
IBM Cloud Pak for Applicationsの新規販売は終了いたしました。
今後のアプリケーションランタイムソリューションは、
現在、日本の多くの企業にとって「2025年の崖」をいかに克服するかが大きな課題となっている中で、レガシーシステムの抱える数々の問題が足かせになっています。
本コラムでは、”企業が抱えるレガシーシステム特有の課題を解決してデジタルトランスフォーメーション(以下:DX)を実現するためには、なぜ新しいアプリケーション開発や既存アプリケーションのモダナイゼーションが必要なのか?” について考察します。
Index
- DX実現にアプリケーションのモダナイゼーションが必要な理由
- モダナイゼーションの事例
- アプリケーションのモダナイゼーションを推進する「IBM Cloud Pak for Applications 」
- この記事に関するお問い合わせ
- 関連情報
DX実現にアプリケーションのモダナイゼーションが必要な理由
レガシーシステムが抱える問題
2000年代に構築した基幹システムを現在に至るまで改修を繰り返しながら利用しているケースは珍しくありません。これらのシステムは今や15年〜20年が経過しており、レガシーシステムと呼ばれています。
既存のレガシーシステムは属人性が高く、さらに、レガシーシステムを運用・保守できるスキルを持った人員は不足しているので、それにともなう運用・保守コストの増大は大きな課題です。また、アプリケーションの改修に数ヵ月単位の工数がかかってしまうため、柔軟性や迅速性の低下も課題となっています。
レガシーシステムを抱える企業の問題
- システム開発・管理の「属人化」による、弊害
- 運用・保守のコスト増大による、新規開発への投資不足
- スキル要員の不足による、新規案件への対応の遅れ
- 「外部連携ができない」システムによる、デジタル・ビジネス創出の損失
- アプリケーション構造による、業務の拡大や変化に対する制約
- データへのアクセスの難しさによる、データ資産の利活用不足
- ビジネススピードを左右する、「アプリケーションの開発サイクル」の遅れ
- 迅速性・柔軟性の低下による、新業務・新商品の投入の遅れ
- 複雑化した構造による、開発・保守の生産性・品質の低下
これらレガシーシステムを抱える企業の問題は、DX がめざすビジネス変革に対する制約となっており、差し迫った足元の課題としてこれを解決することが必要不可欠です。
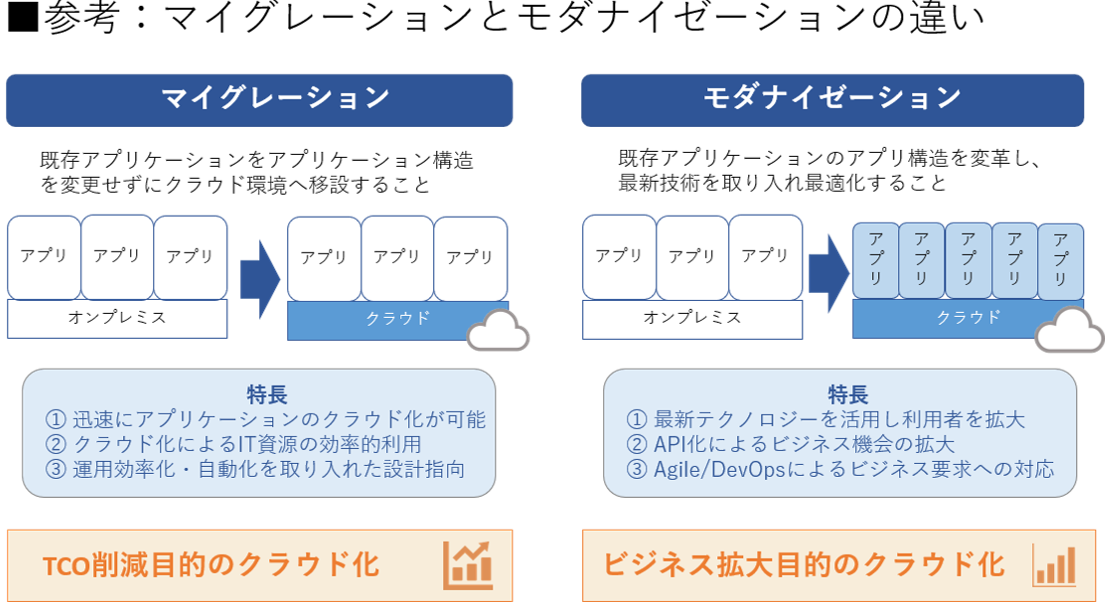
「マイグレーション」と「モダナイゼーション」の違い
レガシーシステム特有の課題を解決し DX を実現するために不可欠な手法として、「モダナイゼーション」があります。
モダナイゼーションを検討するにあたっては、まず「マイグレーション」と「モダナイゼーション」の違いを知っておくことが大切です。
マイグレーションとは、「TCO削減」を目的としたクラウド環境への移行
マイグレーションは、TCO(総所有コスト)の削減を主要な目的としたクラウド化のことをいいます。具体的には、既存のアプリケーションの構造を変えることなくクラウド環境に移行することです。
マイグレーションによる成果としては主に以下が挙げられます。
-
- 迅速にアプリケーションのクラウド化が可能
- クラウド化による IT資源の効率的利用
- 運用効率化・自動化を取り入れた設計指向
モダナイゼーションとは、「ビジネス拡大」を目指すクラウド・ネイティブ化
モダナイゼーションは、マイグレーションによりコスト削減を狙う領域を見定めつつ、戦略領域についてはモダナイゼーションによりビジネス拡大を目指すクラウド・ネイティブ化のことをいいます。具体的には、クラウド・ネイティブ化することで既存アプリケーションのアプリケーション構造を変革し、最新技術を取り入れ最適化することです。
モダナイゼーションによる成果としては主に以下が挙げられます。
-
- 将来にわたってアプリケーションの保守・管理が継続できる環境を整備
- API化によるビジネス機会の拡大
