
グリーン・ファイナンスや代替えエネルギーへの投資など、脱炭素化や ESG投資(「Environment:環境」「Social:社会」「Governance:企業統治」を考慮した投資活動や経営・事業活動への取り組み)は、もはやムーブメントではありません。
これらの取り組みが企業の財務戦略と並ぶ重要な位置を占めるようになっています。
そして、脱炭素化を目指す企業のサステナビリティ・パフォーマンスの最適化に必要不可欠なのが、正確なレポートデータから得る洞察です。
本コラムでは、データ収集と分析を包括的なソフトウェア・プラットフォームにより多岐にわたる ESG指標を報告・管理して排出量を削減するためのアクションを特定し、最終的にはデータ基盤の構築やレポートの合理化、チームのエンゲージメント向上へと導き脱炭素化の加速を実現する IBM の ESGデータ管理プラットフォーム「Envizi ESG Suite」を紹介します。
| 目次 |
|---|
ESG情報開示の世界的な潮流と日本の状況
「ESG」「サステナビリティ」「排出量」「脱炭素化」など、かつては企業にとって馴染みのなかったコンセプトがここ10年間で今や企業戦略の欠かせない一部となりました。
脱炭素に向けた動きは世界的に加速し、国連気候変動枠組条約第26回締約国会議(COP26)が終了した2021年11月時点で、154カ国・1地域が2050年などの年限を区切ったカーボンニュートラル(温室効果ガスの排出を全体としてゼロにすること)の実現を表明しています。
日本でも2020年10月、菅首相による「実質ゼロ表明」宣言(2050年カーボンニュートラル宣言)がありました。これに呼応して地球温暖化対策推進法が一部改正され、「改正地球温暖化対策推進法」(以下 改正温対法)として2021年5月に成立しています。
そもそも温暖化対策については1997年の「京都議定書」を継承して、2015年12月にフランスのパリで開催された COP21 にて世界約200カ国が合意し成立した条約(通称 パリ協定)が対策目標の基準となっています。
そのパリ協定を受けて日本政府は2016年に「地球温暖化対策計画」を閣議決定し、その時点で提示されていた目標は「2030年までの中期目標として温室効果ガス排出を2013年対比26%削減。そして、2050年までに80%削減する」というものでした。
しかし「2050年カーボンニュートラル宣言」ではこの80%という目標削減数値が一気に引き上げられ100%に。すなわち、2050年までに排出ゼロにするということです。
当然、企業対策も強化されることとなり、これに対し産業界には激震が走りました。
改正温対法による排出量情報のデジタル化・オープンデータ化の推進
改正温対法の主なポイントは次の3点です。
- 2050年までに温暖化ガスの排出を実質ゼロにすることを基本理念として明記
- 地域の再エネを活用した脱炭素化を促進する事業推進のための計画・認定制度の創設
- 脱炭素経営の促進に向けた企業の排出量情報のデジタル化・オープデータ化の推進
このなかで特に注目したいのが「企業の温室効果ガス排出量情報のオープンデータ化」です。
従来、温室効果ガスを多量に排出する企業に対しては毎年度の排出量の報告が義務づけられています。その情報は企業単位で公表されていますが報告の多くは紙媒体を中心に行われており、公表までに約2年もの期間を要していました。
そこで改正温対法では排出量情報の公表までにかかる時間を短縮することを目的とし、企業の温室効果ガス排出量報告を、排出量情報活用促進の弊害にとなっている紙媒体中心の報告から原則デジタル化しています。
さらに、企業における脱炭素化の取り組みをより透明性高く可視化するため、従来は開示請求手続きが必要だった事業所単位での排出量情報を、手続きなしでも閲覧可能としています。
これにより、国内外の企業や投資家などに向けて温室効果ガスの排出量情報の活用を促すとともに、脱炭素経営や ESG投資の呼び込みを促進させる考えです。
ESG投資の急拡大と求められる情報開示
金融市場においてはコロナ禍にともなう金融緩和も相まって、ESG投資が急拡大しています。
