
最近「デザイン思考」という言葉をよく聞くようになってきました。IBM社が大量のデザイナーを採用していると話題となっています。そんな中、そろそろ「デザイン思考」って何?自社も取り組むべきなの?と、疑問に思っている方も多いのではないでしょうか。
Wikipedia によると「デザイン思考」とは、
” デザイン思考(でざいんしこう、英: Design thinking)とは、デザイナーが
デザインを行う過程で用いる特有の認知的活動を指す言葉である。”
とのことですが、正直いいまして、私には全く理解できませんでした。
もう少しわかりやすい定義はないかと探してみますと、イノベーション創出サービスを提供する btrax の記事によると、
” 全てを “Why” から始め、最終的にイノベーションを創り出すプロセス”
出展: btrax, 「【やっぱりよくわからない】デザイン思考ってなに?」
とあり、問いを元にイノベーションを創出するための過程とのことで、おぼろげにその概要が見えてきました。
しかし、これでもデザイン思考とは何なのかを理解するにはなかなか難しいと感じました。
そこで、最近よく聞くこの「デザイン思考」について書いてみたいと思います。
ユーザー中心の思考法からイノベーションを生み出す
思考法としての起源は1960年代後半にさかのぼるようです。ビジネスへの応用は、スタンフォード大学で、後に IDEO を創業するデビッド・ケリーによって開始されたと言われています。 ※ IDEO :カリフォルニア州パロアルトに本拠を置くデザインコンサルタント会社
デザイン思考の「デザイン」とは、いわゆる、デザイナーが絵を描いたり、色を塗ったりすることではありません。デザインには、「新しい機会を見つける為の問題解決プロセス」という定義もあり、デザイン思考においては、この意味になります。
デザイン思考のビジネス応用の研究をスタートさせたスタンフォード大学には d.school という学科横断型のプログラムがあります。機械工学、コンピュータサイエンス、ビジネス、法律、文学など様々な学部学科から学生や教職員が集結、デザイン思考を学びながら、分野を越えてイノベーションを生み出していく力を身につけています。
その d.School 発行のデザインガイドによるとデザイン思考には、5つのステップがあります。
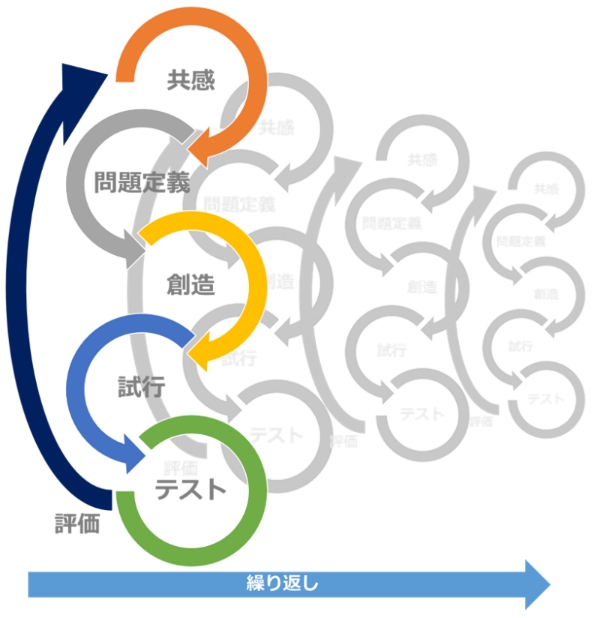
デザイン思考、人間中心の協調的問題解決アプローチ
Step1: 共感(Empathize) ・・・ 共感のためのヒアリング
Step2: 問題定義(Define) ・・・ 本当に解決すべき問題を定義する
Step3: 創造(Ideate) ・・・ 問題解決のアイデアを拡散させる
Step4: プロトタイプ(Prototype) ・・・学びを得るために試行する
Step5: テスト(Test) ・・・ 解決策を改善し評価する
※ 上記のステップを繰り返し改善する
これらを進め、繰り返していくことで、既成概念を排除し、ユーザーに焦点を当てた商品やサービス、またチーム全員が同じ方向を目指して、デザインすることが可能となります。
デザイン思考において最も重要なことは、「ユーザーに焦点を当てる」ということです。とにかく、デザイン思考は、ユーザー中心、ユーザー・ドリヴンな思考法ということがポイントです。
なぜいまデザイン思考なのか?
