
ここ数年、IT運用の複雑性が問題視されています。この複雑性が従来のアプリケーションと最新のアプリケーションを同時に稼働させることを困難にしているからです。
そのため、市場投入の遅れや高額な運用コストが生じ、企業がROIを最大化しながら迅速にトランスフォーメーションを実施するための障害ともなっています。
これは IBM WebSphere Application Server(以下 WAS)のユーザーにとっても同様の課題です。
本記事では、WASの抱える課題と、既存の環境を変更することなく WASの運用を自動化・一元化することでアプリケーション・ワークロードの実行にかかる時間と労力を節約し、さらに、セキュリティとレジリエンシー、パフォーマンスを向上させる「IBM WebSphere Automation」について解説します。
Index
- WebSphereブランドの中核製品「IBM WebSphere Application Server」
- WASユーザーが抱える悩み
- WASの運用を自動化・一元化する新ソリューション「IBM WebSphere Automation」
- IBM WebSphere Automation活用の3つのメリット
- Cloud Pak for Watson AIOpsとの連携でより効率的に
- ぜひ、エヌアイシー・パートナーズにご相談ください
- この記事に関するお問い合わせ
- 関連情報
WebSphereブランドの中核製品
「IBM WebSphere Application Server」
IBMのミドルウェア・ソフトウェアブランド「WebSphere」の中で最も有名な製品が「IBM WebSphere Application Server (WAS)」です。
WASは、多くのミッションクリティカルを支える商用の Webアプリケーションサーバーとして1998年から提供されており、安定稼働が評価され長年にわたり多くのユーザーに利用されてきました。
WASの特長は、Webアプリケーション環境の一般的な3層構造 (Webサーバー・アプリケーションサーバー・DBサーバー) のうち、WAS単体で “Webサーバー” と “アプリケーションサーバー” 両方の機能を提供できることや、Webサーバーからリクエストを受け Java/PHP/Ruby などで作成されたアプリケーションを実行し、動的なコンテンツの生成が可能なことにあります。
さらに、負荷分散機能を持ったエディション “Network Deployment” により、大規模環境にもこの製品1つで対応が可能です。
また、ワークロード全体の可視性を高めエンタープライズ・アプリケーションを分析し、Kubernetes への対応を促進できるように設計されていることも、WASが多くのユーザーに活用される理由となっています。
WASユーザーが抱える悩み
多くのミッションクリティカルなシステムを支える基盤ミドルウェアとして長年にわたり企業に選ばれ活用されてきたWASですが、この歴史があるからこそ浮上する課題もあります。
それが「運用効率の低下」です。例えば、以下のようなことが起きています。
- システムのサイロ化によってWASが複数のシステムにまたがって運用されており、それぞれを個別に管理しているため人手がかかる
- Webアプリケーションシステムのセキュリティ強化のためには、開発したアプリケーションだけではなく基盤であるWASの脆弱性を把握して速やかにパッチを適用することが重要だが、一括で状態が確認できず、調査・適用に手間がかかる
- 多くのミッションクリティカルシステムを支える基盤ミドルウェアであるのに、企業全体で一貫したポリシー適用が難しい
これらWASが抱える問題を、費用対効果や脆弱性対策などの観点から解決するのが
「IBM WebSphere Automation」です。
WASの運用を自動化・一元化する新ソリューション
「IBM WebSphere Automation」
2021年5月12日、8つの新ソリューションの1つとしてIBMがオンラインイベント “Think 2021” で発表したのが、「IBM WebSphere Automation」です。
IBM WebSphere Automation なら、サイロ化したシステムに散在するWASの運用を、自動化かつ一元化することが可能です。既存環境の変更は必要ありません。
同時に、一貫したポリシーの適用を実現することで脆弱性対策を強化し、レジリエンシーとパフォーマンスの向上も実現します。
これにより、運用/管理の手間とコストを減らしアプリケーション開発にかける時間を創出。
アプリケーションの迅速な市場投入を可能にすることで、ROIを最大化します。
それでは、IBM WebSphere Automation活用の各メリットを詳しく見ていきましょう。
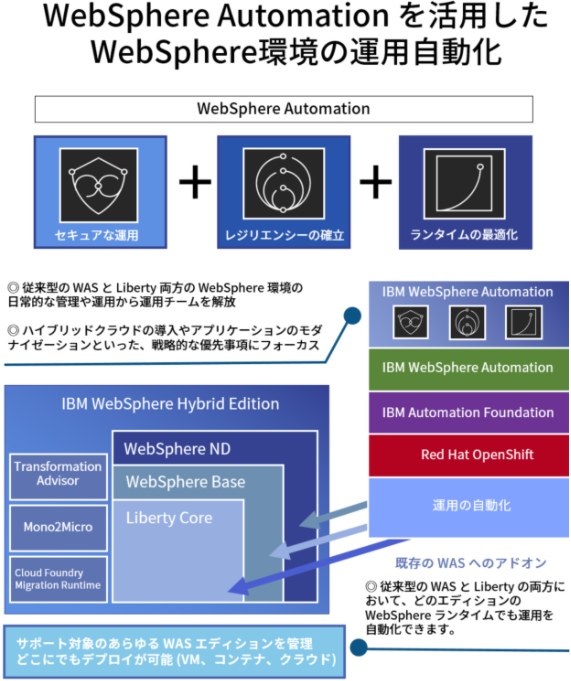
IBM WebSphere Automation活用の3つのメリット
1. 一貫したポリシーを適用したセキュアな運用
IBM WebSphere Automation は、サイロ化した各システムに散在するWASの管理を一元化することでリスクを低減し、コンプライアンスに厳格に対応します。
管理の一元化により、一貫したポリシー適用が可能になるだけでなく単一のダッシュボードを使用することで、運用チームが最も関連性の高い情報にアクセスすることを容易にします。
また、潜在するリスクに対しても自動的にリスクを検知し、各システムに散在するWASに対してパッチを効率的に配布することによって、DevSecOps をより積極的に実践することが可能になります。
2. 運用のレジリエンシーを確立し、イノベーションのための時間を創出
IBM WebSphere Automation は、WASの管理や運用を自動化することで煩雑な手作業を削減し、最適なリソース活用を通してコストと時間を節約します。
自動化によってルーティーン作業を削減し障害を素早く復旧することで、チームの対応能力強化に寄与し運用の効率化とレジリエンシーを確立します。
これにより、人手不足の解消、さらに、WASやLibertyの環境管理にかかるコストとその複雑性を最小限に抑えることが可能になります。
また、WASの運用管理工数の削減でチームの時間をより価値の高い活動にあてることができるため、イノベーションのための時間や機会を 生み出すことも大きな効果です。
3. 運用パフォーマンスの向上
IBM WebSphere Automation を活用し、様々な環境からの情報を統合するダッシュボードを活用することで、個々の環境を確認しなくてよくなるため運用効率を改善できます。
また、作業の自動化を行うことができるため、様々な環境に共通したベストプラクティスを展開することで安定稼働を実現できます。
これらにより、運用パフォーマンスを向上することができるため、コスト削減だけでなく安定稼働が可能となります。
Cloud Pak for Watson AIOpsとの連携でより効率的に
さらに IBM WebSphere Automationは、「IBM Cloud Pak for AIOps」との連携でより効率的なWASの運用管理を実現することができます。
IBM Cloud Pak for AIOps は、AIを活用してIT運用の課題を解決できる運用基盤で、監視データを集約・分析し、現在なにが起こっているのかをリアルタイムに捕捉。問題発生をとらえ影響範囲を予測し、対処方法を提案します。
これらは、1つのダッシュボードで運用全体を確認できるため、複雑でサイロ化されたマルチクラウド/ハイブリッドクラウド環境でIT運用が抱える課題の迅速な解決を可能にします。
IBM Cloud Pak for AIOps は、予兆を検知することでプロアクティブ (積極的) な保全活動もできるようさらに製品を進化させており、今後の動向にも注目したいところです。
ぜひ、エヌアイシー・パートナーズにご相談ください
エヌアイシー・パートナーズは IBM Value Add Distributor として、お客さまの課題に対し長年の実績とIBM製品への深い理解を持って、IBM製品を組み合わせた複合的な解決策をご提案しています。
以下に当てはまる顧客の課題を解決したい方は、ぜひ、エヌアイシー・パートナーズまでご相談ください。
- クラウド・テクノロジーに関する経験が乏しく、お客様の運用提案ができていない
- お客様にアプリケーションサーバーの高額な運用コストの削減提案を実施したい
- お客様が利用しているWAS環境は様々な企業が個別に導入しているため、一貫したポリシー適用が難しい
- WASの脆弱性対策が一貫してできていない
- 費用対効果を最大化できるソリューションを採用したい
- 構築スキルの習得が難しい
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBM WebSphere Application Server (WAS) (製品情報)
- 【やってみた】WebSphere Hybrid Edition導入してみた:OpenShift導入編 (ブログ)