ESG投資とは “ESGの3要素を重視し社会的責任を果たしている企業に対し投資をすること” を意味します。
2021年7月19日、世界の ESG投資額の統計を集計している国際団体の GSIA(Global Sustainable Investment Alliance)*1 から、ESG投資の統計報告書「Global Sustainable Investment Review(GSIR)」の2020年版が発行されました。
同報告書によれば、2020年の世界の ESG投資額が18年比で15%増の35.3兆ドル(約3900兆円)で、これが全運用資産に占める比率は35.9%と18年比で2.5ポイント上昇しています。日本の ESG投資額も2020年には2.8兆円(約320兆円)と、2018年と比べて31.8%も増加しました。
これにともない、気候変動に関する情報開示を企業に求める動きが世界的に広がっています。
日本でも東京証券取引所のプライム市場上場企業は、TCFD提言*2 またはそれと同等の国際的枠組みに基づく開示を求められています。
こうした動きに加えて、2021年11月には IFRS財団(The IFRS Foundation)により「国際サステナビリティ基準審議会(ISSB)」が設立されました。
これにより、ESG情報の開示に関する統一的な国際基準を策定する ISSB基準に準拠したサステナビリティ開示基準の公開草案を2024年3月31日までに公表し、2024年度中(遅くとも2025年3月31日まで)に確定する計画も進んでいます。
産業界では、国内外で取引先まで含めたサプライチェーン全体の脱炭素化やそれにともなう経営全体の変容(グリーントランスフォーメーション(GX))が加速し、デジタル技術の活用でサプライチェーン上の CO2排出量を算定し可視化するサービスの開発も活発になっています。
参考情報
*1. Global Sustainable Investment Alliance(GSIA)
GSIA は2年に一度、日米欧など世界5地域のESG投資の普及団体が年金基金や資産運用会社などを対象に実施したアンケートを基に「Global Sustainable Investment Review(GSIR)」でESG投資額を公表している。
※サステナブル投資(SRI・ESG投資)の発展に寄与することを目的とした NPO日本サステナブル投資フォーラム(JSIF)作成の「Global Sustainable Investment Review 2020」日本語訳ダウンロードは「こちら」
*2. TCFD提言
「気候変動関連財務情報開示タスクフォース(Task Force on Climate-related Financial Disclosures)」の略称。
G20財務大臣・中央銀行総裁会議の要請を受け、2015年12月に金融安定理事会(FSB)により気候関連の情報開示および気候変動への金融機関の対応を検討するために設立された。
TCFD は2017年6月公表の最終提言をはじめ、関連ガイダンス等複数の刊行物を公表。そのメインレポートが「Final Report: Recommendations of the Task Force on Climate-related Financial Disclosures(気候関連財務情報開示タスクフォースによる提言 最終報告書)」で、通称「TCFD提言」といわれる。
- TCFDとは(TCFDサイト)
- ESG情報開示枠組みの紹介:気候関連財務情報開示タスクフォース(Task Force on Climate-related Financial Disclosures, TCFD)提言(JPXサイト)
- JPXからのお知らせ:「TCFD提言に沿った情報開示の実態調査(2022年度)」の公表について(JPXサイト)
Scope毎のCO2排出量の把握はサプライチェーン脱炭素化実現の第一歩
これらの状況の中でカーボンニュートラルに向けて企業が取り組むべきことは、まず CO2排出量を正しく把握・可視化し、サステナビリティ・パフォーマンスを最適化することです。
その目的は、気候関連の財務情報の開示、顧客企業への排出量報告、Scope情報の収集、省エネ法・温対法への対応です。
特に日本が目指す「カーボンニュートラル」は CO2 だけに限らず、メタン、N2O(一酸化二窒素)、フロンガスを含む「温室効果ガス」を対象にしたものであり、「全体としてゼロに」とは「排出量から吸収量と除去量を差し引いた合計をゼロにする」ことを意味します。
そのため企業の排出責任の範囲は自社単体からサプライチェーン全体に広がり、排出量を把握することの重要性が高まっています。
国際的な温室効果ガス排出量の算定・報告の基準となるのが「温室効果ガス(GHG)プロトコル」です。その中で設けられている温室効果ガスのサプライチェーン排出量の算定方法・範囲のことをScope(スコープ)と呼びます。
サプライチェーン全体の排出量は「スコープ3基準」として次のように区分されています。
- Scope1:事業者自らの燃料の燃焼や工業プロセスにともなう排出量を示す指標
- Scope2:他社から供給された電気・熱・蒸気などのエネルギー使用にともなう排出量を示す指標
- Scope3:サプライチェーン排出量のうち、Scope1とScope2以外の間接排出量を示す指標
Scope3 では、自社内だけではなく部品メーカーや原材料メーカーなど、自社製品の生産に必要な部品製造のために他社が排出した温室効果ガスの排出量を把握することが求められています。
日本全体の CO2排出量削減目標を達成するにはこの Scope3 の排出量にも着目する必要があります。したがって、Scope3 の算出は複雑さをともなうと同時にサプライチェーン全体での脱炭素化実現の第一歩だといえます。
これに対応して CO2 を可視化するサービスは近年クラウドを中心に様々なものが登場しており、マクロ視点での非財務情報としての温室効果ガス排出量実績や削減目標・取り組みの公開まで実現できていますが、可視化までの取り組みで止まってしまい、次のアクションへつなげられていないケースも少なくありません。
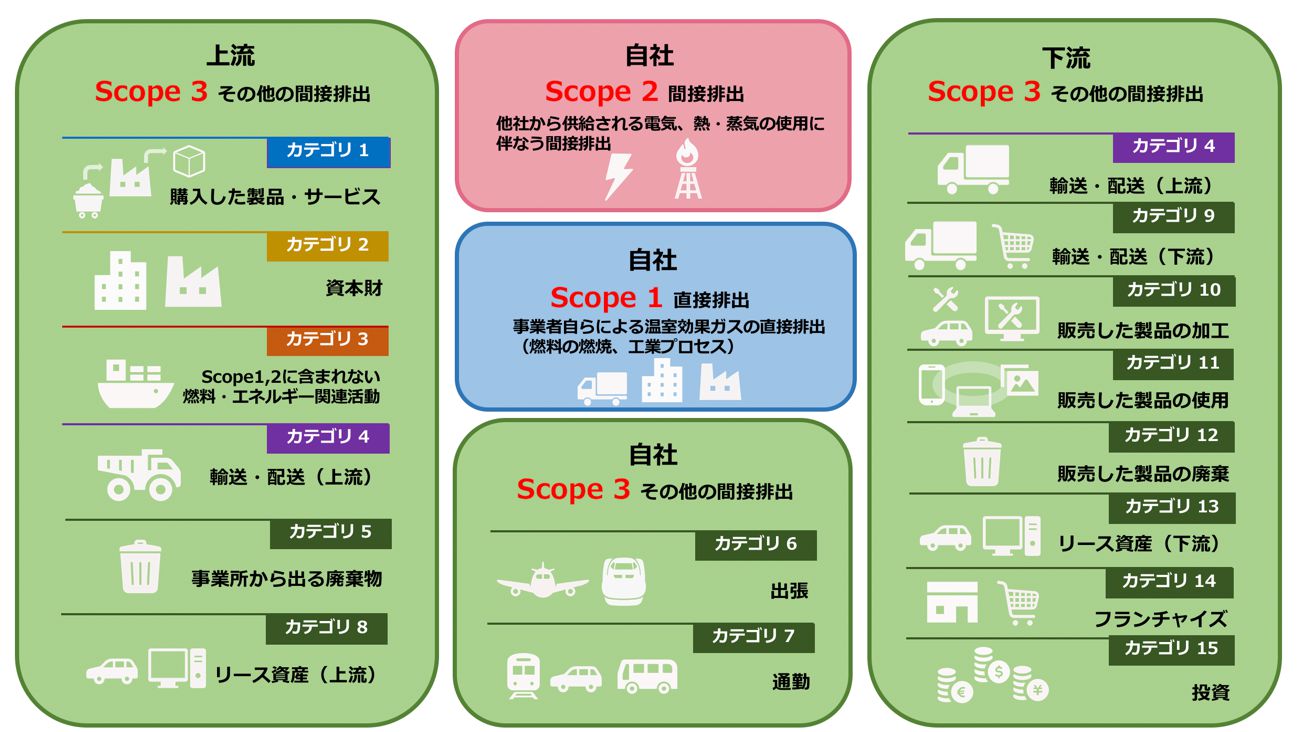
図1:温室効果ガス(GHG)排出量のスコープ3基準の範囲
ESGレポート、ESGパフォーマンス、エネルギー管理、施設の最適化
IBM は2022年1月、環境パフォーマンス管理においてデータ分析ソフトウェア・プロバイダー大手Envizi社 の買収を発表しました。
Envizi社は炭素排出量の管理で組織をサポートするというビジョンを持って2004年に設立され、これまで20年近い歴史の中で英国と米国の市場で成長し、10年以上の運用ノウハウを活用したベストプラクティスを提供しています。
IBM の「Envizi ESG Suite(以下 Envizi)」には、同社の実績がそのまま活かされています。
正確なデータから得る洞察は脱炭素化の道筋に不可欠です。
Envizi の15種類のモジュールは、全体で排出量管理、ESGレポート、ESGパフォーマンス、エネルギー管理、および施設の最適化など様々な機能を提供しており、お客様のニーズに合わせてソリューションを拡張できます。
Scope1 および Scope2、さらには Scope3 の全カテゴリをカパーする500を超えるデータ・タイプの収集と集約を自動で実行でき、カスタム・フィールドの追加も容易です。

図2:Enviziがカバーするデータの種類
これにより ESG指標を報告・管理できるようになるだけではなく、データと分析を包括的なソフトウェア・プラットフォームで提供し、現状の可視化や適切な情報開示を支援、そして、サステナビリティ・パフォーマンス管理を促進します。
また、国際的に認められた主要な ESG報告書作成フレームワークに対応し、強力な視覚化機能と簡単にカスタマイズ可能なダッシュボードを使用することで環境目標の管理や効率性を向上させる機会の特定、サステナビリティ・リスクの評価を行うことが可能です。
温室効果ガス排出量係数は様々な国や地域、カテゴリごとに次々と更新されていく状況で、ユーザー自らが管理することが非常に難しくなっています。これに対しても、Envizi ではお客様が活動量に関するデータを入力するだけで自動的に排出量が算出されるようなっています。
また、毎年のように変わる ESG情報開示フレームワークに対しても Envizi を使うことで簡単にレポーティング作業を管理することができます。
お客様の大きな価値となるサステナビリティ・イニシアチブ促進を目指して
500種類以上のデータの収集と統合を自動化する Envizi は、前述の TCFD の他にも ESG要素に関する開示基準として国際的なサステナビリティ報告基準を運営する「CDP*3」や「SASB*4」など、主要なサステナビリティ・レポートの開示フレームワークをサポートしています。
さらに Envizi は、以下のような IBM のより広範な AI搭載ソフトウェアを共に使用することで企業の環境イニシアチブと日常業務における運用エンドポイントとの間で生成されるフィードバックを自動化し、現状を把握しながら素早い改善アクションの実行を可能にします。
- IBM Maximo(設備保全管理ソリューション)
- IBM Sterling(サプライチェーン・ソリューション)
- IBM Environmental Intelligence Suite(気候変動による経済的影響を事前に計画・管理)
- IBM Turbonomic(ITインフラの「リアルタイム最適化」を実行)
これによりお客様は ESG対応状況を迅速に把握し、目的にあったテンプレートを用いることでゴールを明確にしてデータの可視化を進め、レポートの作成とプロジェクトを円滑に運営してサステナビリティ活動を加速することができます。
そして、レポートを公開することで透明性をアピールするとともにカーボンニュートラルを企業の大きな価値に転換し、サステナビリティ・イニシアチブの促進や環境目標を実現することが可能になるのです。
エヌアイシー・パートナーズは IBM認定ディストリビューターとして、Envizi ESG Suite および Envizi ESG Suite と連携可能な製品の販売を通し、お客様のよりレジリエントで持続可能な運用とサプライチェーンの創出、そして、持続可能性への取り組みをスケーラブルにするための重要なステップを支援いたします。
参考情報
*3. CDP
英国の慈善団体が管理する非政府組織(NGO)であり、投資家、企業、国家、地域、都市が自らの環境影響を管理するためのグローバルな情報開示システムを運営。
2000年の発足以来グローバルな環境課題に関するエンゲージメント(働きかけ)の改善に努めており、日本では2005年より活動開始。(一般社団法人 CDP Worldwide-Japan)
*4. SASB
「Sustainability Accounting Standards Board(サステナビリティ会計基準審議会)」の略称。
2011年に米国サンフランシスコを拠点に設立された非営利団体で、企業の情報開示の質向上に寄与し、中長期視点の投資家の意思決定に貢献することを目的に将来的な財務インパクトが高いと想定されるESG要素に関する開示基準を設定している。
2018年11月に11セクター77業種について情報開示に関するスタンダードを作成・公表。
「ESG情報開示枠組みの紹介:SASB(Sustainability Accounting Standards Board, サステナビリティ 会計基準審議会)スタンダード」(JPXサイト)
お問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
NI+C Pサイト情報
- IBM Envizi ESG Suite
– 企業の透明性ある情報開示と脱炭素に向けた取り組みをサポートする、ESGデータ管理プラットフォームです。
IBMサイト情報
- IBM Envizi ESG Suite
- Envizi ソリューション概要紹介ビデオ
- サステナビリティ・レポートの作成を製造業のポートフォリオ全体で変革
- IBM Maximo 設備保全管理ソリューション
- IBM Sterling サプライチェーン・ソリューション
- IBM Environmental Intelligence Suite
- IBM Turbonomic