
今後の基幹業務システムは、クラウド化・コンテナ化が進み、オンプレミス、クラウドを問わず稼働します。
クラウド環境とオンプレミス環境/プライベートクラウドを併用するハイブリッドクラウド、もしくは複数のクラウド環境を併用するマルチクラウドで稼働する企業システムの一元管理を実現するためには、従来の SoR*1 システム、およびクラウド・ネイティブな SoE*2 システムを、シンプルに統合管理していくことが必要になります。
この記事では、複雑化するマルチクラウド管理の現状を解説するとともに、ハイブリッド・マルチクラウド環境に対応し、効率的に IT基盤を管理する「IBM Cloud Pak for Multicloud Management」をご紹介します。
*1. SoR(System of Records):
「記録のためのシステム」の意味。社内に従来から存在する分断化されたレガシーシステム
*2. SoE(System of Engagement):
顧客とのつながりを作り・維持し、絆を生むために、顧客視点を基に構築した新しいITシステム
Index
- これからのIT基盤管理における中核は、ハイブリッド/マルチクラウドの統合管理
- ハイブリッド/マルチクラウド環境の統合管理ソリューション「IBM Cloud Pak for Multicloud Management」
- ICP4 MCMの3つの価値
- この記事に関するお問い合わせ
- 関連情報
これからのIT基盤管理における中核は、
ハイブリッド/マルチクラウドの統合管理
業務の効率化・生産性向上の実現を目的としたクラウド・ベースのサービスを利用するために、オンプレミス環境だけに留まらず、ハイブリッドクラウド、もしくはマルチクラウドを活用する企業が急増しています。
ところが、戦略的にハイブリッド/マルチクラウド環境を活用している企業はあるものの、効率的な管理ができている企業はまだ限られているのが現状です。
オンプレミス環境だけではなく、ハイブリッドクラウドやマルチクラウドを積極的に活用する “ハイブリッド/マルチクラウド戦略” は、プライベートクラウドとパブリッククラウド双方の最も良い点を組み合わせるため、莫大な価値を企業にもたらします。
一方で、この複雑なハイブリッド/マルチクラウド環境には、混在するアプリケーションやシステム基盤およびデータ、複数のクラウドと複数ベンダー、そしてクラウド・テクノロジーには、それぞれベンダー独自の運用・管理ツールを利用する必要があります。
それぞれの環境が独立した管理となるため、クラウドのコストと管理の最適化を運用管理上の大きな課題として挙げる管理者も少なくありません。
これからマルチクラウド環境の導入を検討している方は、複数の環境を管理することが必要となること、また、この課題を解決する必要があることを理解しなくてはなりません。
ハイブリッド/マルチクラウド環境を効率的に管理するには、最適なパフォーマンスと利便性を維持しながらコストをコントロールできるだけでなく、セキュリティも保護できなければなりません。また、ハイブリッドクラウドの要件に合わせて、オンプレミスのレガシー・ネットワークを改良する必要もあります。
クラウド環境との効率的な連携を実現するためのネットワークには、信頼性・柔軟性・拡張性・安全性が求められます。運用負荷の軽減と柔軟性の確保を目的に、仮想化および自動化テクノロジーを活用しネットワークの管理を簡素化することで、更なる運用効率の向上を検討する必要がでてきます。
つまり、基幹業務のクラウド化・コンテナ化が進み、オンプレミス、クラウドを問わず複雑なハイブリッド/マルチクラウド環境を活用する今日の企業がこれらの課題を解決するためには、企業システムが稼働する環境を効率的に管理する「一元管理」の実現が必要なのです。
例えば、どの環境でどのアプリケーションが稼働しているのか、そのアプリケーションの負荷がどの程度なのか、を把握しコントロールすることで、アプリケーションの負荷を最適化し、無駄なアプリケーションの稼働を削減することができます。
それによってクラウド環境で利用するリソースを最適化できるため、コスト削減につながります。
今回ご紹介するようなオールインワンのハイブリッド/マルチクラウド管理ソリューションは、管理コストを削減するだけでなく、環境の選択肢を拡大します。
また、セキュリティとガバナンスを向上させ、ワークロードごとのニーズに基づいた柔軟なアプリケーション展開を可能にします。
ハイブリッド/マルチクラウド環境の統合管理ソリューション「IBM Cloud Pak for Multicloud Management」
「IBM Cloud Pak for Multicloud Management (以下、ICP4 MCM)」は、Red Hat OpenShift 上で稼動し、ハイブリッド/マルチクラウド環境を統合管理するソリューションです。
ICP4 MCM は、ハイブリッド/マルチクラウド環境全体にわたって複数の kubernetesクラスタを統合管理し、ガバナンスの強化、VM/コンテナ基盤のプロビジョニングの自動化、および共通化を提供します。
さらにアプリケーション展開後には複数のソースからのイベントを統合し、SoR/SoE 問わず統合モニタリングを実施することで障害の解決を速やかに行うことができ、可用性の向上にも寄与します。
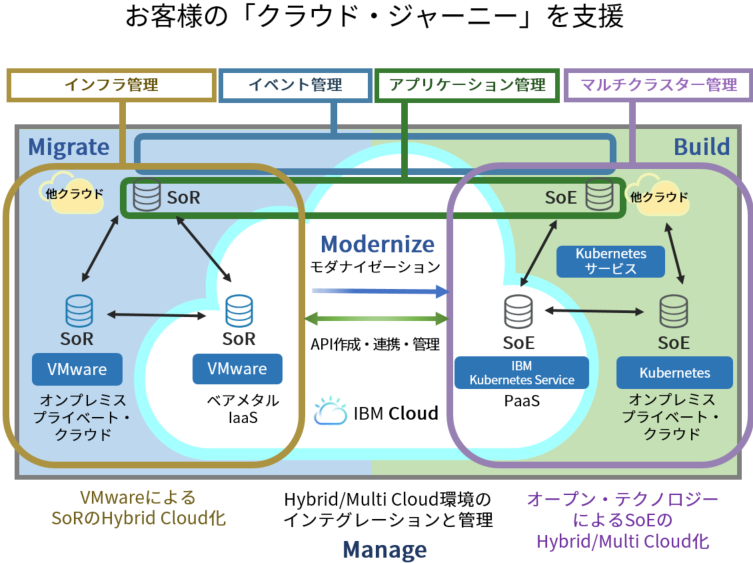
ICP4 MCMの3つの価値
ICP4 MCM の機能は大きく「インフラ管理」「マルチクラスタ―管理」「イベント管理/アプリケーション管理」の3つに分けられます。
概要は以下の図になります。

これらの機能も含めて、ICP4 MCM が提供する価値は大きく以下の3つです。
- ハイブリッド/マルチクラウド環境への仮想マシン/コンテナの迅速な展開
(「インフラ管理」「マルチクラスタ―管理」機能) - イベント統合・統合モニタリングによる問題判別と解決スピードの向上
(「イベント管理/アプリケーション管理」機能) - オープン・テクノロジーのサポートを提供するマルチクラウド運用管理基盤
(IBMによるサポート)
それぞれについて説明をしていきます。
1. ハイブリッド/マルチクラウド環境への仮想マシン/コンテナの迅速な展開
ICP4 MCM は、オンプレミスやプライベートクラウド、パブリッククラウドを併用するハイブリッド/マルチクラウド環境において、仮想マシン/コンテナの展開を自動化することでサーバーの構築作業を最小限にし、アプリケーションの展開を素早く実施できます。
仮想マシンの展開はテンプレートから行うため、同じアプリケーションを複数の環境(例えば、オンプレミス環境と IBM Cloud環境それぞれ)へ展開することができます。
コンテナ環境においては、複数の kubernetesクラスタを統合管理することができるため、クラスタをまたがったアプリケーションの一貫したデプロイ、アップデート、管理を実現でき、リソース効率を最大化します。
アプリケーションの展開を速めることで、お客様の DX がより円滑に進められます。
2. イベント統合・統合モニタリングによる問題判別と解決スピードの向上
ICP4 MCM は、ハイブリッド/マルチクラウド環境で発生するイベントを統合し、イベント/インシデントの相関処理・優先順位付けを行うことで、環境が複雑になるのに従い長期化しやすくなっている障害対応を迅速化します。
また、アラート通知の自動化やタスクの自動化機能により、繰り返し発生する問題を解決するための工数を削減します。
3. オープン・テクノロジーのサポートを提供するマルチクラウド運用管理基盤
ICP4 MCM は、VM およびコンテナ基盤のライフサイクルを一元管理するためのオープン・テクノロジーを IBM のサポート付きで利用できます。
ICP4 MCM のすべての管理コンポーネントはコンテナ対応済みで、Red Hat OpenShift 上で稼働するために最適化されています。
また、これらのコンテナは Red Hat で認定済みであることに加えて、IBM 認定済みのソフトウェアとして事前統合されており、IBM がサポートをするので安心して利用することができます。
このように、全社レベルでクラスタを統合管理し、アプリケーション展開速度の向上や問題対応に活用することで、ICP4 MCM はお客様のIT管理とモダナイゼーションを支援します。
また、ハイブリッド/マルチクラウドの環境を一貫した構成と共通のセキュリティ・ポリシーで管理し、オンプレとクラウドに同じ基準・ルールを適用することで、既存のレガシーシステムの運用に加えて新規のクラウド・ネイティブ技術ベースのアプリケーションも統合的に管理することが可能となり、コストを削減することも可能です。
さらに、アプリケーションの実行環境が必要なときにも、従来は数日から数週間かかっていたのに対し、即日(場合によっては数分程度)で環境を手に入れることができるのです。
*DXの進化を支える基盤- IBM Cloud Paks*
レガシーシステムの問題点を解決し、オープンなコンテナ技術によるアプリの可搬性の向上とオープンなオーケストレーションによる管理・運用の効率化を実現するのが、プラットフォームを最適化するIBM のソリューション「IBM Cloud Paks」です。
IBM Cloud Paksは、エンタープライズにおけるユースケース別に6製品を、オンプレミス、プライベートクラウド、パブリッククラウド、エッジ・コンピューティングと同じアーキテクチャーで提供しており、これらを活用していくことで、モダナイゼーションを効率的に進めていくことができます。
また、企業固有のアプリケーション、データ、ワークロードの要件に対応する、最適なアーキテクチャーと手法を選択できます。IBMのハイブリッド・マルチクラウド・プラットフォームは、Linux や kubernetes などのオープン・テクノロジーに基づいているため、選択したクラウド上でデータやアプリケーションを、安全に展開・実行・管理でき、将来にわたってロックインされるリスクもありません。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは、「こちら」からお願いします。
関連情報
- IBM Cloud Pak for Multicloud Management のご紹介 (資料) ※会員専用ページ
– IBM Cloud Pak for Multicloud Management の概要ご紹介資料です。 - IBM Cloud Paks シリーズ ご紹介資料 (資料) ※会員専用ページ
– 6つの Cloud Paks について、お客様の理解度に応じて必要な資料を選択できる形式になっています。
【外部サイト】