それでは、なぜ今、デザイン思考が注目されているのでしょうか。
現在、グローバルエコノミーにおける先進企業は、生き残りをかけ、イノベーションを生み出し続けなければならい状況にあります。日本では、優等生とされていた大企業の没落、海外企業への身売りなど、これまでのビジネスモデルや製品サイクルが急激に変化する状況にあります。
日本のみならず、全世界的に新興国発の企業、またベンチャー企業などから攻勢を受け、競争も激化し、大胆に収益モデルの転換を余儀なくされています。
また、スマートフォンを始めとするテクノロジーはどんどん進化するものの、成熟した社会におていては、ヒット商品が生まれにくい状況にあります。単なる性能強化や機能の充実では消費者を満足させ続けられなくなってきています。
このような状況下において、顧客が真に欲するもの、顧客すら気づいていないニーズを掘り起こす、「イノベーションを生み出し続ける」ユーザー中心の思考法としてデザイン思考が注目されているのです。
IT 業界と「デザイン思考」
さて、それでは我々の IT 業界でのデザイン思考の浸透度はどのようなものになっているのでしょうか。
日経ビジネスオンラインによると IBM 社はグローバルで、
“2012年には375人にすぎなかったIBMの社内デザイナーの数は、2015年には1100人にまで増加。さらに2017年には1500人に増やす計画だ。”
出展: 日経ビジネスオンライン, 「米IBM、2017年にはデザイナー1500人体制へ」, 2016年7月28日
としており、デザイン思考を現場で実践するためのデザイナーを相当な勢いで増やしています。
また、
“独ソフトウェア大手SAPも変革の手段としてデザイン思考を活用したグローバル企業です。直近5年で全世界の売り上げを1.4兆円から2.7兆円まで2倍近く伸ばした背景に、デザイン思考がありました。”
出展: Forbes, 「世界的企業は今、なぜ「デザインx経営」なのか?」, 2017年3月29日
とあり、SAP は、デザイン思考によって既に結果を出している企業の一つとのことです。余談ではありますが、スタンフォード大学の d.School は、SAP 創始者のハッソ・プラットナーの個人の寄付により設立されたことからも早い段階から SAP がデザイン思考に注目していたことがわかります。
Salesforce 社でも Ignite と呼ばれるデザイン思考の専門支援チームが、顧客のためのデジタル・トランスフォーメーションのビジョン作りを支援しています。
例を挙げるときりがないほど、多くの IT 企業でデザイナーが活躍し、デザイン思考が活用されていることがわかります。
以下は Techcrunch が、IT関連企業でのデザイナーの需要はこれまでになく高まっているとし、6社でのザイナーとディベロッパーの比率を割り出したもののまとめです。
明らかに、IT 関連大手企業でのデザイナーの採用が増えていることがわかります。
Atlassian Dropbox Intercom 2012年 2017年
1:25 → 1:92013年 2017年
1:10 → 1:62017年
1:5Uber IBM 2010年 2017年
1:11 → 1:82017年
1:82012年 2017年
1:72 → 1:8出典: Techcrunch, 「過去5年間でデザイナーの採用目標が倍増―
―大手6社のデータに見るデザイン人材の動向, 2017年6月2日
とは言ってもデザイン思考ってそんなに簡単なの?
それでは、デザイン思考を日本の IT 企業が実践していくことは、簡単なのでしょうか。
これは、「その会社による」としか言えません。
単純に「デザイナー」と呼ばれる方を社員として迎えたり、プロジェクトごとに配置したりすれば成功するようなものでもありません。前述の d.School がまとめた「デザイン思考に必要な39のメソッド」では、その題名だけからも 39 ものメソッドが必要というこで、その難しさを物語っています。
日本でもデザイン思考を大学で教えたり、研修が受けられるようになったりしてきました。しかし、短期研修ではなかなか上手く実践するところまで到達するのは難しく、また大学で勉強してきたとしても受け入れ側の態勢が整っていない、というのが現状のようです。
そこでまずは、自社が「デザイン思考」のメリットを享受しやすい文化にあるか?というところからチェックしてみるのはいかがでしょうか。
<デザイン思考のための社風チェック>
|
上記に一つでも当てはまることがあれば、デザイン思考を実践する前に自社のマインドセットを切り替えに注目した方がよいかもしれません。
多くのデザイナーを採用している IBM 社であっても、デザイン思考の導入には以下のようなアプローチを踏んでいます。
” IBMは巨大かつ複雑な組織で、製品のテクノロジーも複雑です。デザイナーが入社後、それぞれのチームに入る前に“橋”をかけるようなサポートを行う必要がありました。現在、新たなデザイナーに対して3カ月のブートキャンプ・プログラムを実施していますが、私は、その設計と運営、管理を行いました。
また、このデザイナー向けのプログラムを実施していく中で、IBM全社員に対しても、デザイン及びデザイン思考について教育を行い、会社を変化させないといけないことがわかりました。なぜなら、全社員も、企業としてどのような方向に変化していくのかを知る必要がありますから。
そこで一人でも多くのIBM社員がデザイン及びデザイン思考を体験し理解するための教育プログラムをつくりました。デザイナー向けから全社員向けに、私の役割はここ数年でこうした変化を遂げてきました。”
出典: Forbes, 「IBMがデザイナーを1000人雇い、デザイン思考を推める理由」, 2017年3月24日
まずは、デザイン思考を知り、この思考法を社内で展開できる雰囲気か判断し、そうでなければまずは、その目的づけ、会議や打ち合わせのやり方、ユーザーとの接し方、縦割りのプロセスなどを見直すところから始めてみてはいかがでしょうか。
いきなり、「デザイン思考」ありきからスタートすると、単なる思考法マニュアルになってしまい、「デザイン思考でやってみたが何も起こらない」となってしまう可能性があります。
それでは、デザイン思考そのものの恩恵を十分享受し、真のイノベーションに到達することは難しいでしょう。
クラウドとデザイン思考
では、具体的に何か製品開発にデザイン思考を応用した例はないかと探してみると、身近な良い例がありました。それはBluemix です。Bluemix はデザイン思考を元に開発された製品なのです。
”The Bluemix team used IBM Design Thinking to focus on users—not functions or capabilities—with the goal of letting developers focus on their work, rather than on infrastructure and configuration.
【抄訳】Bluemix チームは、IBM デザイン・シンキングを使用して、インフラやコンフィグではなく、開発者が自分の仕事に集中できるように、「ユーザー」~ 機能や能力ではない ~ に焦点を当てました。”
出展: IBM Design, 「Case study: IBM Bluemix」, 2014年7月17日
また、当プロジェクトでは、多くの人数と時間をユーザーとの時間に費やし、マネジメント、エンジニアリング、設計、マーケティングに至るまで、一同が関わり、共創することで、計画より半年以上前倒しして、Bluemix を完成させることができたとのことです。
ここでは、多くを触れませんが、このような形で、IBM 社のクラウド戦略の根幹をなす製品開発にデザイン思考が活用され、成果が出ていることがわかります。
Bluemix でのケーススタディでもわかる通り、イノベーションのプラットフォームとしてのクラウド活用が今後進んでいくことは間違いないでしょう。それは、Bluemix の特長を例にとると、
|
など、デザイン思考のような、プロトタイピングを重視する早期実行型の思考法にマッチしやすいと考えられるからです。
今後は、IT企業だけではなく、別業態からもクラウドを中心にイノベーションを進めていく企業がどんどん増えるはずです。これらの企業や迎え撃つ既存の IT企業の開発者は、サーバー構築や運用の労力にとらわれず、プログラミングに集中できるBluemix をベースに新たなサービスを模索したり、構築を進めたりすることは自然な選択ではないでしょうか。
更に、デザイン思考をベースに開発された Bluemix 上で、デザイン思考を活用し、イノベーションを実現する、これらは非常に相性の良い組み合わせかと容易に想像できます。
今後もデザイン思考の取り組みにも注目していただければ幸いです。次回は「デザイン思考導入を阻むもの」について考えてみたいと思います。