- Agile/DevOps (アジャイル/デプオプス) によるビジネス要求への迅速な対応
クラウド・ネイティブ化のメリット
このように、アプリケーション・モダナイゼーションは現行のアプリケーションを最新技術で更改し、「ビジネスの成長と拡大」を目的として「クラウド・ネイティブ化」することで新たな価値を生み出すよう変革することを意味します。
クラウド・ネイティブとは「クラウドの利点を徹底的に活用するシステム」を意味しており、様々なクラウドサービスを利用して開発・構築された、クラウドでの運用を前提としたシステムやサービスです。
そのメリットは、既に提供されているサービスを使うことによる開発期間の短縮や、アプリケーションを細分化することにより改修時の影響範囲が小さくなることによって修正期間・工数の削減ができる、などが挙げられます。昨今では、IaaS を用いて既存のシステムを最小限の改修でクラウドに移行し、その上で、PaaS や SaaS を活用してクラウド・ネイティブに作り替える「リフト&シフト」と呼ばれる手法も広まっています。
つまり、アプリケーション・モダナイゼーションによってレガシーシステムを「クラウド・ネイティブ化(Shift)」することでアプリケーション開発および管理の場を最適化し、レガシーシステムの課題であった「可用性」「スケーラビリティ」「リリースまでの期間短縮」などの問題を解決することができるのです。
参考)「CNCF Cloud Native Definition v1.0」
モダナイゼーションの事例
2018年に経済産業省の DXレポートが公開されて以降、多くの企業がブラックボックス化したレガシーシステムを様々なレベルで刷新し、「2025年の崖」を克服するべく DX 実現のための IT基盤整備に取り組んでいます。
ここで、モダナイゼーションの事例を幾つか紹介しましょう。
サイロ化されたインターネットサービスを改善
この企業では、部分最適によってサイロ化され、利便性が低くなったインターネットサービスを改善する必要に迫られていました。
アプリケーションフレームワークに Struts* を採用していたためにセキュリティ上の問題も抱えており、そのほかにも、各種キャッシュレス決済の技術を採用することや、ソーシャルメディア連携を強化して新しいビジネス領域を開拓する必要もありました。
これに対して同社は、ToBe アーキテクチャとして、フレームワーク更改や PaaS化、コンテナ化/マイクロサービス化、DevOps 適用を採用。
最新のアプリケーションフレームワークを導入し、コンテナ化による保守性と拡張性の高いアプリケーション構造を実現しました。さらに、DevOps によって新しいサービスをタイムリーに実装・展開できるようになりました。
*Struts : Java Servlet API を拡張してMVC (Model, View, Controller) アーキテクチャを採用した、オープンソースのフレームワーク
レガシーシステムに散在していた顧客データを収集・集約
またある企業では、顧客データが事業ごとに散在して再利用が困難になっており、ガバナンスにも課題がありました。また、システム構造がサイロ化していたため、アプリケーションのリリースサイクルが長期化していることも問題となっていました。
これに対して同社は、ToBe アーキテクチャとして UXモダナイゼーション、SoE/SoR分離、コンテナ化/マイクロサービス化、DevOps 適用を採用。
レガシーシステムに散在していた顧客データを収集し、IBM が提唱する、次世代アーキテクチャに従った変化に強いデジタルサービス層に集約しました。さらに、マイクロサービスのアプリケーションをコンテナで実装することで柔軟性の高いシステム構造を実現しています。
レガシーシステムのデータはそのままに、メインフレーム資産を API連携
メインフレームを利用していたある企業は、レガシーシステムのデータはそのままに、フロント側の各チャネルにデータを提供したいと考えていました。
これに対して同社は、ToBeアーキテクチャとして API化、SoE/SoR分離、コンテナ化/マイクロサービス化を採用。次世代アーキテクチャのデジタルサービス層にアプリケーション基盤、API管理基盤を設けることで、メインフレーム資産をシンプルに API連携させています。
アプリケーションのモダナイゼーションを推進する
「IBM Cloud Pak for Applications 」
モダナイゼーションとクラウド・ネイティブ・アプリケーション開発・実行を
サポートする「IBM Cloud Pak for Applications 」
レガシーシステムの問題点を解決し、オープンなコンテナ技術によるアプリの可搬性向上と、オープンなオーケストレーションによる管理・運用の効率化を実現するのが IBM Cloud Paks シリーズです。
IBM Cloud Paks とは、Red Hat OpenShift 上で稼働するミドルソフトウェア群で、オープンなコンテナ技術によるアプリの可搬性向上と、オープンなオーケストレーションによる管理・運用の効率化を実現します。
Red Hat OpenShift とコンテナ化された IBMソフトウェアを含み、オンプレミス、プライベートクラウド、パブリッククラウド、エッジ・コンピューティングを同じアーキテクチャで提供。エンタープライズでは、オープンソースそのものだけでは難しく、運用の負荷も増大します。
IBM Cloud Paks は、他社の Kubernetesサービスと比べて、運用サービスがエンタープライズ用に共通化されており、ソフトウェアが最適化された形で提供されます。ユースケース別に6製品があり、そのなかで、アプリケーションのビルド、拡張、デプロイ・実行を支援する製品が、「IBM Cloud Pak for Applications」です。
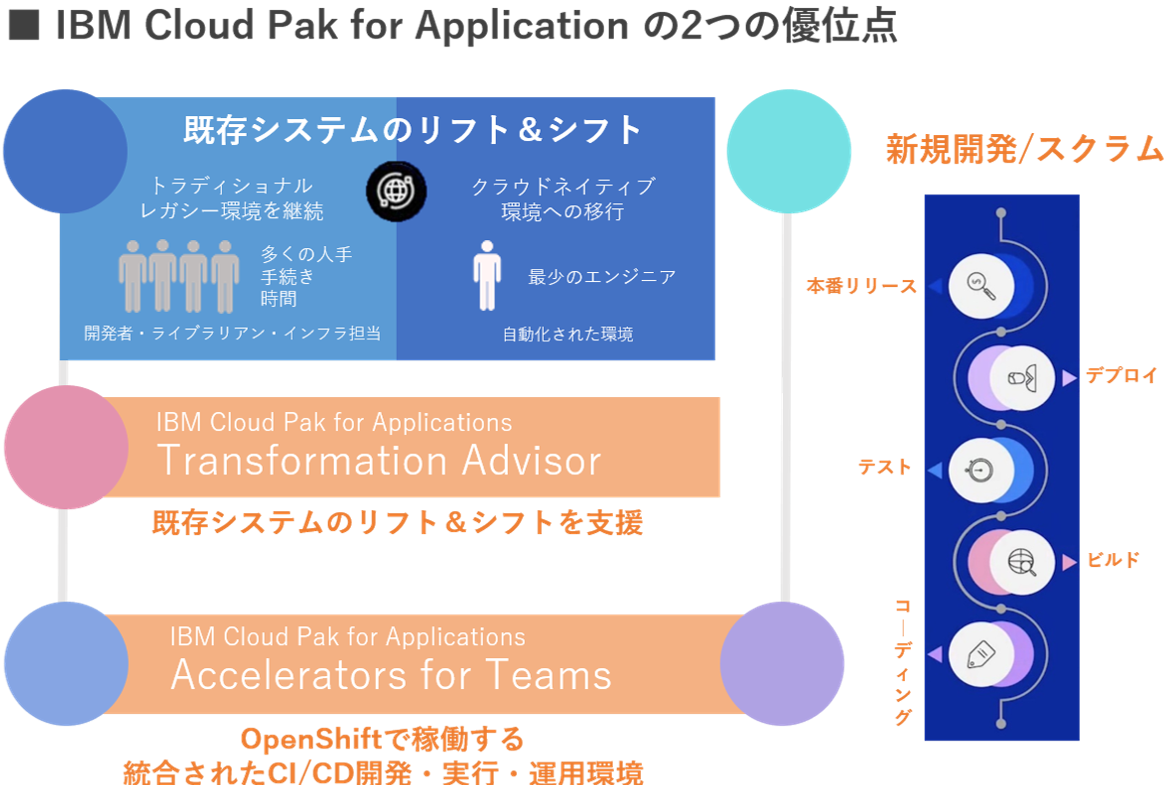
IBM Cloud Pak for Applications の2つの優位性
IBM Cloud Pak for Applications は、既存のアプリケーションを最新化し、Red Hat OpenShift で実行するクラウド・ネイティブのアプリケーションを新規開発するための、エンタープライズ対応のコンテナ化されたソフトウェア・ソリューションとして提供されています。
CI/CD開発・実行環境である「Accelerators for Teams」とコードのモダナイゼーションをアドバイスする「Transformation Advisor」の2つの優位点があり、開発者、IT運⽤者、LOB (Line of Business) それぞれに、大きなメリットを与えます。
「IBM Accelerators for Teams 」は、従来型のアプリケーションのハイブリッドクラウド/マルチクラウドへの移行を支援するとともに、必要なツールとランタイムを使用して革新的なクラウド・ネイティブ・アプリケーションを開発できる基盤を提供します。
また「Transformation Advisor」は、既存のレガシーシステムのアプリケーションをコンテナ上で実行できるかを分析、必要な手順を教示しコンテナ環境への移行をサポートします。
IBM Cloud Pak for Applications の3つの価値
先程ご説明した2つの優位点は、いま必要なものから将来必要となるものまで、お客様にとって3つの価値を提供します。
-
既存アプリの実行 :
現在の環境で、従来どおりアプリケーションを実行
– パブリッククラウド、オンプレミス、プライベートクラウドのどこでもアプリケーションが
実行可能 –
IBM Cloud Pak for Applications は、既存のアプリケーションが存在する場所で実行し、最新化されたアプリケーションと新しいクラウド・ネイティブのアプリケーションをコンテナ内のクラウドにデプロイします。そのため、パブリッククラウド、オンプレミス、プライベートクラウドのどこでも、ビジネスに最適な場所と方法でアプリケーションを実行できます。
