
皆さま、こんにちは。てくさぽBLOG メンバーの 岡田です。
前回のブログ(「Cisco UCSってなんだ?」)で Cisco UCS の特徴をお伝えしましたが、特長を知ると実際に使ってみたくなりますよね。特にUCSの管理インターフェイスであるUCS Managerは使ってみることが理解への一番の早道なのですが、ファブリックインターコネクト(以下 FI)の購入が難しい場合もあるかと思います。
そのような場合にお勧めしたいのが、今回ご紹介する「UCS Platform Emulator(以下 UCS Emulator)」です。
今回は、この UCS Emulator を利用できるようにする手順をご紹介します。
1.UCS Emulatorとは
Cisco UCS Managerの設定・管理操作をシミュレートし、どのように機能するかを確認することができます。仮想マシンのディスクイメージとして提供されていますので、簡単に環境構築が可能です。
2.用意するもの
環境構築にあたり、以下をご用意ください。
- Cisco.com ID (今回は登録手順の紹介は省略します。)
Cisco.com ID登録手順:
https://supportforums.cisco.com/sites/default/files/attachments/document/files/cisco_com_registration.201607.pdf - 仮想環境(vSphere,Hyper-Vなどのサーバー仮想化環境や、VMware WorkStation/FusionなどのPCでの仮想化環境でも利用できます)
- Webブラウザ(Microsoft Internet Explorer 6.0 以上,またはMozilla Firefox 3.0 以上)
サポートされる仮想環境、Webブラウザの詳細は以下のリリースノートの2ページ目をご確認ください。
https://communities.cisco.com/servlet/JiveServlet/download/69786-4-129067/UCSPE_GMR1_Release_Notes_3_1_2bPE1_Final.pdf - IPアドレス 3個(固定IPで利用する場合)/サブネットマスク/デフォルトゲートウェイ
3.ダウンロード
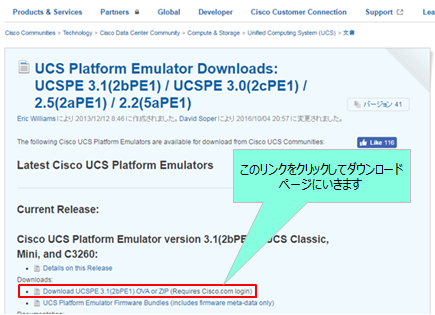
まずダウンロードサイトにアクセスし、Cisco.com IDでログインします。
(ダウンロードサイト)
https://communities.cisco.com/docs/DOC-37827
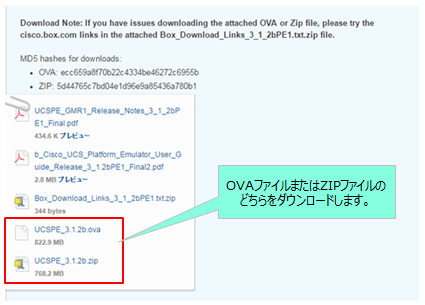
ログインしたらファイルをダウンロードします。Zipファイル形式とovaファイル形式の2種類がありますので、ご利用環境によってお選びください。今回はOVAファイルをダウンロードしました。
4.仮想マシンの構築
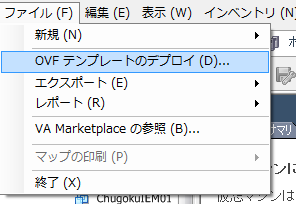
OVAファイルをデプロイします。OVAファイルのデプロイ方法は一般的な手順と同じですので、ここでは詳細は省略します。
今回は、vSphere 5.0の環境上に構築しました。以降の画面イメージはvSphere クライアント 5.0の画面になります。
まず、vSphere クライアントのメニューバーの「ファイル」-「OVFファイルテンプレートのデプロイ」を選択します。
以降、ウィザード画面には利用環境にあった値を入力してください。これにより仮想マシンが作成されます。では、”UCS Emularor の設定” を行っていきましょう。
続きは、こちら↓(※)をご覧ください。
『Cisco UCS Emulatorを触ってみよう!』 の “5.UCS Emulatorの設定”
※ビジネスパートナー専用サイト(MERITひろば)のコンテンツです。ログイン or 新規会員登録が必要となります。
MERITひろば には、Cisco UCS に関する以下のような製品情報、サポート保守のサービスの情報が提供されております。あわせて、ぜひ、ご活用ください。
▼10分でわかる『Cisco UCS 製品』まとめ
▼IBMの技術員がサポートする「CISCO UCS IBM保守サービス」
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp