
Oracle Database を比較的低コストで利用できるエディションとして Oracle SE2 は知られた存在ですが、このデータベースを動かすなら「IBM Power10 S1014」が最も有力な候補であることをご存じでしょうか。
TCOコストやパフォーマンス、バージョン対応、セキュリティという観点で、旧世代の Powerシリーズよりも、何より x86サーバー環境よりも多大なメリットを有しています。
本記事では Oracle SE2サーバーとしての IBM Power10 S1014 の魅力を深堀りしていきます。
| 目次 |
|---|
Oracle SE2を最も経済的に使うならIBM Power10 S1014
Oracle Database は、企業情報システムのデータベースとして他には代えがたい独特のポジショニングを有しています。
その一方、ライセンスコストに関しては企業の懸念材料になり続けていることも事実です。
そうした中、Oracle Database の標準機能を実装していながら低コストで利用できるエディションが「Oracle Standard Edition 2(SE2)」です。
SE2 の上位エディションである Oracle EE を EE特有の機能を駆使することなく使っているのであれば(*1)、Oracle SE2 にスイッチするだけでもコストダウンを図ることができます。
加えてハードウェアの選択でもコストダウン効果を得ようというなら、ぜひ、IBM Power10 の「S1014」を第一候補として検討してみてください。
S1014 は IBM Power10ラインナップのエントリークラスに相当するスケールアウトモデルのサーバーですが、実はとても有用なのです。
さらに、IBM Power10 の採用は、性能の高さを生かしたサーバー統合という形でのコストメリットも生み出せます。
下図の表は、Power8 や Power9 と比較したときに、Oracle SE2用サーバーとしてどれだけパフォーマンスが高いかを示したものです。
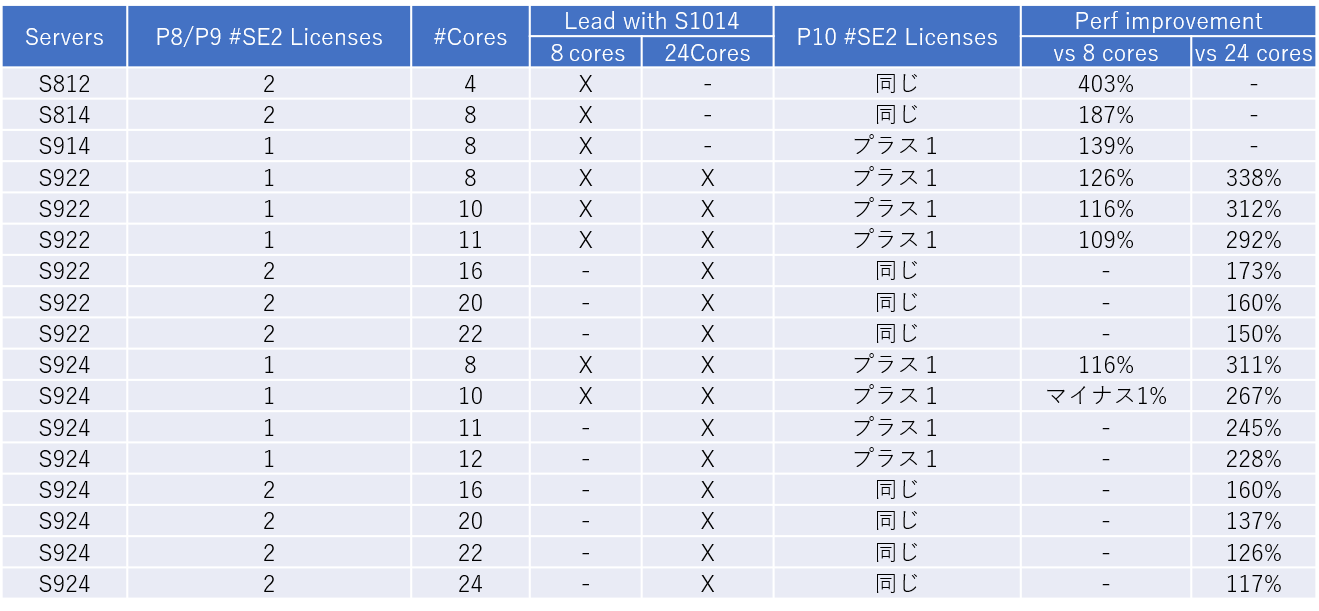
図1:Oracle SE2サーバーとしてのIBM Power10の実力比較
見かけの価格は高いように感じても、サーバー統合により全体コストを下げられます。
Oracle SE2 が分散して何台もある状況であれば、ご検討いただく価値は十分にあるでしょう。
*1. Oracle Database製品およびエディションによる機能の差異
- Oracle Database製品
- Oracle Database製品で許可される機能、オプションおよびManagement Pack
- Oracle Databaseオプションおよび許可される機能