また、既存のアプリケーションに対して、オープンソース標準に基づいて構築された統合 Kubernetesプラットフォームである Red Hat OpenShift に合わせたツールを提供するとともに、アプリケーションの実行場所にかかわらずそれらをサポートします。
-
既存アプリのモダナイズ :
コンテナ環境へ移行が必要となったときに、それをサポートする
ツール・知見を提供
– 既存システムのリフト&シフトを支援ツール「Transformation Advisor」を活用可能 –
IBM Cloud Pak for Applications には、既存アプリケーションのモダナイゼーションを支援するツールとして、「Transformation Advisor」が用意されています。これは、オンプレミス環境で実行されていた Java EE のアプリケーションをコンテナ上で実行できるかを分析し、どういう手順が必要かをレポートするなど、既存システムのリフト & シフトを支援します。
また、「WebSphere Migration Toolkit」やローカル開発と連携する IDE 拡張機能などにより、コンテナ環境への移行をサポートします。
-
新規アプリの開発 :
新規アプリケーションをクラウド・ネイティブで作成するための
開発ツールや環境、各種オープンソースを統合して提供
-「Accelerators for Teams」フレームワークに含まれている各種オープンソースを
サポート付きで開発可能 –
IBM Cloud Pak for Applications には、複数のオープンソースを組み合わせてコンテナ上のアプリケーションを開発・テスト・管理できるようにした「Accelerators for Teams (旧 Kabanero) 」が含まれます。
ツールをひとつひとつ組み合わせて開発環境を構築するのは容易ではありませんが、「Accelerators for Teams」は開発者がすぐに使えるかたちで提供されており、しかも IBM のサポートが付いているので安心して利用することができます。
また、テンプレートや管理のためのアーキテクト・ツール、開発者向けツールなども充実。Accelerators for Teams で作成したアプリケーションをテスト・本番で実行するランタイムも各種用意されており、なかでも「Libertyランタイム」はスピーディーな開発に対応する軽量の次世代ランタイムです。これにより、自動化された環境で最小人数のエンジニアでの開発が可能となります。
このように、OpenShift ベースの基盤でコンテナ化することでハイブリッド・クラウド/マルチ・クラウド双方に対応し DX を加速させる IBM Cloud Pak for Applications は、これを利用することで既存アプリケーションの利用、モダナイゼーション、新たなネイティブ・アプリケーションの開発がスムーズに行えるようになります。
アプリケーション・モダナイゼーションを検討する上で、IBM Cloud Pak for Applications はエヌアイシー・パートナーズが自信をもってお勧めするソリューションです。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- 今、デジタルサービスに求められる必須要件とは!?アプリケーションのコンテナ化で得られる5つのメリット (コラム)
– 今注目されている「コンテナ化」。コンテナ化とは?そのメリットとは? - 【やってみた】Cloud Pak for Applications 導入してみた:Cloud Pak for Applications 導入編 (ブログ)
– 今回は、AWS 上に構築した Openshift 環境に Cloud Pak for Applications をインストールします! - IBM Cloud Paks シリーズ ご紹介資料 (資料) ※会員専用ページ
– 6つの Cloud Paks について、お客様の理解度に応じて必要な資料を選択できる形式になっています。