
こんにちは。
てくさぽBLOGメンバーの佐野です。
最近世間で業務の効率化ツールとして注目を集めているソリューションであるRPA(Robotic Process Automation)。
どんなソリューションなのか?どういうところに適用する(できる)のか?が言葉を聞いただけではなかなか理解しづらいので、今回はRPAの概要編ということで解説をいたします。
1.RPAって?
RPAは”Robotic Process Automation”の略です。”Robotic”とあるので、Pepperのようなロボットを想像するかもしれません。
または、工場などに設置されているような製品を組み立てるために使う機械を想像するかもしれません。
実はRPAでいう”ロボット”は物理的なロボットではなく”ソフトウェアのロボット”を指します。ソフトウェアなので、”パソコン上の操作を自動化する”ためのロボットとなります。
よくあるRPAの使い方の例としては以下のようなものがあります。
例1:Excel(CSV)で受け取ったお客様情報一覧を社内の顧客管理システムに入力する
例2:ECサイトを巡って自社製品の実勢価格を一覧としてExcelにまとめる
上記のようなことを実現できる、PC操作を自動化するためのソフトウェアロボ=RPA なわけですが、RPAが最も威力を発揮するのは複数のアプリケーションをまたぐ操作の自動化です。
Excel内で完結する処理なのであれば、マクロで済んでしまいますが、RPAはExcelをはじめとした、Webブラウザや専用アプリケーション間のデータの橋渡しができるソリューションです。
例えば、顧客マスタのExcel(CSV)を元に顧客管理システムと販売管理システムのそれぞれに顧客情報を登録することができます。
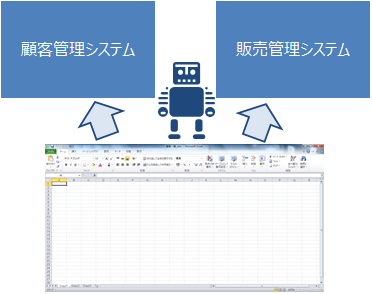
世の中にはRPAソリューションが多数ありますが、大きく2種類の特長に分類できます。
- サーバー実行型
- デスクトップ実行型
サーバー実行型は実行するロボットをサーバー上で管理します。特に多くのロボットを稼働させる場合には実行スケジュールの調整やスケールアウトの柔軟性が高いという点でも集中管理する場合にはサーバー型が最適です。
それに対してデスクトップ実行型はユーザーの端末上でロボットを稼働させることができます。サーバーを用意する必要がないため、すぐに始められる(スモールスタートできる)ところが良い点です。
デスクトップ実行型はRDA(Robotic Desktop Automation)と呼ばれることもあります。
サーバー実行型・クライアント実行型のどちらがよいのか?という問いには、それぞれにメリット・デメリットがあるのでケース・バイ・ケースとしか言えません。どのような業務を対象とするのか、どの程度の規模になるのかによって、最適なものを選択する必要があります。
海外製品も含めたRPAのメジャーな製品を分類すると以下のようになります。

2.RPAを使うとどういう効果があるの?
RPAを導入すると以下の効果が見込めます。
- 人為的な操作ミスによる手戻りの削減
- 業務のスピードアップ・効率化
- 人間がより付加価値の高い仕事に時間を割けるようになる
また、RPAを導入する際に業務プロセスの見直しをすることが多いので、副次的な効果として、業務プロセスの簡素化を実現することもあります。
RPAを導入することによって効果が大きくなる業務は以下のようなパターンです。
- 業務の量が多く、転記やシステムへの入力といった操作の繰り返し
- 同じ内容(例:お客様情報)を複数システムへ登録
他には、RPA単体ではなくOCR製品と組み合わせて帳票の読み取りからシステムへの入力までを自動化する、という業務も効果が大きくなります。
このように、人間の判断が比較的少ない操作をRPAにより自動化することで従業員のワークロード削減に繋がります。
さらに、対象業務によってはお客様の待ち時間が減少し、顧客満足度向上につながる、なんてことも有り得ます。
具体的な例として、弊社内で実装した例を以下に挙げます。
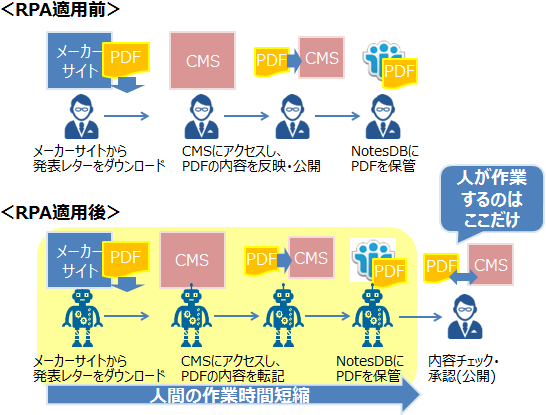
この例では、メーカーのサイトにある発表レターを弊社のサイトに掲載する業務の自動化になります。
この仕組みを実装することで、人間が定型的・定期的に実行していた業務の一部を自動化でき、メーカーサイト・CMS・Notesと3か所あった作業ポイントがCMSのみの1か所に集約できています。
3.RPAでロボットを作るにはどうしたらよいの?
