です。
例えば本番環境と同一構成を別リージョンに作成したい場合、通常は一つ一つリソースをプロビジョニングし別環境にも同じ作業を行います。
コードを定義し Schematics Blueprints を使用すればコードを組み合わせて環境をデプロイできるため、作業工数の削減が期待できます。
システムの構築は設計から始まり、構築、試験の実施、運用手順書の作成など多くの過程があり、長い時間と労力が必要です。
昨今 Schematics をはじめとする IaC の実現ツールが徐々に広まりつつありますが、これからは従来の構築作業がコードとツールを利用した作業や運用に移行していくかもしれません。
最新情報
2023年8月23日に Terraform バージョン0.x が2023年9月末で営業活動終了、2024年9月末にサポート終了されることが発表されました。
既存でバージョン0.xをご利用されている場合は2024年9月末までにバージョン1.x以上にアップグレードする必要があります。
Schematics に限らず、IBM Cloudサービスの営業活動終了/サポート終了などは定期的に発表されますので、留意してご利用いただくことが重要です。
お問い合わせ
この記事に関するご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
E-Mail:nicp_support@NIandC.co.jp