
こんにちわ。
てくさぽBLOGメンバーの佐野です。
2019年7月9日に IBM が RedHat の買収完了を発表しました。
RedHat の買収で IBM が得るものはいくつかありますが、その中でも特に “OpenShift” がハイブリッドクラウドのプラットフォームとして注目を集めています。
IBM は OpenShift を使って、IBM Cloud だけでなく AWS や Azure、GCP 上などのパブリッククラウド上でも簡単に IBM のソリューションを利用できるようにすることを考えています。
それを実現するための製品が “IBM Cloud Paks” シリーズとなっています。
1.IBM Cloud Paks とは?
IBM Cloud Paks には2019年9月17日時点で5つの製品が出ています。

IBM Cloud Paks は単に 既存のIBM のソリューションをコンテナ化して提供しているだけでなく、可用性・拡張性が確保された上で企業ユース向けの様々な機能が実装された状態で利用できるようになっています。
そのため、個別に製品を購入し自力で様々なインフラ設計・設定をする必要がありません。
そんな IBM Cloud Paks シリーズの中でも今回は IBM Cloud Pak for Data(以下 ICP4D)の導入をしていきます。
ちなみに、今回の導入は kubernetes 環境としては OpenShift ではなく IBM Cloud Private を利用します。
2.IBM Cloud Pak for Data
さて、今回導入する ICP4D はそもそもどういうソリューションなのでしょうか?
一言でいうなら、「データ分析のためのプラットフォーム」となります。

ICP4D を使って、データの収集・整形・カタログを整備して分析ツールにデータを渡し活用することができます。
このソリューションが特に効果を発揮するのはデータを分析ツールに渡すための前処理の効率化です。
データのカタログを作るための自動化支援機能(割り当てる用語の推奨やデータクラスの自動判別)を持っているため、人間がゼロから登録をする必要がありません。
また、本ソリューションに組み込まれている製品だけでなく、Add-on として使いたい製品を追加することができるので、「今は使わないけれど将来的に・・・」という対応も可能です。
「データ分析を個別の部署内だけでなくて対象を広げたい」「データ分析のためにいろいろなツールを使っていて運用負荷が高くなってきた」というようなお客様には最適なソリューションとなります。
3.事前準備
ICP4D 導入前の事前準備としては、
- システム要件の確認
- OS の設定
が必要になります。
システム要件は IBM の Knowledge Center を確認しましょう。
Installing Cloud Pak for Data
日本語での表示もできますが、最新の情報を確認する場合には英語表示にしてください。
今回は検証環境なので3ノードクラスタ(Master/Worker の機能を3台に導入する)構成とします。
環境は以下の図のようになっています。
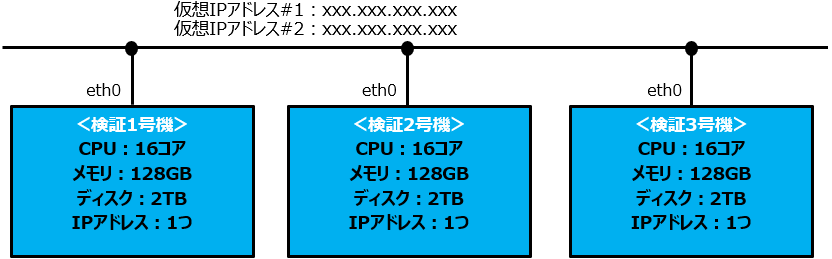
今回はオンプレ環境なので ICP4D の画面へアクセスするために割り当てる仮想 IP を2つ用意します。
また、Add-on を追加で導入するため、CPU /メモリは最小要件よりも多く確保しています。
準備する環境について簡単にポイントを整理しておきます。
<CPU>
最新の CPU であればそれほど気にする必要はありませんが、SSE4.2 や AVX/AVX2 をサポートしている必要があります。