- Oracle Management Packおよび許可される機能
対x86サーバー環境ではさらに大きな優位性を発揮
このように、IBM Power10 は従来の Powerラインナップと比較してさまざまなメリットがありますが、対x86サーバー環境ではさらにそれ以上の優位性を発揮します。
そもそも、IBM Power10 は1ソケットで高いパフォーマンスを有します。
x86サーバーが HMT2(Hardware Multithreading 2)実装であるのに対し、IBM Power10 は SMT8(Simultaneous Multithreading 8)をサポートしており、トランザクション処理のキャパシティが非常に高く、まさにデータベースに適したサーバーであるといえるでしょう。
一方で Oracle SE2 は、1データベースあたりの同時処理可能スレッド数が16に制限されているため、プラットフォームに関わらず SE2用の基盤にデータベースを仮想統合することで、今時のハードウェアリソースを余すところなく活用でき TCO削減につながります。
IBM Power10 には仮想化技術である PowerVM が搭載されているため、複数の SE2データベースを仮想統合する際にも仮想化ソフトウェアを追加で購入する必要がありません。DBごとにリソース管理が行えるというメリットもあります。
さらに、PowerVM はハードウェアと密接に連携した仮想化のため、オーバーヘッドが非常に少ないという特長があります。
CPUシェアが可能であるとともに CPU利用効率が高いため、より多くのデータベースを効率的に稼働させることができます。
ある調査では、S1014 24Coreモデルでの Oracle SE2搭載は、上位機種のx86サーバーと比べて24%、Oracle製データベースアプライアンスとの比較では最大38%、TCO が低くなると算出されています。
IBM Power10 では OS である AIX のライブアップデートができ、OSアップデート時は一部の更新を除いてほぼ再起動が不要です。”信頼性” “可用性” “セキュリティ” という点でも、サーバープラットフォームとして業界で高い評価を受け続けています。
このように、様々な観点で安定した稼働を実現でき、運用負荷を大きく軽減します。
古いバージョンの Oracle Database もそのまま稼働できます。
IBM Power10 で Oracle Database を動かすメリットとして、比較的古いバージョンを搭載できる、ということがあります。