製品にもよりますが、ロボットは主に以下の2種類の方法で動作を定義することができます。
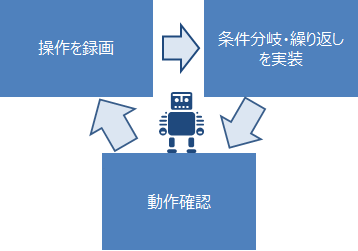
1.操作を録画し再現する
2.操作を手作業で定義する
最もお手軽なのは1.による録画ですので、この機能を利用することが基本となりますが、人間が実行した操作を記録するだけなので人間が頭で判断しているコト(例えば条件分岐や繰り返し操作)を網羅してロボットを作ることができません。
そのため、条件分岐などを実装するためには、2.を使うことになります。
ロボットの定義は実行してすぐに動作を確認することができるので、「1.で録画」→「2.で条件分岐・繰り返し操作を実装」→ロボットを実行して動作確認→他の操作を「1.で録画」→「2.で条件分岐・繰り返し操作を実装」→ロボットを実行して動作確認・・・
ということを繰り返してロボットを作っていきます。
製品によっても違う部分がありますが、Webブラウザの操作を記録する場合、HTML構文解析機能をもっているものは、HTMLタグのどの項目をどのように変える(入力する)のか、ということを判断できるので、精度が高くなります。
また、画像認識機能を持つ製品もあり、それらの製品ではウィンドウ内の位置情報だけでなく「どのボタンを押すか」を画像一致で検索・実行できます。
ロボットの一連の動作を定義したものを”シナリオ”と呼びますが、シナリオの書き方が製品毎に大きく異なります。
フローチャートのように動作を定義していくものもあれば、まるでプログラミング言語でコーディングをするかのようにシナリオを作るものもあります。
RPAとしての機能だけではなく、維持運用のことも考慮して”どのようにシナリオを作るのか?”も気を付けた方がよいポイントです。
「ロボットを作るにはどういうスキルセットが必要なの?」と聞かれることも多いのですが、条件分岐・繰り返しもあり、正しい処理に直すためのデバッグを考えるとプログラミングを全くやったことが無い人だけでは難しいです。
しかし、バリバリのプログラミングスキルが必要かというとそうでもないので、Excelマクロを組んだことがある人であれば問題ないレベルではないかと思います。
4.まとめ
今回は概要の解説ですが、実際には製品によって実現できることが大きく変わってきます。モノによっては、RPA製品単体で実現出来るけれど、別の製品だと他の製品を購入・連携させないといけない、なんてこともあります。
また、Webブラウザの操作はHTML構文解析機能を利用するため精度が高いのですが、それ以外のアプリケーション(Office製品除く)は専用のモジュールが用意されていないことが多いので、画像認識や座標指定での実装となり、精度が落ち、実装できることに制限が発生することが多いです。
製品選定をする場合には、RPA製品としてどのようなモジュールが用意されているのかについても気にした方がよいポイントの一つです。
次回以降に、弊社が取扱いできる2製品(WinActor、IBM RPA with Automation Anywhere)を検証しましたので、その内容や製品の特長も含めて解説をしていきますのでお楽しみに。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp