
「データが増え続け、業務に支障をきたさないように運用するのに苦労している」「増えたデータを活用しきれていない」「運用担当者は日々の業務運用で手一杯」。
このような悩みを打ち明けられていることはないでしょうか。
IoTや5Gといったテクノロジーの導入など、今企業では取得できるデータの幅が大きく広がり、データをどう集め、どう格納し、どう活用するか、さらに、急速に増えたデータをどう管理するかは、企業にとって重要なテーマになっています。
このような企業の課題解決の糸口としておすすめなのが、アプライアンス型のストレージです。
ハードウェアとソフトウェアが一体となって提供されるこの製品は、別途サーバーやソフトウェアを選定・初期構築する必要がなく、運用の負担を軽減できます。
さらに、最新のアプライアンスは大容量で拡張性にも富んでいるため、これから「データを蓄積していきたい」「AI活用に着手し、少しずつ本格化させたい」というニーズにも適しています。
そこで本記事では、スケール・アウト型の共用ファイルシステムである「IBM Spectrum Scale」をベースとしたアプライアンス・ストレージ 「IBM Elastic Storage System」を紹介します。
Index
- ハードウェアとソフトウェアが一体化した統合ソリューション
「IBM Elastic Storage System」 - IBM Elastic Storage System内のエンジン「IBM Spectrum Scale」
- IBM Elastic Storage Systemが誇る6つの特長
- 豊富なモデルの組み合わせで自由なカスタマイズが可能に
- エヌアイシー・パートナーズが、モデル選びを支援します
- この記事に関するお問い合わせ
- 関連情報
ハードウェアとソフトウェアが一体化した統合ソリューション
「IBM Elastic Storage System」
IBM Elastic Storage System (以下 IBM ESS) は、アプライアンス・ストレージです。
ハードウェアの構築、ソフトウェアのインストール、そして動作テストまでも工場で事前に実施した上でお客様サイトに搬入されます。
そのため、現場ではただちにラックへのマウント作業に入れます。
また、事前に綿密な設計を施さなくてもエンタープライズレベルのパフォーマンスや可用性を発揮するよう開発されており、短期間で本番運用を開始することができます。
さらに、運用開始後のシステムアップデートも、OSからファームウェアおよび IBM Spectrum Scale、IBM ESS に特化した部分に至るまで包括的なパッチプログラムは IBM から提供されるので、お客様側ではバッチプログラムを適用するだけで済みます。
そのため、ソフトウェア間の互換性のずれなどを気にすることなく、常に最新の状態で利用できます。
包括的なサービス提供ということに関しては、保守についても同様です。
ハードウェア、ソフトウェアの切り分けなく、問い合わせ窓口は IBM に一本化できます。
管理性に優れているのも IBM ESS の大きな特長です。
視認性に富んだ GUI管理ツールを備えており、これを用いることでストレージ専門の担当者でない方もわかりやすくかつ効果的に日常管理を行えます。
IBM Elastic Storage System内のエンジン
「IBM Spectrum Scale」
このストレージは、アプライアンスながら Software Defined Storage に属しています。
ベースになっているのは、Software Defined Storage であるスケール・アウト型の共用ファイルシステム IBM Spectrum Scale です。
IBM は長年このテクノロジーの発展に精力を傾けてきました。
長いデータソースのプロトコルを管理するパートとデータを管理するパートが別に存在し、それぞれ必要に応じて柔軟に追加可能です。
そのため、 最初は最少構成で導入して徐々に適用を広げていくといったスモールスタートが可能で、ご要件に合わせていつでも簡単に柔軟に拡張できます。
なかでもメリットの大きな機能として挙げられるのは、データの階層管理機能と拠点間ファイル連携機能です。
データの階層管理機能は、データのアクセス頻度に応じて高頻度のものは高速ストレージに、頻度の低いデータは低速ストレージに、とデータの適材適所保存が可能。
ユーザーは、どのストレージプール上にファイルがあるかを意識する必要はなく、データが移動してもいつも同じ操作でアクセスが可能です。
拠点間ファイル連携機能は Active File Management と呼ばれるもので、複数拠点間での非同期コピーを自動で実現します。
データすべてを選択することが可能なら、一部に絞ることもできます。
また、キャッシュはリードオンリー、リード/ライト、DR など様々なモードが選べるため、現場ユーザーの必要とするデータを本社から定期的に配信したり、逆に現場のデータを本社に自動収集する、といったデータ管理が容易に実現できます。
IBM Elastic Storage Systemが誇る6つの特長
IBM ESS がアプライアンス・ストレージとして持つ特長をご紹介します。
1. 可用性・性能設計いらずのSpectrum Scale RAID
IBM ESS は、データ保護機能である RAID が設計ずみのソフトウェア機能として提供されます。
このため、通常のストレージのようにストレージ装置側で別途設計する手間をかける必要はありません。
また、このソフトウェアRAID は、一般的なディスク・ドライブでも十分にエンタープライズレベルのパフォーマンスを発揮します。
2. サイレント・データ破壊を検出可能なEnd-to-endチェックサム
ストレージ管理においては、常に読み書きできるデータが保管されていることが重要です。
しかし、ときにはコンピュータシステム内部で電磁気的な干渉が発生し、メモリの中でビットが自発的に反転してしまうことがあります。
いわゆる “サイレント・データ破壊” で、通常は障害と見なされず読み出してからデータが壊れていることがわかるという厄介な事象です。
その点IBM ESS には、書きこみ時のチェックサムと読み出し時のチェックサムを比較するEnd-to-endチェックサム機能があります。
異常を検知した段階でRAID復旧が行われますので運用停止はありません。
3. パフォーマンス向上に貢献する小容量ファイルの高速Write
このアプライアンス・ストレージでは、NVMeドライブあるいはサーバープロセッサー上の NVDIMMカードが高機能な RAIDコントローラの役割を担っています。
これにより、4KiB未満の小容量データをメタデータ内に直接格納することができます。
これをキャッシュに書きこんだ後ただちに IBM ESS内の I/Oサーバ間で自動レプリケーションが行われ、これを持って格納完了とします。
そのため、IoTデータなど小容量ながら新しいデータが次々送られてくるような利用ケースにおいてはさらにパフォーマンスを向上させることが可能です(図1)。
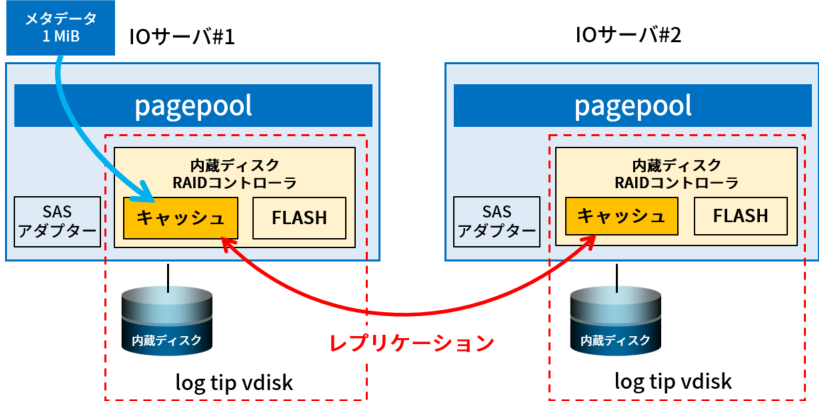
図1. IBM ESSの小容量ファイル高速Write機能
4. NVDIMM/NVMeによる停電耐性実現で、UPSバックアップいらず
IBM ESS の NVDIMMカード/NVMeドライブは強力です。
まずデータに関しては、直接ディスク書込みをもって格納完了とするライトスルー機能を実現しています。
また、メタデータに関しては上記の特長3.でも触れたとおり、キャッシュ書き込みと2台の I/Oサーバ間でのレプリケーションで格納完了となります。
どちらかの I/Oサーバに障害が発生しても、片方の I/Oサーバで代替運転が可能です。
停電耐性も高く、万が一不測の停電が起きた場合でもNVDIMMカード/NVMeドライブ上のキャパシタがキャッシュ上のデータをただちにフラッシュに退避させます。
これにより、データ消失のリスクを最小限に抑えます。
5. 様々な容量のデータに最適対応
ストレージの性能は扱うデータの大きさによっても変化します。
大容量ファイルならば、ディスク内のブロックサイズを大きく設定したほうがパフォーマンス的に有利です。
しかし、小容量ファイルを大きなブロックサイズで管理すると断片化傾向が高まってしまい、性能が低下する上にデータの格納効率も低下してしまいます。
IBM ESSは、ファイルシステム単位で最適なブロックサイズを指定できます。
また、1つのブロックを複数のサブ・ブロックで構成可能であるため、小容量データを効率よく格納できます。
例えば、最大のブロックサイズである 16MiB である場合、16KiB のサブ・ブロックが最大1,024個まで構成可能です。
これにより、ストレージの実効容量を有効に活用できます。
6. 手間をかけずに容量の追加・拡張が可能
このアプライアンスはシステム拡張も容易です。
“小さく生んで大きく育てる” ことができる秘密が、この特長にあります。
これから AI活用を本格化させようという場合にはまさに不可欠な機能といえるでしょう。
増設の際、IBM Spectrum Scale がデータのリバランスをバックグランドで自動実行します。増設前後でデータを退避させたり切り戻したり、といった作業は必要ありません。
このため、当初にパフォーマンスや容量見積もりに頭を悩ませる懸念から解放されます。
豊富なモデルの組み合わせで自由なカスタマイズが可能に
IBM ESS は、ラインナップが豊富なことも大きな魅力です。
速度重視モデルと容量重視モデルが用意されているので、エンドユーザー企業のニーズにフィットした構成を実現できます。
ただし、正直なところモデルがありすぎるために迷うことも事実です。また、選択したモデル路線をその後継続して利用することになるため、最初のモデル選びには慎重さも求められます。
そこで IBM では、モデル選択のために FOSDE tool というデザインツールを提供しています。
FOSDE tool は、正式名称を「File Object Solution Design Engine tool」といい、Webで提供されています。
IBMid があれば自由に利用することが可能です。
大きく、”案件管理” “IBM Spectrum Scale や IBM ESS の検討事項リスト” “ESS構成” という3つの機能があり、ウィザード形式で1つ1つステップを踏みながら最適なモデルを絞りこめるようになっています。
基本は英語表記ですが、検討事項リストなどには日本語訳がついています。
例えば ESS構成機能では、プルダウンメニューを選択していくだけで構成可能なモデルをどんどん特定していくことができます。
実効容量の計算やパフォーマンスの予測なども可能ですから、ここで欲しいストレージ性能をいろいろシミュレーションできるというわけです(図2)。
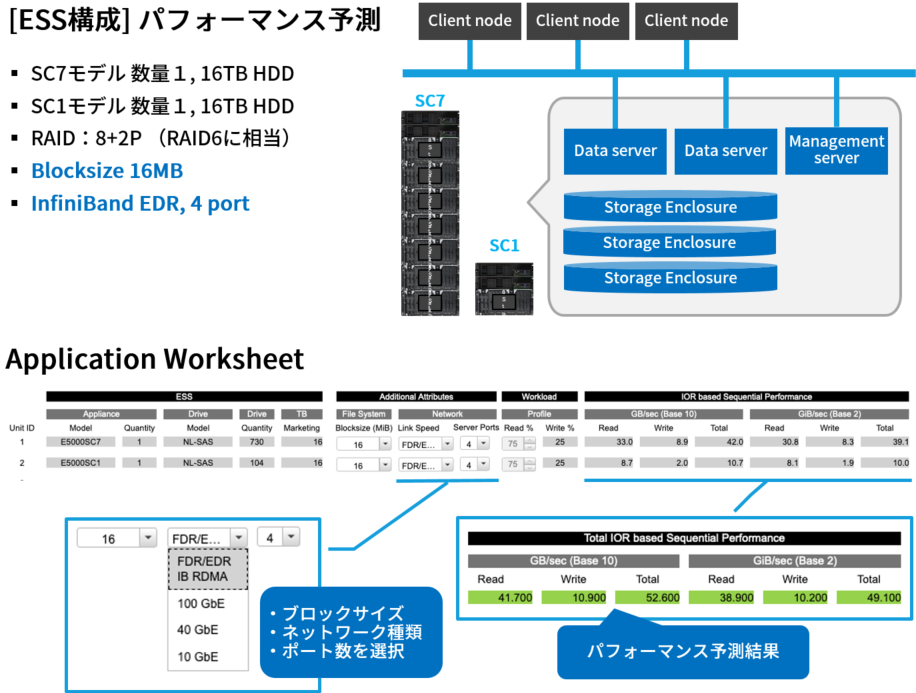
図2. FOSDE toolを使ったESS構成シミュレーション例
エヌアイシー・パートナーズが、モデル選びを支援します
エヌアイシー・パートナーズでは、エンドユーザー企業の課題解決をパートナーとともに考え、提案できる体制を整えています。
IBM ESS に関しても、IBM Spectrum Scale を含めて技術の詳細に精通したエンジニアがいつでも構成設計をお手伝いします。
もちろん、構成作業を支援する FOSDE tool が存在します。入力した内容は IBM と共有でき、選択した構成に無理がないかどうかなどの観点でレビューが提供されることになっています。
ただ、英語表記ということもあり、ウィザードを進める過程では疑問・質問が生じることもあるかと思います。
そうした際は、ぜひ、エヌアイシー・パートナーズにご相談ください。パートナー、エンドユーザー企業の立場に立って支援させていただきます。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBMストレージ製品 (製品情報)
– ストレージ機能のソフトウェア化を実現した SDS製品 (Software Defined Storage) も含め、幅広いラインアップを取りそろえています。