また、10ユーザー程度を想定した要件であるため、追加の Add-on やユーザー数が増加する場合には、コア数を多くした方がよいでしょう。
特にデータ仮想化機能を使う時にはインスタンスを作成するときに CPU やメモリを割り当てる必要がありますので、事前にどの機能に対してどれぐらいの割り当てをするのか検討をしておきましょう。
<メモリ>
メモリについても CPU 同様に、使う機能やユーザー数に応じてどれぐらいのリソースが必要になるかを検討します。
<ディスク>
ディスクについてはシステム要件内にも記載がありますが、root ファイルシステムで最低 100GB、インストールパス (ex. /ibm) で 500GB、データパス (ex. /data) で 500GB が必要になります。
この容量は最小要件なので、追加でインストールする Add-on やデータ容量によって追加のリソースを用意する必要があります。
また、root 容量はインストール前に警告が出てくるので 200GB 程度は割り当てしておいた方がよいでしょう。
ディスクにはパフォーマンス要件もあります。
よっぽど変なディスクでなければ問題ありませんが、Latency テストで 286 KB/s、Throughput テストで 209 MB/s が必要になります。※詳細はこちらの「Disk requirements」パートを参照下さい。
パフォーマンスについてもインストール前にチェックされるため、満たさない場合には警告が出てきます。 ※警告なのでインストールを進めることはできます。
<OS>
OS としては Redhat Enterprise Linux 7.5 以上が必須となります。
OS 設定するポイントが多いので簡単ですが以下にまとめます。
- ネットワークポートへ静的 IP アドレスの付与
- DNS サーバーは必須
- タイムゾーン設定
- 時刻同期設定(chrony)
- Firewall の無効化
- SELinux の設定(permissive)
- インストールパス/データパスに対してファイルシステムの設定変更(noatime 設定)
- First Master ノードから他のノードへの SSH 接続設定(パスワード無し接続)
- (必要に応じて)Docker registry 設定
インストールする環境の準備は以上になります。
事前準備まで完了したら一度バックアップを取得しておきましょう。インストールに失敗した時に、OS を再導入し、1から設定をやり直すのは結構時間がかかりますので。 ※ここは結構重要なポイントです。
4.導入
ICP4D を導入するためのプログラムを Passport Advantage サイトからダウンロードしましょう。
入手方法はこちら
インストールの実行には、当然ファイルに対して実行権限をつけないと進まないので、tar ファイルを解凍した後の “installer.x86_64.nnn” に +x 権限を付与することを忘れずに。
ICP4Dのインストール実行する前に、設定ファイルを作る必要があります。
環境に応じてファイルの内容を変える必要がありますので、こちらを参照しながら設定ファイル(wdp.conf)を作成しインストールパスに配置しましょう。
インストール実行前に事前チェックツールをダウンロードし実行します。
入手方法や実行方法はこちらに記載があります。
エラーや警告が出ていれば何か問題が発生していますので、メッセージをよく読んで解消しましょう。
事前チェックツールの実行をクリアすればいよいよインストールの実行です。
インストールの実行方法は設定ファイル(wdp.conf)作成の URL の項番5に記載があります。
が、インストール実行前にちょっと待ってください。