以下の図は IBM Power10 における Oracle Database のシングルインスタンスの構成サポート状況の図で、表の中の〇は推奨バージョン、△は稼働可能バージョン(現在はOracleがサポート終了しているがかつて動作保証されていた組合せ)であることを示しています。
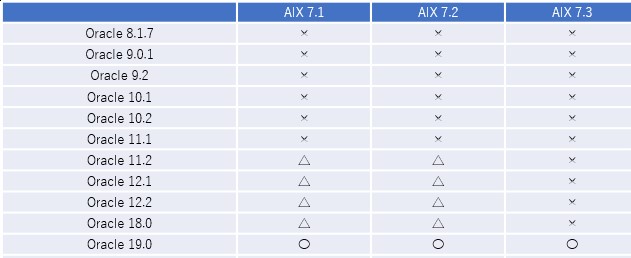
図2:IBM Power10におけるOracle Databaseのシングルインスタンスサポート状況
これを見ると、さかのぼって Oracle 11.2(11gリリース2)まで対応可能になっています。
データベースサーバーは基幹システムであり、その変化が実業務にインパクトを与えるためになかなかバージョンを上げられないというケースも多々あるかと思います。
そのような場合でも IBM Power10 であれば、バージョンを上げずにそのままの状態で稼働させながら大きなパフォーマンス向上を実現させることが可能です。
セキュリティでも一歩先行く機能を実装
セキュリティもまた、ビジネスの継続性を考える上で非常に重要なポイントです。
ここでも IBM Power10 S1014 は Oracle SE2 の稼働に大きく貢献します。
AIX上で稼働することで、競合する OS と比較し脆弱性を低く抑えることができます。
脆弱性に関するレポートは、23年間で286件、年あたり平均14件という少なさです。
また、IBM Power10 は物理メモリ上のデータを常に暗号化するという透過的メモリ暗号化を実装しており、処理性能に影響を与えることなく脅威からデータを守ることが可能です。
AIX ではファイルシステムの暗号化も標準機能として提供しているためデータベース側で特段の対応が不要である点も、運用負荷の軽減につながります。
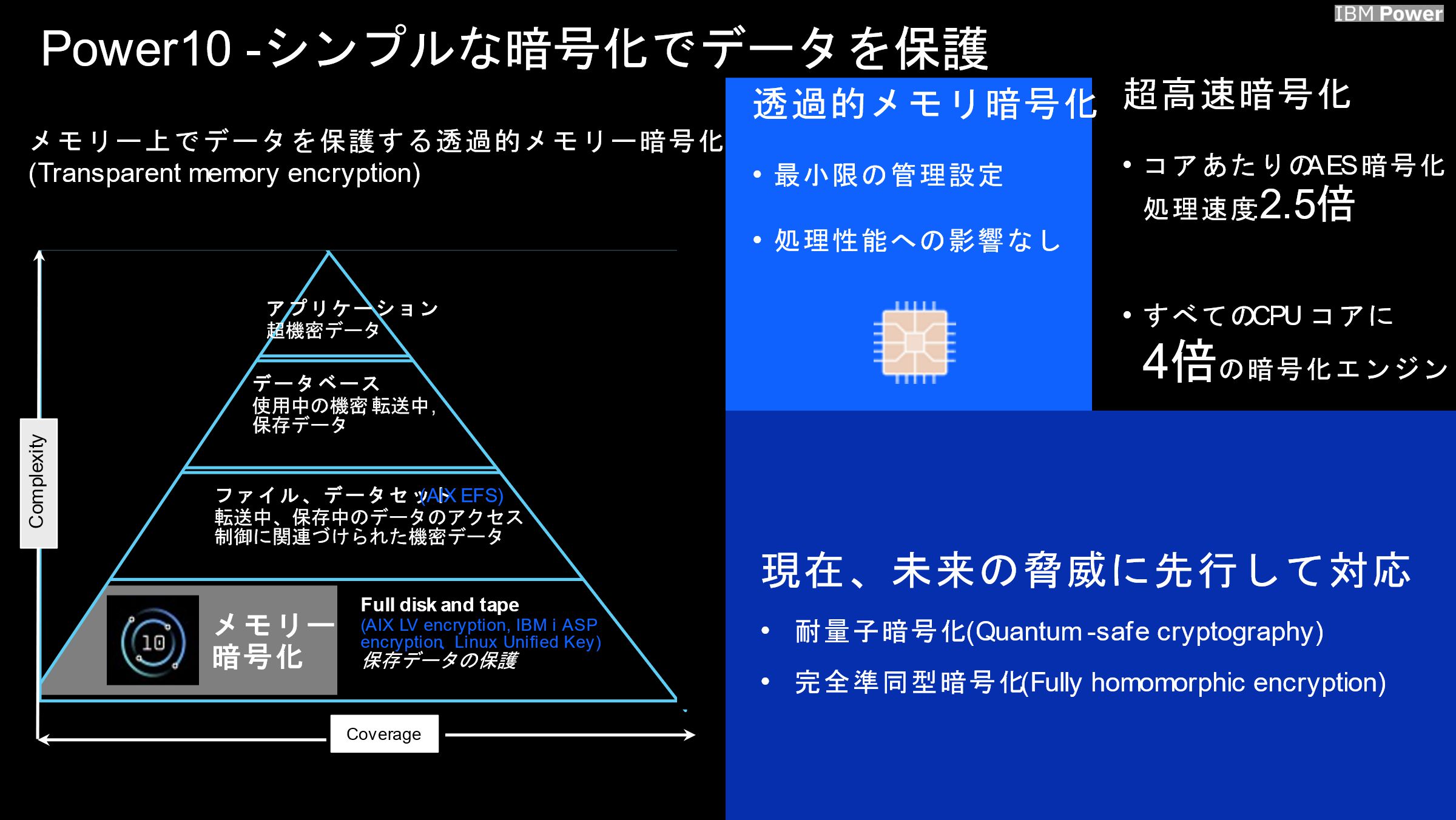
図3:IBM Power10は透過的メモリ暗号化でデータを保護
Oracleに関する悩みはNI+C Pにご相談ください
エヌアイシー・パートナーズでは、IBM Power10 S1014 をインフラとする Oracle SE2サーバー構築に当たり、潜在ニーズを含めたシステム構成の検討から具体的な構成案の作成までサポートします。また、データベースサーバーを取り巻くシステム全体の提案支援も行っています。
エンドユーザーのお客様の課題を解決するために、リセラーの皆様と一緒に知恵を絞り、汗をかくことがモットーです。
「何となく次もx86サーバー」という提案は、いったん脇に置いてみてください。
Oracle で悩んでおられるお客様のその課題、IBM Power10 S1014 であっさり解決できるかもしれません。
この記事に関するお問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いいたします。