v2.1.0.2 でのインストールには約2.5時間ほどかかります。(環境や設定によって前後することがあります。)
インストール開始後にコンソールを切断すると途中経過が分からなくなってしまうので、十分な時間を確保した上で実行するか、screen 上で実行して、切断した後でも途中経過が分かるようにしておくことをお勧めします。
また、インストールのログは以下のディレクトリ下に “wdp ほにゃらら”というファイル名で出力されているので、必要に応じて確認してください。
(インストールパス)/InstallPackage/tmp/
インストールを実行したコンソール上で出ないログも表示されるので、止まっているように見える場合にはこちらも確認した方がよいかもしれません。
※インストールイメージを他ノードへ転送するところで結構時間がかかる場合が多いです。
インストール完了するまでの間ずっとログを見ていてもよいですが、(上記のような時間がかかる処理で)止まったり、Warning が大量に出るとドキドキヒヤヒヤしますので、「止まったら対処する」ぐらいの気持ちでいた方が精神衛生上よいです。
5.ICP4D 導入後
環境や構成にも依存しますが ICP4D v2.1.0.2 では約2.5-3時間程度で導入が完了するので、その間はひたすら待ちます。
インストールが無事に終わると、以下のようなメッセージが出てきます。
Installation was successful and took 02:55:05
Access the zen web portal using the following URL: https://xxx.xxx.xxx.xxx:31843
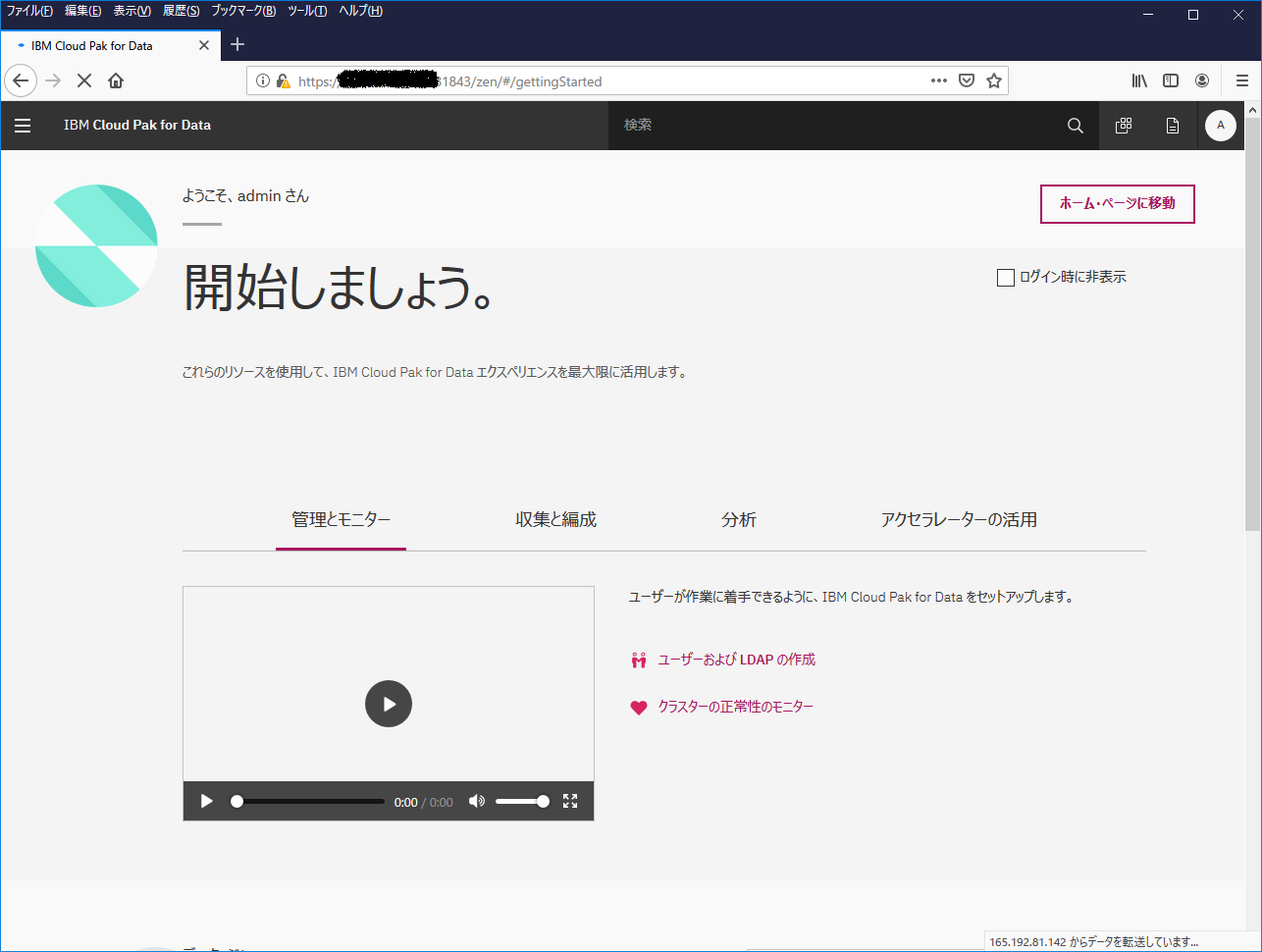
このメッセージが表示されれば無事 ICP4D の導入は完了です。記載されている URL にアクセスをして ICP4D の画面にログインしてみましょう。
ログインできて下のような画面が表示されれば OK です。必要に応じて Add-on の導入などを実施ください。
※画面表示はブラウザの言語設定に依存します。添付画面は日本語設定になっているので日本語で表示されていますが、英語表示になっている場合にはブラウザの言語設定をご確認下さい。
Add-on の導入については Knowledge Center に記載がありますので、導入する Add-on 毎に用意するもの・手順をご確認下さい。該当箇所はこちら。
もし、エラーや Warning がログ上に表示されるようであれば、各ノードに対して設定変更をするなどで問題を解消するように対処して下さい。
6.まとめ
ICP4D のインストーラは自動化されており、実行したらインストールが完了するまで人間が何か操作をする必要がありません。(最初に Y や A や Enter を押す必要はありますが。)
半面、途中でインストーラがエラーで止まってしまうと retry で先に進められれば問題は無いのですが、同じ場所で何度も止まってしまい、先に進まない場合にはエラーの原因を取り除くために多大な労力がかかります。
なので、本番導入前に何度もインストールを試してみるといった事前準備をしっかりしておくことが重要です。
OS 設定が漏れている、必要スペックが不足している、などの環境・事前設定以外の要因で止まってしまった場合には、原因究明や対処が難しい場合がほとんどです。
同じ環境・設定であっても OS レベルから再導入することでうまくいくこともあるので、うまくいかない場合には自力での問題解決にはある程度で見切りをつけて OS レベルから再導入することもご検討ください。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp